2023年11月份在某电商系统生产中的Elasticsearch(以下简称ES)集群突然,出现了大量慢查询告警,导致请求堆积。经过几天的排查发现了ES节点主分片和副本分片分布存在不均匀的问题。当然了暂未有定论是由于分片不均衡导致了性能下降,但是主分片和副本分片分布不均匀确实是个问题。
1、概念说明
下面我们来介绍一些重要的概念。
-
集群(cluster):代表一个集群,其中包含多个节点。集群中有一个主节点,这个主节点通过选举产生。主节点和从节点是集群内部的概念。Elasticsearch采用去中心化的设计,即在集群外部看来,没有中心节点,因为对外部来说,与任何一个节点通信和与整个Elasticsearch集群通信是等价的。 -
主分片(Primary Shard):代表索引的主分片。Elasticsearch可以将一个完整的索引分成多个主分片,将其分布在不同的节点上,实现分布式搜索。主分片的数量只能在索引创建前指定,并且创建后不能更改。 -
副本分片(Replica Shard):代表索引的副本分片。Elasticsearch可以为一个索引设置多个副本,副本的作用有两个方面:一是提高系统的容错性,当某个节点的分片损坏或丢失时,可以从副本中恢复数据;二是提高查询效率,Elasticsearch会自动对搜索请求进行负载均衡。 -
数据恢复(recovery):或重新分布是指在节点加入或退出集群时,根据机器的负载情况重新分配索引分片的过程。当一个节点重新启动时,也会进行数据恢复。
那么,在什么情况下可能导致分片分布不均匀呢?
索引的动态均衡:包括集群内部节点数量调整、新增索引、删除索引副本、删除索引等情况;增加副本:因有大量的数据集中写入到某个节点;节点宕机:通常在下线一个Elasticsearch节点后,该节点上的主分片会被判定为丢失,此时Elasticsearch集群会自动将其他节点上的副本分片设置为主分片。当该节点重新启动时,分片数据会被识别为副本分片。这些操作可能导致一些节点上的主分片较为集中,而另一些节点上的副本分片较为集中;大量集中数据写入:大量数据的集中写入可能导致主分片在短时间内不均匀的情况。当业务场景需要大量写入时,如果设置了较多的ingest节点进行写入,由于无法实时同步,可能会导致主分片在节点之间不均匀地分布。
上述两种情况经常发生,因此分片分布不均匀并不罕见。
2、分配与平衡策略
以下动态设置可用于控制集群中分片的重新平衡:

2.1、 shard分配策略
参数说明: cluster.routing.allocation.enable-(动态) 启用或禁用特定类型分片的分配:
all-(默认值)允许为所有类型的分片分配分片。primaries- 仅允许为主分片分配分片。new_primaries- 仅允许为新索引的主分片分配分片。none- 不允许对任何索引进行任何类型的分片分配。
重新启动节点时,此设置不会影响本地主分片的恢复。如果重新启动的节点具有未分配的主分片的副本,会立即恢复该主分片。
cluster.routing.allocation.node_concurrent_incoming_recovers
允许在一个节点上进行多少次并发的传入分片恢复。传入恢复是指在节点上分配目标分片(很可能是副本,除非分片正在重新定位)的恢复。默认值为2。
cluster.routing.allocation.node_concurrent_outgoing_recoveries
允许在一个节点上进行多少次并发传出分片恢复。传出恢复是指在节点上分配源分片(很可能是主分片,除非分片正在重新定位)的恢复。默认值为2。
cluster.routing.allocation.node_concurrent_recoveries
设置cluster.routing.allocation.node_concurrent_incoming_recoveries和cluster.routing_allocation.node _concurrent_outgoing_recoveries的快捷方式。
cluster.routing.allocation.node_initial_priparies_recoveries
虽然复制副本的恢复是通过网络进行的,但节点重新启动后未分配的主服务器的恢复使用本地磁盘中的数据。这些恢复应该很快,这样就可以在同一节点上并行进行更多的初始主恢复。默认值为4。
cluster.routing.allocation.same_shard.host
允许根据主机名和主机地址执行检查,以防止在单个主机上分配同一分片的多个实例。默认为false,表示默认情况下不执行任何检查。此设置仅适用于在同一台计算机上启动多个节点的情况。
2.2. rebalance平衡策略
参数说明:cluster.routing.allocation.allow_rebalance用来控制rebalance触发条件:
always- 始终允许重新平衡;indices_primaries_active- 仅在所有主分片可用时;indices_all_active- (默认)仅当所有分片都激活时;
cluster.routing.allocation.cluster_concurrent_rebalance用来控制均衡力度,允许集群内并发分片的rebalance数量,默认为2。
cluster.routing.allocation.node_concurrent_recoveries,每个node上允许rebalance的片数量。
3、解决方案
3.1、重启节点
在重启ES集群之前,我们先来看看集群分片分配设置(allocation和rebalance)默认参数。
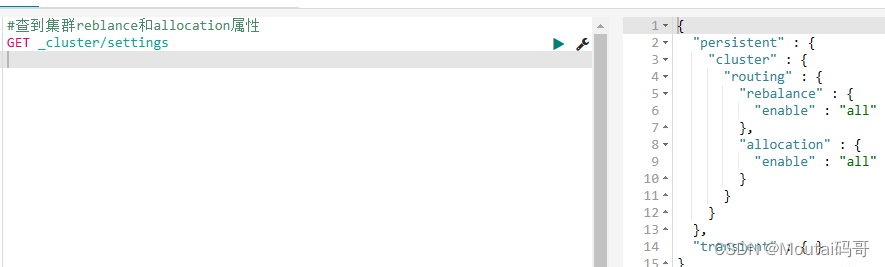
默认设置情况下,经过多次重启,实践证明重启条件下ES集群不会触发自动均衡。
3.2 自动分片迁移
假如以idx_items商品索引为例,我们在进行重新(reblance)分片操作之前,一般要对索引数据进行备份,以防意外发生,备份操作如下:
- 备份索引数据:
POST _reindex
{
"source":{
"index": "idx_items"
},
"dest": {
"index": "idx_items_temp"
}
}
- 集群开启自动分片(shard allocation):
PUT _cluster/settings
{
"persistent":{
"cluster.routing.allocation.enable": "all",
"cluster.routing.rebalance.enable": "all",
}
}
- 降低副本数为0
PUT idx_items/_settings
{
"number_of_replicas": 0
}
3.3 手动分片迁移
- 集群开启分片平衡(shard rebalance):
PUT _cluster/settings
{
"persistent":{
"cluster.routing.allocation.enable": "all",
"cluster.routing.rebalance.enable": "none",
}
}
- 降低副本数为0
PUT idx_items/_settings
{
"number_of_replicas": 0
}
- 手动分片迁移
从节点名称为node-1迁移到节点名称node-2,迁移的分片为0.
POST /_cluster/reroute
{
"commands": [
{
"move":{
"index": "idx_items",
"shard": 0,
"from_node": "node-1",
"to_node": "node-2"
}
}
]
}