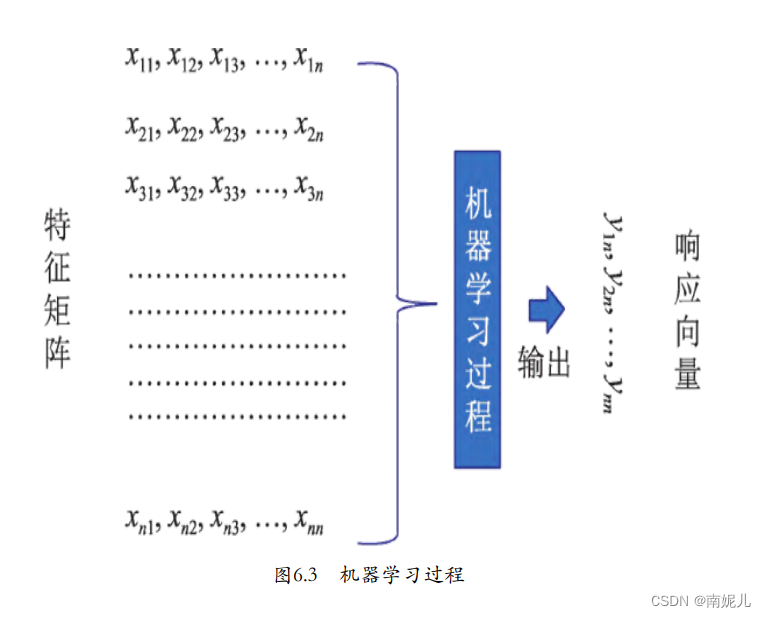
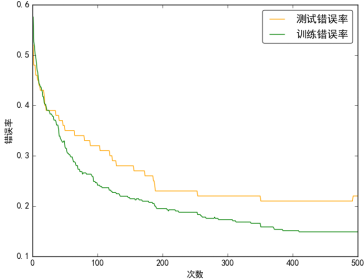
机器学习根据输出的类型一般分为两类,分类和回归。分类的输出一般是离散值,回归输出的值一般是连续的。比如,人脸识别这种就属于分类问题,房价预测一般是一个回归问题。
鸢尾花分类
# -*- coding: UTF-8 -*-
# 导入数据集
from sklearn.datasets import load_iris
iris = load_iris()
# 标签,和特征
X = iris.data
y = iris.target
print('标签的特征维度',X.shape)
# 将数据集分为训练集,测试集
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.4, random_state=1)
# 定义模型并且训练
from sklearn.naive_bayes import GaussianNB
gnb = GaussianNB()
gnb.fit(X_train, y_train)
# 进行预测
y_pred = gnb.predict(X_test)
# 模型预测的准确度
from sklearn import metrics
print("Gaussian Naive Bayes model accuracy(in %):", metrics.accuracy_score(y_test, y_pred)*100)











![【寒假每日一题】洛谷 P1079 [NOIP2012 提高组] Vigenère 密码](https://img-blog.csdnimg.cn/07643aeda095441aaea334d2c5cbae90.png)