松弛方法
- 学习准则
- 在感知函数准则中, 目标函数中采用了 − a T y -\mathbf{a}^T \mathbf{y} −aTy 的形式。实际上有很多其它准则也可以用于感知函数的学习。
- 线性准则
J p ( a ) = ∑ y ∈ Y ( − a T y ) J_p(\mathbf{a})=\sum_{\mathbf{y} \in Y}\left(-\mathbf{a}^T \mathbf{y}\right) Jp(a)=y∈Y∑(−aTy) - 平方准则
J q ( a ) = ∑ y ∈ Y ( a T y ) 2 J_q(\mathbf{a})=\sum_{\mathbf{y} \in Y}\left(\mathbf{a}^T \mathbf{y}\right)^2 Jq(a)=y∈Y∑(aTy)2 - 松弛准则
J r ( a ) = 1 2 ∑ y ∈ Y ( a T y − b ) 2 ∥ y ∥ 2 J_r(\mathbf{a})=\frac{1}{2} \sum_{\mathbf{y} \in Y} \frac{\left(\mathbf{a}^T \mathbf{y}-b\right)^2}{\|\mathbf{y}\|^2} Jr(a)=21y∈Y∑∥y∥2(aTy−b)2 - 线性准则的目标函数是分段线性的, 因此其梯度是不连续的。
- 平方准则的梯度是连续的, 但目标函数过于平滑, 收敛速度很慢(达到目标函数为零的区域的路径很平缓)。同时, 目标函数过于受到最长样本的影响。
-
J
r
(
a
)
J_r(\mathrm{a})
Jr(a) 则避免了这些缺点。
J
r
J_r
Jr (a) 最终达到零。此时对所有的
y
,
a
T
y
>
b
\mathbf{y}, \mathbf{a}^T \mathbf{y}>b
y,aTy>b, 则意味着集合
Y
Y
Y 是空集。
梯度:
∂ J r ( a ) ∂ a = ∑ y ∈ Y a T y − b ∥ y ∥ 2 y \frac{\partial J_r(\mathbf{a})}{\partial \mathbf{a}}=\sum_{\mathbf{y} \in Y} \frac{\mathbf{a}^T \mathbf{y}-b}{\|\mathbf{y}\|^2} \mathbf{y} ∂a∂Jr(a)=y∈Y∑∥y∥2aTy−by
权重更新准则:
a k + 1 = a k − η k ∑ y ∈ Y a T y − b ∥ y ∥ 2 y \mathbf{a}_{k+1}=\mathbf{a}_k-\eta_k \sum_{\mathbf{y} \in Y} \frac{\mathbf{a}^T \mathbf{y}-b}{\|\mathbf{y}\|^2} \mathbf{y} ak+1=ak−ηky∈Y∑∥y∥2aTy−by

- 每一步权重更新都要重新计算错误样本集,而且要用到错误样本集里面的所有样本
- 单样本松弛算法更新准则
a k + 1 = a k − η k a k T y k − b ∥ y k ∥ 2 y k = a k − η k a k T y k − b ∥ y k ∥ y k ∥ y k ∥ \mathbf{a}_{k+1}=\mathbf{a}_k-\eta_k \frac{\mathbf{a}_k^T \mathbf{y}^k-b}{\left\|\mathbf{y}^k\right\|^2} \mathbf{y}^k=\mathbf{a}_k-\eta_k \frac{\mathbf{a}_k^T \mathbf{y}^k-b}{\left\|\mathbf{y}^k\right\|} \frac{\mathbf{y}^k}{\left\|\mathbf{y}^k\right\|} ak+1=ak−ηk∥yk∥2akTyk−byk=ak−ηk∥yk∥akTyk−b∥yk∥yk



- 单样本松弛法的收敛性(设
a
\mathbf{a}
a 是一个解向量, 因此对任意
y
i
\mathbf{y}_i
yi, 有
a
T
y
i
>
b
\mathbf{a}^T \mathbf{y}_i>b
aTyi>b)
∥ a k + 1 − a ∥ 2 = ∥ a k − a ∥ 2 − 2 η b − a k T y k ∥ y k ∥ 2 ( a − a k ) T y k + η 2 ( b − a k T y k ) 2 ∥ y k ∥ 2 ( a − a k + 1 ) T y k = a T y k − a k + 1 T y k > b − a k + 1 T y k ⇒ ∥ a k + 1 − a ∥ 2 < ∥ a k − a ∥ 2 − η ( 2 − η ) ( b − a k T y k ) 2 ∥ y k ∥ 2 \begin{gathered} \left\|\mathbf{a}_{k+1}-\mathbf{a}\right\|^2=\left\|\mathbf{a}_k-\mathbf{a}\right\|^2-2 \eta \frac{b-\mathbf{a}_k^T \mathbf{y}^k}{\left\|\mathbf{y}^k\right\|^2}\left(\mathbf{a}-\mathbf{a}_k\right)^T \mathbf{y}^k+\eta^2 \frac{\left(b-\mathbf{a}_k^T \mathbf{y}^k\right)^2}{\left\|\mathbf{y}^k\right\|^2} \\ \quad\left(\mathbf{a}-\mathbf{a}_{k+1}\right)^T \mathbf{y}^k=\mathbf{a}^T \mathbf{y}^k-\mathbf{a}_{k+1}^T \mathbf{y}^k>b-\mathbf{a}_{k+1}^T \mathbf{y}^k \\ \Rightarrow \quad\left\|\mathbf{a}_{k+1}-\mathbf{a}\right\|^2<\left\|\mathbf{a}_k-\mathbf{a}\right\|^2-\eta(2-\eta) \frac{\left(b-\mathbf{a}_k^T \mathbf{y}^k\right)^2}{\left\|\mathbf{y}^k\right\|^2} \end{gathered} ∥ak+1−a∥2=∥ak−a∥2−2η∥yk∥2b−akTyk(a−ak)Tyk+η2∥yk∥2(b−akTyk)2(a−ak+1)Tyk=aTyk−ak+1Tyk>b−ak+1Tyk⇒∥ak+1−a∥2<∥ak−a∥2−η(2−η)∥yk∥2(b−akTyk)2
如果 0 < η < 2 0<\eta<2 0<η<2,则 ∥ a k + 1 − a ∥ 2 < ∥ a k − a ∥ 2 \left\|\mathbf{a}_{k+1}-\mathbf{a}\right\|^2<\left\|\mathbf{a}_k-\mathbf{a}\right\|^2 ∥ak+1−a∥2<∥ak−a∥2
最小平方误差(MSE)准则函数
- 对两类分类问题, 感知准则函数是寻找一个解向量 a , \mathbf{a ,} a,, 对所有样本 y i \mathbf{y}_i yi, 满足 a T y i > 0 , i = 1 , 2 , … n \mathbf{a}^T \mathbf{y}_i>0, i=1,2, \ldots n aTyi>0,i=1,2,…n 。或者说, 求解一个不等式组, 使满足 a T y i > 0 \mathbf{a}^T \mathbf{y}_i>0 aTyi>0 的数目最大, 从而错分样本最少。
- 将不等式约束改为等式:
a T y i = b i > 0 \mathbf{a}^T \mathbf{y}_i=b_i>0 aTyi=bi>0
其中, b i b_i bi 是任意给定的正常数, 通常取 b i = 1 b_i=1 bi=1, 或者 b i = b_i= bi= n j / n n_j / n nj/n 。 其中 n j , j = 1 n_j, j=1 nj,j=1或 2 2 2, 为属于第 j j j 类样本的总数, 且 n 1 + n 2 = n n_1+n_2=n n1+n2=n - 可得一个线性方程组
Y
a
=
b
\mathbf{Y a}=\mathbf{b}
Ya=b
( y 10 y 11 ⋯ y 1 d y 20 y 21 ⋯ y 2 d ⋮ ⋮ ⋮ ⋮ ⋮ ⋮ y n 0 y n 1 ⋯ y n d ) ( a 0 a 1 ⋮ ⋮ a d ) = ( b 1 b 2 ⋮ ⋮ b d ) \left(\begin{array}{cccc} y_{10} & y_{11} & \cdots & y_{1 d} \\ y_{20} & y_{21} & \cdots & y_{2 d} \\ \vdots & \vdots & & \vdots \\ \vdots & \vdots & & \vdots \\ y_{n 0} & y_{n 1} & \cdots & y_{n d} \end{array}\right)\left(\begin{array}{c} a_0 \\ a_1 \\ \vdots \\ \vdots \\ a_d \end{array}\right)=\left(\begin{array}{c} b_1 \\ b_2 \\ \vdots \\ \vdots \\ b_d \end{array}\right) y10y20⋮⋮yn0y11y21⋮⋮yn1⋯⋯⋯y1dy2d⋮⋮ynd a0a1⋮⋮ad = b1b2⋮⋮bd - 如果 Y \mathbf{Y} Y 可逆, 则 a = Y − 1 b \mathbf{a}=\mathbf{Y}^{-1} \mathbf{b} a=Y−1b
- 但通常情形下样本数远大于特征数 n ≫ d + 1 n \gg d+1 n≫d+1, 求不出逆矩阵;因此考虑定义一个误差向量 e = Y a − b \mathbf{e}=\mathbf{Y a}-\mathbf{b} e=Ya−b, 并使误差向量最小
- 平方误差准则函数:
J s ( a ) = ∥ e ∥ 2 = ∥ Y a − b ∥ 2 = ∑ i = 1 n ( a T y i − b i ) 2 J_s(\mathbf{a})=\|\mathbf{e}\|^2=\|\mathbf{Y} \mathbf{a}-\mathbf{b}\|^2=\sum_{i=1}^n\left(\mathbf{a}^T \mathbf{y}_i-b_i\right)^2 Js(a)=∥e∥2=∥Ya−b∥2=i=1∑n(aTyi−bi)2
求偏导数:
∂ J s ( a ) ∂ a = ∑ i = 1 n 2 ( a T y i − b i ) y i = 2 Y T ( Y a − b ) \frac{\partial J_s(\mathbf{a})}{\partial \mathbf{a}}=\sum_{i=1}^n 2\left(\mathbf{a}^T \mathbf{y}_i-b_i\right) \mathbf{y}_i=2 \mathbf{Y}^T(\mathbf{Y} \mathbf{a}-\mathbf{b}) ∂a∂Js(a)=i=1∑n2(aTyi−bi)yi=2YT(Ya−b)
令偏导数为 0 0 0
Y T Y a = Y T b , ⇒ a = ( Y T Y ) − 1 Y T b = Y + b \mathbf{Y}^T \mathbf{Y} \mathbf{a}=\mathbf{Y}^T \mathbf{b}, \quad \Rightarrow \mathbf{a}=\left(\mathbf{Y}^T \mathbf{Y}\right)^{-1} \mathbf{Y}^T \mathbf{b}=\mathbf{Y}^{+} \mathbf{b} YTYa=YTb,⇒a=(YTY)−1YTb=Y+b
矩阵论告诉我们 Y T Y \mathbf{Y}^T \mathbf{Y} YTY 一定是可逆的(我记得是在值空间零空间那边,但是我已经忘了ಥ_ಥ); Y + \mathbf{Y}^{+} Y+即为 Y \mathbf{Y} Y 的伪逆,实际计算常用(不知道为什么)
Y + ≈ ( Y T Y + ε I ) − 1 Y T ∣ ε → 0 \left.\mathbf{Y}^{+} \approx\left(\mathbf{Y}^T \mathbf{Y}+\varepsilon \mathbf{I}\right)^{-1} \mathbf{Y}^T\right|_{\varepsilon \rightarrow 0} Y+≈(YTY+εI)−1YT ε→0 - 计算伪逆需要求矩阵的逆, 计算复杂度高。如果原始样本的维数很高, 比如 d > 5000 d>5000 d>5000, 将十分耗时
- 采用梯度下降法: a k + 1 = a k + η k Y T ( b − Y a k ) \mathbf{a}_{k+1}=\mathbf{a}_k+\eta_k \mathbf{Y}^T\left(\mathbf{b}-\mathbf{Y} \mathbf{a}_k\right) ak+1=ak+ηkYT(b−Yak)
- 梯度下降法得到的 a k + 1 \mathbf{a}_{k+1} ak+1 将收敛于一个解, 该解满足方程: Y T ( b − Y a ) = 0 \mathbf{Y}^T (\mathbf{b}-\mathbf{Y} \mathbf{a})=\mathbf{0} YT(b−Ya)=0
- 也可以采用序列更新方法, 此方法需要的计算存储量会更小:
a k + 1 = a k + η k ( b k − ( a k ) T y k ) y k \mathbf{a}_{k+1}=\mathbf{a}_k+\eta_k\left(b_k-\left(\mathbf{a}_k\right)^T \mathbf{y}^k\right) \mathbf{y}^k ak+1=ak+ηk(bk−(ak)Tyk)yk - 序列最小平方更新方法

- Widrow-Hoff 要求更正不相等情形: ( a k ) T y k ≠ b k \left(\mathbf{a}_k\right)^T \mathbf{y}^k \neq b_k (ak)Tyk=bk 。但是, 实际上, 满足 ( a k ) T y k = b k \left(\mathrm{a}_k\right)^T \mathbf{y}^k=b_k (ak)Tyk=bk 几乎是不可能的。因此, 迭代将会无穷次进行下去。所以要求 η k \eta_k ηk 需要随着 k k k 的增加而逐渐减小, 以保证算法的收敛性。一般来讲, 实际计算中取: η k = \eta_k= ηk= η 1 / k \eta_1 / k η1/k
- 相对于感知器准则, 最小平方准则方法可能并不收敛于可分超平面, 即使该平面是存在的
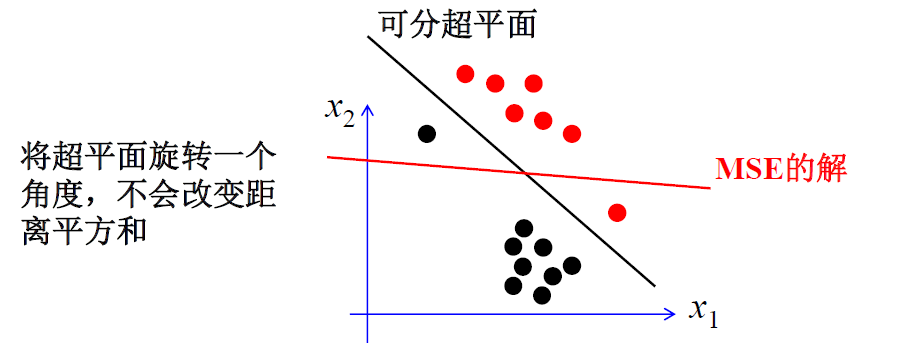
如上图,MSE的解并不能实现线性可分样本集的正确分类
Ho-Kashyap方法
- MSE算法上最小化 ∥ Y a − b ∥ 2 \|\mathbf{Y} \mathbf{a}-\mathbf{b}\|^2 ∥Ya−b∥2, 所得到的最优解并不需要位于可分超平面上
- 如果训练样本是线性可分的, 则可找到一个权向量 a \mathbf{a} a, 对所有样本, 均有 a T y i > 0 \mathbf{a}^T \mathbf{y}_i>0 aTyi>0 。换句话说, 一定存在一个 a \mathbf{a} a 和 b \mathbf{b} b, 使 Y a = b > 0 \mathbf{Y a}=\mathbf{b}>\mathbf{0} Ya=b>0
- 但是, 事先并不知道 b \mathbf{b} b 。因此, MSE准则函数可以更新为: J s ( a , b ) = ∥ Y a − b ∥ 2 J_s(\mathbf{a}, \mathbf{b})=\|\mathbf{Y} \mathbf{a}-\mathbf{b}\|^2 Js(a,b)=∥Ya−b∥2
- 直接优化 J s ( a , b ) J_s(\mathbf{a}, \mathbf{b}) Js(a,b) 将导致平凡解(都取 0 0 0 直接就结束了), 所以需要给 b \mathbf{b} b 加一个 b > 0 \mathbf{b}>\mathbf{0} b>0 的约束条件。此时 b \mathbf{b} b 可以解释为 margin
- 梯度
∂ J s ( a , b ) ∂ a = 2 Y T ( Y a − b ) , ∂ J s ( a , b ) ∂ b = − 2 ( Y a − b ) \frac{\partial J_s(\mathbf{a}, \mathbf{b})}{\partial \mathbf{a}}=2 \mathbf{Y}^T(\mathbf{Y} \mathbf{a}-\mathbf{b}), \quad \frac{\partial J_s(\mathbf{a}, \mathbf{b})}{\partial \mathbf{b}}=-2(\mathbf{Y} \mathbf{a}-\mathbf{b}) ∂a∂Js(a,b)=2YT(Ya−b),∂b∂Js(a,b)=−2(Ya−b) - 对 a \mathbf{a} a 而言, 总有 a = Y + b \mathbf{a}=\mathbf{Y}^{+} \mathbf{b} a=Y+b, 其中 Y + \mathbf{Y}^{+} Y+为 Y \mathbf{Y} Y 的伪逆 ( Y T Y ) − 1 Y T \left(\mathbf{Y}^T \mathbf{Y}\right)^{-1} \mathbf{Y}^T (YTY)−1YT
- 对
b
\mathbf{b}
b, 需要同时满足约束条件
b
>
0
\mathbf{b}>\mathbf{0}
b>0 。梯度更新:
b k + 1 = b k − η k ∂ J s ( a , b ) ∂ b \mathbf{b}_{k+1}=\mathbf{b}_k-\eta_k \frac{\partial J_s(\mathbf{a}, \mathbf{b})}{\partial \mathbf{b}} bk+1=bk−ηk∂b∂Js(a,b) - 由于
b
k
\mathbf{b}_k
bk 总是大于零, 要使
b
k
+
1
\mathbf{b}_{k+1}
bk+1 也大于零, 可以要求
∂
J
s
(
a
,
b
)
/
∂
b
\partial J_s(\mathbf{a}, \mathbf{b}) / \partial \mathbf{b}
∂Js(a,b)/∂b 为负(若
∂
J
s
(
a
,
b
)
/
∂
b
\partial J_s(\mathbf{a}, \mathbf{b}) / \partial \mathbf{b}
∂Js(a,b)/∂b 为正,括号里面为
0
0
0;若
∂
J
s
(
a
,
b
)
/
∂
b
\partial J_s(\mathbf{a}, \mathbf{b}) / \partial \mathbf{b}
∂Js(a,b)/∂b 为负,括号里面为负)
b 1 > 0 , b k + 1 = b k − η k 1 2 ( ∂ J s ( a , b ) ∂ b − ∣ ∂ J s ( a , b ) ∂ b ∣ ) \mathbf{b}_1>\mathbf{0}, \quad \mathbf{b}_{k+1}=\mathbf{b}_k-\eta_k \frac{1}{2}\left(\frac{\partial J_s(\mathbf{a}, \mathbf{b})}{\partial \mathbf{b}}-\left|\frac{\partial J_s(\mathbf{a}, \mathbf{b})}{\partial \mathbf{b}}\right|\right) b1>0,bk+1=bk−ηk21(∂b∂Js(a,b)− ∂b∂Js(a,b) ) -
∂
J
s
(
a
,
b
)
∂
b
=
−
2
(
Y
a
−
b
)
\frac{\partial J_s(\mathbf{a}, \mathbf{b})}{\partial \mathbf{b}}=-2(\mathbf{Y} \mathbf{a}-\mathbf{b})
∂b∂Js(a,b)=−2(Ya−b),并记
e
k
+
=
1
2
(
(
Y
a
k
−
b
k
)
+
∣
Y
a
k
−
b
k
∣
)
\mathbf{e}_k^{+}=\frac{1}{2}\left(\left(\mathbf{Y} \mathbf{a}_k-\mathbf{b}_k\right)+\left|\mathbf{Y} \mathbf{a}_k-\mathbf{b}_k\right|\right)
ek+=21((Yak−bk)+∣Yak−bk∣),则有
a k = Y + b k b 1 > 0 , b k + 1 = b k + 2 η k e k + \begin{gathered} \mathbf{a}_k=\mathbf{Y}^{+} \mathbf{b}_k \\ \mathbf{b}_1>\mathbf{0}, \quad \mathbf{b}_{k+1}=\mathbf{b}_k+2 \eta_k \mathbf{e}_k^{+} \end{gathered} ak=Y+bkb1>0,bk+1=bk+2ηkek+ - 为了防止 b \mathbf{b} b 收敛于 0 \mathbf{0} 0, 可以让 b \mathbf{b} b 从一个非负向量 ( b 1 > 0 ) \left(\mathbf{b}_1>\mathbf{0}\right) (b1>0) 开始进行更新
- 由于要求
∂
J
s
(
a
,
b
)
/
∂
b
\partial J_s(\mathbf{a}, \mathbf{b}) / \partial \mathbf{b}
∂Js(a,b)/∂b 等于
0
\mathbf{0}
0, 在开始迭代时可令
∂
J
s
(
a
,
b
)
/
∂
b
\partial J_s(\mathbf{a}, \mathbf{b}) / \partial \mathbf{b}
∂Js(a,b)/∂b 的元素为正的分量等于零, 从而加快收敛速度。

- 由于权向量序列 { a k } \left\{\mathbf{a}_k\right\} {ak} 完全取决定于 { b k } \left\{\mathbf{b}_k\right\} {bk}, 因此本质上讲 Ho-Kashyap 算法是一个生成margin 序列 { b k } \left\{\mathbf{b}_k\right\} {bk} 的方法
- 由于初始 b 1 > 0 \mathbf{b}_1>\mathbf{0} b1>0, 且更新因子 η > 0 \eta>0 η>0, 因此 b k \mathbf{b}_k bk 总是大于 0 \mathbf{0} 0
- 对于更新因子 0 < η ≤ 1 0<\eta \leq 1 0<η≤1, 如果问题线性可分, 则总能找到元素全为正的 b b b (不懂)
- 如果 e k = Y a k − b k \mathbf{e}_k=\mathbf{Y} \mathbf{a}_k-\mathbf{b}_k ek=Yak−bk 全为 0 , 此时, b k \mathbf{b}_k bk 将不再更新, 因此获得一个解。如果 e k \mathrm{e}_k ek 有一部分元素小于 0 , 则可以证明该问题不是线性可分的 (不懂)