由于小波在应用形式上与卷积很相似,所以如果你有需要,可以查看我以前写过的内容:
- 信号采样基本概念 —— 冲激函数
- 卷积计算——1. 关于卷积的基本概念
- 卷积计算——2. 一些常用于图像的卷积核与应用
另外常见的信号处理工具,傅里叶变化,可以查看以下章节:
- 浅谈傅里叶——1. 从无穷级数到欧拉公式
- 浅谈傅里叶——2. 连续傅里叶公式推导与三角函数正交性
- 浅谈傅里叶——3. 傅立叶收敛性证明与非周期信号的推广
- 浅谈傅里叶——4. 傅里叶的特点分析与短时傅里叶
- 浅谈傅里叶——5. 短时傅里叶的缺点与卷积的基本概念
- 浅谈傅里叶——5. 短时傅里叶的缺点与卷积的基本概念
- 浅谈傅里叶——6. 采样、频率与一个简易的DFT函数
- 浅谈傅里叶——7. 带有相位信息的一维DFT实现方法
- 浅谈傅里叶——8. 一维iDFT的实现
文章目录
- Haar小波的基本实现原理
- 代码实现
- Haar小波分解过程
- Haar小波复原过程
- 比较结果
- 一些其他实现手段
Haar小波的基本实现原理
小波分析是一种数学方法,用于分析和处理时间序列数据。 它的基本思想是将时间序列数据分解为多个不同尺度的部分,以便在分解后的每个尺度上更好地理解数据的特征。
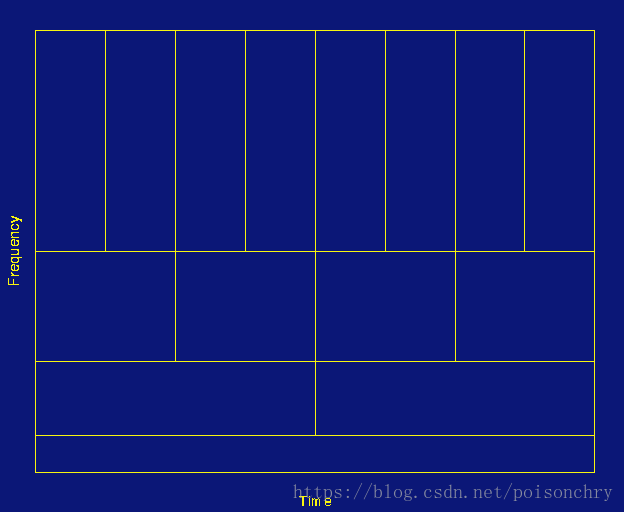
其中一种常用的小波变换方法是Haar小波变换。 Haar小波变换是一种离散小波变换,它可以将时间序列数据分解为近似信息和细节信息。 近似信息是数据的一个粗略的表示,细节信息包含数据的细微差别。 这样,在分解后的不同尺度上分析数据可以得到更清晰的视图。
通常,Haar小波变换是一种递归算法,可以对数据进行多次变换。 在每次变换中,它将数据分成相邻的对,并计算每对的平均值和差值。 平均值是近似信息,差值是细节信息。 这两个信息都保存在列表中。 接下来,程序将使用近似信息作为下一次变换的输入。
在多次变换后,Haar小波变换将生成一组近似信息和细节信息的列表。 列表中的每个元素都对应于不同的尺度。 这些信息可以用于分析数据的不同特征。
与Haar小波变换相对应的是Haar小波逆变换。 这种逆变换可以将Haar小波变换分解后的信息合并成原始时间序列数据。 它使用相同的递归算法,但是它是将信息合并而不是分离。
代码实现
Haar小波分解过程
现在让我们来看看给出的代码。 首先,定义了一个名为discrete_wavelet_transform的函数,该函数接受两个参数:数据列表和深度。 深度表示要进行多少次变换。
函数开始执行时,首先限制深度为所需的变换数量,以将整个数据列表转换为整数。 然后初始化一个空列表,用于存储不同尺度的细节信息。
def discrete_wavelet_transform(data, depth):
# Haar Discrete Wavelet Transform, depth passes
depth = min(int(math.log2(len(data))), depth) # Limit depth to the number of passes needed to transform the entire data list
details = [] # Initialize empty list to store details at different scales
# Loop through the number of passes
for d in range(depth):
# Initialize empty lists for approximations and details for the current pass
approximations, details_for_pass = [], []
# Loop through data by pairs of values
for i in range(0, len(data), 2):
# Append the average of the pair to the list of approximations
approximations.append(sum(data[i:i+2]) / 2)
# Append the difference between the first value of the pair and the average to the list of details
details_for_pass.append(data[i] - approximations[-1])
# Add current details to the beginning of the list
details = details_for_pass + details
# Replace data with approximations for the next pass
data = approximations
return approximations, details # Return approximations and details at different scales
接下来,开始一个循环,循环次数为深度。 在循环的每次迭代中,都会初始化一个近似信息列表和当前循环的细节信息列表。 然后,开始另一个循环,循环次数为数据列表的长度,每次循环都会跳过两个值。 在循环的每次迭代中,都会计算对的平均值并将其添加到近似信息列表中,并将对的第一个值与平均值之差添加到细节信息列表中。
在当前循环结束后,将当前细节信息添加到细节信息列表的开头。 然后用近似信息替换数据列表,以便进行下一次变换。
Haar小波复原过程
接下来是另一个函数,名为inverse_discrete_wavelet_transform,它接受近似信息和细节信息列表作为参数。 该函数执行Haar小波逆变换,并返回原始时间序列数据。
def inverse_discrete_wavelet_transform(approximations, details):
# Haar Inverse Discrete Wavelet Transform, depth passes
N = len(approximations + details) # Calculate length of original data
sums = [sum([[k] * (N // len(approximations)) for k in approximations], [])] # Initialize a list of sums with approximations
bs, i = N // 2, 0 # Initialize block size and index
# Loop until block size becomes 0 or all details have been processed
while bs > 0 and i < len(details):
# Initialize a list of values for the current block of details
values = []
# Loop through the current block of details
for a in details[::-1][i:i+bs]:
# Append alternating negative and positive values to the list of values
values.extend([-a] * (N // (2 * bs)))
values.extend([a] * (N // (2 * bs)))
# Reverse the list of values and add it to the list of sums
sums.append(values[::-1])
# Move to the next block of details
i += bs
# Divide block size by 2
bs //= 2
# Calculate reconstructed data by summing values at each index in list of sums
rec_data = [sum([s[j] for s in sums]) for j in range(N)]
return rec_data # Return reconstructed data
首先计算原始数据的长度,然后将近似信息和细节信息放在一个列表中。 然后初始化一个和的列表,并将近似信息添加到该列表中。 初始化块大小并将其设置为原始数据的一半,并初始化索引。
然后进入一个循环,循环将持续到块大小为0或处理完所有细节信息为止。 在每次循环迭代中,都会初始化一个值列表,用于存储当前块的细节信息。 然后进入另一个循环,循环次数为当前块的细节信息。 在循环的每次迭代中,都会将负值和正值的序列分别添加到值列表中。 这些值列表的大小都是原始数据的一半除以当前块的大小。
然后将值列表翻转,并将其添加到和的列表中。 接下来,将索引设置为当前块的细节信息数量,并将块大小除以2。
最后,计算原始时间序列数据的重建数据。 这是通过对和的列表中的每个索引的值求和来实现的。
比较结果
接下来相对比较简单,首先生成了一个具有1024个样本的正弦波。 然后调用discrete_wavelet_transform函数,将数据列表和10(即要进行的变换次数)作为参数。
接下来,调用inverse_discrete_wavelet_transform函数,将获得的近似信息和细节信息作为参数。
最后,在主函数的循环中,打印出原始数据和重建数据的每对值。
def main():
# generate a sin(x) for a sine wave
signal = [math.sin(math.pi * float(i)/100.0) for i in range(100)]
# Apply the DWT to the data with a depth of 8
approx, details = discrete_wavelet_transform(signal, 2)
# Reconstruct the original data from the approximations and details
r_signal = inverse_discrete_wavelet_transform(approx, details)
# compare the reconstructed data with the original data
for i in range(len(signal)):
# print the original data and the reconstructed data and keep the output to 2 decimal places
print('{:.2f} {:.2f}'.format(signal[i], r_signal[i]))
if __name__ == '__main__':
main() # Call the main function
一些其他实现手段
其他小波的计算过程有很多相似地方,而Haar显然是最简单的一种方式。不过在弄明白Haar小波的基础上是很容易开发出其他小波分解。一些最常见的小波分解方法包括 小波包分解,曲线小波分解 和 小波变换。 这些方法都有其自己的优势和缺点,并且在实现上有所不同。
小波包分解是一种常用的小波分解方法,其中使用可以选择的基小波进行变换。 这些基小波有不同的性质,可以更好地分离不同类型的信息。 小波包分解通常使用数学公式来实现。
曲线小波分解是另一种常见的小波分解方法,它使用曲线拟合来提取信息。 这种方法可以用于分离带有连续曲线的信息。 曲线小波分解通常使用数学公式来实现。
小波变换是另一种常见的小波分解方法,它使用小波函数来提取信息。 小波函数是被设计用于小波变换的特殊函数。 小波变换通常使用数学公式来实现。
与Haar小波分解相比,这些方法通常更具精度,但是实现较为复杂。 Haar小波分解是一种简单而有效的小波分解方法,它使用两个宽度相等的区间来进行变换。 Haar小波分解使用简单的算术运算来实现,因此它很容易理解和实现。 然而,它的精度较低,因此在许多情况下可能不是最佳选择。
小波分解通常用于分析和重建时间序列数据。 它的原理是将时间序列数据的不同频率成分分离出来,以便可以单独分析和处理。 小波分解可以用于许多不同的应用领域,包括图像处理,信号处理,声音处理等。
所以,作为一种比FFT更先进的替代工具,熟练掌握它可以帮助研究人员更好地了解数据,并进行有意义的分析和决策。