文章目录
- 1、文件操作基本知识
- 2、Open
- 3、PathLib
- 3.1、Pathlib—path.open
- 3.2、Pathlib— pathByte.write_bytes/ pathByte.read_bytes
- 4、JSON
- 5、二进制文件操作
- 6、Excel、word
1、文件操作基本知识
按文件中数据的组织形式把文件分为文本文件和二进制文件两类。
文本文件:文本文件存储的是常规字符串,由若干文本行组成,通常每行以换行符’\n’结尾。常规字符串是指记事本或其他文本编辑器能正常显示、编辑并且人类能够直接阅读和理解的字符串,如英文字母、汉字、数字字符串。文本文件可以使用字处理软件如gedit、记事本进行编辑。
二进制文件:二进制文件把对象内容以字节串(bytes)进行存储,无法用记事本或其他普通字处理软件直接进行编辑,通常也无法被人类直接阅读和理解,需要使用专门的软件进行解码后读取、显示、修改或执行。常见的如图形图像文件、音视频文件、可执行文件、资源文件、各种数据库文件、各类office文档等都属于二进制文件。
无论是文本文件还是二进制文件,其操作流程基本都是一致的,首先打开文件并创建文件对象,然后通过该文件对象对文件内容进行读取、写入、删除、修改等操作,最后关闭并保存文件内容。
open(file, mode='r', buffering=-1, encoding=None, errors=None,
newline=None, closefd=True, opener=None)
file参数指定了被打开的文件名称。
mode参数指定了打开文件后的处理方式。
buffering参数指定了读写文件的缓存模式。0表示不缓存,1表示缓存,如大于1则表示缓冲区的大小。默认值是缓存模式。
encoding参数指定对文本进行编码和解码的方式,只适用于文本模式,可以使用Python支持的任何格式,如GBK、utf8、CP936等等。Windows操作系统下默认编码cp936

2、Open
如果执行正常,open()函数返回1个文件对象,通过该文件对象可以对文件进行读写操作。如果指定文件不存在、访问权限不够、磁盘空间不足或其他原因导致创建文件对象失败则抛出异常。
f1 = open( 'file1.txt', 'r' ) # 以读模式打开文件
f2 = open( 'file2.txt', 'w') # 以写模式打开文件
当对文件内容操作完以后,一定要关闭文件对象,这样才能保证所做的任何修改都确实被保存到文件中。
f1.close()
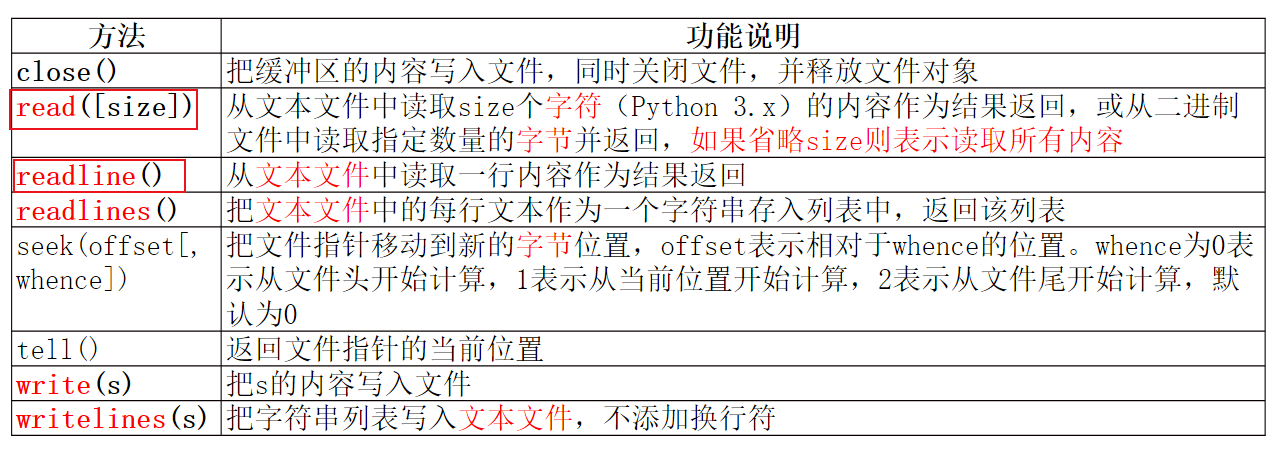
使用with语句块自动关闭资源。在实际开发中,读写文件应优先考虑使用上下文管理语句with。关键字with可以自动管理资源,不论因为什么原因(哪怕是代码引发了异常)跳出with块,总能保证文件被正确关闭,资源被正确释放。 with语句块可以在代码块执行完毕后自动还原进入该代码块时的上下文。 with语句块常用于文件操作、数据库连接、网络连接、多线程与多进程同步时的锁对象管理等场合。
with context_expr [as var]:
with块
例如:
with open(filename, mode, encoding) as fp:
#这里写通过文件对象fp读写文件内容的语句
上下文管理语句with还支持下面的用法:
with open('test.txt', 'r') as src, open('test_new.txt', 'w') as dst:
dst.write(src.read())
示例1 向文本文件中写入内容,然后再读出。
s = 'Hello world\n文本文件的读取方法\n文本文件的写入方法\n'
with open('sample.txt', 'w') as fp: #默认使用cp936编码
fp.write(s)
with open('sample.txt',encoding= 'gbk') as fp: #默认使用cp936编码
print(fp.read())
示例2 假设文件data.txt中有若干整数,所有整数之间使用英文逗号分隔,编写程序读取所有整数,将其按升序排序后再写入文本文件data_asc.txt中。
with open('data.txt', 'r') as fp:
data = fp.readlines() #读取所有行
data = [line.strip() for line in data] #删除每行两侧的空白字符
data = ','.join(data) #合并所有行
data = data.split(',') #分隔得到所有数字字符串
data = [int(item) for item in data] #转换为数字
data.sort(key=int) #升序排序
data = ','.join(map(str,data)) #将结果转换为字符串
with open('data_asc.txt', 'w') as fp: #将结果写入文件
fp.write(data)
3、PathLib
利用Python 标准库 pathlib 模块,可以在各种操作系统中处理文件和目录
不但可以读写文件内容(包括二进制文件),还可以管理文件,以及管理目录
# file_reader.py
from pathlib import Path
path = Path('reading_from_a_file/pi_digits.txt')
contents = path.read_text()
print(contents.rstrip())
from pathlib import Path
path = Path('reading_from_a_file/pi_million_digits.txt')
contents = path.read_text()
lines = contents.splitlines()
pi_string = ''
for line in lines:
pi_string += line.strip()
print(f"{pi_string[:52]}...")
# print(pi_string)
print(len(pi_string))
from pathlib import Path
# path = Path('pi_digits.txt')
path = Path('reading_from_a_file/pi_million_digits.txt')
contents = path.read_text()
lines = contents.splitlines()
pi_string = ''
for line in lines:
pi_string += line.lstrip()
birthday = input("Enter your birthday, in the form mmddyy: ")
if birthday in pi_string:
print("Your birthday appears in the first million digits of pi!")
else:
print("Your birthday does not appear in the first million digits of pi.")
from pathlib import Path
contents = "I love programming.\n"
contents += "I love creating new games.\n"
contents += "I also love working with data.\n"
path = Path('programming.txt')
path.write_text(contents)
3.1、Pathlib—path.open
from pathlib import Path
currentPath = Path.cwd()
path = currentPath / 'python-100.txt'
with path.open('w') as f: # 创建并以 "w" 格式打开 python-100.txt 文件。
f.write('python-100') # 写入 python-100 字符串。
# Path.open(mode='r'),以 "r" 格式打开 Path 路径下的文件,若文件不存在即创建后打开
f = open(path, 'r')
print("读取的文件内容为:%s" % f.read())
f.close()
3.2、Pathlib— pathByte.write_bytes/ pathByte.read_bytes
from pathlib import Path
currentPath = Path.cwd()
str2byte = bytes('python-100', encoding = 'utf-8')
pathByte = currentPath / 'python-100-byte.txt'
# Path.write_bytes(),对 Path 路径下的文件进行写操作,等同 open 操作文件的 "wb" 格式
pathByte.write_bytes(str2byte)
# Path.read_bytes(),打开 Path 路径下的文件,以字节流格式读取文件内容,等同 open 操作文件的 "rb" 格式
print("读取的文件内容为:%s" % pathByte.read_bytes().decode('utf-8'))
Pathlib同样可以读写二进制文件,相关内容在后面介绍
4、JSON
JSON(JavaScript Object Notation)是一种轻量级的数据交换格式,广泛用于将数据从一个应用程序传输到另一个应用程序。它基于JavaScript语言的一个子集,但已成为跨编程语言和平台的通用数据格式。
JSON数据由键值对组成,类似于Python中的字典。
当处理JSON数据时,Python中的 json模块提供了四个主要的函数:dump、load和 dumps、 loads。这些函数提供了在JSON数据和Python对象之间进行转换和序列化的功能。
import json
data = {'name': 'ZhangSan', 'age': 30, 'city': 'ShenZhen'}
# dump函数用于将Python对象序列化为JSON,并将其写入文件对象
# 它接受两个参数:要序列化的对象和目标文件对象
with open('data.json', 'w') as f:
json.dump(data, f)
# load函数用于从JSON文件中读取数据,并将其解析为Python对象
# 它接受一个参数:要读取的文件对象
with open('data.json', 'r') as f:
data = json.load(f)
print(data)
from pathlib import Path
import json
numbers = [2, 3, 5, 7, 11, 13]
path = Path('numbers.json')
contents = json.dumps(numbers)
path.write_text(contents)
from pathlib import Path
import json
path = Path('numbers.json')
contents = path.read_text()
numbers = json.loads(contents)
print(numbers)
# remember_me.py
from pathlib import Path
import json
path = Path('username.json')
if path.exists():
contents = path.read_text()
username = json.loads(contents)
print(f"Welcome back, {username}!")
else:
username = input("What is your name? ")
contents = json.dumps(username)
path.write_text(contents)
print(f"We'll remember you when you come back, {username}!")
5、二进制文件操作
数据库文件、图像文件、可执行文件、动态链接库文件、音频文件、视频文件、Office文档等均属于二进制文件。
对于二进制文件,不能使用记事本或其他文本编辑软件直接进行正常读写,也不能通过Python的文件对象直接读取和理解二进制文件的内容。必须正确理解二进制文件结构和序列化规则,然后设计正确的反序列化规则,才能准确地理解二进制文件内容。
所谓序列化,简单地说就是把内存中的数据在不丢失其类型信息的情况下转成二进制形式的过程,对象序列化后的数据经过正确的反序列化过程应该能够准确无误地恢复为原来的对象。
Python中常用的序列化模块有pickle、struct、shelve、marshal。
示例1 使用pickle模块写入二进制文件。
import pickle
i = 13000000
a = 99.056
s = '中国人民 123abc'
lst = [[1, 2, 3], [4, 5, 6], [7, 8, 9]]
tu = (-5, 10, 8)
coll = {4, 5, 6}
dic = {'a':'apple', 'b':'banana', 'g':'grape', 'o':'orange'}
data = (i, a, s, lst, tu, coll, dic)
with open('sample_pickle.dat', 'wb') as f:
try:
pickle.dump(len(data), f) #要序列化的对象个数
for item in data:
pickle.dump(item, f) #序列化数据并写入文件
except:
print('写文件异常')
示例2 使用struct模块写入二进制文件。
import struct
n = 1300000000
x = 96.45
b = True
s = 'a1@中国'
sn = struct.pack('if?', n, x, b) #序列化,i表示整数,f表示实数,?表示逻辑值
with open('sample_struct.dat', 'wb') as f:
f.write(sn)
f.write(s.encode()) #字符串需要编码为字节串再写入文件
with open('sample_struct.dat', 'rb') as f:
sn = f.read(9)
tu = struct.unpack('if?', sn) #使用指定格式反序列化
n, x, b1 = tu #序列解包
print('n=',n, 'x=',x, 'b1=',b1)
s = f.read(9)
s = s.decode() #字符串解码
print('s=', s)
示例3 excel读写
import openpyxl
from openpyxl import Workbook
fn = r'test.xlsx' #文件名
wb = Workbook() #创建工作簿
ws = wb.create_sheet(title='你好,世界') #创建工作表
ws['A1'] = '这是第一个单元格' #单元格赋值
ws['B1'] = 3.1415926
wb.save(fn) #保存Excel文件
wb = openpyxl.load_workbook(fn) #打开已有的Excel文件
ws = wb.worksheets[1] #打开指定索引的工作表
print(ws['A1'].value) #读取并输出指定单元格的值
ws.append([1,2,3,4,5]) #添加一行数据
ws.merge_cells('F2:F3') #合并单元格
ws['F2'] = "=sum(A2:E2)" #写入公式
for r in range(10,15):
for c in range(3,8):
ws.cell(row=r, column=c, value=r*c) #写入单元格数据
wb.save(fn)
6、Excel、word
#把data.txt转换成Excel 2007+文件。
#假设datat.txt文件中第一行为表头,
#从第二行开始是实际数据,
#并且表头和数据行中的不同字段信息都是用逗号分隔。
from openpyxl import Workbook
def main(txtFileName):
new_XlsxFileName = txtFileName[:-3] + 'xlsx'
wb = Workbook()
ws = wb.worksheets[0]
with open(txtFileName) as fp:
for line in fp:
line = line.strip().split(',')
ws.append(line)
wb.save(new_XlsxFileName)
main('data.txt')
#在word文档中,经常会由于不小心而出现连续的重复字,
#示例使用扩展库python-docx对word文档进行检查并提示
#pip install python-docx
from docx import Document
doc = Document('test.docx')
contents = ''.join((p.text for p in doc.paragraphs))
words = []
for index, ch in enumerate(contents[:-2]):
if ch==contents[index+1] or ch==contents[index+2]:
word = contents[index:index+3]
if word not in words:
words.append(word)
print(words)
#在word文档中,经常会由于不小心而出现连续的重复字,
#示例使用扩展库python-docx对word文档进行检查并提示
#pip install python-docx
import re
from docx import Document
doc = Document('test.docx')
contents = ''.join((p.text for p in doc.paragraphs))
match = re.compile(r'(.)\1+')
words=match.findall(contents)
print(words)
#pip install python-docx
from docx import Document
import re
result = {'fig':[], 'tab':[]}
doc = Document(r'test.docx')
for p in doc.paragraphs: #遍历文档所有段落
t = p.text #获取每一段的文本
if re.match('图\d+', t): #插图
result['fig'].append(t)
elif re.match('表\d+', t): #表格
result['tab'].append(t)
for key in result.keys(): #输出结果
print('='*30)
for value in result[key]:
print(value)