3. 阻塞队列与线程池
3.1 阻塞队列
阻塞:必须要阻塞/不得不阻塞
阻塞队列是一个队列,在数据结构中是先进先出
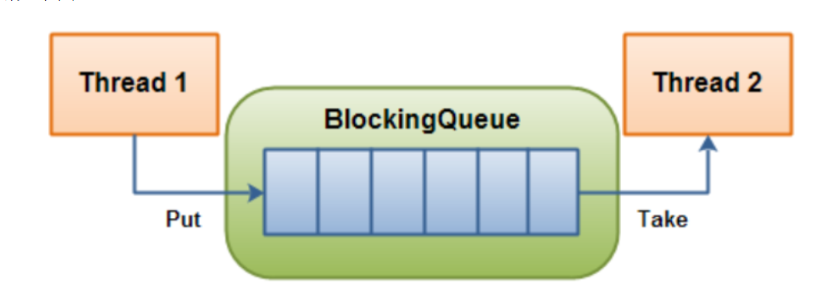
线程1往阻塞队列里添加元素,线程2从阻塞队列里移除元素。
当队列是空的,从队列中获取元素的操作将会被阻塞
当队列是满的,从队列中添加元素的操作将会被阻塞
试图从空的队列中获取元素的线程将会被阻塞,直到其他线程往空的队列插入新的元素
试图向已满的队列中添加新元素的线程将会被阻塞,直到其他线程从队列中移除一个或多个元素或者完全清空,使队列变得空闲起来并后续新增
阻塞队列用处
在多线程领域:所谓阻塞,在某些情况下会挂起线程(即阻塞),一旦条件满足,被挂起的线程又会自动被唤起。
为什么需要 BlockingQueue ?
好处是我们不需要关心什么时候需要阻塞线程,什么时候需要唤醒线程,因为这一切 BlockingQueue 都给你一手包办了。
在 concurrent 包发布以前,在多线程环境下,我们每个程序员都必须去自己控制这些细节,尤其还要兼顾效率和线程安全,而这会给我们的程序带来不小的复杂度。
阻塞队列架构
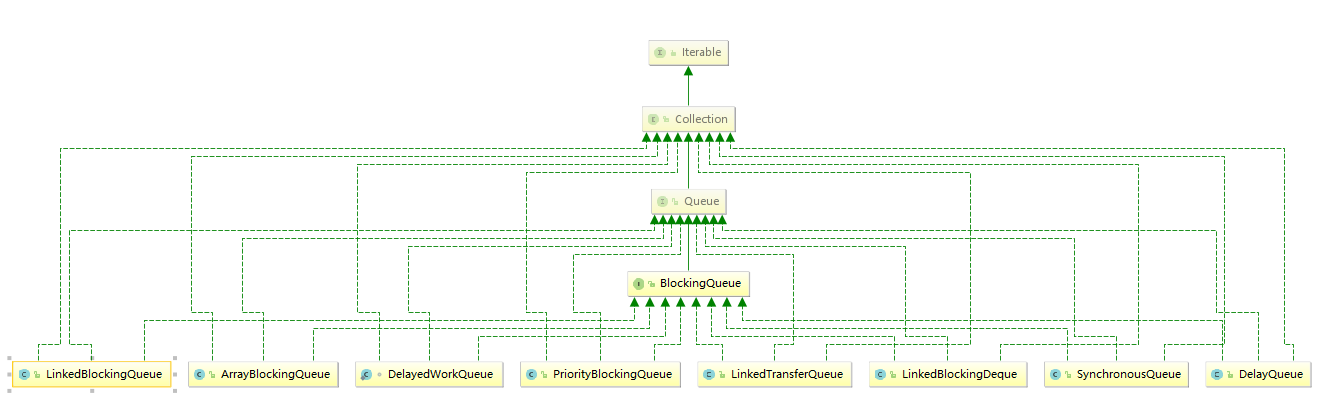
分类:
- ArrayBlockingQueue:由数组结构组成的有界阻塞队列。
- LinkedBlockingQueue:由链表结构组成的有界(但大小默认值为 Integer.MAX_VALUE )阻塞队列,吞吐量通常高于 ArrayBlockingQueue,但是慎用。
- PriorityBlockingQueue:支持优先级排序的无界阻塞队列。
- DelayQueue:使用优先级队列实现的延迟无界阻塞队列。
- SynchronousQueue:不存储元素的阻塞队列,也即单个元素的队列。每个插入操作必须等到另一个线程调用移除操作,否则插入操作一直处于阻塞状态
- LinkedTransferQueue:由链表组成的无界阻塞队列。
- LinkedBlockingDeque:由链表组成的双向阻塞队列。
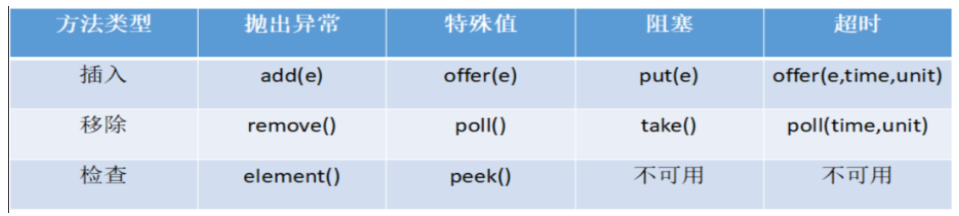
核心方法:

public static void main(String[] args) {
BlockingQueue<Integer> blockingQueue = new SynchronousQueue<>();
new Thread(() -> {
try {
System.out.println(Thread.currentThread().getName() + "\t put 1");
blockingQueue.put(1);
System.out.println(Thread.currentThread().getName() + "\t put 2");
blockingQueue.put(2);
System.out.println(Thread.currentThread().getName() + "\t put 3");
blockingQueue.put(3);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}, "AAA").start();
new Thread(() -> {
try {
TimeUnit.SECONDS.sleep(1);
System.out.println(Thread.currentThread().getName() + "\t" + blockingQueue.take());
TimeUnit.SECONDS.sleep(1);
System.out.println(Thread.currentThread().getName() + "\t" + blockingQueue.take());
TimeUnit.SECONDS.sleep(1);
System.out.println(Thread.currentThread().getName() + "\t" + blockingQueue.take());
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}, "BBB").start();
}
// 结果
AAA put 1
BBB 1
AAA put 2
BBB 2
AAA put 3
BBB 3
3.2 阻塞队列用在哪
- 生产者消费者模式
- 线程池
- 消息中间件
我们这里对生产者消费者模式进行描述,分为传统版和阻塞队列版,传统版在线程通信篇章会讲解,这里写出阻塞队列版本。
3.3 线程池
为什么使用线程池?
例子:
10年前单核 CPU 电脑,假的多线程,像马戏团小丑玩多个球,CPU 需要来回切换。现在是多核电脑,多个线程各自跑在独立的 CPU 上,不用切换效率高。
线程池的优势:
线程池做的工作只要是控制运行的线程数量,处理过程中将任务放入阻塞队列,然后在线程创建后启动这些任务,如果线程数量超过了最大数量,超出数量的线程排队等候,等其他线程执行完毕,再从队列中取出任务来执行。
它的主要特点为:线程复用;控制最大并发数;管理线程。
优点:
- **降低资源消耗。**通过重复利用已创建的线程降低线程创建和销毁造成的销耗。
- **提高响应速度。**当任务到达时,任务可以不需要等待线程创建就能立即执行。
- **提高线程的可管理性。**线程是稀缺资源,如果无限制的创建,不仅会销耗系统资源,还会降低系统的稳定性,使用线程池可以进行统一的分配,调优和监控。
线程池的架构
Java 中的线程池是通过 Executor 框架实现的,该框架中用到了 Executor,Executors,ExecutorService,ThreadPoolExecutor这几个类
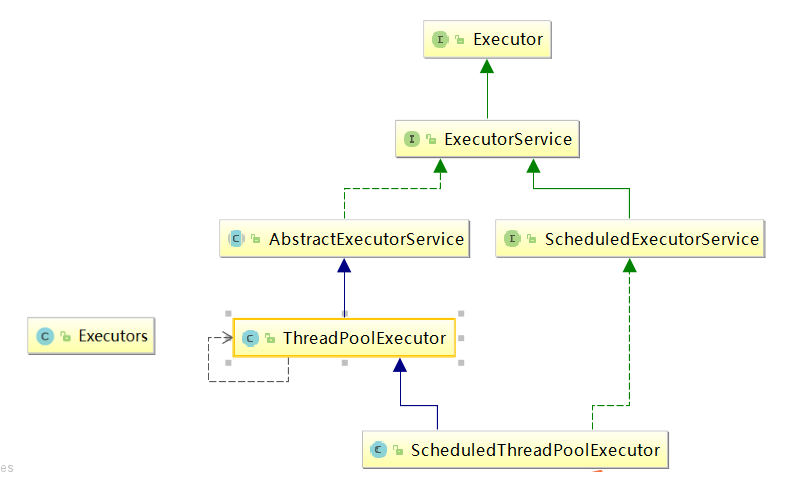
使用:
Executors.newFixedThreadPool(int)执行长期任务性能好,创建一个线程池,一池有x个固定的线程,有固定线程数的线程
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
}
newFixedThreadPool 创建的线程池 corePoolSize 和 maximumPoolSize 值是相等的,它使用的是LinkedBlockingQueue
public static void main(String[] args) {
// 一池5个工作线程,类似一个银行有5个受理窗口
ExecutorService threadPool = Executors.newFixedThreadPool(5);
// 一池1个工作线程,类似一个银行有1个受理窗口
try {
// 模拟有10个顾客过来银行办理业务,目前池子里面有5个中作人员提供服务
for (int i = 1; i <= 10; i++) {
threadPool.execute(() -> {
SmallTool.printTimeAndThread("办理业务");
});
}
} catch (Exception e) {
e.printStackTrace();
} finally {
threadPool.shutdown();
}
}
// 结果
1672495118511 | 25 | pool-1-thread-2 | 办理业务
1672495118511 | 25 | pool-1-thread-2 | 办理业务
1672495118511 | 24 | pool-1-thread-1 | 办理业务
1672495118511 | 27 | pool-1-thread-4 | 办理业务
1672495118511 | 28 | pool-1-thread-5 | 办理业务
1672495118511 | 24 | pool-1-thread-1 | 办理业务
1672495118511 | 26 | pool-1-thread-3 | 办理业务
1672495118511 | 28 | pool-1-thread-5 | 办理业务
1672495118511 | 27 | pool-1-thread-4 | 办理业务
1672495118511 | 25 | pool-1-thread-2 | 办理业务
Executors.newSingleThreadExecutor()一个任务一个任务的执行,一池一线程
public static ExecutorService newSingleThreadExecutor() {
return new FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(1, 1,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>()));
}
newSingleThreadExecutor 创建的线程池 corePoolSize 和 maximumPoolSize 值都是1,它使用的是 LinkedBlockingQueue
public static void main(String[] args) {
// 一池1个工作线程,类似一个银行有1个受理窗口
ExecutorService threadPool = Executors.newSingleThreadExecutor();
try {
// 模拟有10个顾客过来银行办理业务,目前池子里面有5个中作人员提供服务
for (int i = 1; i <= 10; i++) {
threadPool.execute(() -> {
SmallTool.printTimeAndThread("办理业务");
});
}
} catch (Exception e) {
e.printStackTrace();
} finally {
threadPool.shutdown();
}
}
// 结果
1672495284226 | 24 | pool-1-thread-1 | 办理业务
1672495284226 | 24 | pool-1-thread-1 | 办理业务
1672495284226 | 24 | pool-1-thread-1 | 办理业务
1672495284226 | 24 | pool-1-thread-1 | 办理业务
1672495284226 | 24 | pool-1-thread-1 | 办理业务
1672495284226 | 24 | pool-1-thread-1 | 办理业务
1672495284226 | 24 | pool-1-thread-1 | 办理业务
1672495284226 | 24 | pool-1-thread-1 | 办理业务
1672495284226 | 24 | pool-1-thread-1 | 办理业务
1672495284226 | 24 | pool-1-thread-1 | 办理业务
Executors.newCachedThreadPool()执行很多短期异步任务或负载较轻的服务器,线程池根据需要创建新线程,但在先前构建的线程可用时将重用它们。可扩容,遇强则强
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>());
}
newCachedThreadPool 创建的线程池将corePoolSize设置为0,将maximumPoolSize设置为Integer.MAX_VALUE,它使用的是SynchronousQueue,也就是说来了任务就创建线程运行,当线程空闲超过60秒,就销毁线程。
public static void main(String[] args) {
// 一池N个工作线程,类似一个银行有N个受理窗口
ExecutorService threadPool = Executors.newCachedThreadPool();
try {
// 模拟有10个顾客过来银行办理业务,目前池子里面有5个中作人员提供服务
for (int i = 1; i <= 10; i++) {
// 暂停一会线程
SmallTool.sleepMillis(1000);
threadPool.execute(() -> SmallTool.printTimeAndThread("办理业务"));
}
} catch (Exception e) {
e.printStackTrace();
} finally {
threadPool.shutdown();
}
}
// 结果
1672495485999 | 24 | pool-1-thread-1 | 办理业务
1672495487011 | 24 | pool-1-thread-1 | 办理业务
1672495488020 | 24 | pool-1-thread-1 | 办理业务
1672495489032 | 24 | pool-1-thread-1 | 办理业务
1672495490035 | 24 | pool-1-thread-1 | 办理业务
1672495491049 | 24 | pool-1-thread-1 | 办理业务
1672495492057 | 24 | pool-1-thread-1 | 办理业务
1672495493062 | 24 | pool-1-thread-1 | 办理业务
1672495494069 | 24 | pool-1-thread-1 | 办理业务
1672495495081 | 24 | pool-1-thread-1 | 办理业务
当我们不将线程的睡眠,再次运行
// 结果
1672495641929 | 24 | pool-1-thread-1 | 办理业务
1672495641929 | 33 | pool-1-thread-10 | 办理业务
1672495641929 | 26 | pool-1-thread-3 | 办理业务
1672495641929 | 25 | pool-1-thread-2 | 办理业务
1672495641929 | 27 | pool-1-thread-4 | 办理业务
1672495641929 | 31 | pool-1-thread-8 | 办理业务
1672495641929 | 29 | pool-1-thread-6 | 办理业务
1672495641929 | 32 | pool-1-thread-9 | 办理业务
1672495641929 | 30 | pool-1-thread-7 | 办理业务
1672495641929 | 28 | pool-1-thread-5 | 办理业务
可以发现此时使用的线程池中的线程数量发生改变
并且通过上述3种使用线程池的方法可以发现,线程池的原理是:ThreadPoolExecutor,底层源码都是 new 了一个 ThreadPoolExecutor 对象进行创建线程池
线程池中的7大参数
corePoolSize:线程池中的常驻核心线程数maximumPoolSize:线程池中能够容纳同时执行的最大线程数,此值必须大于等于1keepAliveTime:多余的空闲线程的存活时间,当前池中线程数量超过corePoolSize时,当空闲时间达到keepAliveTime时,多余线程会被销毁直到只剩下corePoolSize个线程为止unit:keepAliveTime的单位workQueue:任务队列,被提交但尚未被执行的任务threadFactory:表示生成线程池中工作线程的线程工厂,用于创建线程,一般默认的即可handler:拒绝策略,表示当队列满了,并且工作线程大于等于线程池的最大线程数(maximumPoolSize)时如何来拒绝
请求执行的runnable的策略
源码如下:
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) {
if (corePoolSize < 0 ||
maximumPoolSize <= 0 ||
maximumPoolSize < corePoolSize ||
keepAliveTime < 0)
throw new IllegalArgumentException();
if (workQueue == null || threadFactory == null || handler == null)
throw new NullPointerException();
this.corePoolSize = corePoolSize;
this.maximumPoolSize = maximumPoolSize;
this.workQueue = workQueue;
this.keepAliveTime = unit.toNanos(keepAliveTime);
this.threadFactory = threadFactory;
this.handler = handler;
}
线程池底层工作原理
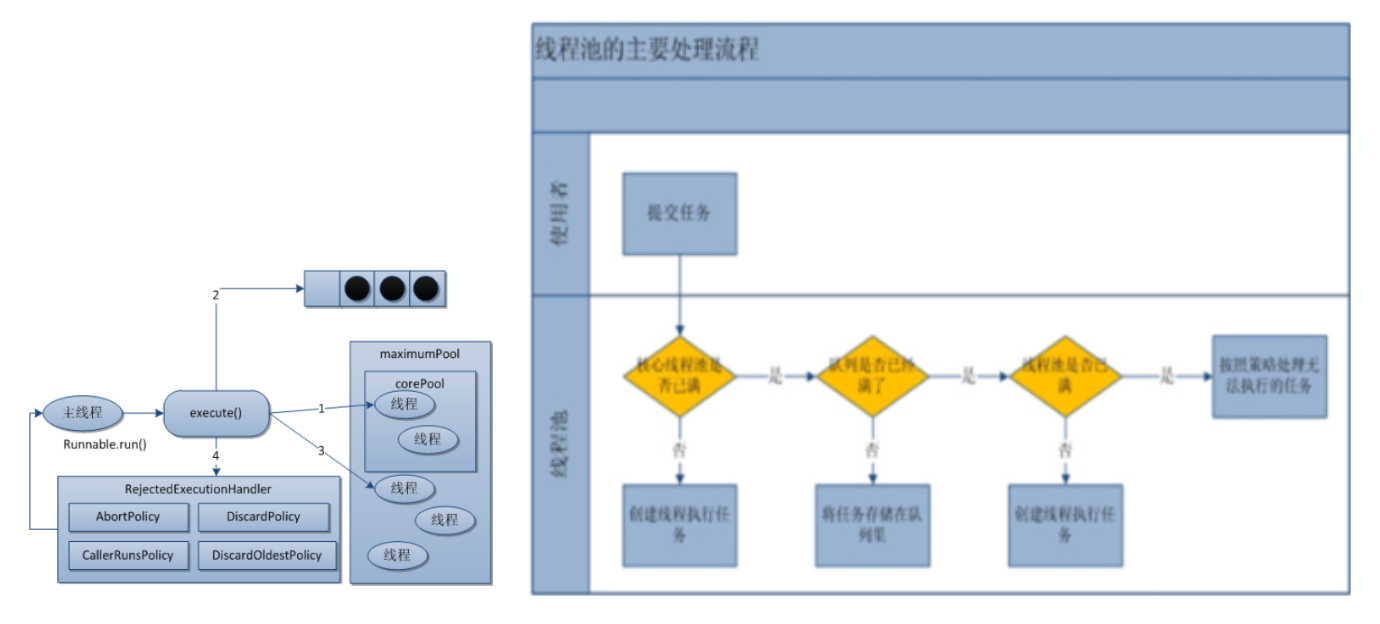
- 在创建了线程池后,开始等待请求。
- 当调用
execute()方法添加一个请求任务时,线程池会做出如下判断:- 如果正在运行的线程数量小于
corePoolSize,那么马上创建线程运行这个任务; - 如果正在运行的线程数量大于或等于
corePoolSize,那么将这个任务放入队列; - 如果这个时候队列满了且正在运行的线程数量还小于
maximumPoolSize,那么还是要创建非核心线程立刻运行这个任务; - 如果队列满了且正在运行的线程数量大于或等于
maximumPoolSize,那么线程池会启动饱和拒绝策略来执行。
- 如果正在运行的线程数量小于
- 当一个线程完成任务时,它会从队列中取下一个任务来执行。
- 当一个线程无事可做超过一定的时间(
keepAliveTime)时,线程会判断:如果当前运行的线程数大于corePoolSize,那么这个线程就被停掉。所以线程池的所有任务完成后,它最终会收缩到corePoolSize的大小。
拒绝策略
在 Java 中已经内置的有拒绝策略,如下所示
AbortPolicy(默认):直接抛出RejectedExecutionException异常,阻止系统正常运行。---- 中止策略CallerRunsPolicy:“调用者运行”一种调节机制,该策略既不会抛弃任务,也不会抛出异常,而是将某些任务回退到调用者,从而降低新任务的流量。— 调用方运行策略DiscardOldestPolicy:抛弃队列中等待最久的任务,然后把当前任务加人队列中尝试再次提交当前任务。DiscardPolicy:该策略默默地丢弃无法处理的任务(直接丢弃超出的任务),不予任何处理也不抛出异常。如果允许任务丢失,这是最好的一种策略。— 丢弃策略
以上内置拒绝策略均实现了 RejectedExecutionHandle 接口
但是在现实工作中我们一个都不用 JDK 提供的三种创建线程池的方法,工作中我们需要自定义使用。
原因如下:

自定义线程池
AbortPolicy 策略
public static void main(String[] args) {
ThreadPoolExecutor threadPoolExecutor = new ThreadPoolExecutor(
2,
5,
1L,
TimeUnit.SECONDS,
new LinkedBlockingQueue<>(3),
Executors.defaultThreadFactory(),
new ThreadPoolExecutor.AbortPolicy()
);
try {
for (int i = 1; i <= 10; i++) {
int temp = i;
threadPoolExecutor.execute(() -> SmallTool.printTimeAndThread("办理业务" + temp));
}
} catch (Exception e) {
e.printStackTrace();
} finally {
threadPoolExecutor.shutdown();
}
}
// 结果 可以看出 直接报了 RejectedExecutionException 异常
java.util.concurrent.RejectedExecutionException: ......
1672546170117 | 26 | pool-1-thread-3 | 办理业务6
1672546170117 | 25 | pool-1-thread-2 | 办理业务2
1672546170117 | 26 | pool-1-thread-3 | 办理业务3
1672546170117 | 24 | pool-1-thread-1 | 办理业务1
1672546170117 | 25 | pool-1-thread-2 | 办理业务4
1672546170117 | 28 | pool-1-thread-5 | 办理业务8
1672546170117 | 27 | pool-1-thread-4 | 办理业务7
1672546170117 | 26 | pool-1-thread-3 | 办理业务5
CallerRunsPolicy 策略
public static void main(String[] args) {
ThreadPoolExecutor threadPoolExecutor = new ThreadPoolExecutor(
2,
5,
1L,
TimeUnit.SECONDS,
new LinkedBlockingQueue<>(3),
Executors.defaultThreadFactory(),
new ThreadPoolExecutor.CallerRunsPolicy()
);
try {
for (int i = 1; i <= 10; i++) {
threadPoolExecutor.execute(() -> SmallTool.printTimeAndThread("办理业务"));
}
} catch (Exception e) {
e.printStackTrace();
} finally {
threadPoolExecutor.shutdown();
}
}
// 结果 即 谁让你调用的,你找谁去调用,这就是 CallerRunsPolicy 策略
1672545863694 | 1 | main | 办理业务
1672545863694 | 28 | pool-1-thread-5 | 办理业务
1672545863695 | 1 | main | 办理业务
1672545863694 | 24 | pool-1-thread-1 | 办理业务
1672545863694 | 26 | pool-1-thread-3 | 办理业务
1672545863694 | 25 | pool-1-thread-2 | 办理业务
1672545863694 | 27 | pool-1-thread-4 | 办理业务
1672545863695 | 26 | pool-1-thread-3 | 办理业务
1672545863695 | 24 | pool-1-thread-1 | 办理业务
1672545863695 | 28 | pool-1-thread-5 | 办理业务
DiscardOldestPolicy 策略
public static void main(String[] args) {
ThreadPoolExecutor threadPoolExecutor = new ThreadPoolExecutor(
2,
5,
1L,
TimeUnit.SECONDS,
new LinkedBlockingQueue<>(3),
Executors.defaultThreadFactory(),
new ThreadPoolExecutor.DiscardOldestPolicy()
);
try {
for (int i = 1; i <= 10; i++) {
int temp = i;
threadPoolExecutor.execute(() -> SmallTool.printTimeAndThread("办理业务" + temp));
}
} catch (Exception e) {
e.printStackTrace();
} finally {
threadPoolExecutor.shutdown();
}
}
// 结果 可以发现 抛弃了 业务3和4 线程 这是因为它们在阻塞队列中是先进来的 等待时间最长 由于使用 DiscardOldestPolicy
// 拒绝策略 所以直接丢弃了 业务3 和 业务4 任务
1672546276424 | 24 | pool-1-thread-1 | 办理业务1
1672546276424 | 25 | pool-1-thread-2 | 办理业务2
1672546276424 | 26 | pool-1-thread-3 | 办理业务6
1672546276424 | 28 | pool-1-thread-5 | 办理业务8
1672546276424 | 26 | pool-1-thread-3 | 办理业务10
1672546276424 | 27 | pool-1-thread-4 | 办理业务7
1672546276424 | 25 | pool-1-thread-2 | 办理业务9
1672546276424 | 24 | pool-1-thread-1 | 办理业务5
DiscardPolicy 策略
public static void main(String[] args) {
ThreadPoolExecutor threadPoolExecutor = new ThreadPoolExecutor(
2,
5,
1L,
TimeUnit.SECONDS,
new LinkedBlockingQueue<>(3),
Executors.defaultThreadFactory(),
new ThreadPoolExecutor.DiscardPolicy()
);
try {
for (int i = 1; i <= 10; i++) {
int temp = i;
threadPoolExecutor.execute(() -> SmallTool.printTimeAndThread("办理业务" + temp));
}
} catch (Exception e) {
e.printStackTrace();
} finally {
threadPoolExecutor.shutdown();
}
}
// 结果 可以看出没有 业务9 和 业务10 任务 这是因为选择了 DiscardPolicy 策略 直接丢弃了超出的任务 线程池的最大容量为5,阻塞队列中的容量为3 整个最大容量为8 故超出该任务量的任务 都会被丢弃
1672546438195 | 27 | pool-1-thread-4 | 办理业务7
1672546438195 | 24 | pool-1-thread-1 | 办理业务1
1672546438195 | 25 | pool-1-thread-2 | 办理业务2
1672546438196 | 27 | pool-1-thread-4 | 办理业务3
1672546438195 | 28 | pool-1-thread-5 | 办理业务8
1672546438196 | 27 | pool-1-thread-4 | 办理业务5
1672546438195 | 26 | pool-1-thread-3 | 办理业务6
1672546438196 | 25 | pool-1-thread-2 | 办理业务4
合理配置线程池参数
这里配置的是最大线程数量,分为 CPU 密集型和 IO 密集型
CPU 密集型
CPU 密集的意思是该任务需要大量的运算而没有阻塞,CPU 一直在全速运行。
CPU 密集任务只有在真正的多核 CPU 上才可以得到加速(通过多线程)。而在单核 CPU 上,无论开几个模拟的多线程该任务都不可能得到加速,因为 CPU 总的运算能力就那些。
CPU 密集型任务配置尽可能少的线程数量,一般公式:CPU 逻辑核数 + 1个线程的线程池
IO 密集型:
-
由于 IO 密集型任务线程并不是一直在执行任务,则应配置尽可能多的线程,如 CPU 逻辑核数 * 2
-
IO 密集型,即该任务需要大量的 IO,即大量的阻塞。在单线程上运行 IO 密集型的任务会导致浪费大量的 CPU 运算能力浪费在等待,所以 IO 密集型任务中使用多线程可以大大的加速程序运行,即使在单核 CPU 上,这种加速主要就是利用了被浪费掉的阻塞时间。
IO 密集型时,大部分线程都被阻塞,故需要多配置线程数:
参考公式:CPU 逻辑核数 / 1 - 阻塞系数,阻塞系数在 0.8 ~ 0.9 之间
更多文章在我的语雀平台:https://www.yuque.com/ambition-bcpii/muziteng