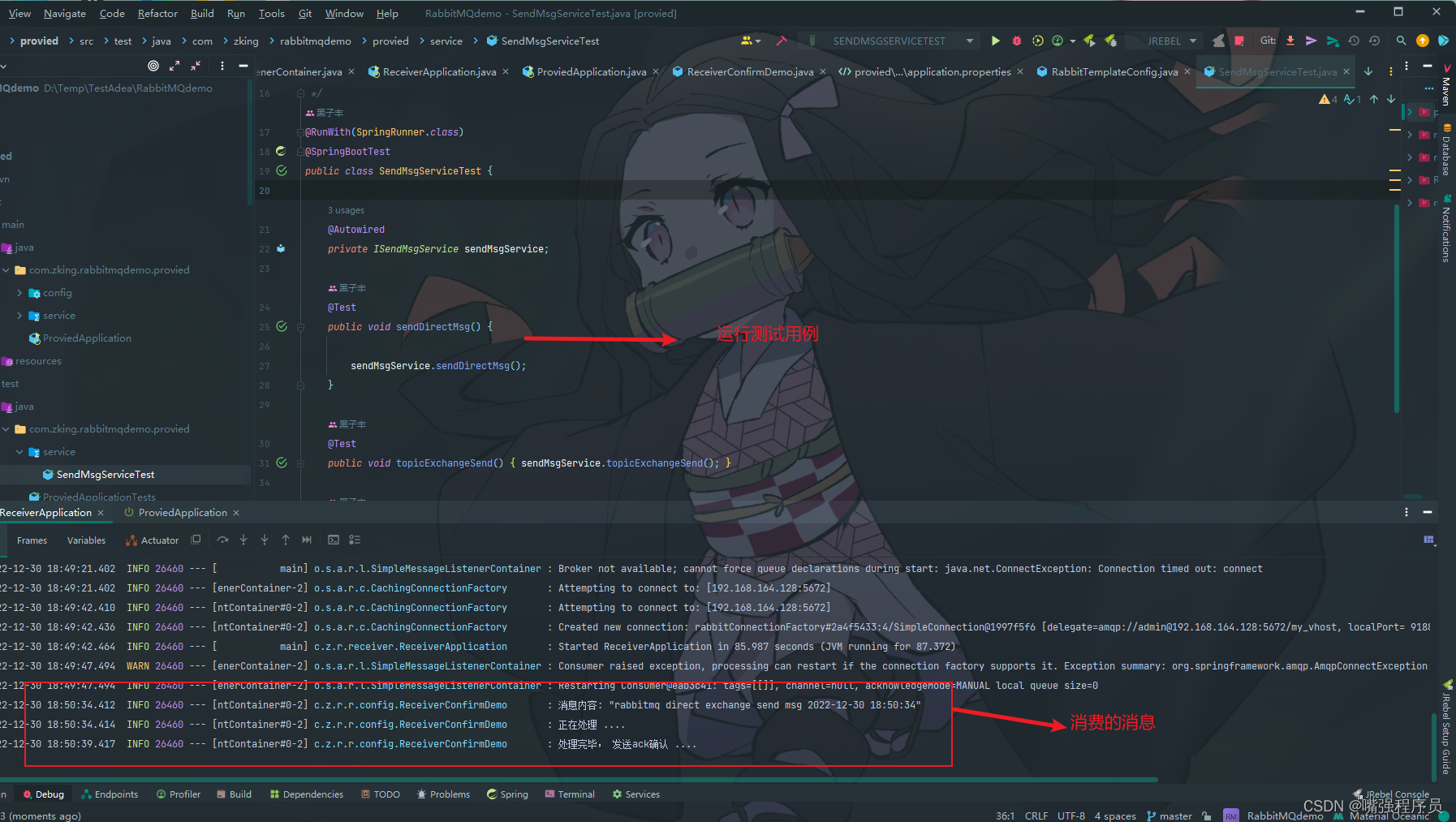
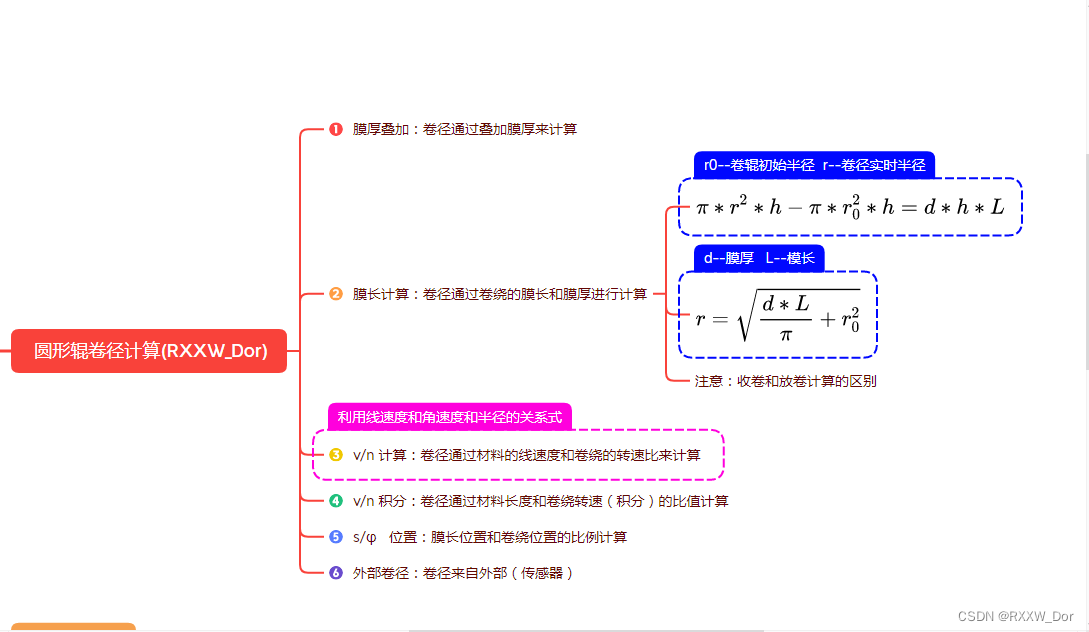
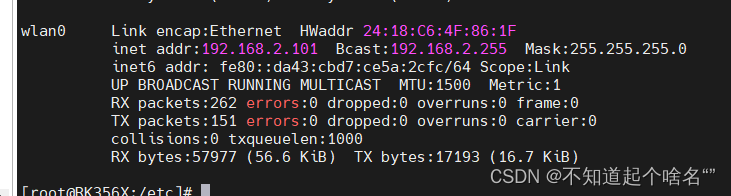
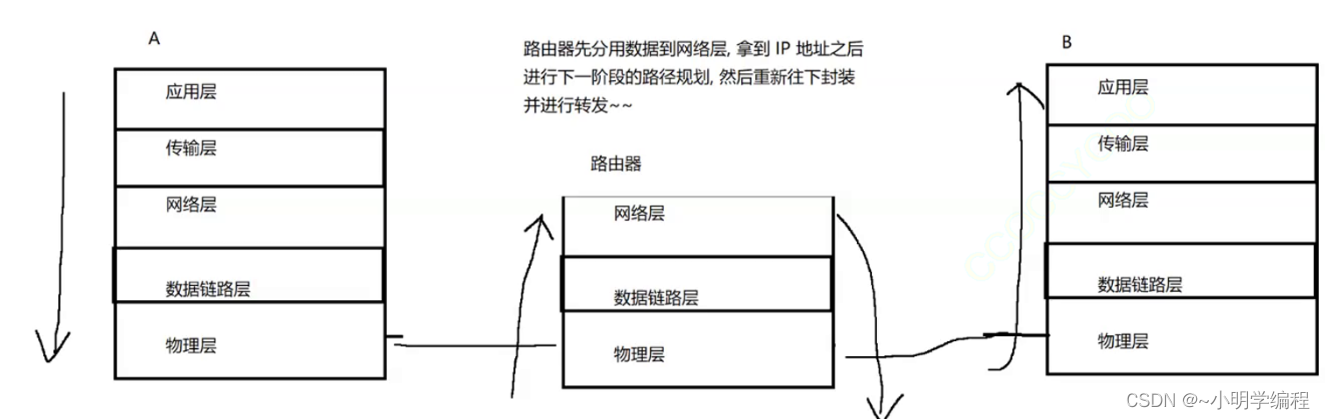
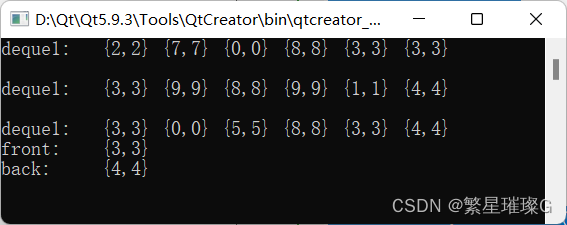
What is Human Pose Estimation?
Human Pose Estimation (HPE) is a way of identifying and classifying the joints in the human body
Human Pose Estimation(HPR 人体姿态估计)是一个对人体关节进行识别和分类的方法。
Essentially it is a way to capture a set of coordinates for each joint (arm, head, torso, etc.,) which is known as a key point that can describe a pose of a person. The connection between these points is known as a pair.
本质上,这是一种捕获描述人类的关键点的每个关节(arm,head、torso,etc…)的方法。这种点与点之间的连接成为pair(对)
The connection formed between the points has to be significant, which means not all points can form a pair. From the outset, the aim of HPE is to form a skeleton-like representation of a human body and then process it further for task-specific applications.
点与点之间的连接必须是重要的,即不是所有点都能形成一个"pair"。从一开始,HPE 的目标就是形成类似骨骼的人体表示,然后针对特定任务的应用对其进行进一步处理。
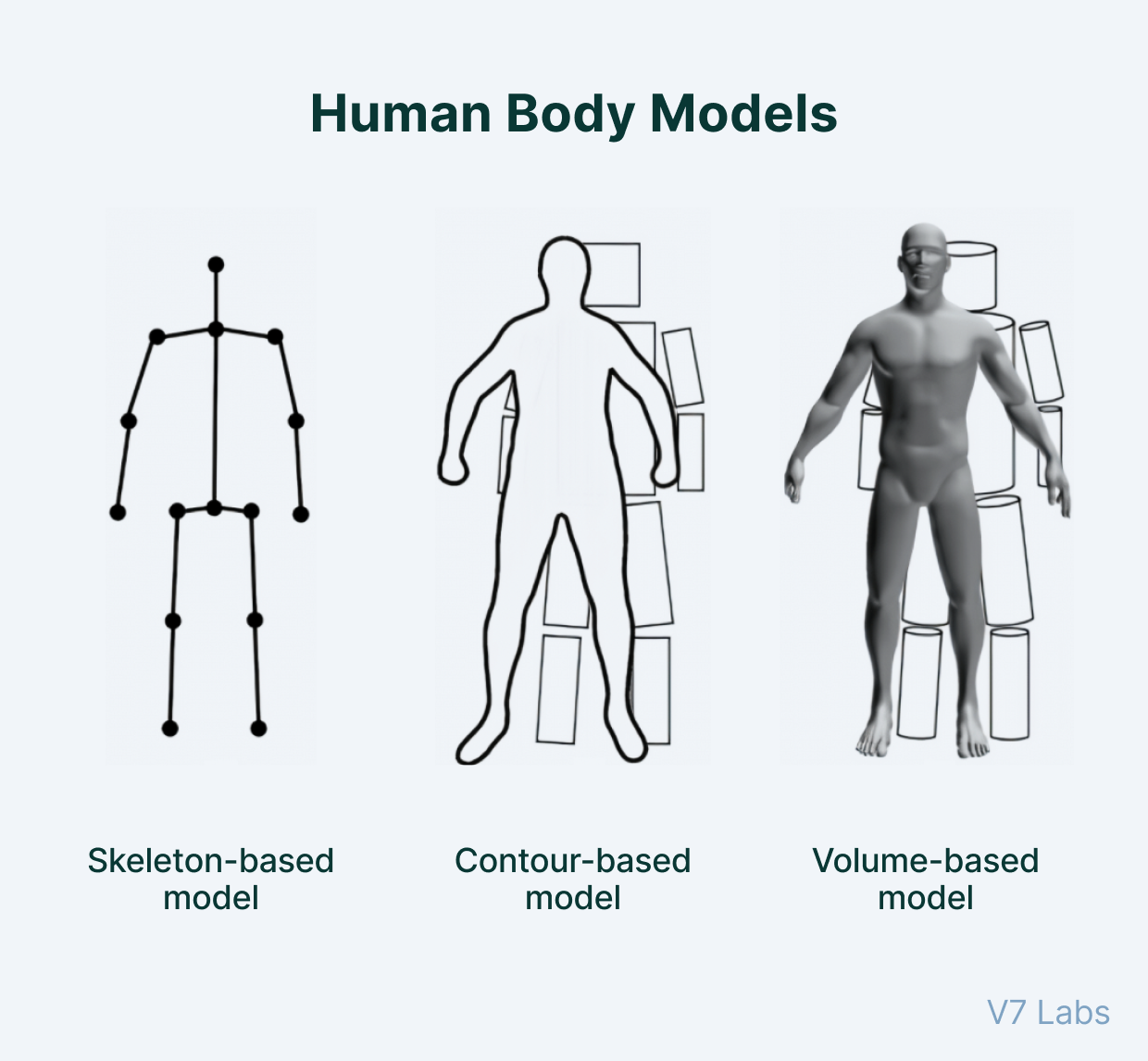
人体姿态检测主要有以下三种:
There are three types of approaches to model the human body:
- Skeleton-based model(基于骨干)
- Contour-based model(基于轮廓)
- Volume-based model (基于卷)
Classical vs. Deep Learning-based approaches
HPE approaches are primarily in the area of computer vision, and it is used to understand geometric and motion information of the human body, which can be very intricate.
HPE方法主要在机器视觉领域,并且他主要用于人体几何学和行为信息的理解上,这些信息往往是错综复杂的。
This section explores the two approaches: the classical approach and the deep learning-based approach to HPE. We will also explain how classical approaches fail to capture the geometric and motion information of the human body, and how deep learning algorithms such as the CNNs excel at it.
这一节探讨两种方法:传统的方法和基于深度学习的方法。我们也会解释为什么传统方法在捕获几何图形和行为信息时会失败,而如CNN的深度学习却在这方面比较出色。
Classical approaches to 2D Human Pose Estimation
Classical approaches usually refer to techniques and methods involving swallow machine learning algorithms.
经典方法通常是指机器学习方法。
For instance, the earlier work to estimate human pose included the implementation of random forest within a “pictorial structure framework”. This was used to predict joints in the human body.
例如,早期估计人类姿势的工作包括在“图像结构框架”内实施随机森林。 这被用来预测人体的关节。
The pictorial structure framework (PSF) is commonly referred to as one of the traditional methods to estimate human pose. PSF contained two components:
图形结构框架(PSF)通常被称为估计人类姿势的传统方法之一。PSF 包含两个组件:
- Discriminator(鉴别器): 它预测某特定位置存在某个身体部位的可能性。
- Prior(先验器): 它使用鉴别器的输出对姿势上的概率分布进行建模;建模的姿势应该是逼真的。
In essence, the PSF objective is to represent the human body as a collection of coordinates for each body part in a given input image. PSF uses nonlinear joint regressors, ideally a two-layered random forest regressor.
从本质上讲,PSF的目标是将人体表示为给定输入图像中每个身体部位的坐标集合。PSF 使用非线性联合回归器,理想情况下是两层随机森林回归器。

These models work well when the input image has clear and visible limbs, however, they fail to capture and model limbs that are hidden or not visible from a certain angle.
当输入图像具有清晰可见的肢体时,这些模型工作良好,但是,它们无法捕获从某个角度隐藏或不可见的肢体。
To overcome these issues, feature building methods like histogram oriented gaussian (HOG), contours, histograms, etc., were used. In spite of using these methods, the classical model lacked accuracy, correlation, and generalization capabilities, so adopting a better approach was just a matter of time.
为了克服这些问题,使用了直方图定向高斯(HOG)、轮廓、直方图等特征构建方法。尽管使用了这些方法,但经典模型缺乏准确性、相关性和泛化能力,因此采用更好的方法只是时间问题。
Deep Learning-based approaches to 2D Human Pose Estimation
Deep learning-based approaches are well defined by their ability to generalize any function (if a sufficient number of nodes are present in the given hidden layer).
基于深度学习的方法可以拟合任何函数(如果隐藏层中存在足够数量的节点)。
When it comes to computer vision tasks, deep convolutional neural networks (CNN) surpass all other algorithms, and this is true in HPE as well.
在计算机视觉任务方面,深度卷积神经网络 (CNN) 超越了所有其他算法,在 HPE 中也是如此。
CNN has the ability to extract patterns and representations from the given input image with more precision and accuracy than any other algorithm; this makes CNN very useful for tasks such as classification, detection, and segmentation.
CNN能够从给定的输入图像中提取模式和表示,比任何其他算法都更精确和准确;这使得CNN对于分类,检测,分割等任务非常有用。
Unlike the classical approach, where the features were handcrafted; CNN can learn complex features when provided with enough training-validation-testing data.
与经典方法不同,其中功能是手工制作的;当提供足够的训练-验证-测试数据时,CNN可以学习复杂的特征。
Toshev et al in 2014 initially used the CNN to estimate human pose, switching from the classical-based approach to the deep learning-based approach, and they named it DeepPose: Human Pose Estimation via Deep Neural Networks.
Toshev 等人在 2014 年最初使用 CNN 来估计人类姿势,从基于经典的方法转向基于深度学习的方法,他们将其命名为 DeepPose:通过深度神经网络估计人类姿势。
In the paper that they had released, they defined the whole problem as a CNN-based regression problem towards body joints.
在他们发表的论文中,他们将整个问题定义为基于CNN的身体关节回归问题。
The authors also proposed an additional method where they implemented the cascade of such regressors in order to get more precise and consistent results. They argued that the proposed Deep Neural Network can model the given data in a holistic fashion, i.e. the network has the capability to model hidden poses, which was not true for the classical approach.
作者还提出了一种额外的方法,他们实现了这种回归器的级联,以获得更精确和一致的结果。他们认为,所提出的深度神经网络可以以整体方式对给定的数据进行建模,即网络具有对隐藏姿势进行建模的能力。
With strong and promising results shown by DeepPose, the HPE research naturally gravitated towards the deep learning-based approaches.
随着DeepPose显示出强大而有希望的结果,HPE的研究自然而然地被基于深度学习的方法所吸引。
Human Pose Estimation using Deep Neural Networks
随着HPE研究的飞速发展,他也将迎接的新的挑战。
One of them was to tackle the multi-person pose estimation.
其中一个是解决多人姿态检测
DNNs are very proficient in estimating single human pose but when it comes to estimating multi-human they struggle because:
DNN 在估计单个人类姿态时非常准确,但在估计多人 时,它们会因为:
- 一个图片可以包含多个人的不同姿势
- 随着人数的增加,之间的相互作用会导致计算复杂性。
- 随着计算复杂度的增加,推理时间也会增加。
In order to tackle these problems, the researchers introduced two approaches:
为了解决这些问题,研究人员引入了两种方法:
- Top-down 自上而下:自顶向下的算法先从图像中检测出所有人,随后利用单人姿态估计的方法对所有人进行姿态估计。自顶向下算法的缺点是算法运行效率随着人数增加而降低,且部分被遮挡的人无法被检测,精度不高。
- Bottom-up 自下而上: 自底向上的算法,先检测出所有人的骨点,再将骨点进行连接形成图,最后通过图优化的方法剔除错误的连接,实现多人姿态估计。自底向上算法的优点是运行时间不随人数增加而线性增加,更有利于实时多人姿态估计。
Now, let’s have a look at deep learning models that are used for multi-human pose estimation.
现在,让我们看一下用于多人体姿势估计的深度学习模型。
OpenPose
OpenPose was proposed by Zhe Cao et. al. in 2019.
It is a bottom-up approach where the network first detects the body parts or key points in the image, followed by mapping appropriate key points to form pairs.
这是一种自下而上的方法,网络首先检测图像中的身体部位或关键点,然后将适当的关键点映射到形成对。
OpenPose also uses CNN as its main architecture. It consists of a VGG -19 convolutional network that is used to extract patterns and representations from the given input. The output from the VGG-19 goes into two branches of convolutional networks.
OpenPose 也使用CNN作为其主要架构。它由一个 VGG-19 卷积网络组成,用于从给定输入中提取模式和表示。VGG-19 的输出进入卷积网络的两个分支。
The first network predicts a set of the confidence map for each body part while the second branch predicts a Part Affinity Fields (PAFs) which creates a degree of association between parts. It is also useful to prune the weaker links in the bipartite graphs.
第一个网络为每个身体部位预测一组confidence map,而第二个分支预测一个Part Affinity Fields (PAF),会在部件之间创建一定程度的关联。修剪二分图中较弱的链接也很有用。

The image above shows the architecture of OpenPose, which is a multi-stage CNN.
上图显示了OpenPose的架构,它是一个多阶段CNN。
Essentially the predictions from the two branches, along with the features, are concatenated for the next stage to form a human skeleton depending upon the number of humans present in the input. Successive stages of CNNs are used to refine the prediction.
本质上,来自两个分支的预测连同特征一起为下一阶段连接起来,以根据输入中存在的人数形成人体骨架。 CNN 的连续阶段用于优化预测。
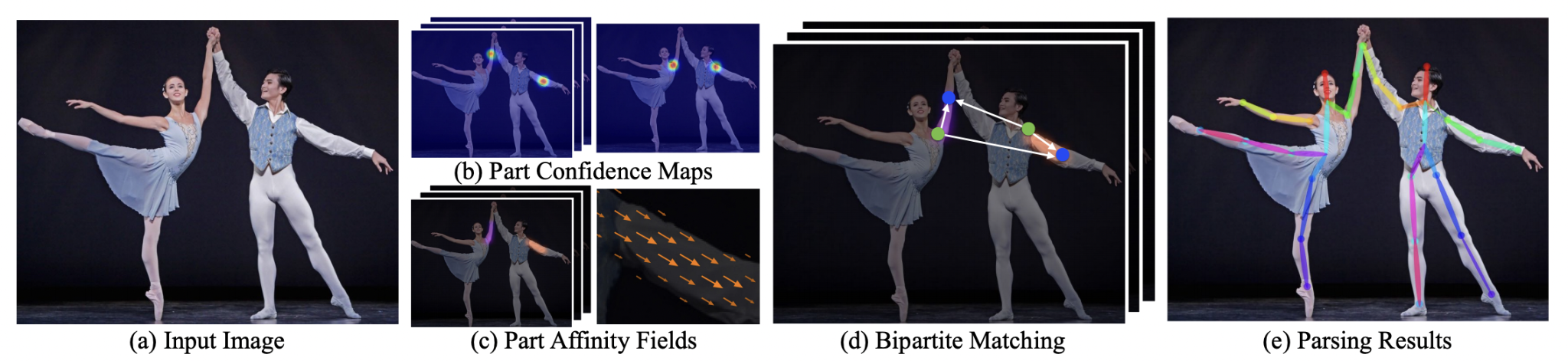
The image above describes the overall pipeline of OpenPose.
上图描述了OpenPose的pipeline 。
AlphaPose (RMPE)
Regional Multi-person Pose Estimation (RMPE) or AlphaPose implements a top-down approach to HPE.
The top-down approach to HPE raises a lot of error in localization and inaccuracies during prediction and is, therefore, quite challenging.
区域多人姿势估计 (RMPE) 或 AlphaPose 对HPE使用了自上而下的方法。 HPE 的自上而下方法在定位和预测过程中会产生大量误差和不准确性,因此极具挑战性。
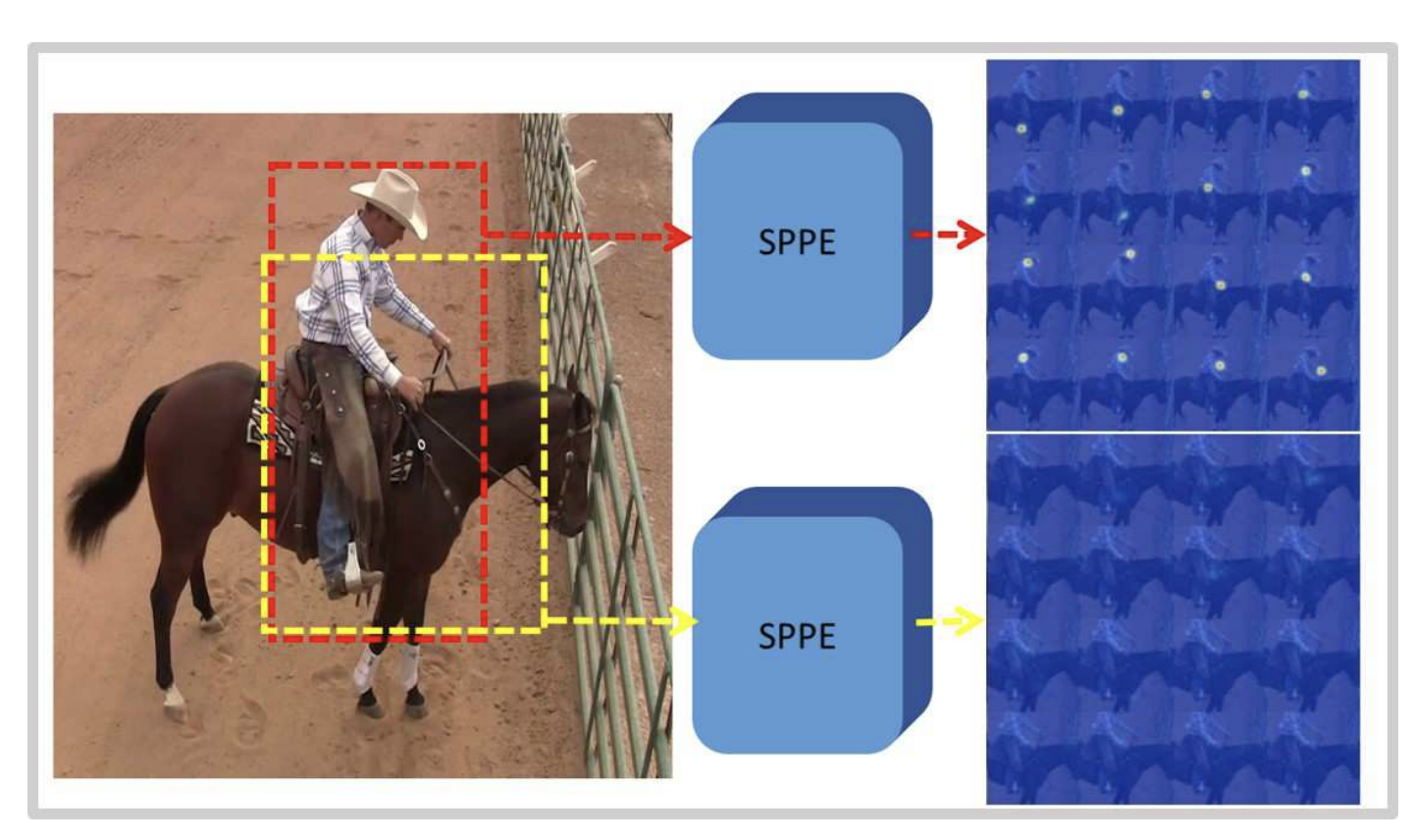
For instance, the image above shows two bounding boxes, the red box represents ground truth while the yellow box represents the predicted bounding box.
例如,上图显示了两个边界框,红色框表示 ground truth,而黄色框表示预测边界框。
Although, when it comes to classification, the yellow bounding box will be considered as a “correct” bounding box to classify a human. However, the human pose can not be estimated even with the “correct” bounding box.
虽然,在分类方面,黄色边界框将被视为对人类进行分类的“正确”边界框。但是,即使使用“正确”的边界框也无法估计人体姿势。
The authors of AlphaPose tackled this issue of imperfect human detection with a two-step framework. In this framework, they introduced two networks:
AlphaPose的作者用两步框架解决了人类检测不完善的问题。在这个框架中,他们引入了两个网络:
- Symmetric Spatial Transformer Network (SSTN)对称空间转换器网络 : 它有助于裁剪输入中的适当区域,从而简化分类任务,进而提高性能。
- Single Person Pose Estimator (SPPE)单人姿势估算器:用于提取和估计人类姿势。
The objective of AlphaPose is to extract a high-quality single-person region from an inaccurate bounding box by attaching SSTN to the SPPE. This method increases classification performances by tackling invariance while providing a stable framework to estimate human pose.
AlphaPose 的目标是通过将 SSTN 附加到 SPPE 从不准确的边界框中提取高质量的单人区域。这种方法通过解决不变性来提高分类性能,同时提供一个稳定的框架来估计人类的姿势。

DeepCut
DeepCut was proposed by Leonid Pishchulin et. al. in 2016 with the objective of jointly solving the tasks of detection and pose estimation simultaneously.
DeepCut 是由 Leonid Pishchulin 等人2016年提出的目标,是共同解决检测和姿态估计任务。
It is a bottom-up approach to estimate human pose.
这是一种自下而上的方法来估计人类的姿势。
The idea was to detect all possible body parts in the given image, then label them such as a head, hands, legs, etc., followed by the process of separating the body parts belonging to each person.
这个想法是检测给定图像中所有可能的身体部位,然后标记它们,例如头部,手,腿等,然后分离属于每个人的身体部位的过程。

The network uses Integral Linear Programming (ILP) modeling to implicitly group all the detected key points in the given input such that the resulting output resembles a skeleton representation of the human.
该网络使用积分线性规划(ILP)建模对给定输入中所有检测到的关键点进行隐式分组,以便生成的输出类似于人类的骨架表示。
Mask R-CNN
Mask R-CNN is a very popular algorithm for instance segmentation.
Mask R-CNN是一种非常流行的实例分割算法。
The model has the capability to simultaneously localize and classify objects by creating a bounding box around the object and also by creating a segmentation mask.
该模型能够通过在对象周围创建边界框以及创建分割掩码来同时定位和分类对象。

The basic architecture can be easily extended for Human Pose Estimation tasks.
基本架构可以轻松扩展,以执行人体姿势估计任务。
Fast R-CNN uses CNN to extract features and representation from the given input.
Fast R-CNN使用CNN从给定输入中提取特征和表示。
The extracted features are then used to propose where the object might be present through a Region Proposal Network (RPN).
然后,提取的特征用于通过区域建议网络 (RPN) 建议对象可能存在的位置。
Since the bounding box can be of various sizes like in the image above, a layer called RoIAlign is used to normalize the extracted features so that they are all of the uniform sizes.
由于边界框可以具有各种大小,如上图所示,因此使用名为 RoIAlign 的图层对提取的特征进行归一化,使它们都具有统一大小。
The extracted features are passed into the parallel branches of the network to refine the proposed region of interest (RoI) to generate bounding boxes and the segmentation masks.
提取的特征被传递到网络的并行分支中,以细化建议的感兴趣区域(RoI),以生成边界框和分割掩码。

When it comes to human pose estimation, the mask segmentation output yielded by the network can be used to detect humans in the given input. Because mask segmentation is very precise in object detection, in this case—human detection, the human pose can be estimated quite easily.
在人体姿势估计方面,网络产生的掩码分割输出可用于检测给定输入中的人类。由于掩模分割在物体检测中非常精确,在这种情况下 - 人类检测,可以很容易地估计人体姿势。
This method resembles the top-down approach, where the person detection stage is performed in parallel to the part detection stage.
此方法类似于自上而下的方法,其中人员检测阶段与零件检测阶段并行执行。
In other words, the keypoint detection stage and person detection stage are independent of each other.
换句话说,关键点检测阶段和人员检测阶段是相互独立的。
7 Human Pose Estimation applications
Human pose estimation has a variety of real-life applications so let’s have a look now at some of the most common HPE use cases.
人体姿势估计具有多种实际应用,因此现在让我们来看看一些最常见的HPE用例。
AI-powered personal trainers
Maintaining physical well-being has become an integral part of our life these days and having a good trainer can help reach our desired fitness level.
如今,保持身体健康已成为我们生活中不可或缺的一部分,拥有一位好的教练可以帮助达到我们想要的健身水平。
It’s no surprise that the market has become saturated with apps that harness the power of AI to help people work out better.
毫不奇怪,市场上已经充斥着利用人工智能的力量来帮助人们更好地锻炼的应用进程。

For instance, Zenia is an AI-powered yoga app that uses HPE to guide you towards achieving a proper posture during your yoga workouts. It uses the camera to detect your pose and estimates how accurate your pose is—if it is correct, then the predicted pose will be represented in green, just like in the image above. If the pose isn’t correct, the red color will replace the green one.
例如,Zenia 是一款由 AI 驱动的瑜伽应用进程,它使用 HPE 指导您在瑜伽锻炼期间保持正确的姿势。它使用摄像头来检测您的姿势并估计您的姿势的准确性 - 如果正确,则预测的姿势将以绿色表示,就像上图一样。如果姿势不正确,红色将取代绿色。
Apart from yoga, HPE has also found application in other forms of exercise.
除了瑜伽,HPE还应用于其他形式的运动。
For example, it is now commonly used in weight lifting, where it can guide app users to perform a proper weight-lift by searching for common mistakes and providing insights on how to fix them to prevent injuries.
例如,它现在通常用于举重,它可以通过搜索常见错误并提供有关如何修复它们以防止受伤的见解来指导应用进程用户执行适当的举重。
Robotics
Robotics has been one of the fastest-growing areas of development.
机器人技术一直是增长最快的发展领域之一。
While programming a robot to follow a procedure can be tedious and time-consuming, deep learning approaches can come to the rescue.
虽然对机器人进行编程以遵循进程可能既乏味又耗时,但深度学习方法可以提供帮助。
Techniques such as reinforcement learning use a simulated environment to achieve the accuracy level required to perform a certain task and can be successfully used to train a robot.
强化学习等技术使用模拟环境来达到执行某项任务所需的精度水平,并且可以成功用于训练机器人。
Motion capture and augmented reality
Another interesting application of HPE can be CGI.
HPE的另一个有趣的应用是CGI。
The entertainment sector, specifically, the cinema business, spends tons of cash to create computer-generated graphics for special effects, mysterious creatures, out-of-the-world sceneries, and a lot more.
娱乐业,特别是电影业,花费大量现金为特效、神秘生物、超凡脱俗的风景等等创建计算机生成的图形。
CGI is expensive because it requires a lot of effort—like wearing special suits and masks to capture the motions, creating superficial effects in the estimated pose, processing power, and also large time investments on top of that.
CGI之所以昂贵,是因为它需要付出很多努力——比如穿上特殊的西装和面具来捕捉动作,在估计的姿势、处理能力中创造肤浅的效果,以及除此之外的大量时间投资。
HPE can automatically extract key points from 2d input and create 3d rendering of the same, which can then be used to add effects, animations, and whatnot.
HPE可以自动从 2D 输入中提取关键点并创建其 3D 渲染,然后可用于添加效果、动画等。
Athlete pose detection
These days, almost all sports rely heavily on data analysis.
Pose detection can help players to improve their technique and achieve better results. Apart from that, pose detection can be used to analyze and learn about the strength and weaknesses of the opponent, which is invaluable for professional athletes and their trainers.
如今,几乎所有的运动都严重依赖数据分析。 姿势检测可以帮助玩家提高技术并取得更好的效果。除此之外,姿势检测可用于分析和了解对手的强弱,这对专业运动员及其教练来说是无价的。

Motion tracking for gaming
Another interesting application of pose estimation comes down to in-game applications, where players can make use of the motion capturing capabilities of HPE to inject poses into the gaming environment. The goal is to create an interactive gaming experience.
姿势估计的另一个有趣应用归结为游戏内应用,玩家可以利用HPE的动作捕捉功能将姿势注入游戏环境。目标是创造互动游戏体验。
For example, Microsoft’s Kinect uses 3D pose estimation (using IR sensor data) to track the motion of the players and to use it to render the actions of the characters virtually into the gaming environment.
例如,微软的Kinect使用3D姿势估计(使用红外传感器数据)来跟踪玩家的动作,并使用它来将角色的动作虚拟地渲染到游戏环境中。
Infant Motion Analysis
HPE can also be used for the analysis of infant motion. This is very helpful for analyzing the behavior of the baby as it grows, especially in assessing the course of its physical development.
HPE 还可用于分析婴儿运动。这对于分析婴儿在成长过程中的行为非常有帮助,尤其是在评估其身体发育过程中。
In some situations, infants are born with serious health issues related to muscles, joints, and nervous system, some of which are caused by cerebral palsy, movement disorders, or traumatic injuries.
在某些情况下,婴儿出生时患有与肌肉、关节和神经系统相关的严重健康问题,其中一些是由脑瘫、运动障碍或创伤引起的。
Motion analysis can help identify which muscles or joints are not working properly. Pose estimation can pick out subtle anomalies in the movement of the infant, which the doctors can analyze and come up with a suitable treatment. HPE can also be used as a recommendation tool to improve physical abilities so that the child can have the greatest level of independence.
运动分析可以帮助识别哪些肌肉或关节无法正常工作。姿势估计可以挑选出婴儿运动中的细微异常,医生可以分析并提出合适的治疗方法。HPE 还可以用作提高身体能力的推荐工具,使孩子能够拥有最大程度的独立性。
Evaluation metrics for Human Pose Estimation model
Deep learning algorithms need proper evaluation metrics to learn the distribution well during the training and also to perform well during the inference. Evaluation metrics depend upon the tasks at hand.
深度学习算法需要适当的评估指标,以便在训练期间很好地学习分布,并在推理期间表现良好。评估指标取决于手头的任务。
In this section, we will briefly discuss the four evaluation metrics required for HPE.
在本节中,我们将简要讨论HPE所需的四个评估指标。
Percentage of Correct Parts (PCP)
PCP is used to measure the correct detection of limbs. If the distance between the two predicted joint locations and the true limb joint locations is almost less than half of the limb length then the limb is considered detected. However, sometimes it penalizes shorter limbs, for example, a lower arm.
PCP用于测量肢体的正确检测。如果两个预测的关节位置与真实肢体关节位置之间的距离几乎小于肢体长度的一半,则认为检测到肢体。然而,有时它会惩罚较短的四肢,例如小臂。
Percentage of Detected Joints (PDJ)
In order to fix the issue raised by PCP, a new metric was proposed. It measures the distance between the predicted and the true joint within a certain fraction of the torso diameter and it is called the percentage of detected joints (PDJ).
为了解决PCP提出的问题,提出了一个新的指标。 它测量躯干直径一定比例内的预测关节和真实关节之间的距离,称为检测到的关节百分比 (PDJ)。
PDJ helps to achieve localization precision, which alleviates the drawback of PCP since the detection criteria for all joints are based on the same distance threshold.
PDJ 有助于实现定位精度,这减轻了PCP的缺点,因为所有关节的检测标准都基于相同的距离阈值。
Percentage of Correct Key-points (PCK)
PCK is used as an accuracy metric that measures if the predicted keypoint and the true joint are within a certain distance threshold. The PCK is usually set with respect to the scale of the subject, which is enclosed within the bounding box.
PCK 用作精度指标,用于测量预测的关键点和真实关节是否在某个距离阈值内。PCK 通常相对于主体的比例进行设置,该比例包含在边界框中。
The threshold can either be:
- PCKh@0.5 是当阈值 = 头骨链接的 50% 时
- PCK@0.2 是预测关节和真实关节之间的距离 < 0.2 * 躯干直径
- 有时以 150 毫米作为阈值。
- 它减轻了较短的肢体问题,因为较短的肢体具有较小的躯干和头骨链接。
- PCK 用于 2D 和 3D (PCK3D)
Object Keypoint Similarity (OKS) based mAP
OKS is commonly used in the COCO keypoint challenge as an evaluation metric. It is defined as:
OKS 在 COCO 关键点挑战中通常用作评估指标。它被定义为:
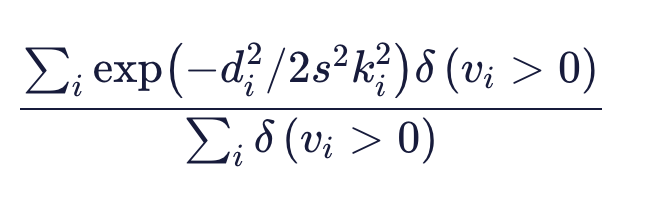
Where,
- di 是ground truth 和预测关键点之间的欧氏距离
- s is the square root of the object segment area s 是对象段区域的平方根
- k is the per-keypoint constant that controls fall off. k 是控件衰减的每个关键点常量。
- vi is considered to be a visibility flag that can be 0, 1 or 2 for not labeled, labeled but not visible and visible and labeled respectively. vi 被认为是一个可见性标志,可以是 0、1 或 2,分别表示未标记、标记但不可见和可见和标记。
Because OKS is used to calculate the distance (0-1), it shows how close a predicted keypoint is to the true keypoint. 由于 OKS 用于计算距离 (0-1),因此它显示了预测的关键点与真实关键点的接近程度。
Top 10 Research Papers on Human Pose Estimation
Here are some of the most prominent research papers regarding various HPE approaches.
以下是有关各种HPE的一些最突出的研究论文。我将paperswithcode连接放到了下面,可以直接点击连接下来论文或查看原码。论文精读及模型讲解后面我都会做教程的。
- DeepPose: Human Pose Estimation via Deep Neural Networks
https://paperswithcode.com/paper/deeppose-human-pose-estimation-via-deep
- Convolutional Pose Machines
https://paperswithcode.com/paper/convolutional-pose-machines
- RMPE: Regional Multi-Person Pose Estimation
https://paperswithcode.com/paper/rmpe-regional-multi-person-pose-estimation
- Efficient Object Localization Using Convolutional Networks
https://paperswithcode.com/paper/efficient-object-localization-using
- DeepCut: Joint Subset Partition and Labeling for Multi-Person Pose Estimation
https://paperswithcode.com/paper/deepcut-joint-subset-partition-and-labeling
- Simple Baselines for Human Pose Estimation and Tracking
https://paperswithcode.com/paper/simple-baselines-for-human-pose-estimation
- OpenPose: Realtime Multi-Person 2D Pose Estimation using Part Affinity Fields
https://paperswithcode.com/paper/openpose-realtime-multi-person-2d-pose
- Human Pose Estimation for Real-World Crowded Scenarios
https://paperswithcode.com/paper/human-pose-estimation-for-real-world-crowded
- DensePose: Dense Human Pose Estimation In The Wild
https://paperswithcode.com/paper/densepose-dense-human-pose-estimation-in-the
- PersonLab: Person Pose Estimation and Instance Segmentation with a Bottom-Up, Part-Based, Geometric Embedding Model
https://paperswithcode.com/paper/personlab-person-pose-estimation-and-instance
paperswithcode中的sota以及其他优秀经典论文
https://paperswithcode.com/task/pose-estimation
Human Pose Estimation in a Nutshell
Human Pose Estimation (HPE) is a way of extracting the pose of the human(s), usually in a form of a skeleton, from a given input: an image or a video.
人体姿势估计 (HPE) 是一种从给定输入(图像或视频)中提取人体姿势的方法,通常以骨骼的形式。
It’s a fascinating and a rapidly growing field of research that finds applications in a variety of industries. Some of the most common use cases for HPE include sports coaching, computer games, healthcare, and more.
这是一个引人入胜且快速增长的研究领域,可在各种行业中找到应用。HPE的一些最常见用例包括体育教练、电脑游戏、医疗保健等。