命名都以芝麻街的角色命名
- x 分为x’ 和 x’’ ,自己跟自己学
- bert 架构跟 transformer Encoder 一样,输入一排向量,输出一排向量,一般用在自然语言处理上

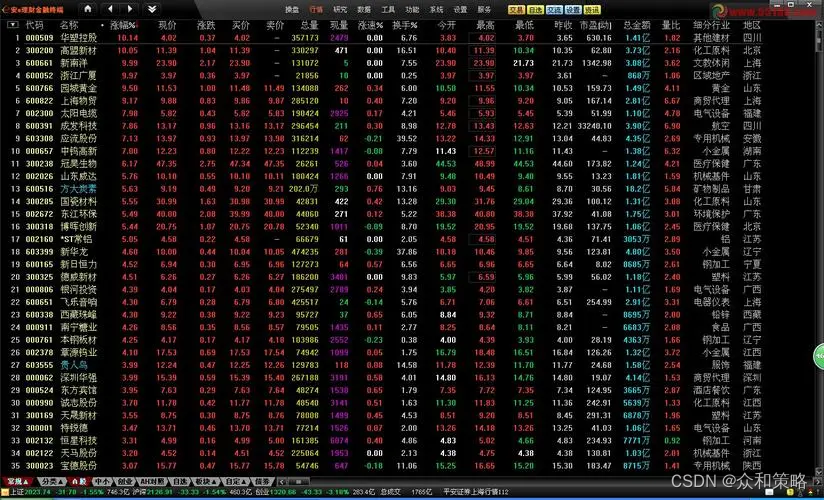
模型大小:



- x 分为 x’ x’’ 自学习

- bert 可以做输入一排向量,输出一排向量,输入和输出一样长。 一般用在自然语言处理
- bert 架构与 transformer encoder 一样
- randomly masking some tokens ,随机盖住一些token
* 使用 特殊 token 覆盖
* 或者 随机数 覆盖
*
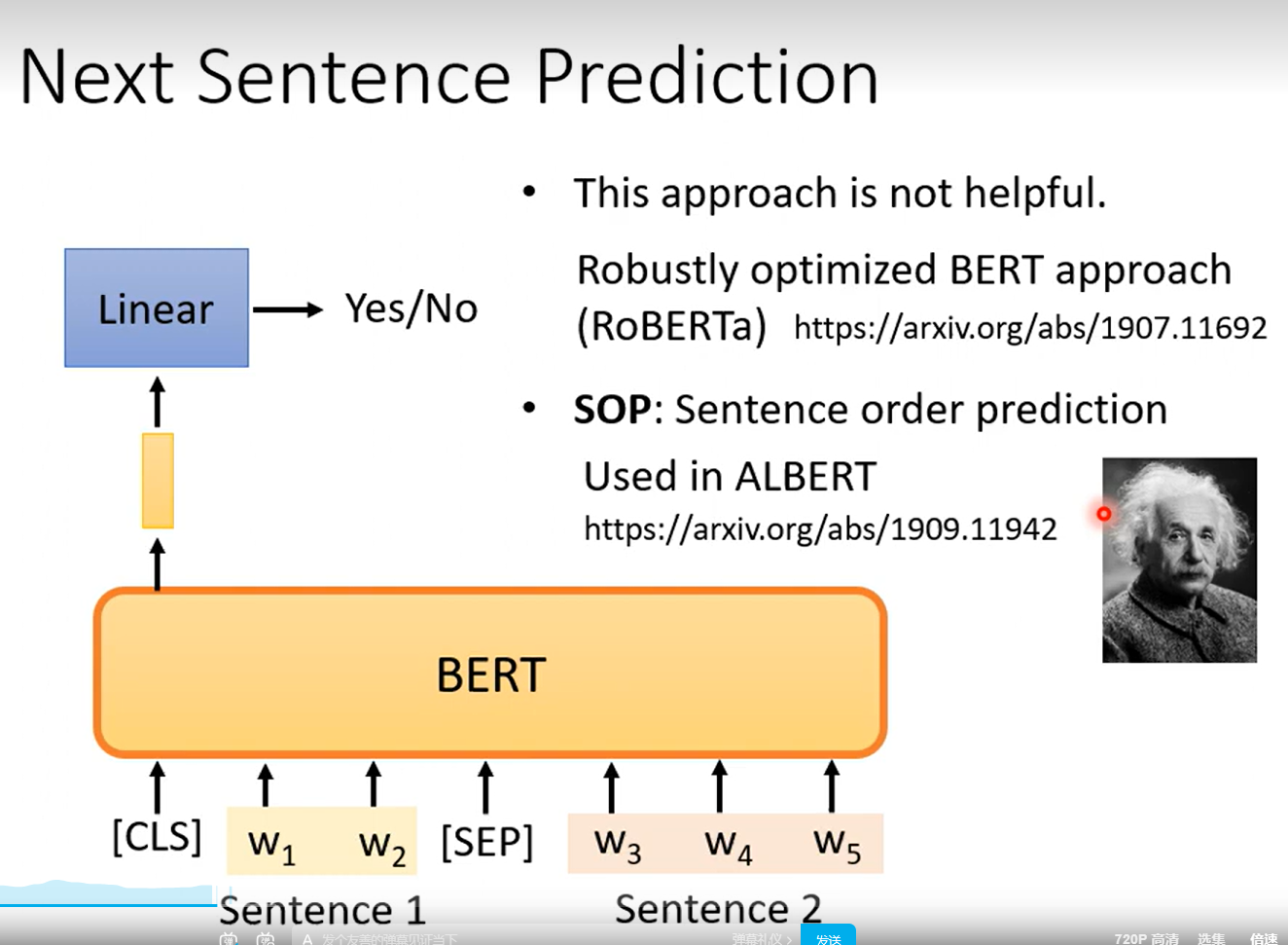
- 预测两个句子是不是连接的

bert 可用来完成各种各样的任务
bert 分化成各种各样的任务 (fine-tune)