一、引言
最近线上出现由于线程池任务执行超时导致的空指针,按道理说基本不会很多执行超时的,看了看监控,那个时间点发生了gc,gc时间超过5s。
说明这次是gc垃圾回收导致的问题,实际上需要排查解决的是垃圾回收问题。表象总是和实际的原因差距很大。

二、环境
操作系统、容器环境没什么好说的,主要是GC相关的
jvm参数:
-Xmx12288m -Xms12288m -Xss256k -XX:MetaspaceSize=128m -XX:MaxMetaspaceSize=256m -XX:MaxGCPauseMillis=200 -XX:+UseG1GC -XX:-OmitStackTraceInFastThrow -XX:MinHeapFreeRatio=30 -XX:MaxHeapFreeRatio=50 -Djava.util.concurrent.ForkJoinPool.common.parallelism=4 -XX:CICompilerCount=3 -XX:MetaspaceSize=256m -XX:MaxMetaspaceSize=512m -XX:ActiveProcessorCount=4 -XX:+PreserveFramePointer -XX:+PrintGC -XX:+PrintGCDetails -XX:+PrintGCDateStamps -XX:+UseGCLogFileRotation -XX:NumberOfGCLogFiles=5 -XX:GCLogFileSize=32M -XX:+HeapDumpOnOutOfMemoryError gc收集器是g1
最大堆大小:12288.00 MB
最大非堆大小:1256.00 MB
g1是整堆收集,收集他定义的region策略。所以监控上所有的gc时间都给到了young gc,达到5s,是让同事很疑惑的。其实监控显示的不太对,属于汇总时间。

三、分析-TCP丢包
这个方向实际对不上这个问题,只是有一些特征显示有这种可能,后面被其他机器的现象排除了。
但是这个猜测方向有没有必要呢,当然是有的。发现问题去排查解决本来就是根据原理先提出一些方向,对这些方向进行论证,排除错误的方向,留下可能的方向再去找依据支持这个论点,再通过实验解决问题。
即使一个方向对不上这次的问题,只要他的理论没有问题,他就可能在下一次映射在其他的问题上。老话说的好:大胆猜测,小心求证。
1、丢包监控
作者为什么会产生丢包影响gc的猜测呢?因为在监控上显示在对应的时间点发生了tcp丢包重传的问题,监控拉长之后这个突峰也是非常明显。
但是这个现象为什么会联系到gc延长的问题呢?作者是这样思考的:TCP丢包重传默认上1s,如果是本来很快结束的请求因为重传而迟迟不结束,那么这个处理任务相关的所有对象都不能释放,不能被gc回收。
这也是之前作者的经验,丢包导致了请求延长,有兴趣的同学可以看看之前发生的问题
生产问题(五)TCP丢包排查_tcp connection lost怎么排查-CSDN博客
生产问题(五)TCP丢包解决_tcp丢包的解决方案-CSDN博客

2、TCP参数
有了猜测就看看当前的设置是不是这样,说不定重传设置的很低呢,在机器上输入
sysctl -a查看一下重传的retrans参数,的确是1s

3、其他机器
接下来需要确认其他机器,是不是所有的发生这种gc延长的机器和对应的时间都有丢包重传的现象。
很明显,作者发现其他机器或者其他时间点都没有,那就不是这个原因。也幸好有多个机器、多个时间点,不然这个可能性不能排查,也就需要更多的验证。
四、分析-GC日志
工具还是挺全的,在机器发布的时候就会生成一份GC日志,后续不断写入,所以可以看到当时发生了什么。
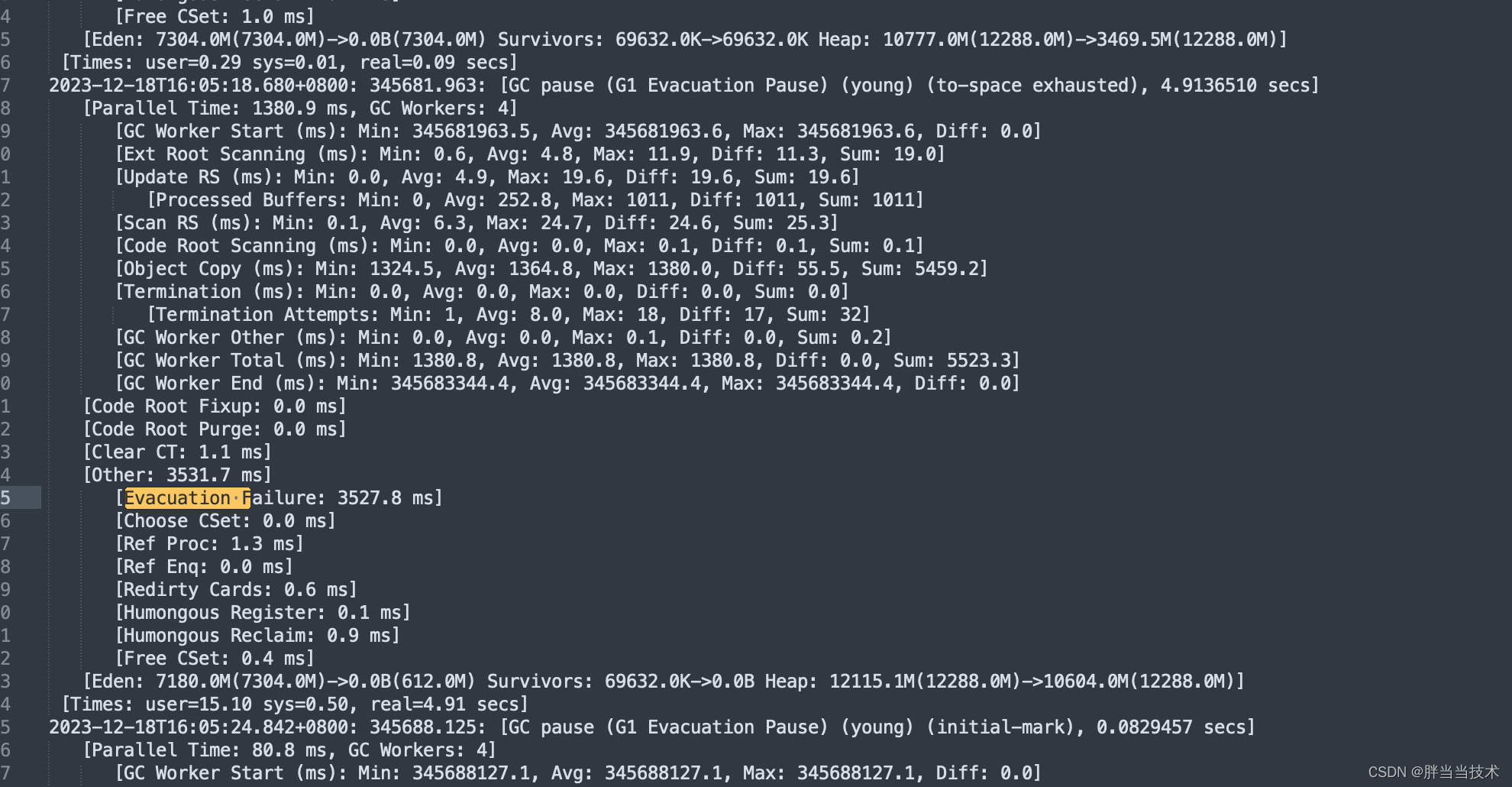
基本上每一个对应的机器和时间点都看到了Evacuation Failure,在region复制转移的时候,对象分配失败了,to-space exhausted也是一个比较明显的特征
五、分析-GC调优
1、G1ReservePercent
G1ReservePercent没有设置,那就是默认的10%预留空间给存活对象转移,这个比例是相对于整堆的,那么预留空间就有1.2g左右,这个看起来也是满了,因为Heap: 12115.1M(12288.0M)->10604.0M(12288.0M)。
那么要不要调大G1ReservePercent呢,作者感觉是不需要的,1.2g不少了,这样还不行,再调大也没什么用处。比例应该没什么问题。
2、G1HeapRegionSize
G1HeapRegionSize没有设置,通常情况下,G1 会将堆内存划分为 2048 个 Region,我们堆内存的大小为 12G ,那么每个 Region 的大小为 6MB左右。那么超过1/2Region大小的都会作为大对象准备放入Humongous区域,对象的大小为Region的几倍,会使用多个连续的Humongous区域来存储这个大对象。
再结合当前的处理任务会产生大对象,每个大对象都会达到几十M,如果是region里面分配不下,然后需要整合几个Humongous存放,为了能找到连续的H区,有时候不得不启动Full GC,那么就比较符合这个现象了。
这样看来就可以调整G1HeapRegionSize,把region放大,免得这些大对象放不下,需要整合多个Humongous。
六、总结
这一次的问题涉及到网络、jvm、gc多方面的知识,需要经过多种原理剖析论证,锁定了方向之后就需要实验了,作者后续会把实验结果同步。
发现问题去排查解决本来就是根据原理先提出一些方向,对这些方向进行论证,排除错误的方向,留下可能的方向再去找依据支持这个论点,再通过实验解决问题。
即使一个方向对不上这次的问题,只要他的理论没有问题,他就可能在下一次映射在其他的问题上。老话说的好:大胆猜测,小心求证。有了解的同学也可以谈谈自己的想法,给我们多一些验证方向。








![[计网02] 数据链路层 笔记 总结 详解](https://img-blog.csdnimg.cn/direct/8b9f7732e8d4421c948d42269f393a82.png)