1 整体架构
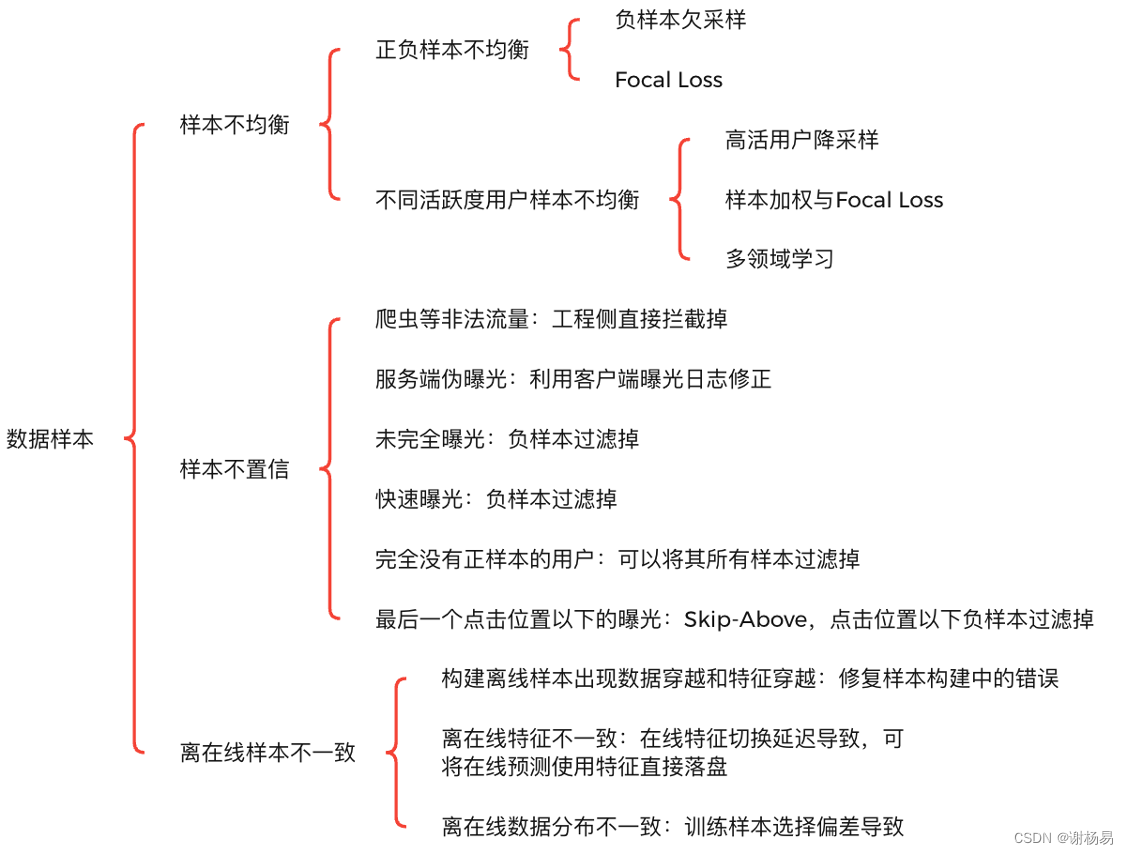
深度学习的数据样本决定了算法的上限,模型只是去不断逼近这个上限,可见数据样本对于深度学习的重要意义。与CV和NLP不同,推荐系统可以获取大量用户的浏览和点击等行为,很容易构造正负样本。例如,在精排点击率(Click-Through Rate,CTR)预估任务中,通常将用户点击物品作为正样本,将用户曝光未点击作为负样本。另外,精排面对的候选集和解空间相比召回和粗排要小得多,所以它的样本选择偏差(Sample Selection Bias,SSB)问题相对没那么严重。精排模型在数据样本上一般会遇到以下问题。
- 样本不均衡:包括正负样本不均衡、不同活跃度用户样本不均衡等。
- 样本不置信:包括爬虫等非正常流量、服务端伪曝光、未完全曝光、快速曝光、完全没有正样本的用户、最后一个点击位置以下的曝光等。
- 离在线样本不一致:包括构建离线样本出现数据穿越和特征穿越、特征不一致、数据分布不一致等。
数据样本的技术架构如图所示,下面逐一详细讲解。
2 样本不均衡
样本不均衡问题在深度学习的各项任务中均广泛存在,是一个共性问题。在计算机视觉和自然语言处理中处理样本不均衡问题的方法也可以应用在推荐算法中。样本不均衡问题主要有正负样本不均衡和不同活跃度用户样本不均衡等。
在点击率预估任务中,如果点击率是1%,则正负样本的比例为1: 99,负样本远远多于正样本,导致样本不均衡。如果在分类问题中存在样本不均衡问题,样本少的类别在训练时反向传播梯度更新的几率就小,对模型损失(Loss)的贡献也比较低,不利于其收敛,最终导致样本多的类别主导了模型,使得模型整体偏向它们,而对其他类别预估不准确。针对此类问题,主要有如下解决方法。
- 负样本欠采样:也叫负样本降采样,指采用随机欠采样,以一定概率从全量负样本中选取一部分样本,将其余的样本直接丢弃。这种方法简单易行,一方面可以减少样本存储和模型训练的压力,另一方面可以缓解正负样本不均衡问题。但负样本中其实也有很多有用的信息,直接丢弃实在可惜,特别是在小场景样本不足时。另外,负样本欠采样在一定程度上破坏了训练和预测两阶段数据分布的一致性。除了负样本欠采样,也可以同时对正样本做一定程度的重复采样,也就是过采样,以增加正样本数量,从而进一步缓解正负样本不均衡问题。通过简单复制构造过采样正样本时,要注意可能出现的过拟合问题。
- Focal Loss:最早使用在图像领域,可以解决图像多分类中的样本不均衡问题,也可以使用在推荐场景中。负样本数量多且一般比较容易区分,可以通过Focal Loss自动降低其权重。正样本则相反,样本少且难学习,通过Focal Loss可以自动增加其权重。Focal Loss可以充分利用所有样本,不用做欠采样,尽量保留所有数据信息,最终可实现在正负样本不均衡的情况下,模型充分收敛。
用户活跃度也会存在样本不均衡问题,高活用户的样本比低活用户多很多,会导致模型偏向于学习高活用户,在低活用户上的表现不够好。此时的解决方法主要如下。
- 对高活用户降采样:减少高活用户的正负样本,从而使得不同活跃度用户的样本可以均衡。随机降采样的方法实现简单,但由于丢弃了一部分样本,可能会损失一些宝贵的数据信息。
- 样本加权与Focal Loss:可以在损失函数中增加低活用户样本的权重,使得模型更关注它们。同样,可以利用Focal Loss实现自动调权。
- 多领域学习:将高活与中低活用户单独建模,分别训练它们的样本。为了加快模型收敛,可以共享模型Embedding层和部分底层。
3 样本不置信
推荐系统精排模型一般将用户曝光点击作为正样本,曝光未点击作为负样本。那么,曝光点击就一定是用户感兴趣,未点击就一定是不感兴趣吗?其实不尽然。精排中存在很多样本不置信问题,主要如下。
- 爬虫等非正常流量:通过爬虫可以快速形成大量的点击行为,这些显然不是真实用户的行为。把它们加入精排正样本,会造成严重的样本不置信问题。因此,需要在网络请求的入口处拦截掉爬虫。
- 服务端伪曝光:服务端发出一次网络请求,会下发多条数据给客户端,用户可能需要滚动屏幕才能浏览完毕。如果用户未浏览完毕,则有部分数据没有得到真正曝光,形成伪曝光。如果将没有真正曝光的样本也加入负样本,则会带来负样本的不置信。所以一般需要采用客户端上报的日志来构建样本,避免出现伪曝光问题。
- 未完全曝光:在瀑布流产品中,物品以卡片的形式展现,卡片可能只曝光了一部分,如图2-2所示,导致用户没有点击。如果将这部分未完全曝光的样本也当作负样本,则同样存在样本不置信问题。因此,可以将这部分样本从负样本中过滤掉
- 快速曝光:在瀑布流产品中,用户快速滚动屏幕,会在短时间内产生大量曝光未点击样本。用户可能没有对这些物品给予足够关注,但如果直接认为用户不感兴趣,而把它们当作负样本,会有一定的样本不置信问题。在沉浸式产品中,这个问题同样存在。怎么避免这个问题呢?可以设定一个曝光时间阈值,将低于阈值的曝光未点击从负样本中去除。
- 完全没有正样本的用户:如果用户只是为了签到,或者碰巧被消息推送唤醒,抑或是随便点开了App,那么可能没有正样本,全是负样本。此时,用户是否点击与推荐的物品是否符合兴趣关系不大,可以直接将负样本过滤掉。
- 最后一个点击位置以下的曝光:用户点击某个物品后,可能兴趣已经得到了满足,因此对点击位置以下的物品没有给予足够的注意。这部分曝光未点击样本同样置信度不足,可以从负样本中过滤掉。这就是Skip-Above方案。
4 离在线样本不一致
在精排模型中,我们经常碰到这样的情况:在离线训练模型时,验证集中的指标增长了,但在线上做A/B测试时,指标不但没有增长,反而可能有所下降。这就是典型的离在线不一致问题,产生该问题的原因如下。
- 构建的离线样本出现数据穿越和特征穿越:一种情况是验证集数据穿越,也就是验证集中的数据出现在了训练集中。例如训练模型时使用了1号到30号数据,验证集使用了30号数据,导致模型训练时就包含了验证集中的数据,离线训练指标当然就会增长了,此时一定要注意训练集和验证集要完全独立。另一种情况是特征穿越,在构造后验统计特征时容易遇到。例如,统计近7天用户的点击数,如果将当天的数据也统计在内,则会导致特征中包含标签(label)信息,造成特征穿越,此时一定要注意不要包含标签所在分区的数据。
- 离在线特征不一致:在线侧使用的特征很多是通过离线侧定时产出,再加载到线上系统中的,这会导致线上特征切换延时问题。例如,当特征按照天的级别产出时,如果特征切换发生在早上4点,则早上0点到4点之间的线上特征仍然是前一天的老特征。但离线侧构建样本时,通常整天都使用新特征,这就会导致一定程度的离在线特征不一致问题。若要优化这个问题,则一般可以将线上预测时使用的所有特征直接落盘,这样就不需要离线拼接特征构造样本,但会增加推荐工程的资源开销。
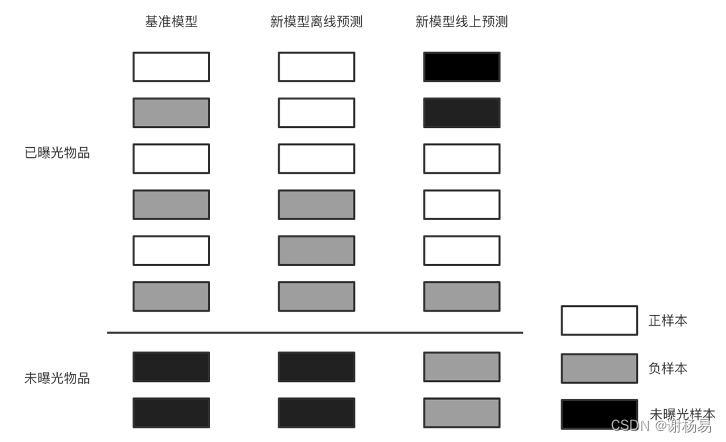
- 离在线数据分布不一致:训练模型使用的离线样本,不论正样本还是负样本,都是基于用户曝光日志产出的。大量未曝光样本和物品没有参与模型训练,处于冰山之下。但在线上预测时,需要对候选集进行全量打分,而不仅仅是已曝光的物品。部分物品可能不在曝光日志中,没有参与模型训练,导致其线上预估可能不准确,从而影响线上指标和业务效果。其本质原因是训练阶段样本选择偏差问题,导致训练和预测(也就是离线和在线)两阶段数据分布不一致。离线样本仅仅是线上数据的一部分,模型在离线数据中表现好,不一定在线上数据中表现好。
5 参考文献
[1] Lin T Y , Goyal P , Girshick R ,et al.Focal Loss for Dense Object Detection[J].arXiv e-prints, 2017.
[2] Li P , Li R , Da Q ,et al.Improving Multi-Scenario Learning to Rank in E-commerce by Exploiting Task Relationships in the Label Space[C]//CIKM '20: The 29th ACM International Conference on Information and Knowledge Management.ACM, 2020.DOI:10.1145/3340531.3412713.
[3] Sheng X R , Zhao L , Zhou G ,et al.One Model to Serve All: Star Topology Adaptive Recommender for Multi-Domain CTR Prediction[J].2021.DOI:10.48550/arXiv.2101. 11427.