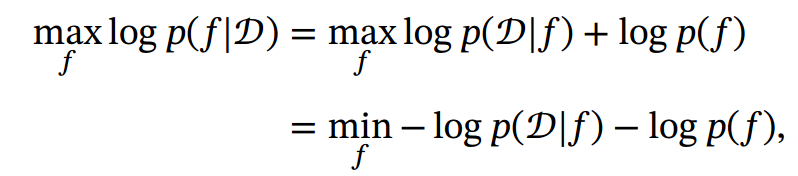1.spark数据倾斜
数据倾斜俩大直接致命后果:Out Of Memory,运行速度慢。这主要是发生在Shuffle阶段。同样Key的数据条数太多了。导致了某个key所在的Task数据量太大了,远远超过其他Task所处理的数据量。
数据倾斜一般会发生在shuffle过程中。很大程度是使用可能会触发shuffle操作的算子:distinct、groupByKey、reduceByKey、aggregateByKey、join、cogroup、repartition等。
定位:
通过观察spark Web UI的界面(端口号8088),定位数据倾斜发生在第几个stage中。如果是用yarn-client模式提交,那么本地是直接可以看到log的,可以在log中找到当前运行到了第几个stage;如果是用yarn-cluster模式提交,则可以通过Spark Web UI来查看当前运行到了第几个stage。此外,无论是使用yarn-client模式还是yarn-cluster模式,我们都可以在Spark Web UI上深入看一下当前这个stage各个task分配的数据量,从而进一步确定是不是task分配的数据不均匀导致了数据倾斜。
数据倾斜的原因:
聚合、join等情况key的分布不均匀
shuffle并行度不够
解决方案
1.将数据倾斜提前到上游的Hive ETL
相当于将数据倾斜提前到Hive中,Hive的底层是MapReduce,运行稳定,不容易失败,而Spark如果出现数据倾斜,很容易崩溃报错。
2.调整shuffle并行度
增加shuffle read task的数量,可以让原本分配给一个task的多个key分配给多个task,从而让每个task处理比原来更少的数据。
3.自定义Partitioner
使用自定义的Partitioner实现类代替默认的HashPartitioner,尽量将所有不同的Key均匀分配到不同的Task中。
4.Reduce side Join转变为Map Join
在对RDD使用join类操作,或者是在Spark SQL中使用join语句时,而且join操作中的一个RDD或表的数据量比较小(比如几百M),比较适用此方案。一个RDD是比较小的,采用广播小RDD全量数据+map算子来实现与join同样的效果,也就是map join,此时就不会发生shuffle操作,也就不会发生数据倾斜。
5.过滤导致少数倾斜的key
比如数据中有很多null的数据,对业务无影响的前提下,可以在shuffle之前过滤掉。
6.为倾斜key增加随机前/后缀
先将有数据倾斜的RDD中倾斜Key对应的数据集单独抽取出来加上随机前缀,另外一个RDD每条数据分别与随机前缀结合形成新的RDD(笛卡尔积,相当于将其数据增到到原来的N倍,N即为随机前缀的总个数),然后将二者Join后去掉前缀。然后将不包含倾斜Key的剩余数据进行Join。最后将两次Join的结果集通过union合并,即可得到全部Join结果。
2.Spark为什么比mapreduce快?
1)基于内存计算,减少低效的磁盘交互;
2)高效的调度算法,基于DAG;
3)容错机制Linage,精华部分就是DAG和Lingae
3.hadoop和spark使用场景?
Hadoop/MapReduce和Spark最适合的都是做离线型的数据分析,但Hadoop特别适合是单次分析的数据量“很大”的情景,而Spark则适用于数据量不是很大的情景。
-
一般情况下,对于中小互联网和企业级的大数据应用而言,单次分析的数量都不会“很大”,因此可以优先考虑使用Spark。
-
业务通常认为Spark更适用于机器学习之类的“迭代式”应用,80GB的压缩数据(解压后超过200GB),10个节点的集群规模,跑类似“sum+group-by”的应用,MapReduce花了5分钟,而spark只需要2分钟。
4.spark宕机怎么迅速恢复?
适当增加spark standby master
编写shell脚本,定期检测master状态,出现宕机后对master进行重启操作
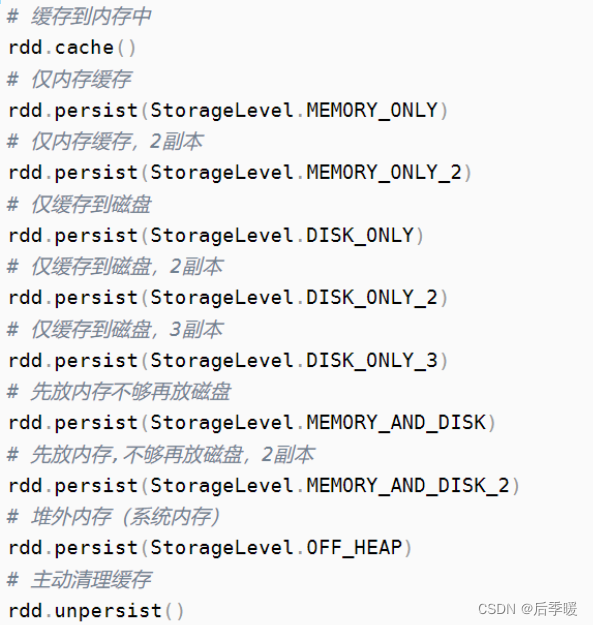
5. RDD持久化原理?
spark非常重要的一个功能特性就是可以将RDD持久化在内存中。
调用cache()和persist()方法即可。cache()和persist()的区别在于,cache()是persist()的一种简化方式,cache()的底层就是调用persist()的无参版本persist(MEMORY_ONLY),将数据持久化到内存中。
如果需要从内存中清除缓存,可以使用unpersist()方法。RDD持久化是可以手动选择不同的策略的。在调用persist()时传入对应的StorageLevel即可。
6.checkpoint检查点机制
应用场景:当spark应用程序特别复杂,从初始的RDD开始到最后整个应用程序完成有很多的步骤,而且整个应用运行时间特别长,这种情况下就比较适合使用checkpoint功能。
原因:对于特别复杂的Spark应用,会出现某个反复使用的RDD,即使之前持久化过但由于节点的故障导致数据丢失了,没有容错机制,所以需要重新计算一次数据。
Checkpoint首先会调用SparkContext的setCheckPointDIR()方法,设置一个容错的文件系统的目录,比如说HDFS;然后对RDD调用checkpoint()方法。之后在RDD所处的job运行结束之后,会启动一个单独的job,来将checkpoint过的RDD数据写入之前设置的文件系统,进行高可用、容错的类持久化操作。
检查点机制是我们在spark streaming中用来保障容错性的主要机制,它可以使spark streaming阶段性的把应用数据存储到诸如HDFS等可靠存储系统中,以供恢复时使用。具体来说基于以下两个目的服务:
1、控制发生失败时需要重算的状态数。Spark streaming可以通过转化图的谱系图来重算状态,检查点机制则可以控制需要在转化图中回溯多远。
2、提供驱动器程序容错。如果流计算应用中的驱动器程序崩溃了,你可以重启驱动器程序并让驱动器程序从检查点恢复,这样spark streaming就可以读取之前运行的程序处理数据的进度,并从那里继续。
7.checkpoint和持久化的区别
1.持久化只是将数据保存在BlockManager中,而RDD的lineage是不变的。但是checkpoint执行完后,RDD已经没有之前所谓的依赖RDD了,而只有一个强行为其设置的checkpointRDD,RDD的lineage改变了。
2.持久化的数据丢失可能性更大,磁盘、内存都可能会存在数据丢失的情况。但是checkpoint的数据通常是存储在如HDFS等容错、高可用的文件系统,数据丢失可能性较小。
8.说一下RDD的血缘
RDD可以从本地集合并行化、从外部文件系统、其他RDD转化得到,能从其他RDD通过Transformation创建新的RDD的原因是RDD之间有依赖关系,代表了RDD之间的依赖关系,即血缘,RDD和他依赖的父RDD有两种不同的类型,即宽依赖和窄依赖。
划分宽依赖和窄依赖的关键点在:分区的依赖关系。也就是说父RDD的一个分区的数据,是给子RDD的一个分区,还是给子RDD的所有分区。父RDD的每一个分区,是被一个子RDD的一个分区依赖(一对一或者多对一),就是窄依赖。如果父RDD的每一个分区,是被子RDD的各个分区所依赖(一对多),就是宽依赖。一旦有宽依赖发生,就意味着会发生数据的shuffle。发生了shuffle也就意味着生成了新的stage。
9.宽依赖函数,窄依赖函数分别有哪些?
窄依赖的函数有:map, filter, union, join(父RDD是hash-partitioned ), mapPartitions, mapValues
宽依赖的函数有:groupByKey, join(父RDD不是hash-partitioned ), partitionBy
10.谈一谈RDD的容错机制?
RDD不同的依赖关系导致Spark对不同的依赖关系有不同的处理方式。对于宽依赖而言,由于宽依赖实质是指父RDD的一个分区会对应一个子RDD的多个分区,在此情况下出现部分计算结果丢失,单一计算丢失的数据无法达到效果,便采用重新计算该步骤中的所有数据,从而会导致计算数据重复;对于窄依赖而言,由于窄依赖实质是指父RDD的分区最多被一个子RDD使用,在此情况下出现部分计算的错误,由于计算结果的数据只与依赖的父RDD的相关数据有关,所以不需要重新计算所有数据,只重新计算出错部分的数据即可。
Spark框架层面的容错机制,主要分为三大层面(调度层、RDD血统层、Checkpoint层),在这三大层面中包括Spark RDD容错四大核心要点。
(1)Stage输出失败,上层调度器DAGScheduler重试。
(2)Spark计算中,Task内部任务失败,底层调度器重试。
(3)RDD Lineage血统中窄依赖、宽依赖计算。
(4)Checkpoint缓存。
11.谈一谈你对RDD的理解
rdd分布式弹性数据集,简单的理解成一种数据结构,是spark框架上的通用货币。所有算子都是基于rdd来执行的,不同的场景会有不同的rdd实现类,但是都可以进行互相转换。rdd执行过程中会形成dag图,然后形成lineage保证容错性等。从物理的角度来看rdd存储的是block和node之间的映射。
RDD是spark提供的核心抽象,全称为弹性分布式数据集。RDD在逻辑上是一个hdfs文件,在抽象上是一种元素集合,包含了数据。它是被分区的,分为多个分区,每个分区分布在集群中的不同结点上,从而让RDD中的数据可以被并行操作(分布式数据集)。 比如有个RDD有90W数据,3个partition,则每个分区上有30W数据。RDD通常通过Hadoop上的文件,即HDFS或者HIVE表来创建,还可以通过应用程序中的集合来创建;RDD最重要的特性就是容错性,可以自动从节点失败中恢复过来。即如果某个结点上的RDD partition因为节点故障,导致数据丢失,那么RDD可以通过自己的数据来源重新计算该partition。这一切对使用者都是透明的。RDD的数据默认存放在内存中,但是当内存资源不足时,spark会自动将RDD数据写入磁盘。比如某结点内存只能处理20W数据,那么这20W数据就会放入内存中计算,剩下10W放到磁盘中。RDD的弹性体现在于RDD上自动进行内存和磁盘之间权衡和切换的机制。
12.Spark主备切换机制原理知道吗
Spark Master主备切换主要有两种机制,之中是基于文件系统,一种是基于Zookeeper.基于文件系统的主备切换机制需要在Active Master挂掉后手动切换到Standby Master上,而基于Zookeeper的主备切换机制可以实现自动切换Master。