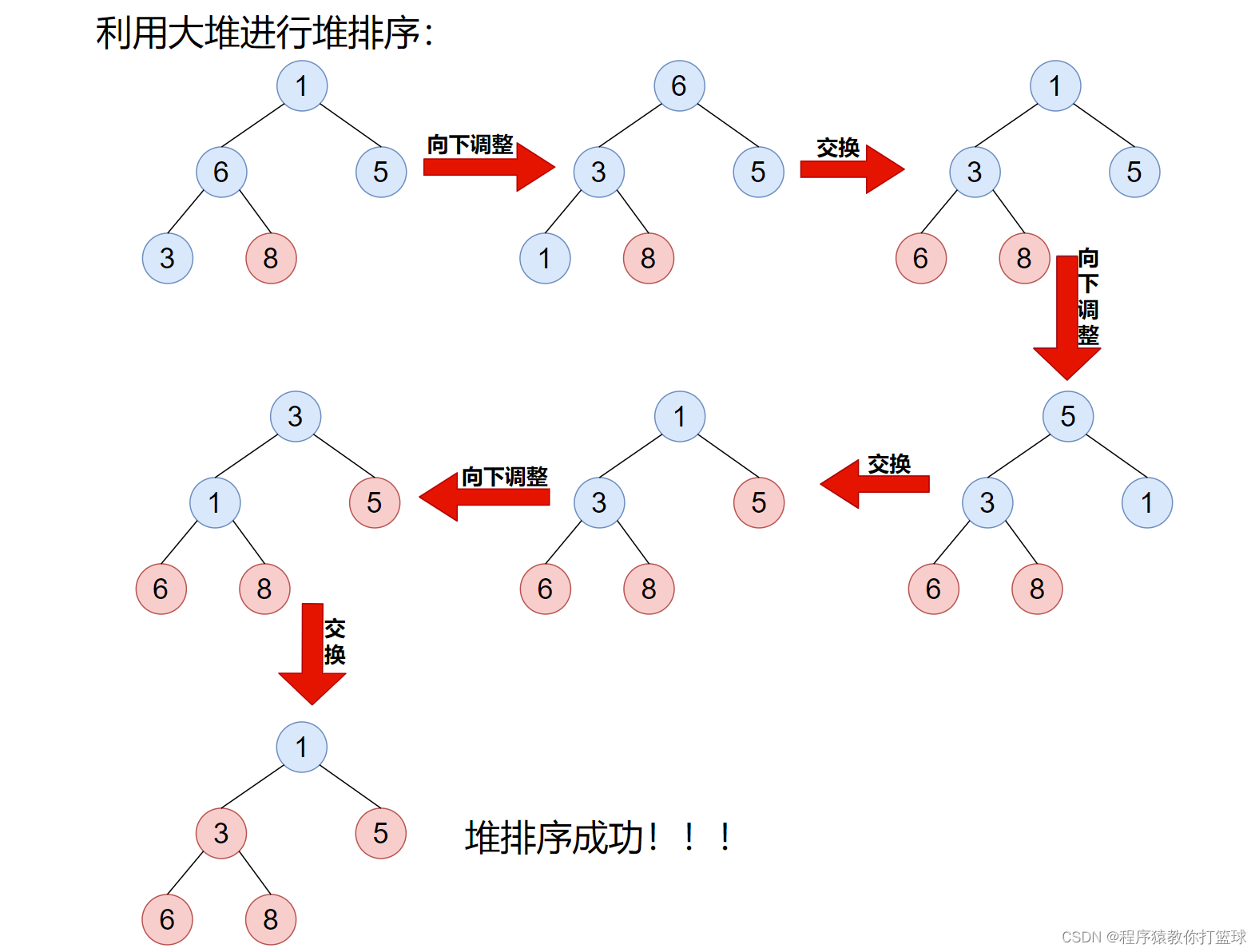
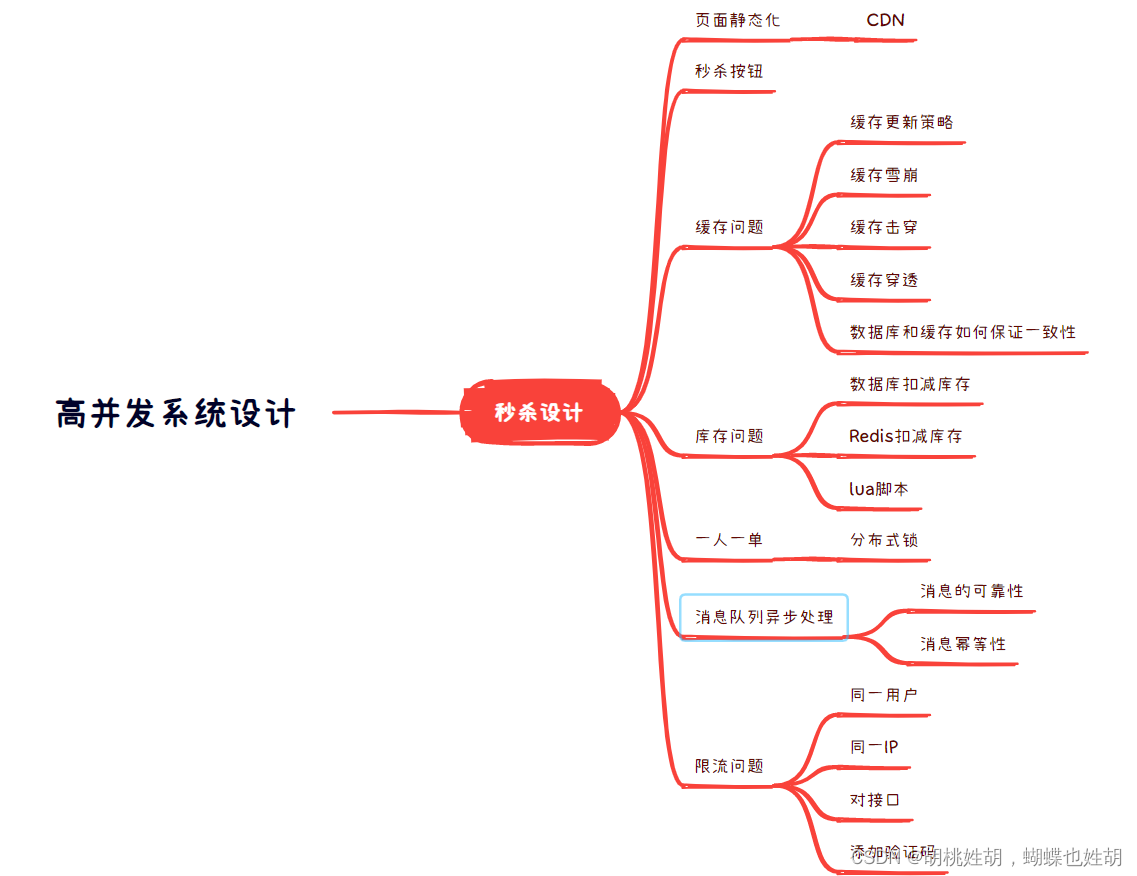
高并发秒杀
秒杀问题相信大家都知道的,虽然是一个烂大街的项目,但是秒杀问题背后的知识是很值得学习的,很多高并发系统设计都可以参照秒杀系统来进行实现。而且顺着这个问题,我会教给大家如何进行高并发的系统设计。
我们先来看一下脑图,了解一下我们可以获得的知识。
页面静态化
我们知道,我们要进行秒杀的时候,必定是要进入一个页面的,这个页面可能会有很多图片,商品信息等等,我们在此页面的时候,用户很可能在秒杀活动开始之前,去查看一些信息,看一些图片,或者秒杀成功之后,不退出页面,继续查看页面的一些信息。而每查看一次信息,都会增加服务的压力。因此我们需要将页面做静态化处理。用户游览商品等常规操作,并不会请求到服务端,这样可以过滤大多数无效的请求。
CDN
页面静态化仍然是不够的,为了让用户更好的加载秒杀页面,提高用户的体验感,我们需要使用CDN,由于用户之间地理位置差异可能较大,因此应该使用CDN让用户就近获取秒杀页面,提高响应速度和命中率。
秒杀按钮
用户进行秒杀操作的时候,可能会持续点击按钮,以最快速度进行秒杀。这样会产生很多无效请求,给服务器带来巨大的压力,因此在秒杀活动开始之前,前端让按钮变灰,不可点击。当秒杀时间到达的时候,才可以进行点击。
缓存问题
在秒杀场景中,并发量巨大,因此我们必定会使用缓存,例如Redis,而且我们不仅要使用Redis,还得搭建Redis集群,那么就产生了使用缓存的一系列问题。
缓存更新策略
- 内存淘汰
- 超时剔除
- 主动更新
对于低一致性的需求,我们一般使用内存淘汰或者超时剔除。但是对于高一致性的需求,我们需要使用主动更新策略。
主动更新有3种策略:
- 由缓存的调用者,在更新数据库的同时更新缓存
- 缓存与数据库整合为一个服务,由服务来维护一致性,调用者只需要调用服务,不需要关心缓存一致性问题
- 调用者只操作缓存,由其他线程异步将缓存数据持久化到数据库,保证最终一致性。
缓存穿透
例如,我们把需要秒杀的商品做了缓存,但是有些用户会恶意的请求不存在的商品id,这样缓存无法命中,就会直接打在数据库上,数据库无法承受并发压力,从而最终宕机。
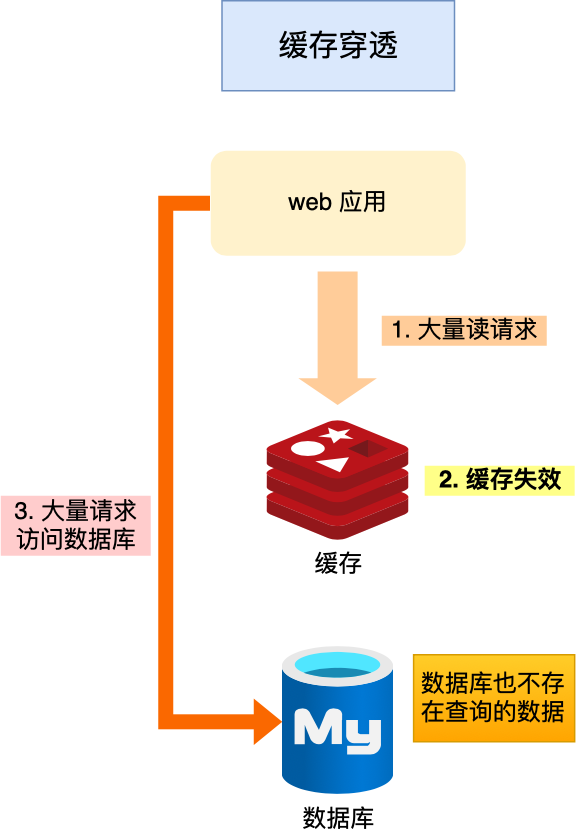
这就是典型的缓存穿透问题。
解决方案如下:
主动防御
- 在前端处对请求进行合法性校验,把恶意的请求直接过滤掉,例如请求参数不合理,请求字段不存在等等
- 加强用户的权限校验,不是所有的用户都有资格发送这样的请求
- 做好热点参数的限流
被动防御
- 缓存空值或者缺省值。缺点是会有格外的内存消耗
- 布隆过滤器。缺点是我需要考虑布隆过滤器和Redis不一致的问题,MySQL和Redis数据不一致的问题就已经够呛了,你再来个布隆过滤器和Redis之间的数据不一致问题,这是无法接受的。因此布隆过滤器这个解决方案只能用于缓存数据更新很少的场景中。
布隆过滤器
布隆过滤器由一个初值都为0的bit数组和N和哈希函数组成。当我们想要标记某一个数据存在的时候会做以下操作:
- 使用N个哈希函数分别计算这个数据的哈希值,得到N个哈希值。
- 把这N个哈希值对bit数组的长度取模,得到每个哈希值在数组种对应的位置
- 把对应位置的bit位设置为1,完成标记操作
当查询某一个数据的时候,就执行刚才的计算过程,得到N个位置,如果发现有一个位置不为1,那么就说明查询的数据没有在Redis中保存。
缓存击穿
缓存击穿也叫热点key问题,被一个高并发访问并且缓存重建业务比较复杂的key突然失效了,无数的请求访问会在瞬间给数据库带来巨大冲击。
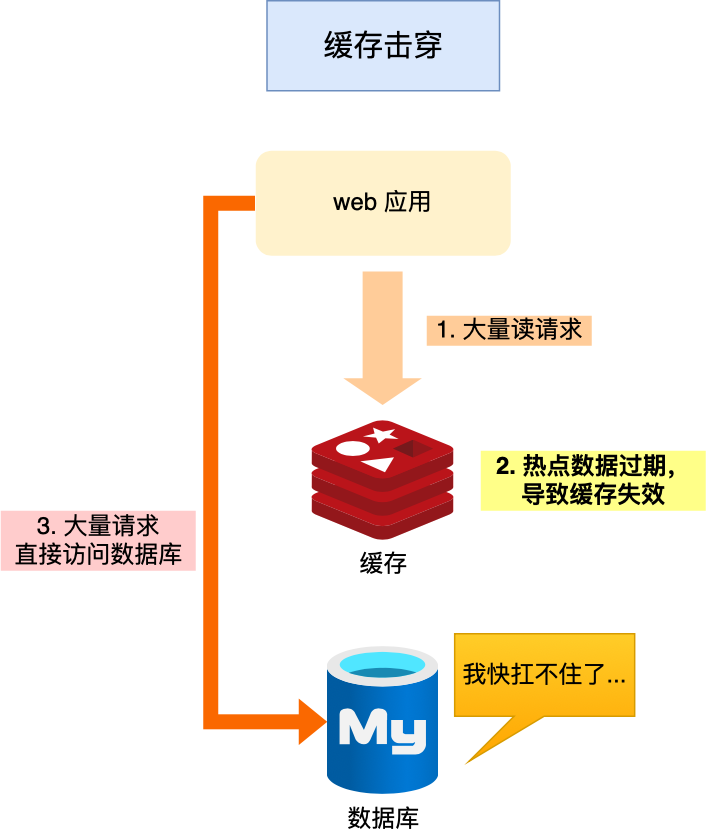
解决方案如下:
- 互斥锁+逻辑过期时间。具体实现为:
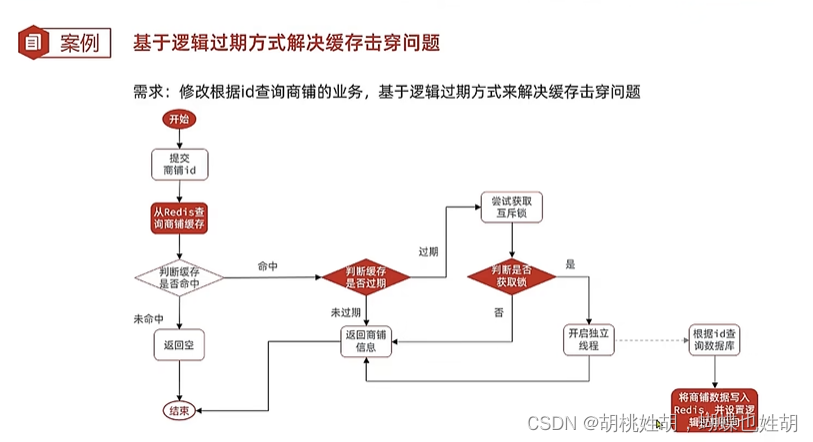
- 不给热点数据设置过期时间,由后台异步更新缓存,或者在热点数据准备要过期前,提前通知后台线程更新缓存以及重新设置过期时间;
缓存雪崩
缓存雪崩是指大量缓存同时失效。
导致Redis缓存雪崩一般来说有两个可能性:
- 大量缓存在同一时间失效
- Redis服务宕机
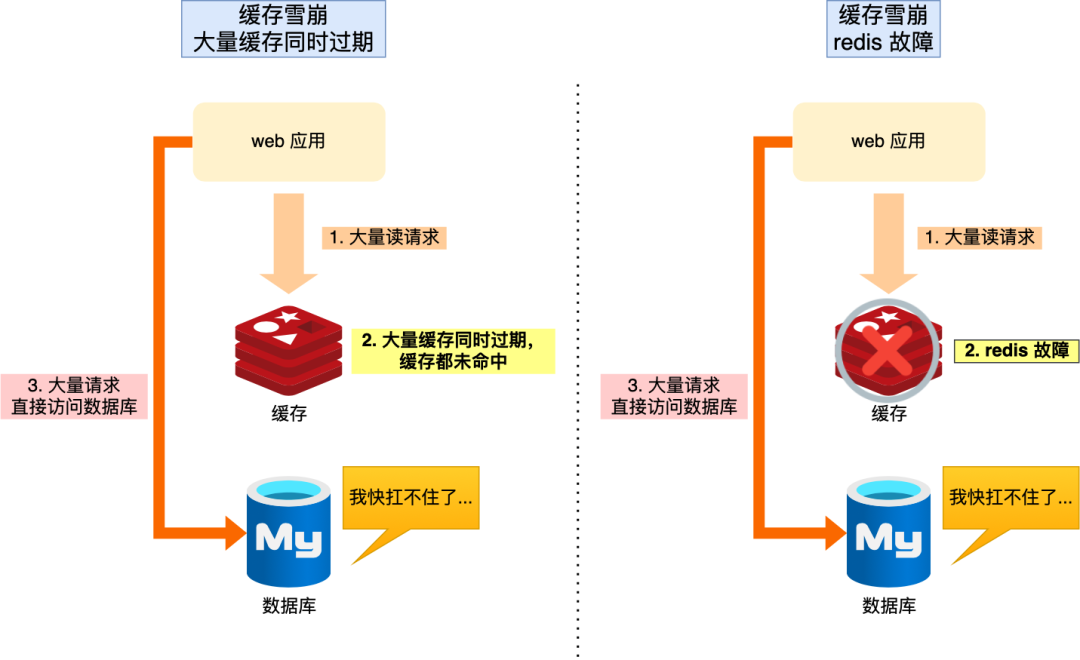
缓存同时失效
解决方案如下:
-
均匀设置过期时间,给数据的过期时间加上一个随机数
-
互斥锁。当业务线程在处理用户请求时,如果发现访问的数据不在 Redis 里,就加个互斥锁,保证同一时间内只有一个请求来构建缓存(从数据库读取数据,再将数据更新到 Redis 里),当缓存构建完成后,再释放锁。未能获取互斥锁的请求,要么等待锁释放后重新读取缓存,要么就返回空值或者默认值。
实现互斥锁的时候,最好设置超时时间,不然第一个请求拿到了锁,然后这个请求发生了某种意外而一直阻塞,一直不释放锁,这时其他请求也一直拿不到锁,整个系统就会出现无响应的现象。因此最好使用
set命令加上过期时间(保证原子性)。 -
双key策略。我们对缓存数据可以使用两个 key,一个是主 key,会设置过期时间,一个是备 key,不会设置过期,它们只是 key 不一样,但是 value 值是一样的,相当于给缓存数据做了个副本。
当业务线程访问不到「主 key 」的缓存数据时,就直接返回「备 key 」的缓存数据,然后在更新缓存的时候,同时更新「主 key 」和「备 key 」的数据。
双 key 策略的好处是,当主 key 过期了,有大量请求获取缓存数据的时候,直接返回备 key 的数据,这样可以快速响应请求。而不用因为 key 失效而导致大量请求被锁阻塞住(采用了互斥锁,仅一个请求来构建缓存),后续再通知后台线程,重新构建主 key 的数据。
-
后台线程更新。业务线程不再负责更新缓存,缓存也不设置有效期,而是让缓存“永久有效”,并将更新缓存的工作交由后台线程定时更新。
Redis宕机
- 搭建Redis高可用集群
- 服务熔断或者限流
缓存与数据库之间的一致性
我们一般有两种方式:
- 先更新缓存再更新数据库
- 先更新数据库再更新缓存
这两种方法都会导致缓存和数据库之前不一致的问题,只是先更新缓存再更新数据库出现问题的概率稍微小一点而已。那么接下来介绍如何尽可能的让它们保持一致。
先更新缓存再更新数据库
使用延迟双删。
#删除缓存
redis.delKey(X)
#更新数据库
db.update(X)
#睡眠
Thread.sleep(N)
#再删除缓存
redis.delKey(X)
加了个睡眠时间,主要是为了确保请求 A 在睡眠的时候,请求 B 能够在这这一段时间完成「从数据库读取数据,再把缺失的缓存写入缓存」的操作,然后请求 A 睡眠完,再删除缓存。
所以,请求 A 的睡眠时间就需要大于请求 B 「从数据库读取数据 + 写入缓存」的时间。
但是具体睡眠多久其实是个玄学,很难评估出来,所以这个方案也只是尽可能保证一致性而已,极端情况下,依然也会出现缓存不一致的现象。
因此,还是比较建议用「先更新数据库,再删除缓存」的方案。
先更新数据库再更新缓存
- 重试机制
- 订阅MySQL的binlog
重试机制
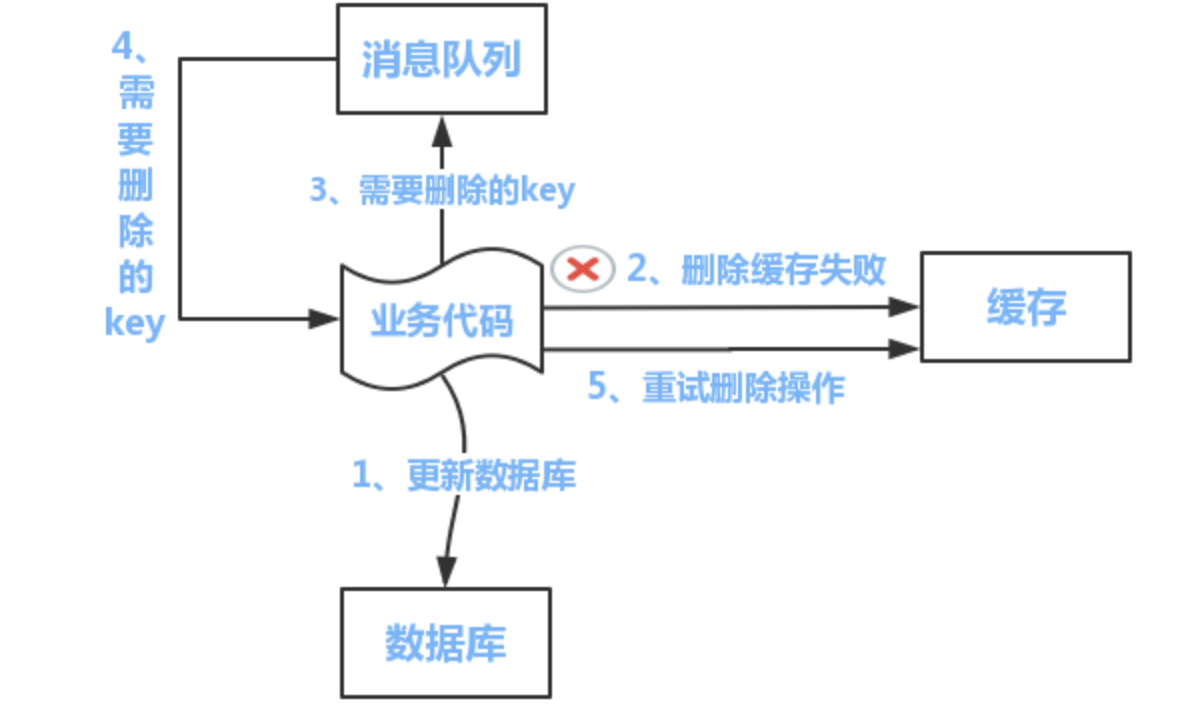
如果删除缓存失败了,那么就把需要删除的key加入到消息队列,进行消息的补偿重试。
如果补偿成功,就把这个消息删了,否则继续进入队列一直补偿,直到成功为止。
订阅MySQL的binlog
「先更新数据库,再删缓存」的策略的第一步是更新数据库,那么更新数据库成功,就会产生一条变更日志,记录在 binlog 里。
于是我们就可以通过订阅 binlog 日志,拿到具体要操作的数据,然后再执行缓存删除,阿里巴巴开源的 Canal 中间件就是基于这个实现的。
Canal 模拟 MySQL 主从复制的交互协议,把自己伪装成一个 MySQL 的从节点,向 MySQL 主节点发送 dump 请求,MySQL 收到请求后,就会开始推送 Binlog 给 Canal,Canal 解析 Binlog 字节流之后,转换为便于读取的结构化数据,供下游程序订阅使用。
下图是 Canal 的工作原理:

所以,如果要想保证「先更新数据库,再删缓存」策略第二个操作能执行成功,我们可以使用「消息队列来重试缓存的删除」,或者「订阅 MySQL binlog 再操作缓存」,这两种方法有一个共同的特点,都是采用异步操作缓存。
库存问题
数据库扣减库存
使用数据库扣减库存,是最简单的实现方案了,假设扣减库存的sql如下:
update product set stock=stock-1 where id=123;
这种写法对于扣减库存是没有问题的,但如何控制库存不足的情况下,不让用户操作呢?
这就需要在update之前,先查一下库存是否足够了。
伪代码如下:
int stock = mapper.getStockById(123);
if(stock > 0) {
int count = mapper.updateStock(123);
if(count > 0) {
addOrder(123);
}
}
大家有没有发现这段代码的问题?
没错,查询操作和更新操作不是原子性的,会导致在并发的场景下,出现库存超卖的情况。
有人可能会说,这样好办,加把锁,不就搞定了,比如使用synchronized关键字。
确实,可以,但是性能不够好。
还有更优雅的处理方案,即基于数据库的乐观锁,这样会少一次数据库查询,而且能够天然的保证数据操作的原子性。
只需将上面的sql稍微调整一下:
update product set stock=stock-1 where id=product and stock > 0;
在sql最后加上:stock > 0,就能保证不会出现超卖的情况。
但需要频繁访问数据库,我们都知道数据库连接是非常昂贵的资源。在高并发的场景下,可能会造成系统雪崩。而且,容易出现多个请求,同时竞争行锁的情况,造成相互等待,从而出现死锁的问题。
但是实际上,我们不可能用MySQL去扣减库存的,这样效率太低了,我们会使用Redis来扣减库存。
Redis扣减库存
redis的incr方法是原子性的,可以用该方法扣减库存。伪代码如下:
boolean exist = redisClient.query(productId,userId);
if(exist) {
return -1;
}
int stock = redisClient.queryStock(productId);
if(stock <=0) {
return 0;
}
redisClient.incrby(productId, -1);
redisClient.add(productId,userId);
return 1;
复制代码
代码流程如下:
- 先判断该用户有没有秒杀过该商品,如果已经秒杀过,则直接返回-1。
- 查询库存,如果库存小于等于0,则直接返回0,表示库存不足。
- 如果库存充足,则扣减库存,然后将本次秒杀记录保存起来。然后返回1,表示成功。
估计很多小伙伴,一开始都会按这样的思路写代码。但如果仔细想想会发现,这段代码有问题。
有什么问题呢?
如果在高并发下,有多个请求同时查询库存,当时都大于0。由于查询库存和更新库存非原则操作,则会出现库存为负数的情况,即库存超卖。
当然有人可能会说,加个synchronized不就解决问题?
调整后代码如下:
boolean exist = redisClient.query(productId,userId);
if(exist) {
return -1;
}
synchronized(this) {
int stock = redisClient.queryStock(productId);
if(stock <=0) {
return 0;
}
redisClient.incrby(productId, -1);
redisClient.add(productId,userId);
}
return 1;
加synchronized确实能解决库存为负数问题,但是这样会导致接口性能急剧下降,每次查询都需要竞争同一把锁,显然不太合理。
那么,有没有更好的方案呢?
lua脚本
我们都知道lua脚本,是能够保证原子性的,它跟redis一起配合使用,能够完美解决上面的问题。
lua脚本有段非常经典的代码:
StringBuilder lua = new StringBuilder();
lua.append("if (redis.call('exists', KEYS[1]) == 1) then");
lua.append(" local stock = tonumber(redis.call('get', KEYS[1]));");
lua.append(" if (stock == -1) then");
lua.append(" return 1;");
lua.append(" end;");
lua.append(" if (stock > 0) then");
lua.append(" redis.call('incrby', KEYS[1], -1);");
lua.append(" return stock;");
lua.append(" end;");
lua.append(" return 0;");
lua.append("end;");
lua.append("return -1;");
该代码的主要流程如下:
- 先判断商品id是否存在,如果不存在则直接返回。
- 获取该商品id的库存,判断库存如果是-1,则直接返回,表示不限制库存。
- 如果库存大于0,则扣减库存。
- 如果库存等于0,是直接返回,表示库存不足。
一人一单
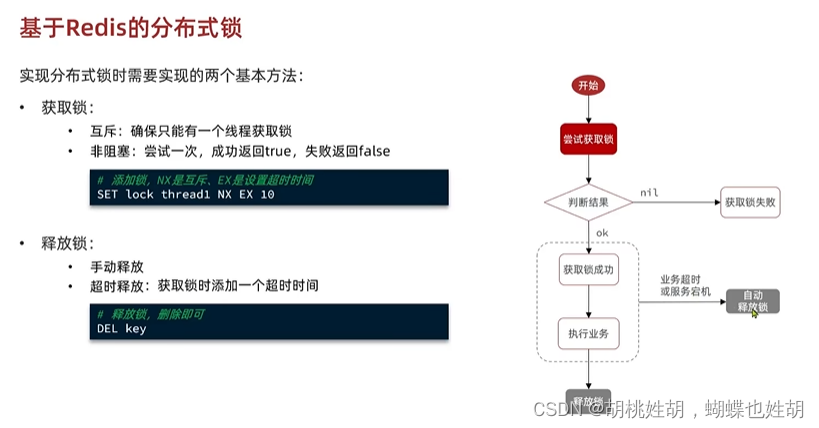
我们可以使用分布式锁实现一人一单问题。
并且我们为了让分布式锁能够释放,要添加过期时间,这个过期时间需要能够比秒杀时间长。
因此我们可以用Redis的这个命令:
# 添加锁,利用setnx的互斥特性
SETNX lock thread1
# 添加锁过期时间,避免服务器宕机的死锁
EXPIRE lock 10
setnx命令和expire命令必须是分开使用的,这就造成了一个问题,如果我在这两个命令之间添加失败了,那么这个锁就没有过期时间了,导致永不过期。因此我们需要保证原子性,可以使用lua脚本,但是其实Redis的set命令是可以做到的。
SET lock thread1 NX EX 10
消息队列异步处理
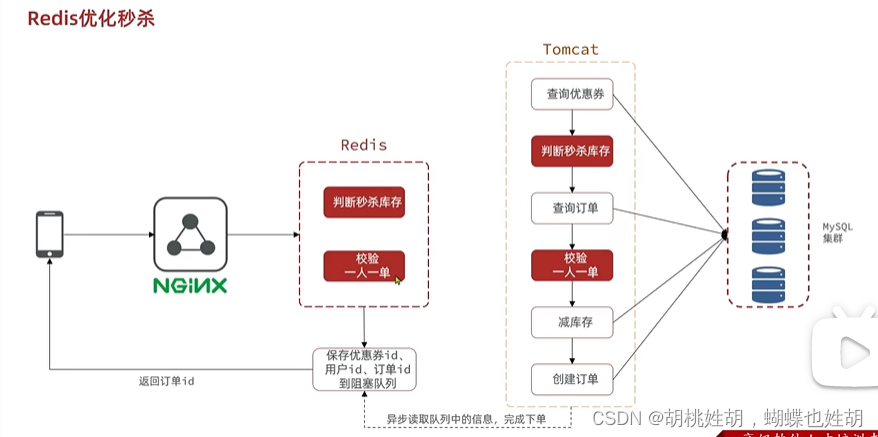
- 我们可以基于Lua判断秒杀库存呢,一人一单,决定用户是否秒杀成功
- 如果秒杀成功了,将产品ID和用户ID封装后存入消息队列
- 开启线程任务,不断从消息队列中获取消息,实现异步下单
Lua脚本如下:
-- 1. 参数列表
-- 1.1 优惠券id
local voucherId = ARGV[1]
-- 1.2 用户id
local userId = ARGV[2]
-- 2. 数据key
-- 2.1 库存key
local stockKey = 'seckill:stock' .. voucherId
-- 2.2 订单key
local stockKey = 'seckill:order' .. voucherId
-- 3. 脚本业务
-- 3.1 判断库存是否充足 get stockKey
if (tonumber(redis.call('get', stockKey)) <= 0) then
-- 3.2 库存不足,返回1
return 1
end
-- 3.2 判断用户是否下单 SISMEMBER orderKey userId
if redis.call('sismember', orderKey, userId) == 1 then
-- 3.3 存在说明是重复下单
return 2
end
-- 3.4 扣库存(incrby stockKey - 1)
redis.call('incrby', stockKey, -1)
-- 3.5 下单(保存用户) sadd orderKey userId
redis.call('sadd', orderKey, userId)
消息队列引发的其他问题可以看看我的这一篇文章:
https://blog.csdn.net/qq_61039408/article/details/128071331?spm=1001.2014.3001.5501
限流问题
对同一个用户进行限流
限制同一个用户id,比如每分钟只能请求5次接口。
但是,有的人可以模拟不同用户进行恶意请求,因此我们要限制同一个IP地址
对同一个IP进行限流
限制同一个ip,比如每分钟只能请求5次接口。
但这种限流方式可能会有误杀的情况,比如同一个公司或网吧的出口ip是相同的,如果里面有多个正常用户同时发起请求,有些用户可能会被限制住。
别以为限制了用户和ip就万事大吉,有些高手甚至可以使用代理,每次都请求都换一个ip。
因此我们对接口进行限流
对接口进行限流
在高并发场景下,这种限制对于系统的稳定性是非常有必要的。但可能由于有些非法请求次数太多,达到了该接口的请求上限,而影响其他的正常用户访问该接口。看起来有点得不偿失。
加入验证码
通常情况下,用户在请求之前,需要先输入验证码。用户发起请求之后,服务端会去校验该验证码是否正确。只有正确才允许进行下一步操作,否则直接返回,并且提示验证码错误。
此外,验证码一般是一次性的,同一个验证码只允许使用一次,不允许重复使用。
普通验证码,由于生成的数字或者图案比较简单,可能会被破解。优点是生成速度比较快,缺点是有安全隐患。
还有一个验证码叫做:移动滑块,它生成速度比较慢,但比较安全,是目前各大互联网公司的首选。