一步一步学爬虫(4)数据存储之CSV文件存储
- 4.3 CSV文件存储
- 4.3.1 写入
- 4.3.2 读取
- 4.3.3 总结
4.3 CSV文件存储
- CSV,全称Comma-Separated Values,中文叫做逗号分隔值或字符分隔值,其文件以纯文本形式存储表格数据。CSV文件是一个字符序列,可以由任意数目的记录组成,各条记录以某种换行符分隔开。每条记录都由若干字段组成,字段间的分隔是其他字符或字符串,最常见的是逗号或制表符。不过所有记录都有完全相同的字段序列,相当于一个结构化表的纯文本形式。它比Excel文件更加简洁,XLS文本是电子表格,包含文本、数值、公式和格式等内容,CSV中则不包含这些,就是以特定字符作为分隔符的纯文本,结构简单清晰。所以,有时候使用CSV来存储数据是比较方便的。本节我们就来讲解Python读取数据和将数据写入CSV文件的过程。
4.3.1 写入
-
这里先看一个简单例子:
import csv with open('data.csv','w') as csvfile: writer = csv.writer(csvfile) writer.writerow(['id','name','age']) writer.writerow(['1001','Mike',20]) writer.writerow(['1002','Bob',22]) writer.writerow(['1003','Jordan',21]) -
这里首先打开 data.csv文件,然后指定打开的模式为w(即写人),获得文件句柄,随后调用csv库的 writer 方法初始化写人对象,传人该句柄,然后调用 writerow 方法传入每行的数据,这样便完成了写入。
-
运行结束后,会生成一个名为 data.csv 的文件,此时数据就成功写入了。直接以文本形式打开,会显示如下内容:
id,name,age 10001,Mike,20 10002,Bob,22 10003,lordan,21 -
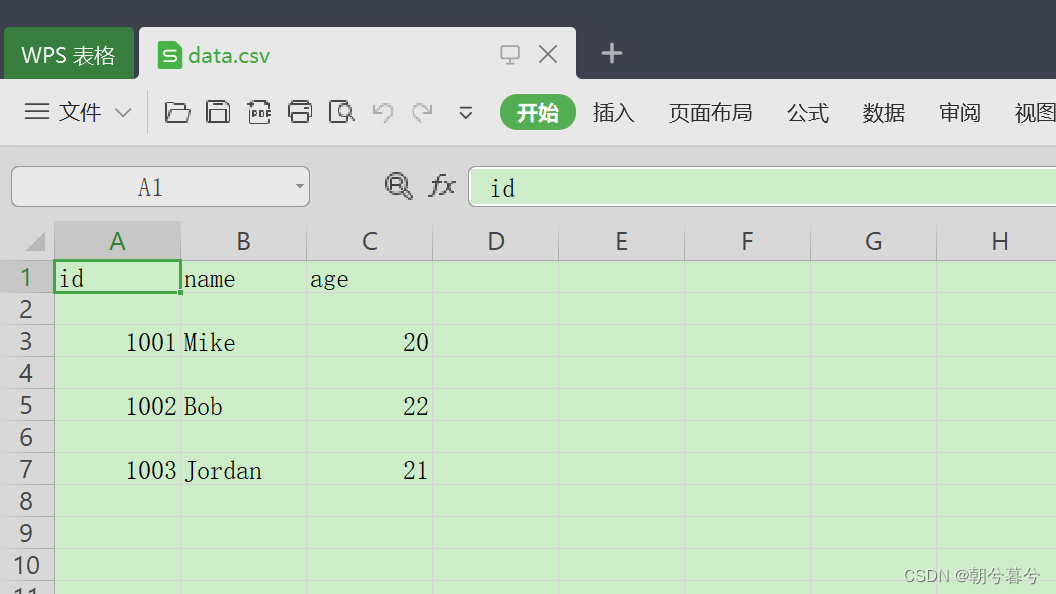
可以看到,写人 CSV文件的文本默认以逗号分隔每条记录,每调用一次 writerow 方法即可写入一行数据。用Excel 打开 data.csv文件的结果如图所示:
-
如果想修改列与列之间的分隔符,可以传入delimiter 参数,其代码如下:
import csv with open('data.csv','w') as csvfile: writer = csv.writer(csvfile, delimiter='') writer.writerow(['id','name','age']) writer.writerow(['1001','Mike',20]) writer.writerow(['1002','Bob',22]) writer.writerow(['1003','Jordan',21]) -
这里在初始化写入对象时,将空格传入了 delimiter参数。此时输出结果中的列与列之间就是空格分隔了,内容如下:
id name age 10001 Mike 20 10002 Bob 22 10003 Jordan 21 -
另外,我们也可以调用 writerows 方法同时写入多行,此时参数需要传入二维列表,例如:
import csv with open('data.csv', 'w') as csvfile: writer = csv.writer(csvfile) writer.writerow(['id','name','age']) writer.writerows([['1001','Mike',20],['1002','Bob',22],['1003','Jordan',21]]) -
注意,这里除了用到writerows方法,后面加的内容,还要用中括号[]括起来。
-
输出结果是相同的,内容如下:
id,name,age 10001,Mike,20 10002,Bob,22 10003,lordan,21 -
但是一般情况下,爬虫爬取的都是结构化数据。我们一般会用字典表示这种数据。csv库也提供了字典的写人方式,实例如下:
import csv
with open('data.csv', 'w') as csvfile:
filenames = ['id','name','age']
writer = csv.DictWriter(csvfile, fieldnames=filenames)
writer.writeheader()
writer.writerow({'id':'10001','name':'Mike','age': 20})
writer.writerow({'id':'10002','name':'Bob','age': 22})
writer.writerow({'id':'10003','name':'Jordan','age': 21})
-
这里先定义了3个字段,用fieldnames表示,然后将其传给DictWriter方法以初始化一个字典写入对象、并将对象赋给writer变量。接着调用写入了对象的writeheader方法先写入头信息,再调用writerow方法传入了相应字典。最终写入的结果和之前是完全相同的。内容如下:
id,name,age 10001,Mike,20 10002,Bob,22 10003,lordan,21 -
这样就把字典写人了 CSV 文件中
-
另外,如果想追加写人,可以修改文件的打开模式,即把 open 函数的第二个参数改成a,代码如下:
import csv with open('data.csv', 'w') as csvfile: filenames = ['id','name','age'] writer = csv.DictWriter(csvfile, fieldnames=filenames) writer.writerow({'id':'10004','name':'Durant','age': 22}) -
这样再次执行这段代码,文件内容便会变
id,name,age 10001,Mike,20 10002,Bob,22 10003,lordan,21 10004,Durant,22 -
由结果可见,数据被追加写人到了文件中。
-
如果要写人中文内容,我们知道可能会遇到字符编码的问题,此时需要给 open 参数指定编码格式。例如,这里再写入一行包含中文的数据,代码改写如下:
import csv with open('data.csv', 'w') as csvfile: filenames = ['id','name','age'] writer = csv.DictWriter(csvfile, fieldnames=filenames) writer.writeheader() writer.writerow({'id':'10004','name':'王伟','age': 22}) -
这里要是没有给 open 函数指定编码,可能会发生编码错误。
-
另外,如果接触过 pandas 等库,可以调用 DataFrame 对象的 to_csv 方法将数据写人CSV文件中。
-
这种方法需要安装pandas库,安装命令为:
pip3 install pandas -
安装完成之后,我们便可以使用 pandas 库将数据保存为 CSV 文件,实例代码如下:
import pandas as pd data = [ {'id':'10001','name':'Mike','age': 20}, {'id':'10002','name':'Bob','age':22}, {'id':'10003','name':'Jordan','age':21}, ] df = pd.DataFrame(data) df.to_csv('data.csv', index=False) -
这里我们先定义了几条数据,每条数据都是一个字典,然后将其组合成一个列表,赋值为 data。紧接着我们使用 pandas 的DataFrame 类新建了一个 DataFrame 对象,参数传人 data,并把该对象赋值为df。最后我们调用 df 的 to_csv 方法也可以将数据保存为 CSV 文件。
4.3.2 读取
-
我们同样可以使用 csv 库来读取 CSV 文件。例如,将刚才写入的文件内容读取出来,相关代码如下:
import csv with open('data.csv', 'r', encoding='utf-8') as csvfile: reader = csv.reader(csvfile) for row in reader: print(row) -
运行结果如下:
['id', 'name', 'age'] ['10001', 'Mike', '20'] ['10002', 'Bob', '22'] ['10003', 'Jordan', '21'] -
这里我们构造的是 Reader 对象,通过遍历输出了文件中每行的内容,每一行都是一个列表。注意,如果 CSV 文件中包含中文,还需要指定文件编码。
-
另外,我们也可以使用 pandas 的 read_csv 方法将数据从 CSV 文件中读取出来,例如:
import pandas as pd df = pd.read_csv('data.csv') print(df) -
运行结果如下:
id name age 0 10001 Mike 20 1 10002 Bob 22 2 10003 ordan 21 -
这里的 df 实际上是一个 DataFrame 对象,如果你对此比较熟悉,则可以直接使用它完成一些数据的分析处理。如果只想读取文件里面的数据,可以把 df 再进一步转化为列表或者元组,实例代码如下:
import pandas as pd df = pd.read_csv('data.csv') data = df.values.tolist() print(data) -
这里我们调用了df的values属性,再调用tolist方法,即可将数据转化为列表形式,运行结果如下:
[[10001, 'Mike', 20], [10002, 'Bob', 22], [10003, 'Jordan', 21]] -
另外,直接对df进行逐行遍历,同样能得到列表类型的结果,代码如下:
import pandas as pd df = pd.read_csv('data.csv') for index, row in df.iterrows(): print(row.tolist()) -
运行结果如下:
[10001, 'Mike', 20] [10002, 'Bob', 22] [10003, 'Jordan', 21] -
可以看到,我们同样获取了列表类型的结果。
4.3.3 总结
- 本节中,我们了解了CSV文件的写入和读取方式。这也是一种常用的数据存储方式,需要熟练掌握。