自己去看文章数据的话,比较慢,所以一直想通过程序来批量获取CSDN的文章数据,最近研究了一下,发现还是挺简单的,能够直接通过解析json来获取文章数据,跟大家分享一下。
文章目录
- 一、步骤
- 1、首先我们到自己的主页或别人的主页【也就是你想获取的文章数据的那个页面】
- 2、找到这个以get-busness的请求开头的请求
- 3、解析请求响应的json数据
- 4、数据持久化
- 二、完整的方法代码
一、步骤
1、首先我们到自己的主页或别人的主页【也就是你想获取的文章数据的那个页面】
这里以我自己的为例。
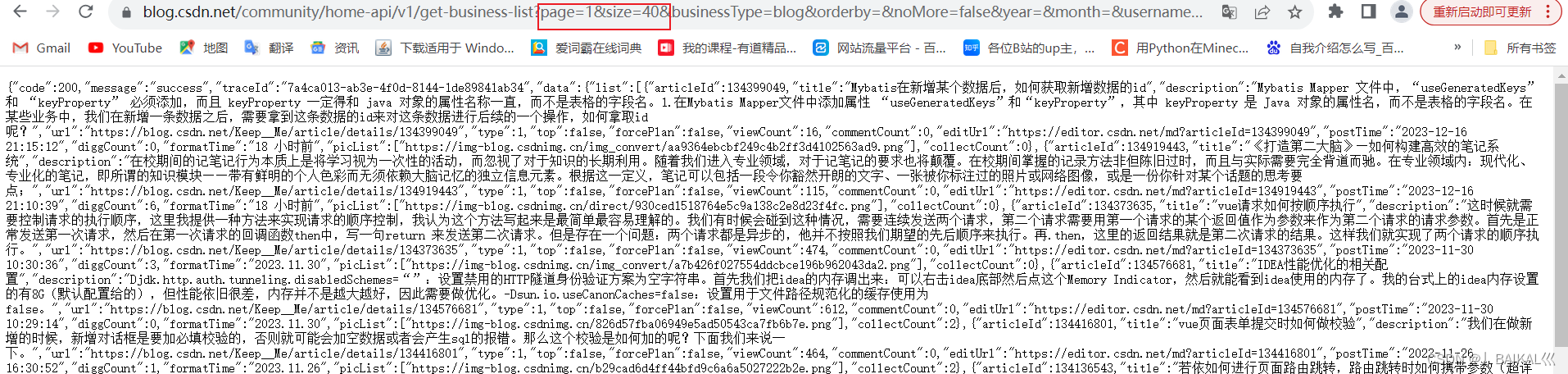
2、找到这个以get-busness的请求开头的请求
查看它的响应信息,我们会发现这里面有20条文章的数据信息,且单个文章的信息也是比较全的,包括了比较重要的几个信息,包括阅读量,文章标题,发布时间等,这就足够了。
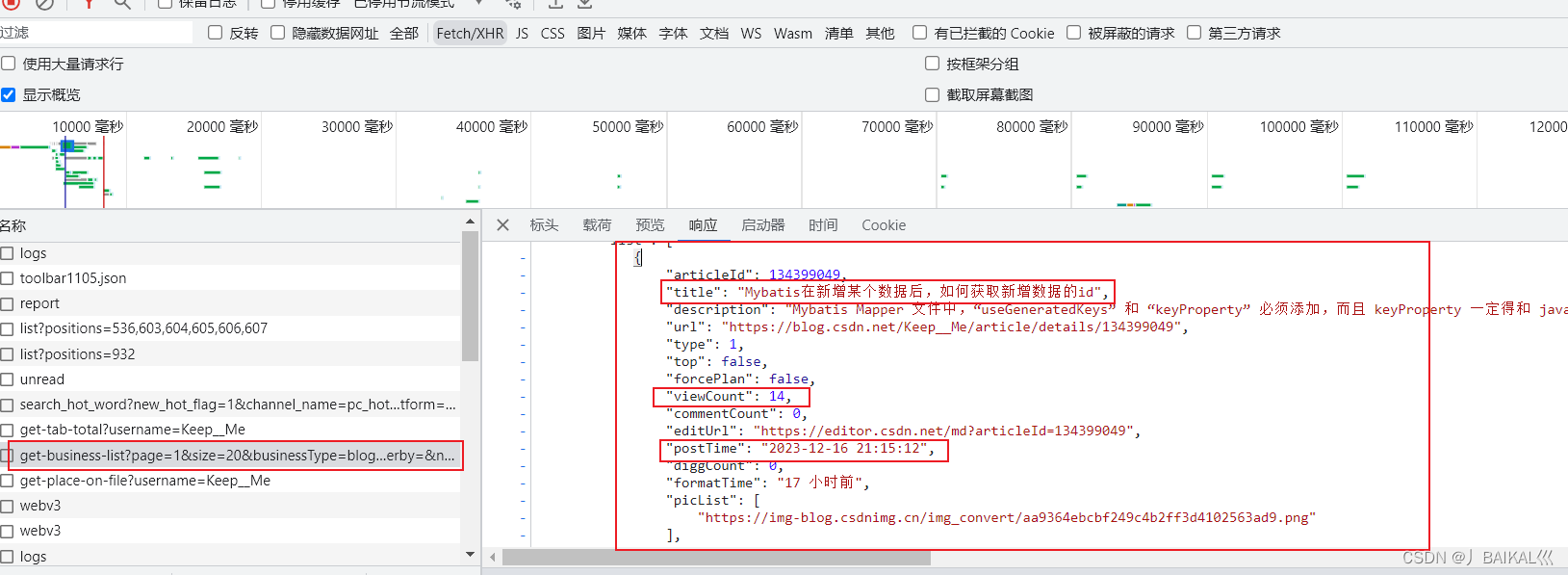
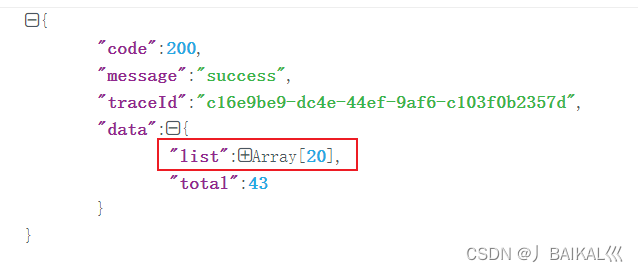
那有的人就会想问了,这里只有20条,如果我想获取更多的数据该怎么办呢?
我们直接调整请求的参数即可,我们直接到请求的标头中,把请求的url复制出来,更改这个size的参数。
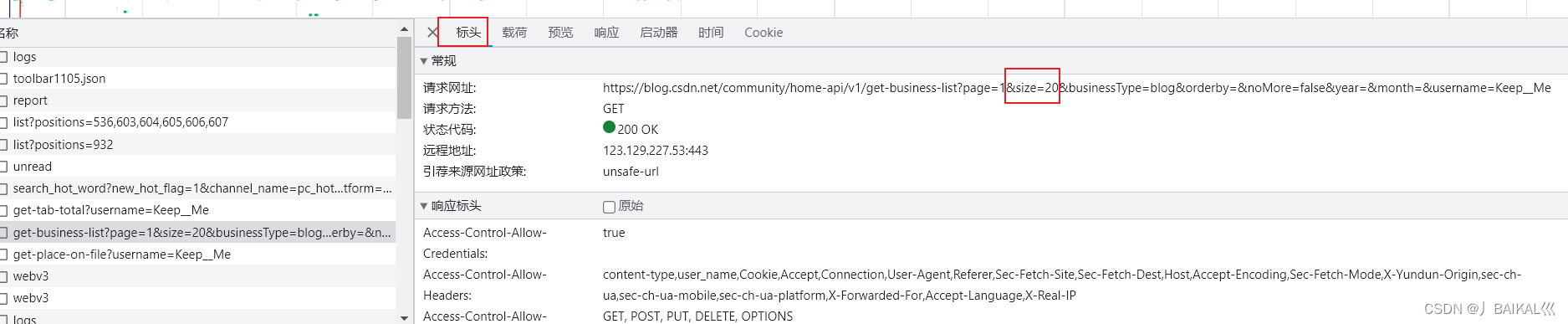
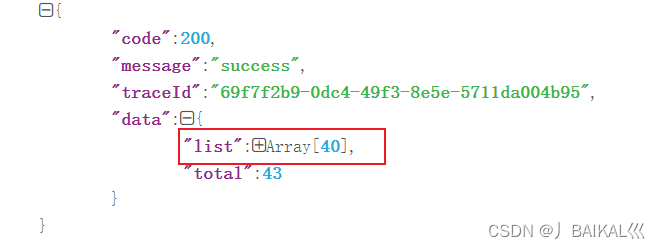
这里我们将size参数调整为40,发送请求,就得到了40条文章数据。
3、解析请求响应的json数据
这里直接参考代码即可,就是一层一层去解析json拿到对应的文章数据。
4、数据持久化
4.1 建文章数据库表
建表语句如下:
CREATE TABLE `article` (
`id` int(11) NOT NULL AUTO_INCREMENT COMMENT '主键自增id',
`title` varchar(255) NOT NULL COMMENT '文章标题',
`release_time` datetime NOT NULL COMMENT '发布时间',
`yesterday_views` int(11) DEFAULT '0' COMMENT '昨日阅读量',
`daily_views` int(11) NOT NULL DEFAULT '0' COMMENT '当天阅读量',
`weekly_views` int(11) NOT NULL DEFAULT '0' COMMENT '本周阅读量(周日)',
`create_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '记录创建时间',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=1359 DEFAULT CHARSET=utf8 COMMENT='csdn文章表';
4.2 创建文章实体类对象
实体类如下:
import java.util.Date;
import com.fasterxml.jackson.annotation.JsonFormat;
import org.apache.commons.lang3.builder.ToStringBuilder;
import org.apache.commons.lang3.builder.ToStringStyle;
/**
* csdn文章对象 article
*
* @author ruoyi
* @date 2023-10-15
*/
public class Article
{
private static final long serialVersionUID = 1L;
/** 主键自增id */
private Long id;
/** 文章标题 */
private String title;
/** 发布时间 */
@JsonFormat(pattern = "yyyy-MM-dd")
private Date releaseTime;
/** 昨日阅读量 */
private Long yesterdayViews;
/** 当天阅读量 */
private Long dailyViews;
/** 本周阅读量(周日) */
private Long weeklyViews;
public void setId(Long id)
{
this.id = id;
}
public Long getId()
{
return id;
}
public void setTitle(String title)
{
this.title = title;
}
public String getTitle()
{
return title;
}
public void setReleaseTime(Date releaseTime)
{
this.releaseTime = releaseTime;
}
public Date getReleaseTime()
{
return releaseTime;
}
public void setYesterdayViews(Long yesterdayViews)
{
this.yesterdayViews = yesterdayViews;
}
public Long getYesterdayViews()
{
return yesterdayViews;
}
public void setDailyViews(Long dailyViews)
{
this.dailyViews = dailyViews;
}
public Long getDailyViews()
{
return dailyViews;
}
public void setWeeklyViews(Long weeklyViews)
{
this.weeklyViews = weeklyViews;
}
public Long getWeeklyViews()
{
return weeklyViews;
}
@Override
public String toString() {
return new ToStringBuilder(this,ToStringStyle.MULTI_LINE_STYLE)
.append("id", getId())
.append("title", getTitle())
.append("releaseTime", getReleaseTime())
.append("yesterdayViews", getYesterdayViews())
.append("dailyViews", getDailyViews())
.append("weeklyViews", getWeeklyViews())
.append("createTime", getCreateTime())
.toString();
}
}
4.3 将数据封装到实体类中,并插入到数据库中
参考代码
二、完整的方法代码
/**
* 通过爬虫批量插入文章数据
* @return
*/
//@Override
public int insertArticleByCSDN() throws IOException, ParseException {
String url2="https://blog.csdn.net/community/home-api/v1/get-business-list?page=1&size=50&businessType=blog&orderby=&noMore=false&year=&month=&username=Keep__Me";
//获取的JSON接口数据
String list = sendGet(url2);
//System.out.println(list);
//定义一个空变量
JSONObject row = null;
//将获取的JSON数据存储到变量中
JSONObject jsonObject = JSON.parseObject(list);
//定义一个空对象
Article article;
int sum = 0;
if ("200".equals(jsonObject.getString("code"))) {
article=new Article();
JSONObject dataObject = jsonObject.getJSONObject("data");
// 获取 list 数组
JSONArray listArray = dataObject.getJSONArray("list");
if (listArray != null) {
for (int i = 0; i < listArray.size(); i++) {
JSONObject itemObject = listArray.getJSONObject(i);
// 解析 itemObject 中的各个属性
int articleId = itemObject.getIntValue("articleId");
String title = itemObject.getString("title");
article.setTitle(title);
String description = itemObject.getString("description");
String url = itemObject.getString("url");
int type = itemObject.getIntValue("type");
boolean top = itemObject.getBooleanValue("top");
boolean forcePlan = itemObject.getBooleanValue("forcePlan");
int viewCount = itemObject.getIntValue("viewCount");
Long dailyViews=(long)viewCount;
article.setDailyViews(dailyViews);
//获取当前是星期几
LocalDate today = LocalDate.now();
DayOfWeek dayOfWeek = today.getDayOfWeek();
String chineseDayOfWeek = dayOfWeek.getDisplayName(TextStyle.FULL_STANDALONE, Locale.CHINA);
if("星期日".equals(chineseDayOfWeek)){
article.setWeeklyViews(dailyViews);
}
int commentCount = itemObject.getIntValue("commentCount");
String editUrl = itemObject.getString("editUrl");
String postTime = itemObject.getString("postTime");
Date releaseTime = new SimpleDateFormat("yyyy-MM-dd").parse(postTime);
article.setReleaseTime(releaseTime);
int diggCount = itemObject.getIntValue("diggCount");
String formatTime = itemObject.getString("formatTime");
int collectCount = itemObject.getIntValue("collectCount");
Date nowDate = DateUtils.getNowDate();
article.setCreateTime(nowDate);
// 获取 picList 数组
JSONArray picListArray = itemObject.getJSONArray("picList");
if (picListArray != null) {
List<String> picList = new ArrayList<>();
for (int j = 0; j < picListArray.size(); j++) {
String picUrl = picListArray.getString(j);
picList.add(picUrl);
}
// 将解析出的数据保存到某个数据结构中(例如 JavaBean)
// ...
}
int i1 = articleMapper.insertArticle(article);
sum+=i1;
}
}