1 File类
1.1 File类概述
1.1.1 什么是File类
File是java.io包下作为文件和目录的类。File类定义了一些与平台无关的方法来操作文件,通过调用File类中的方法可以得到文件和目录的描述信息,包括名称、所在路径、读写性和长度等,还可以对文件和目录进行新建、删除及重命名等操作。

对于目录,Java把File类当作一种特殊类型的文件,即文件名单列表。但是File类不能读取文件内容,操作文件内容需要使用输入流和输出流。
1.1.2 构建 File 对象
File 的构造方法如下:
File(String pathname)通过将给定路径名字符串转换成抽象路径名来创建一个新 File 实例。
其中,路径可以是相对路径或者绝对路径。抽象路径应尽量使用相对路径,并且目录的层级分隔符不要直接写”/”或”\”,应使用File.separator 这个常量表示,以避免不同系统带来的差异。代码示意如下所示:
![]()
1.1.3 绝对路径和相对路径
绝对路径是指:无论当前工作目录如何,始终指向文件系统中的相同位置的路径。路径以盘符或/开头。
相对路径是指从某个给定的工作目录开始到目标位置的路径,路径不能以盘符或/开头。
比如查看如下示意:

对于文件 demo.txt,其绝对路径是固定的;但是如果当前工作目录不同,其相对路径的写法也不同。
1.1.4【案例】使用 File 类示例
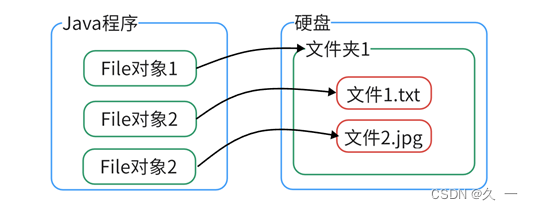
首先,创建案例访问的目标文件。在src目录下新建api_03包,在该包下新建一个demo.txt文件,并在该文件中编写任意文字并保存。然后构建 File 对象访问该文件,输出文件的各项信息。
代码示意如下:
package api_03;
import java.io.File;
public class FileDemo1 {
public static void main(String[] args) {
/*
* File创建时需要指定路径
* 路径通常用相对路径,因为绝对路径无法做到
* 平台无关性(window与linux的路径写法不同)
*
* 相对路径中"./"为当前目录,具体是哪里要看
* 当前程序的运行环境而定,在IDEA中运行
* 时,指的就是当前程序所在的项目目录
*/
File file = new File("./src/api_03/demo.txt");
//获取名字
String name = file.getName();
System.out.println(name);
//获取长度(单位是字节)
long length = file.length();
System.out.println(length+"字节");
boolean cr = file.canRead();
boolean cw = file.canWrite();
System.out.println("可读:"+cr);
System.out.println("可写:"+cw);
boolean ih = file.isHidden();
System.out.println("隐藏文件:"+ih);
}
}1.2 File类常用操作
1.2.1 File 操作文件
File的常用方法有:
1、length() 方法
- 返回由此抽象路径名表示的文件的长度(占用的字节量)
- 返回 long 类型的数值
2、exists() 方法
- 测试此抽象路径名表示的文件或目录是否存在
- 返回值:若该File表示的文件或目录存在则返回true,否则返回false
3、createNewFile() 方法
- 当且仅当不存在具有此抽象路径名指定的名称的文件时,创建由此抽象路径名指定的一个新的空文件
- 返回值:如果指定的文件不存在并成功地创建,则返回 true;如果指定的文件已经存在,则返回 false
4、delete() 方法:删除此抽象路径名表示的文件或目录
- 返回值:当且仅当成功删除文件或目录时,返回 true;否则返回 false
- 需要注意的是,若此File对象所表示的是一个目录时,在删除时需要保证此为空目录才可以成功删除(目录中不能含有任何子项)
1.2.2【案例】创建新文件示例
编写代码,使用File对象创建新文件。代码示意如下:
package api_03;
import java.io.File;
import java.io.IOException;
public class FileDemo2 {
public static void main(String[] args) throws IOException {
/*
* 在当前目录下新建文件:test.txt
*/
File file = new File("./src/api_03/test.txt");
/*
* boolean exists()
* 判断当前File表示的路径下是否已经存在
* 对应的文件或目录
*/
if(!file.exists()) {
file.createNewFile();
System.out.println("文件已创建!");
}else {
System.out.println("文件已存在!");
}
}
}1.2.3【案例】删除文件示例
编写代码,使用File对象删除文件。代码示意如下:
package api_03;
import java.io.File;
public class FileDemo3 {
public static void main(String[] args) {
/*
* 将当前目录下的test.txt文件删除
*/
File file = new File("./src/api_03/test.txt");
if(file.exists()) {
file.delete();
System.out.println("文件已删除!");
}else {
System.out.println("文件不存在!");
}
}
}1.2.4 File 创建目录
File创建目录时,常用方法有:
1、isDirectory() 方法:判断当前File表示的是否为一个目录,返回 boolean 类型
2、mkdir() 方法:
- 创建此抽象路径名指定的目录
- 当且仅当已创建目录时,返回 true;否则返回 false
3、mkdirs() 方法:
- 创建此抽象路径名指定的目录,包括所有必需但不存在的父目录
- 当且仅当已创建目录以及所有必需的父目录时,返回 true;否则返回 false
- 注意:此操作失败时也可能已经成功地创建了一部分必需的父目录
1.2.5【案例】创建目录示例
编写代码,使用File对象创建目录。代码示意如下:
package api_03;
import java.io.File;
public class FileDemo4 {
public static void main(String[] args) {
/*
* 当前目录下新建一个demo目录
*/
File dir = new File("./src/api_03/demo");
if(!dir.exists()) {
dir.mkdir();
System.out.println("目录已创建!");
}else {
System.out.println("目录已存在!");
}
/*
* 当前目录下新建多级目录
* d1/d2/d3
*/
File dir2 = new File("./src/api_03/d1/d2/d3");
if(!dir2.exists()) {
/*
* 该方法会将所有不存在的父目录一同
* 创建出来.而mkdir方法若父目录不存在
* 则创建失败.
*/
dir2.mkdirs();
System.out.println("多级目录已创建!");
}else {
System.out.println("多级目录已存在!");
}
}
}1.2.6 File 删除目录
File删除目录时,使用delete() 方法:删除此抽象路径名表示的文件或目录。当且仅当成功删除文件或目录时,返回 true;否则返回 false
需要注意的是,若此File对象所表示的是一个目录时,在删除时需要保证此为空目录才可以成功删除(目录中不能含有任何子项)。
1.2.7【案例】删除空目录示例
编写代码,使用File对象删除空目录。代码示意如下:
package api_03;
import java.io.File;
public class FileDemo5 {
public static void main(String[] args) {
File dir = new File("./src/api_03/d1/d2/d3");
if(dir.exists()) {
/*
* delete方法删除目录时要求目录
* 必须是空目录,否则不删除
* true-删除成功 false-其他
*/
boolean flag = dir.delete();
if (flag){
System.out.println("目录已删除!");
}else{
System.out.println("删除失败!");
}
}else {
System.out.println("目录不存在!");
}
}
}1.2.8 获取目录的所有子项
当目录含有子目录时,可以使用listFiles() 方法:返回一个抽象路径名数组,这些路径名表示此抽象路径名表示的目录中的子项(文件或目录)。
返回类型为 File[ ],即抽象路径名数组,这些路径名表示此抽象路径名表示的目录中的文件和目录。
- 如果目录为空,那么数组也将为空
- 如果抽象路径名不表示一个目录,或者发生 I/O 错误,则返回 null
1.2.9【案例】获取当前目录下所有子项示例
编写代码,获取当前目录下的所有子项,并打印输出信息。代码示意如下:
public class FileDemo6 {
public static void main(String[] args) {
File dir = new File("./src/api_03");
/*
* boolean isFile()
* 判断当前File表示的是否为文件
*
* boolean isDirectory()
* 判断当前File表示的是否为目录
*/
if(dir.isDirectory()) {
/*
* File[] listFiles()
* 获取当前目录下的所有子项,以一个File数组
* 形式返回,每个元素表示其中一个子项
*/
File[] subs = dir.listFiles();
System.out.println(subs.length);
for(int i=0;i<subs.length;i++) {
System.out.println(subs[i].getName());
}
}
}
}1.2.10 方法的递归
在计算机科学中,递归(Recursion)是一种解决计算问题的方法,其中的解决方案取决于同一问题的较小实例的解决方案。递归通过使用从自身方法中调用自身方法来解决此类递归问题。 该方法可以应用于多种类型的问题,递归是计算机科学的核心思想之一。Java支持递归,在 Java 编程中,递归是允许方法调用自身方法。
1.2.11 经典的求文件夹大小问题
在使用电脑管理文件时,我们经常会查看一个文件夹的大小。文件夹的大小,等于该文件夹各级文件夹中所有文件的大小总和。
假设有文件夹1如下图所示:

此时,文件夹1的总大小为:文件1的大小+文件夹2的大小;文件夹2又等于文件2+文件3;所以总和为 23KB。
这是在确定已知文件夹1只有如图所示的下级内容时。如果不确定文件夹1下有多少级目录,也不确定每个目中有多少个文件,如何来统计呢?
这适用于用递归的思路来解决。
假设有方法 getFile(File file),用于计算文件 file 的大小:
- 如果传入的 file 是文件,则直接获取并返回该文件的大小
- 如果传入的 file 是文件夹,则遍历该文件夹下的每一个子目录,并对每个子目录调用 getFile() 方法,并且把子目录作为参数传入,并对获取到的文件大小求和
逻辑过程如下图所示:

递归的过程如下图所示:

由此可见,使用递归可以解决经典的求文件夹大小的问题。
但是,在使用递归时,必须注意:
1、递归次数尽量少,因为递归的开销较大,效率较差
2、递归操作必须被一个分支语句控制,有条件的执行,否则会出现死循环,并最终造成内存溢出
1.2.12【案例】求文件夹大小示例
编写代码,获取文件夹的大小,并打印输出信息。代码示意如下:
package api_03;
import java.io.File;
/**
* 递归示例
* 求api_03文件夹的大小
*/
public class RecursionDemo {
public static void main(String[] args) {
File file = new File("./src/api_03");
long sum = getSize(file);
System.out.println("size = " + sum+" bytes");
}
public static long getSize(File file){
if (file.isFile()){
return file.length();
}else{
File[] files = file.listFiles();
long sum = 0;
for(int i = 0; i < files.length; i++){
sum += getSize(files[i]);
}
return sum;
}
}
}1.2.13 FileFilter接口
FileFilter 是用于抽象路径名的过滤器,此接口的实例可传递给 File 类的 listFiles(FileFilter) 方法,用于返回满足该过滤器要求的子项。使用方式如下所示:
File[] listFiles(FileFilter filter)返回符合要求的 File 对象数组。
1.2.14【案例】文件过滤器示例
编写代码,统计某目录下所有以F开头的文件个数及名称,并打印输出信息。代码示意如下:
package api_03;
import java.io.File;
import java.io.FileFilter;
/**
* 统计api_03目录下所有以F开头的文件个数及名称
*/
public class FileDemo7 {
public static void main(String[] args) {
File dir = new File("./src/api_03");
if(dir.isDirectory()) {
FileFilter filter = new FileFilter() {
public boolean accept(File file) {
String name = file.getName();
System.out.println("正在过滤:"+name);
return name.startsWith("F");
}
};
File[] subs = dir.listFiles(filter);
System.out.println(subs.length);
for(int i=0;i<subs.length;i++) {
System.out.println(subs[i].getName());
}
}
}
}2 I/O 流
2.1 I/O流概述
2.1.1 什么是 I/O流
在计算机中,input/output(I/O、i/o 或非正式的 io 或 IO)是信息处理系统(例如计算机)与外界(可能是人类或其他信息处理系统)之间的通信。 输入是系统接收到的信号或数据,输出是系统发送的信号或数据。
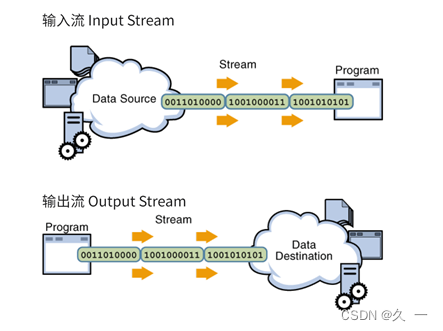
Java将数据的输入/输出(I/O)操作当作流处理,流是一组有序的数据序列,也可称为数据流。
数据流分为两种形式:输入流和输出流。站在当前系统的角度,数据流入系统的是输入流,数据流出系统的是输出流。如下图所示:
2.1.2 I/O的流分类
为支持Java程序的I/O操作,Java在java.io包下提供了丰富的I/O相关API(80余个类和接口)。为了快速掌握Java I/O的核心API,需要先了解I/O流的分类。
可以按照不同的角度对流进行分类:
1、按照数据流的方向不同可以分为输入流和输出流
2、按处理数据单位不同可以分为字节流和字符流
3、按使用方式不同可分为节点流与处理流,也称为基础流和高级流
- 节点流:真实连接数据源与程序之间的"管道",负责实际搬运数据的流,读写一定是建立在节点流的基础上进行的
- 处理流:不能独立存在,必须连接在其它流上,使得在读写数据的过程中,当数据流经当前处理流时对其做某些加工处理,简化我们对数据的相关操作
实际应用中我们会串联一组高级流并最终连接到基础流上,使得对数据的读写以流水线加工的方式实现。这个过程称为流的连接,也是IO的精髓所在。

2.2 字节流
2.2.1 字节流概述
字节流,顾名思义,是指数据流中的数据以字节为单位进行操作,主要用于处理二进制数据。
InputStream和OutputStream是字节流的核心类,是2个抽象类,定义了基础的数据流读写方法,字节流中的其他类均为两个类的子类。
FileInputStream和FileOutputStream是字节流中最为常用的类,分别继承自InputStream和OutputStream,属于基础流。
BufferedInputStream和BufferedOutputStream是字节流中较为常用的高级流,间接继承自InputStream和OutputStream,主要提供了缓冲区功能。
2.2.2 创建 FOS 对象
FileOutputStream,是文件的字节输出流,可以以字节为单位将数据写入文件。
其构造方法有:
- FileOutputStream(File file):创建一个向指定 File 对象表示的文件中写数据的文件输出流
- FileOutputStream(String filename):创建一个向具有指定名称的文件中写数据的文件输出流
这里需要注意:若指定的文件已经包含内容,那么当使用FOS对其写入数据时,会将该文件中原有数据全部清除。
若想在文件的原有数据之后追加新数据则需要以下构造方法创建FOS:
- FileOutputStream(File file,boolean append):创建一个向指定 File 对象表示的文件中写数据的文件输出流
- FileOutputStream(String filename,boolean append):创建一个向具有指定名称的文件中写数据的文件输出流
以上两个构造方法中,第二个参数若为true,那么通过该FOS写出的数据都是在文件末尾追加的。
2.2.3【案例】FileOutputStream示例
编写代码,向文件写入数据:分别测试覆盖写操作和追加写操作。代码示意如下:
package api_03;
import java.io.FileOutputStream;
import java.io.IOException;
public class FileOutputDemo {
public static void main(String[] args) throws IOException {
/*
* 文件输出流有两种创建方式,分别表示的是覆盖写操作和追加写操作
* 构造方法如下:
* FileOutputStream(File file)
* FileOutputStream(String path)
* 以上形式创建的文件流是覆盖写模式,当创建时指定的文件已经存在,则会将该
* 文件数据全部清除,然后通过当前流写出的内容作为该文件的数据
*
* FileOutputStream(File file,boolean append)
* FileOutputStream(String path,boolean append)
* 当构造方法第二个参数为true时,当前文件流为追加写模式,
* 即:若文件已经存在,原有数据保留,通过当前流写出的内容都被追加到文件中。
*/
FileOutputStream fos = new FileOutputStream("./src/api_03/fos.txt", true);
// String str = "这是第一次写出的内容\n";
String str = "这是第二次写出的内容\n";
byte[] data = str.getBytes("utf-8");
fos.write(data);
System.out.println("写出完毕!");
fos.close();
}
}2.2.4 创建 FIS 对象
FileInputStream(常简称为 FIS对象),作为文件的字节输入流,使用该流可以以字节为单位从文件中读取数据。
FileInputStream有两个常用的构造方法:
- FileInputStream(File file):创建一个从指定 File 对象表示的文件中读取数据的文件输入流
- FileInputStream(String name):创建用于读取给定的文件系统中的路径名name所指定的文件的文件输入流
2.2.5 读和写
FileInputStream继承自InputStream,其提供了以字节为单位读取文件数据的方法read:
- int read():从此输入流中读取一个数据字节,若返回-1则表示EOF(End Of File)
- int read(byte[] b):从此输入流中将最多 b.length 个字节的数据读入到字节数组b中
FileOutputStream继承自OutputStream,其提供了以字节为单位向文件写数据的方法write:
- void write(int d):将指定字节写入此文件输出流,这里只写给定的int值的”低八位”
- void write(byte[] d):将 b.length 个字节从指定 byte 数组写入此文件输出流中
- void write(byte[] d,int offset,int len):将指定 byte 数组中从偏移量 off 开始的 len 个字节写入此文件输出流
2.2.6【案例】FileInputStream示例
编写代码,读取文件内容。代码示意如下:
package api_03;
import java.io.FileInputStream;
import java.io.IOException;
public class FileInputDemo {
public static void main(String[] args) throws IOException {
FileInputStream fis
= new FileInputStream("./src/api_03/fos.txt");
// 存放读取到的数据的容器
byte[] data = new byte[1024];
// 执行一次读取,将读到的数据存入data中
int len = fis.read(data);
System.out.println("实际读取到了"+len+"个字节");
String str = new String(data,0,len,"utf-8");
System.out.println(str);
fis.close();
}
}2.2.7 【案例】文件复制示例
编写代码,实现文件复制。代码示意如下:
package api_03;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
public class FileCopyDemo1 {
public static void main(String[] args) throws IOException {
/*
* 1:创建文件输入流,用于读取原文件
* 2:创建文件输出流,用于写复制文件
* 3:循环从原文件读取一组字节并写入
* 到复制文件中,完成复制工作
* 4:关闭两个流
*/
FileInputStream fis
= new FileInputStream("./src/api_03/fos.txt");
FileOutputStream fos
= new FileOutputStream("./src/api_03/fos_cp.txt");
byte[] data = new byte[1024*10];
int len = -1;
// 当读取到流的末尾时,会返回-1
while((len = fis.read(data))!=-1) {
// 注意规避数组中的冗余数据
fos.write(data,0,len);
}
System.out.println("复制完毕!");
fis.close();
fos.close();
}
}在上述操作中,需要特别注意读取到流的末尾时可能遇到的数组中数据冗余问题。

2.3 缓冲流
2.3.1 字节缓冲流概述
当对文件或其他数据源进行频繁的读/写操作时,效率比较低,这时如果使用缓存流就能够更高效地读/写信息。
比如,可以使用缓冲输出流来一次性批量写出若干数据减少写出次数来提高写出效率。
如果用生活中的例子做比方,则如下图所示:

相对于每次都直接从原罐中舀取的操作而言,可以先把物品舀取到一个容器中(相当于缓存),再使用容器去运输。
2.3.2 BIS 与 BOS
BufferedInputStream和BufferedOutputStream称为字节缓存流。它们本身并不具有输入/输出流的读取与写入功能,只是在其他流上加上缓存功能提高效率,就像是把其他流包装起来一样,因此,缓存流是一种处理流。
BufferedInputStream:字节缓存流内置一个缓存区,第一次调用read()方法时尽可能将数据源的数据读取到缓存区中,后续再用read()方法时先确定缓存区中是否有数据,若有则读取缓存区中的数据,当缓冲区中的数据用完后,再实际从数据源读取数据到缓存区中 ,这样可以减少直接读数据源的次数。
BufferedOutputStream:通过输出流调用write()方法写入数据时,先将数据写入缓存区中,缓存区满了之后再将缓冲区中的数据一次性写入数据目的地。使用缓存字节流可以减少输入/输出操作的次数,以提高效率。
2.3.3 【案例】缓冲流文件复制示例
编写代码,使用字节缓冲流实现文件复制。代码示意如下:
package api_03;
import java.io.*;
public class FileCopyDemo2 {
public static void main(String[] args) throws IOException {
// 随机选取本地一个文件即可,本例中的文件大小为112MB
FileInputStream fis
= new FileInputStream("D:/Development/nacos-server-2.0.3.zip");
BufferedInputStream bis
= new BufferedInputStream(fis); // 默认缓冲区大小 8192字节
FileOutputStream fos
= new FileOutputStream("D:/Development/nacos-server-2.0.3_cp.zip");
BufferedOutputStream bos
= new BufferedOutputStream(fos); // 默认缓冲区大小 8192字节
int d = -1;
long start = System.currentTimeMillis();
while((d = bis.read())!=-1) {
bos.write(d);
}
long end = System.currentTimeMillis();
System.out.println("复制完毕!耗时"+(end-start)+"ms"); // 1566ms
bis.close();
bos.close();
}
}2.3.4 flush 方法
输出流缓冲流提供了flush方法:强制将当前缓冲区中已经缓存的字节一次性写出。可以提高数据写出的即时性,但同样也增加了实际写出的次数,一定程度上降低了写出效率。
在输出流缓冲流的close方法中默认也会调用一次flush方法:保证在关流操作之前清空缓冲区,以避免缓冲区中的数据未能全部输出的情况。
2.3.5 【案例】flush方法示例
编写代码,测试 flush 方法。代码示意如下:
package api_03;
import java.io.BufferedOutputStream;
import java.io.FileOutputStream;
import java.io.IOException;
public class BOSFlushDemo {
public static void main(String[] args) throws IOException {
FileOutputStream fos
= new FileOutputStream("./src/api_03/fos2.txt");
BufferedOutputStream bos
= new BufferedOutputStream(fos);
String str = "这是我们输出的文字";
byte[] data = str.getBytes("utf-8");
bos.write(data);
// bos.flush();
System.out.println("写出完毕!");
/*
* 缓冲流关闭前会调用一次flush方法.
*/
// bos.close();
}
}2.4 序列化与反序列化
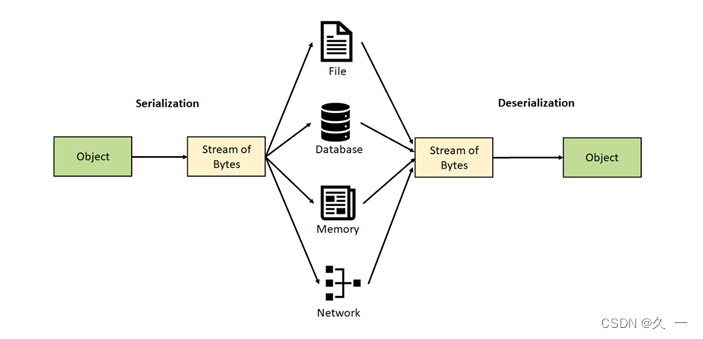
2.4.1 对象序列化概念
对象是存在于内存中的,有时候我们需要将对象保存到硬盘上,又有时我们需要将对象传输到另一台计算机上等等这样的操作。这时我们需要将对象转换为一个字节序列,而这个过程就称为对象序列化
相反,我们有这样一个字节序列需要将其转换为对应的对象,这个过程就称为对象的反序列化。
如下图所示:

2.4.2 序列化与反序列化
序列化是指先将内存中对象的相关信息(包括类、数字签名、对象除transient和static之外的全部属性值,以及对象的父类信息等)进行编码,再传输到数据目的地的过程。
如果与序列化的顺序相反,就叫反序列化,将序列化的对象信息从数据源中读取出来,并重新解码组装为内存中一个完整的对象。
如下图所示:
2.4.3 OIS 与 OOS
Java中的序列化和反序列化是通过对象流来实现的,分别是ObjectInputStream和ObjectOutputStream。
ObjectOutputStream:对对象进行序列化的输出流,其实现对象序列化的方法为:
void writeObject(Object o)该方法可以将给定的对象转换为一个字节序列后写出 。
ObjectInputStream:对对象进行反序列化的输入流,其实现对象反序列化的方法为:
Object readObject(),该方法可以从流中读取字节并转换为对应的对象。
2.4.4 Serializable接口
当使用对象流写入或读取对象时,需要保证对象是可序列化的。这是为了保证能把对象写入文件中,并且能再把对象正确地读回到程序中。一个类如果实现了Serializable接口,那么这个类创建的对象就是可序列化的对象。Java中的包装类和String类均实现了Serializable接口。
Serializable接口中的方法对程序是不可见的,因此实现该接口的类不需要实现额外的方法,只是作为可序列化的标志。
如果把一个序列化的对象写入ObjectInputStream中,Java虚拟机就会实现Serializable接口中的方法,将一定格式的数据(对象的序列化信息)写入目的地中。当使用ObjectInputStream从数据源中读取对象时,就会从数据源中读回对象的序列化信息,并根据对象的序列化信息创建一个对象。
2.4.5 transient关键字
对象在序列化后得到的字节序列往往比较大,有时我们在对一个对象进行序列化时可以忽略某些不必要的属性,从而对序列化后得到的字节序列”瘦身”。此时,可以对不需要序列化的属性使用关键字 transient:被该关键字修饰的属性在序列化时其值将被忽略。
2.4.6 【案例】序列化示例
首先,创建示例使用的Person类:包含4个属性,其中一个属性添加transient关键字修饰。代码示意如下:
package api_03;
import java.io.Serializable;
import java.util.Arrays;
public class Person implements Serializable {
String name;
int age;
String gender;
// 使用 transient修饰的属性不会参与序列化
transient String[] otherInfo;
public Person(String name, int age, String gender, String[] otherInfo) {
this.name = name;
this.age = age;
this.gender = gender;
this.otherInfo = otherInfo;
}
@Override
public String toString() {
return "Person{" +
"name='" + name + '\'' +
", age=" + age +
", gender='" + gender + '\'' +
", otherInfo=" + Arrays.toString(otherInfo) +
'}';
}
}main方法中添加代码,实现Person 对象的序列化。代码示意如下:
package api_03;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.ObjectOutputStream;
public class SerializationDemo {
public static void main(String[] args) throws IOException {
String name = "苍老师";
int age = 40;
String gender = "男";
String[] otherInfo = {"Java讲师","来自中国","会拍抖音"};
Person p = new Person(name, age, gender, otherInfo);
FileOutputStream fos
= new FileOutputStream("./src/api_03/person.obj");
ObjectOutputStream oos
= new ObjectOutputStream(fos);
/*
这里流连接的操作分别为:
1:先将给定对象通过对象流写出,此时对象流会将该对象转换为一组字节,这个过程称
为对象序列化
2:序列化后的字节再通过文件流写入了文件,即:写入磁盘中,这个过程称为数据持久
化
*/
oos.writeObject(p);
System.out.println("写出完毕!");
oos.close();
}
}2.4.7 【案例】反序列化示例
Main方法中添加代码,实现Person 对象的反序列化。代码示意如下:
package api_03;
import java.io.FileInputStream;
import java.io.IOException;
import java.io.ObjectInputStream;
public class DeSerializationDemo {
public static void main(String[] args) throws IOException, ClassNotFoundException {
FileInputStream fis
= new FileInputStream("./src/api_03/person.obj");
ObjectInputStream ois
= new ObjectInputStream(fis);
Person p = (Person)ois.readObject();
// otherInfo属性值为null,因为是transient修饰的
System.out.println(p);
ois.close();
}
}2.4.8 经典面试题目:I/O流分类的方式包括以下几个方面:
按照数据流的方向分类:
- 输入流(Input Stream):用于从外部读取数据到程序中。
- 输出流(Output Stream):用于将程序中的数据输出到外部。
按照数据的单位分类:
- 字节流(Byte Stream):以字节为单位进行读写操作,适用于处理二进制数据或字节流形式的文本数据。
- 字符流(Character Stream):以字符为单位进行读写操作,适用于处理文本数据,能够正确处理字符编码和跨平台的字符表示。
按照流的角色分类:
- 节点流(Node Stream):直接与数据源或目标进行交互,可以读写字节或字符。
- 处理流(Processing Stream):对已存在的流进行包装,提供了额外的功能或对数据进行处理。







![[论文笔记] GAMMA: A Graph Pattern Mining Framework for Large Graphs on GPU](https://img-blog.csdnimg.cn/direct/f60b98607e08477b9735657df6d4bf89.png)