GAMMA: A Graph Pattern Mining Framework for Large Graphs on GPU
GAMMA: 基于 GPU 的针对大型图的图模式挖掘框架 [Paper] [Code]
ICDE’23
摘要
提出了一个基于 GPU 的核外(out-of-core) 图模式挖掘框架(Graph Pattern Mining, GPM) GAMMA, 充分利用主机内存来处理大型图.
- GAMMA 采用对用户透明的自适应隐式主机内存访问方式.
- 针对 GAMMA 在核心外 GPU 系统中提供的原语提出了一些优化
I. 介绍
GPM 算法通常产生大量中间结果. 本文关注使用硬件加速器 (GPU) 的 GPM 算法的高效计算.
已经提出的 GPM 框架中大多数基于 CPU, 性能不令人满意.
现有基于 GPU 的工作侧重于设计特定的 GPM 算法, 仅 Pangolin 一个基于 GPU 的 GPM 框架. Pangolin 的工作假设是图和中间结果可以驻留 GPU 设备内存中, 但 GPM 算法产生大量中间结果而 GPU 设备内存有限, 这致使其不能处理大型图.
为了在 GPU 上处理大型图, 现有工作将图划分并显示传输到 GPU 进行处理; 但需要特定于任务的划分策略, 会导致冗余内存传输和额外时间重组开销. 最好避免这些开销.
本文目标是为 GPU 设备内存无法容纳的图设计一个核外 GPM 框架.
面临挑战和解决方法:
- 挑战: 在 CPU-GPU 异构平台上存储和访问大型图数据和中间结果.
解决: 采用隐式主机内存访问方法, 将主机内存和设备内存变成统一的地址空间.
提出了一种基于访问量化模型的自适应访问方法, 以及考虑数据局部性的数据结构. - 挑战: 解决在核外 GPU 系统上处理大型图而导致的计算瓶颈: 线程产生的输出数量的不确定性和大量冗余计算, 以及超过设备内存大小的数据排序.
解决: 三种原语的优化:- 动态设备内存分配策略, 解决扩展过程中数量的不确定性
- 对多个扩展过程进行分组以减少冗余计算
- 实现了一个针对超过设备内存大小的数据的高效的排序算法.
GAMMA 是第一个可处理超过设备内存容量的大型图的核外 GPM 框架.
文章贡献:
- 提出了一个基于 GPU 的 GPM 框架, GAMMA, 其使用主机内存来处理大型图. 为用户算法提供了灵活有效的接口.
- 构建了一种自适应方法来确定使用不同的访问主机内存的模式(统一和零拷贝), 以消除主机内存和设备内存间的带宽差距.
- 对现有 GPM 框架原语提出了三种针对大型图的优化.
- GAMMA 在可扩展性和性能方面有很大提高.
II. 预备知识
A. 异构系统架构

B. 主机内存访问
在 GPU 上处理大型图的方式:
显示内存转移: 将图的每个部分移至设备内存. 两种实现方式:
- 对大型图划分, 使每个分区适合设备内存.
引入了额外数据传输成本并降低了 GPU 利用率.
特定于任务的数据划分方案不能支持通用 GPM 框架. - 细粒度数据传输: 在主机内存中收集所需数据, 并重组为压缩结构, 再传输到设备.
在 CPU 上进行的数据提取和重组开销很大.
不适用于在核外 GPU 上的大规模 GPM.
隐式内存访问: 将主机内存和设备内存统一到统一地址空间, 所需数据可从 CPU 实时获取. 对用户透明. 数据传输与计算重叠, 发出内存请求的线程将切换到 GPU 直到获取到所需数据. GAMMA 中使用隐式内存访问. 两种隐式内存访问模式:
- 统一内存(unified memory): 将主机和设备内存视为统一内存空间, 数据驻留在两侧. 设备向驻留在主机内存中的数据发出访问请求时, 会产生页面错误(page fault), 然后数据页面(通常 4KB)迁移至设备并进行缓存. 这会导致页面错误处理和长的迁移延迟, 但后续对该页面的访问可直接引用设备中的缓存.
对具有良好空间或时间局部性的数据友好. - 零拷贝内存(zero-copy memory): 以 128B 为单位的数据传输, 几乎没有额外数据迁移开销, 在设备上没有缓冲区.
适用于孤立的不频繁访问的数据.
III. GAMMA 设计概览
A. 嵌入表
B. 执行工作流
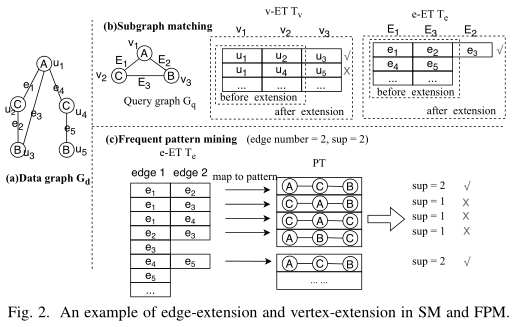
GAMMA 采用 “extension-aggregation-filter” 三阶段执行过程.
- Extension: 扩展一个结点或边
- Aggregation: 将嵌入表 E T ET ET 映射到模式图表 P T PT PT 中, 并在 P T PT PT 上计算聚合函数.
- Filtering: 允许用户指定对嵌入的约束条件.
C. 实现 GPM 任务 - 示例

- 子图同构(Subgraph Isomorpism): 最坏情况最优连接(worst-case optimal join, WOJ)子图匹配

- 频繁模式图挖掘(Frequent Pattern Mining, FPM)

IV. 图数据存储和访问
数据图用压缩稀疏行(CSR)表示. 在主机内存中维护数据图.
对于每个页面
p
p
p, 计算在下一个扩展中访问
p
p
p 中的数据量:
如果要访问
p
p
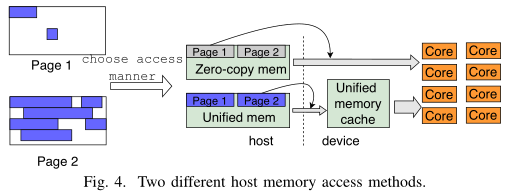
p 的很大一部分(图 4 页面 2), 则对
p
p
p 采用统一内存访问(多个线程访问同一页面
p
p
p);否则,
p
p
p 采用零拷贝内存访问(图 4 页面 1).
- 空间局部性(Spatial Locality): 定义了页面中有多少数据将被访问.
S p a t i a l L o c i ( p ) = ∑ l ( v ) ∈ p ∧ l ( v ) ∈ A i ∣ l ( v ) ∣ × t i m e s i ( l ( v ) ) SpatialLoc_i(p)=\sum_{l(v)\in p\wedge l(v)\in A_i}|l(v)|\times times_i(l(v)) SpatialLoci(p)=l(v)∈p∧l(v)∈Ai∑∣l(v)∣×timesi(l(v))- A i A_i Ai: 第 i i i 个扩展中所有访问的邻接表
- l ( v ) l(v) l(v): 结点 v v v 的邻接表
- t i m e s i ( l ( v ) ) times_i(l(v)) timesi(l(v)): 第 i i i 个扩展中访问 l ( v ) l(v) l(v) 的次数
- 空间局部性(Temporal Locality):
T e m p L o c i ( p ) = ∑ j ≤ i − 1 ∑ l ( v ) ∈ p ∧ l ( v ) ∈ A i ∣ l ( v ) ∣ × t i m e s j ( l ( v ) ) TempLoc_i(p)=\sum_{j\leq i-1}\sum_{l(v)\in p\wedge l(v)\in A_i}|l(v)|\times times_j(l(v)) TempLoci(p)=j≤i−1∑l(v)∈p∧l(v)∈Ai∑∣l(v)∣×timesj(l(v)) - 访问热度(Access Heat): 结合空间局部性和时间局部性来建模页面被访问的可能性.
A c c H e a t i ( p ) = A i ∑ j ≤ i A j × S p a t i a l L o c i ( p ) + ∑ j ≤ i − 1 A j ∑ j ≤ i A j × T e m p L o c i ( p ) AccHeat_i(p)=\frac{A_i}{\sum_{j\leq i}A_j}\times SpatialLoc_i(p)+\frac{\sum_{j\leq i-1}A_j}{\sum_{j\leq i}A_j}\times TempLoc_i(p) AccHeati(p)=∑j≤iAjAi×SpatialLoci(p)+∑j≤iAj∑j≤i−1Aj×TempLoci(p)
每次扩展后更新每个页面的
A
c
c
H
e
a
t
i
(
p
)
AccHeat_i(p)
AccHeati(p), 并以此确定接下来扩展的内存访问方法:
通过统一内存访问的页面最大数量
N
u
N_u
Nu 由设备缓冲区大小确定.
A
C
C
H
e
a
t
ACCHeat
ACCHeat 最大的
N
u
N_u
Nu 个页面采用统一内存方式访问, 其余数据采用零拷贝内存方式访问.
V. GAMMA: 实现和优化
A. 嵌入表
数据结构:
使用前缀树存储嵌入, 并在 “filtering” 阶段后压缩嵌入表.
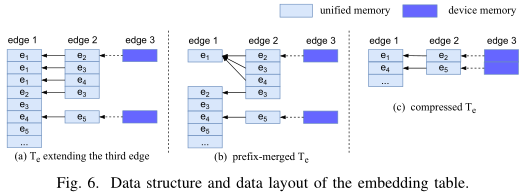
嵌入表压缩操作:
- 分别标记有效嵌入和无效嵌入.
- 对所有标记进行前缀扫描, 从而确定有效嵌入在压缩后的新位置.
- 并行收集有效嵌入构成压缩嵌入表.
数据布局:
嵌入表以列优先的方式存储: 结点(或边)的每一列连续存储; 每个顶点(或边)都有指向同一嵌入中前一结点的指针.
嵌入表驻留主机内存中, 采用统一内存访问方式.
在设备保留一个缓冲区写入扩展结果, 扩展后再刷新(flush)数据至主机内存.
B. 原语优化
挑战 1: 并行写冲突
每个线程产生的结果数量不确定, 并行线程不知道开始写入的位置.
优化 1: 动态内存分配策略: 内存被分成许多内存块, 构成内存池.

wrap 间写冲突: 每个 wrap 被分配 1 个内存块用于写入嵌入扩展结果, 内存块写满后再请求新内存块.
wrap 内线程间写冲突: warp 级前缀扫描 (可借助 wrap 的 SIMT 特性).
GPU 内核仅有几百个活动的 wrap 且每个 wrap 每次只请求一个新内存块, 从而限制了由于 warp 间内存块分配竞争产生的额外时间开销.
挑战 2: 冗余计算
多个列表交集中的冗余计算.
优化 2: 预先对多个邻接表求交集获得交集列表, 利用 GPU 共享内存(shared memory)来存储交集列表

挑战 3: 基于 GPU 的外部排序
大多数基于 GPU 的排序算法都假设输入适合 GPU 内存, 且超过 GPU 内存的两种方法没有充分利用 GPU 并行性.
优化 3: 优化的核外 GPU 排序算法.
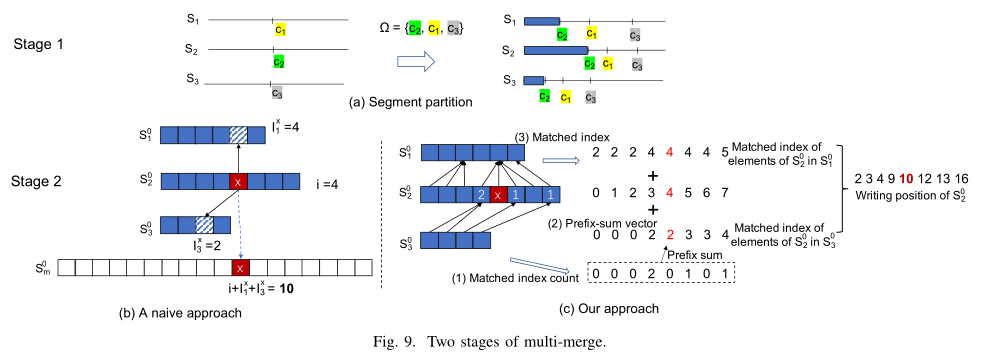
首先将模式图表
P
T
PT
PT 划分为片段
S
i
(
i
=
1
,
.
.
.
,
n
)
S_i(i=1,...,n)
Si(i=1,...,n), 使每个片段
S
i
S_i
Si 可通过核内 GPU 排序算法进行排序.
n
n
n 个排序后的片段
S
i
S_i
Si 写回主机内存后, 使用多路归并算法(Algorithm 3)合并.

- Line 2: 将每个片段 S i S_i Si 由检查点(checkpoint) C i C_i Ci 分成数量相同的 p s i z e p_{size} psize 大小的两部分. Ω = { C 1 , . . . C i , . . . , C ∣ Ω ∣ } ( ∣ Ω ∣ ≤ n ) \Omega=\{C_1,...C_i,...,C_{|\Omega|}\}\ (|\Omega|\leq n) Ω={C1,...Ci,...,C∣Ω∣} (∣Ω∣≤n)
- Line 4: 对每个检查点
x
=
C
i
∈
Ω
x=C_i\in\Omega
x=Ci∈Ω 找对应的匹配索引
§
i
\S_i
§i. 并利用
∣
Ω
∣
|\Omega|
∣Ω∣ 个检查点的匹配索引
§
i
\S_i
§i将每个片段
S
i
S_i
Si 分成
∣
Ω
∣
+
1
|\Omega|+1
∣Ω∣+1 大小的小片段列表
S
i
o
,
o
=
0
,
.
.
.
,
∣
Ω
∣
S_i^o, o=0,...,|\Omega|
Sio,o=0,...,∣Ω∣.
§ i of x = { 0 < § i < ∣ S i ∣ , S i [ § i − 1 ] < x ≤ S i [ § i ] 0 , x ≤ S i [ 0 ] ∣ S i ∣ , x > S i [ ∣ S i ∣ − 1 ] \S_i\ \ \text{of}\ \ x=\begin{cases} 0 < \S_i < |S_i|, & S_i[\S_i-1] < x \leq S_i[\S_i]\\ 0, & x\leq S_i[0]\\ |S_i|, & x > S_i[|S_i|-1] \end{cases} §i of x=⎩ ⎨ ⎧0<§i<∣Si∣,0,∣Si∣,Si[§i−1]<x≤Si[§i]x≤Si[0]x>Si[∣Si∣−1] - Line 6-28: 每个子任务将
S
i
o
,
i
=
1
,
.
.
.
,
n
S_i^o, i=1,...,n
Sio,i=1,...,n 小片段合并为有序列表
S
m
o
S_m^o
Smo, 由第
o
o
o 个 wrap 处理.
对于元素 x ∈ S i o ( S i o [ i ] = x ) x\in S_i^o(S_i^o[i]=x) x∈Sio(Sio[i]=x), 其在 S m O S_m^O SmO 的位置为 i + ∑ t = 1 o − 1 I t x + ∑ t = o + 1 n I t x i+\sum_{t=1}^{o-1}I_t^x+\sum_{t=o+1}^nI_t^x i+∑t=1o−1Itx+∑t=o+1nItx, 其中 I t x I_t^x Itx 表示元素 x x x 在小片段 S t o S_t^o Sto 中的匹配索引. - Line 10-23: 遍历第
o
o
o 个子任务的所有小片段对
(
S
j
o
,
S
k
o
)
,
k
<
j
(S_j^o,S_k^o), k<j
(Sjo,Sko),k<j:
- Line 15: 计算每个元素 p ∈ S j o p\in S_j^o p∈Sjo 在 S k o S_k^o Sko 的匹配索引 p o s pos pos.
- Line 19: I t x I_t^x Itx 由小片段对 ( S i o , S t o ) , t < i (S_i^o,S_t^o), t < i (Sio,Sto),t<i 时对 x x x 计算匹配索引位置的列表 m a t c h e d _ i d x matched\_idx matched_idx 得到.
- Line 20-21:
I
t
x
I_t^x
Itx 由小片段对
(
S
t
o
,
S
i
o
)
,
t
>
i
(S_t^o,S_i^o), t > i
(Sto,Sio),t>i 时统计
x
x
x 匹配索引数目的列表
m
a
t
c
h
e
d
_
c
n
t
matched\_cnt
matched_cnt 得到.
C. 复杂度分析
以 SM 算法来计算:
- Pangolin 组合枚举: O ( n k − 1 d m a x ( k − 2 ) l o g ( d m a x ) ) O(n^{k-1}d_{max}(k-2)log(d_{max})) O(nk−1dmax(k−2)log(dmax))
- GAMMA 组合枚举:
O
(
n
k
−
2
(
k
−
2
)
d
m
a
x
+
n
k
−
1
d
m
a
x
log
(
d
m
a
x
)
)
O(n_{k-2}(k-2)d_{max}+n^{k-1}d_{max}\log(d_{max}))
O(nk−2(k−2)dmax+nk−1dmaxlog(dmax))
GAMMA 组合枚举+同构检测: O ( n k − 2 ( k − 2 ) d m a x + n k − 1 d m a x ( log ( d m a x ) + e k log k ) ) O(n_{k-2}(k-2)d_{max}+n^{k-1}d_{max}(\log(d_{max})+e^{\sqrt{k\log k}})) O(nk−2(k−2)dmax+nk−1dmax(log(dmax)+eklogk))
GAMMA 并行: O ( n k − 2 ( k − 2 ) d m a x + n k − 1 d m a x ( log ( d m a x ) + e k log k ) w ) O(\frac{n_{k-2}(k-2)d_{max}+n^{k-1}d_{max}(\log(d_{max})+e^{\sqrt{k\log k}})}{w}) O(wnk−2(k−2)dmax+nk−1dmax(log(dmax)+eklogk))
VI. 实验
性能: Figure 11, Figure 12, Figure 14
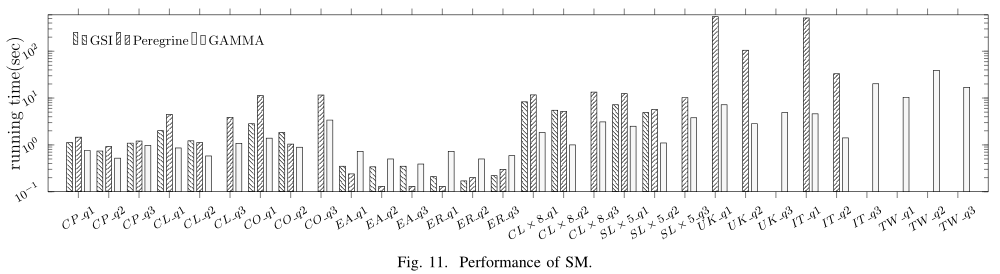

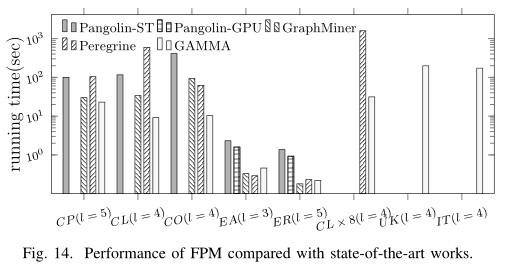
扩展性: Figure 15, Figure 16
各种优化的性能提升: Figure 17, Figure 18, Figure 19, Figure 20
笔者总结
本文的核心在于通过自适应隐式主机内存访问方式实现了一个针对大型图的基于 GPU 的图模式挖掘框架, 并围绕核外 GPU 系统带来的计算瓶颈进行了优化.
GAMMA 系统属于通用图挖掘系统, 采用以嵌入为中心(Embedding-Centric)的图挖掘模式, 支持结点诱导(vertex-induced)和边诱导(edge-induced)的子图扩展方式.