今天介绍LSM Tree这个数据结构,严格意义上来说,他并不像他的名字一样是一棵树型的数据结构,而更多是一种设计思想。
LSM Tree最先在1996年被提出,后来被广泛运用于现代NoSQL(非关系型数据库)系统中,包括BigTable, Dynamo, HBase, Cassandra, LevelDB, RocksDB, and AsterixDB.

LSM Tree主要是瞄准了IO操作中,顺序写的速度比随机写快几个数量级的特点,采用out-of-place 更新的特性,将随机写入累积到顺序写入,以利用存储设备的高顺序写入带宽。
那他是怎么做到的呢?实际上设计上其实也相当的简单粗暴。
LSM Tree通过将写入操作集中在内存中,并定期将数据合并到持久性存储介质(如磁盘)上,实现了高吞吐量的写入和高效的查询性能。LSM Tree引入了“组件”的概念,组件是指存储数据的单元或数据结构,它们按照特定规则组织和管理数据。
组件根据其存在于内存中或是磁盘中,被划分为:
1. 内存组件(Memory Component):LSM树通过内存组件(也称为memtable)存储最近写入的数据。内存组件通常是一个有序的数据结构(如平衡树或跳表),它提供快速的写入和查询操作。写入操作首先在内存组件中进行,以实现低延迟的写入性能。
2. 磁盘组件(Disk Component):当内存组件达到容量限制或触发某些条件时,LSM树将内存组件中的数据刷新到磁盘组件中。磁盘组件通常是一系列按键有序存储的文件(SSTable),其中每个文件称为一个层级(level)。较新的数据存储在较高的层级,而较旧的数据存储在较低的层级。每个层级的文件都是顺序写入的。磁盘组件之间的数据合并操作以保持数据的有序性和紧凑性。
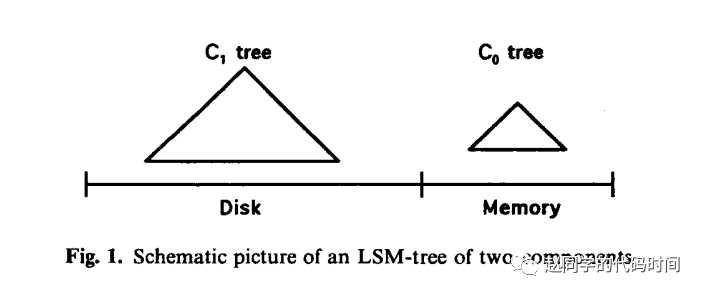
因此,不难看出,无论是在内存组件还是磁盘组件,LSM Tree都是使用有序的数据结构实现的,这也是为什么说LSM Tree是一种设计思想,而不是一个具体的数据结构的原因,在内存组件中,C0 tree可以采用B+树、红黑树等数据结构实现,他们可以被随机访问,直接修改,内存组件由于存在于内存中,访问快但容量小。在内存组件满或某些条件触发时,从内存组件中刷到磁盘组件中,因此,就起到了将随机写整合为顺序写的效果。
LSM Tree的查询过程
1. 首先进行内存查询:首先,查询操作会在内存组件(如memtable)中进行。由于内存组件是一个有序的数据结构,可以使用二分查找或其他高效的查找算法来定位所需的键。如果找到了匹配的键,则返回对应的值。如果在内存组件中未找到匹配的键,查询将继续进入下一个阶段。
2. 内存缺失时磁盘查询:如果在内存组件中未找到匹配的键,查询将继续在磁盘组件中进行查找。LSM树的磁盘组件通常由多个层级的文件组成,其中较新的数据存储在较高的层级,较旧的数据存储在较低的层级。
LSM Tree的增删改过程
LSM Tree的增删改过程都在内存中进行,按照内存中的有序结构的方式进行增加操作,删除过程同样都可以视作“增”,对于删除操作,在内存中将关键字打上标记,这样,在合并过程中,该key就会被忽略,从而实现删除的效果。
LSM Tree的合并过程
将高一层级的LSM Tree合并到第一层级会触发合并(也可以叫压缩),LSM树会从每个层级中选择一组候选文件进行合并。通常,合并操作从较高层级开始,逐渐向下进行。选择候选文件的策略可以根据不同的实现和需求而有所不同,常见的策略包括选择最旧的文件、选择文件大小最接近某个阈值的文件等。选定的候选文件会按照键的顺序进行排序。这可以通过一次性读取文件中的数据,并使用外部排序算法(如归并排序)来实现。排序后的数据将成为合并操作的输入。合并操作会将排序后的数据合并到一个新的文件中。新文件通常位于较低层级。合并操作的目标是保持数据的有序性和紧凑性。它会逐个比较排序后的键值对,并根据键的顺序将它们写入新文件。如果有重复的键,则通常选择最新的键值对作为合并结果。合并后的新文件可能会包含一些重复的键值对或已标记为删除的数据。为了优化存储空间,可以进行压缩操作。压缩操作会移除重复的键值对、删除标记和其他冗余数据,以减少文件的大小。压缩操作通常在合并操作之后进行,以避免对正在合并的数据产生冗余的压缩开销。
多Level LSM Tree
LSM Tree可以具有多个磁盘组件(似乎在后面的实现中往往只有一种),称为多组分LSM树(Multi-component LSM-trees)是LSM树的一种变体,它引入了多个组件类型以优化存储和查询性能。
在传统的LSM树中,通常只有两种组件类型:内存组件和磁盘组件。然而,多组分LSM树引入了额外的组件类型,以更好地适应不同的工作负载和性能需求。
多组分LSM树的主要组件类型包括:
内存组件(memtable):内存组件是多组分LSM树中的一个重要组成部分,它与传统LSM树中的内存组件相同。它存储最近的写入操作,并提供快速的插入和查询性能。与传统LSM树不同的是,多组分LSM树中的内存组件可以具有不同的配置和特性,以适应不同类型的数据和查询负载。
热存储组件(hot storage component):热存储组件是多组分LSM树中的一种组件类型,用于存储频繁访问的热数据。热存储组件可以位于内存或者高性能的存储介质上,以提供更快的查询响应时间。它通常用于存储最常访问的数据,以减少查询延迟。
冷存储组件(cold storage component):冷存储组件用于存储不经常访问的冷数据。这些组件通常位于较低性能的存储介质上,如磁盘或者低成本的云存储。冷存储组件可以容纳大量的数据,并提供较低的存储成本,但查询性能可能相对较低。
归档存储组件(archive storage component):归档存储组件用于长期存储和归档数据,这些数据很少被访问。归档存储组件通常采用高度压缩的格式,以减小存储空间的占用。这些组件通常位于持久性存储介质上,如冷存储或者备份存储。
多组分LSM树通过引入不同类型的组件,根据数据的访问模式和性能需求,将热数据存储在高性能组件中,而将冷数据存储在较低性能组件中。这样可以提高查询性能和存储效率,同时满足不同类型的数据访问需求。
LSM Tree的异地更新特性
传统的索引结构通常采用in-place更新策略,即直接覆盖旧记录来存储新的更新。而LSM树采用了out-of-place更新策略,即始终将更新存储在新的位置,而不是直接覆盖旧条目。
LSM树的out-of-place特性带来了一些优势。首先,它提高了写入性能,因为可以利用顺序I/O来处理写入操作。相比之下,传统的in-place更新结构需要进行随机的I/O操作,影响写入性能。其次,out-of-place特性简化了恢复过程,因为它不会覆盖旧数据,可以更容易地进行数据恢复。此外,LSM树的out-of-place特性还允许对数据进行可调整的并发控制和高空间利用率的管理。
然而,out-of-place特性也带来了一些挑战。由于记录可能存储在多个位置,读取性能可能会受到影响。此外,LSM树通常需要进行单独的数据重新组织过程,以持续改善存储和查询的效率。
LSM树的out-of-place特性是其设计的关键部分,它使LSM树成为现代NoSQL系统中存储层的重要组成部分,并为各种工作负载提供了高性能和高效的存储管理。
如何继续优化LSM Tree
LSM Tree具有良好的写性能,但是无疑也降低了读性能,如何提升LSM Tree的读性能?
可以考虑采用布隆过滤器,提前过滤一些明确不存在的key,来加快读性能;
可以考虑采用在有序结构上使用的更加高效的查找算法,比如二分查找来提高查找速度;
可以考虑使用hash,将数据分割映射等。
在以下链接中,有之前的创作者设计的LSM Tree的增删查改样例,有兴趣的读者可以了解。
https://blog.csdn.net/jinking01/article/details/105377370
如果想要更多了解LSM Tree的学术上的进展,推荐一篇文献调研:
https://doi.org/10.1007/s00778-019-00555-y