📋 博主简介
- 💖 作者简介:大家好,我是wux_labs。😜
热衷于各种主流技术,热爱数据科学、机器学习、云计算、人工智能。
通过了TiDB数据库专员(PCTA)、TiDB数据库专家(PCTP)、TiDB数据库认证SQL开发专家(PCSD)认证。
通过了微软Azure开发人员、Azure数据工程师、Azure解决方案架构师专家认证。
对大数据技术栈Hadoop、Hive、Spark、Kafka等有深入研究,对Databricks的使用有丰富的经验。- 📝 个人主页:wux_labs,如果您对我还算满意,请关注一下吧~🔥
- 📝 个人社区:数据科学社区,如果您是数据科学爱好者,一起来交流吧~🔥
- 🎉 请支持我:欢迎大家 点赞👍+收藏⭐️+吐槽📝,您的支持是我持续创作的动力~🔥
《PySpark大数据分析实战》-10.独立集群模式的代码运行
- 《PySpark大数据分析实战》-10.独立集群模式的代码运行
- 前言
- 使用spark-submit提交代码
- Spark History Server历史服务
- 独立集群模式的代码运行流程
- 结束语
《PySpark大数据分析实战》-10.独立集群模式的代码运行
前言
大家好!今天为大家分享的是《PySpark大数据分析实战》第2章第3节的内容:独立集群模式的代码运行。

使用spark-submit提交代码
spark-submit可以在不指定选项和参数、仅指定Python代码路径的情况下正常运行,但是这种方式提交运行,Spark应用程序仅会在单机上运行,这与本地模式一致。这种方式没有充分利用集群的资源,并且在集群的Spark Master Web UI上也无法查看提交运行的Spark应用程序。要充分利用集群资源并在Spark Master Web UI上看到提交的Spark应用程序,需要为spark-submit指定必要的选项,其中最重要的一个选项是master。未指定该选项,则Spark默认以本地模式启动,本地模式也是可以指定master选项的,可选的master值包括local、local[n]、local[*]。在独立集群模式下,需要将master的值指定为Spark Master Web UI中看到的值spark://node1:7077。在YARN模式下,需要将master的值指定为yarn。master选项的一些可选值列表见表。
| master选项值 | 描述 |
|---|---|
| local | 本地模式运行,所有计算都在一个线程中,无法并行计算 |
| local[n] | 本地模式运行,指定使用n个线程来模拟n个worker,通常将n指定为CPU的核数,以最大化利用CPU的能力 |
| local[*] | 本地运行模式,直接使用CPU的最多核数来设置线程数 |
| spark://node1:7077 | 独立集群模式,指定为独立集群的master地址 |
| yarn | Spark on YARN模式,master固定值为yarn,可区分cluster模式和client模式 |
由于spark-submit所在的路径$SPARK_HOME/bin/已经添加到环境变量$PATH里面,所以可以直接执行命令,指定master选项后提交Spark应用程序,命令如下:
$ spark-submit --master spark://node1:7077 /home/hadoop/WordCount.py
除了master选项,spark-submit还支持其他一些选项:
- –deploy-mode,用于决定Spark应用程序的Driver在哪里启动,使用client指定Driver在本地启动,使用cluster指定在集群中的一台服务器上启动Driver。默认值是client。
- –name,指定Spark应用程序的名称。
- –files,使用逗号分隔的文件列表,用于向集群提交文件,可以传递用于应用程序中使用的参数等。
- –conf,通过命令行动态地更改应用程序的配置。
- –driver-memory,指定为应用程序的Driver分配的内存大小。
- –executor-memory,指定为应用程序的每个Executor分配的内存大小。
Spark应用程序在运行的过程中,会遇到报错的情况,这是由于words.txt文件是存放在本地文件系统的而不是HDFS上,Spark应用程序在执行的时候会去本地系统读取文件,而words.txt仅存在于node1上,在node2和node3上并不存在,所以node2和node3上分配到的executor在进行文件读取的时候就会报错。而文件上传到HDFS则不会有这个问题。错误信息如下:
...
(10.0.0.7 executor 2): java.io.FileNotFoundException: File file:/home/hadoop/words.txt does not exist
...
(10.0.0.6 executor 1): java.io.FileNotFoundException: File file:/home/hadoop/words.txt does not exist
...
将words.txt复制到所有服务器节点后再次运行Spark应用程序,程序就不会报错,可以正确运行并成功输出结果。复制文件到所有节点的命令如下:
$ scp words.txt node2:~/
$ scp words.txt node3:~/
程序运行完成后,在Spark Master Web UI可以看到应用程序的Job信息,两次运行的应用程序如图所示。

点击应用程序链接,可以看到应用程序运行情况如图所示。在该列表中点击stdout和stderr链接可以查看日志信息。

Spark History Server历史服务
Spark应用程序运行结束后,Spark Driver Web UI随着Driver程序的结束而被关闭,此时要看应用程序的执行情况及日志信息,可以通过Spark History Server进行查看,Spark History Server的默认服务端口是18080,通过浏览器访问node1的该端口打开Spark History Server界面,可以看到两次运行结束的应用程序,如图所示。

点击应用程序列表中的链接,会跳转到应用程序的执行情况界面,如图所示。历史应用程序执行情况界面,与Spark Driver Web UI界面一致,功能也一样。

独立集群模式的代码运行流程
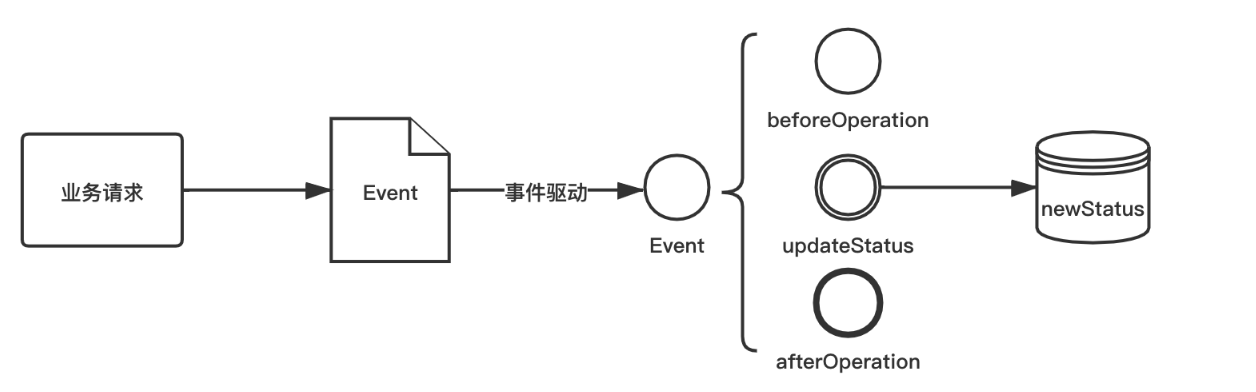
使用spark-submit提交Spark应用程序到独立集群进行运行,应用程序的执行流程如图所示。

 :在Spark集群启动后,不管集群中是否有提交Spark应用程序运行,Worker节点都会向Master节点汇报自己的资源情况,例如空闲CPU、空闲内存等。
:在Spark集群启动后,不管集群中是否有提交Spark应用程序运行,Worker节点都会向Master节点汇报自己的资源情况,例如空闲CPU、空闲内存等。
1:客户端通过spark-submit提交应用程序运行,首先会执行程序中的main()函数,在客户端启动Driver进程。
2:Driver进程启动后,会实例化SparkContext,SparkContext会向集群的Master注册并申请资源。
3:Master会根据Worker的资源情况,分配满足条件的Worker节点,Worker节点上会启动Executor。
4:Executor启动后,会反向注册到Driver。
5:Executor反向注册完成后,Driver将应用程序代码进行解析,并由Task Scheduler将Task分配到Worker节点并最终由Executor进行执行。
6:Executor执行Task任务,并向SparkContext汇报状态,直到Task执行完成。
7:当所有的Task都执行完成,SparkContext会请求Master进行注销,整个应用程序运行完成。
结束语
好了,感谢大家的关注,今天就分享到这里了,更多详细内容,请阅读原书或持续关注专栏。