Python Socket编程
文章目录
- Python Socket编程
- 1. 弄懂HTTP、Socket、TCP这几个概念
- 五层网络模型
- 2. client和server实现通信
- Socket编程模式指南
- 代码实现
- 3. socket实现聊天和多用户连接
- 4. socket模拟http请求
- 5. socket使用I/O多路复用模式模拟http请求
1. 弄懂HTTP、Socket、TCP这几个概念
- 整个计算机网络都是有协议组成的
- 每一个应用程序只能占用1个端口
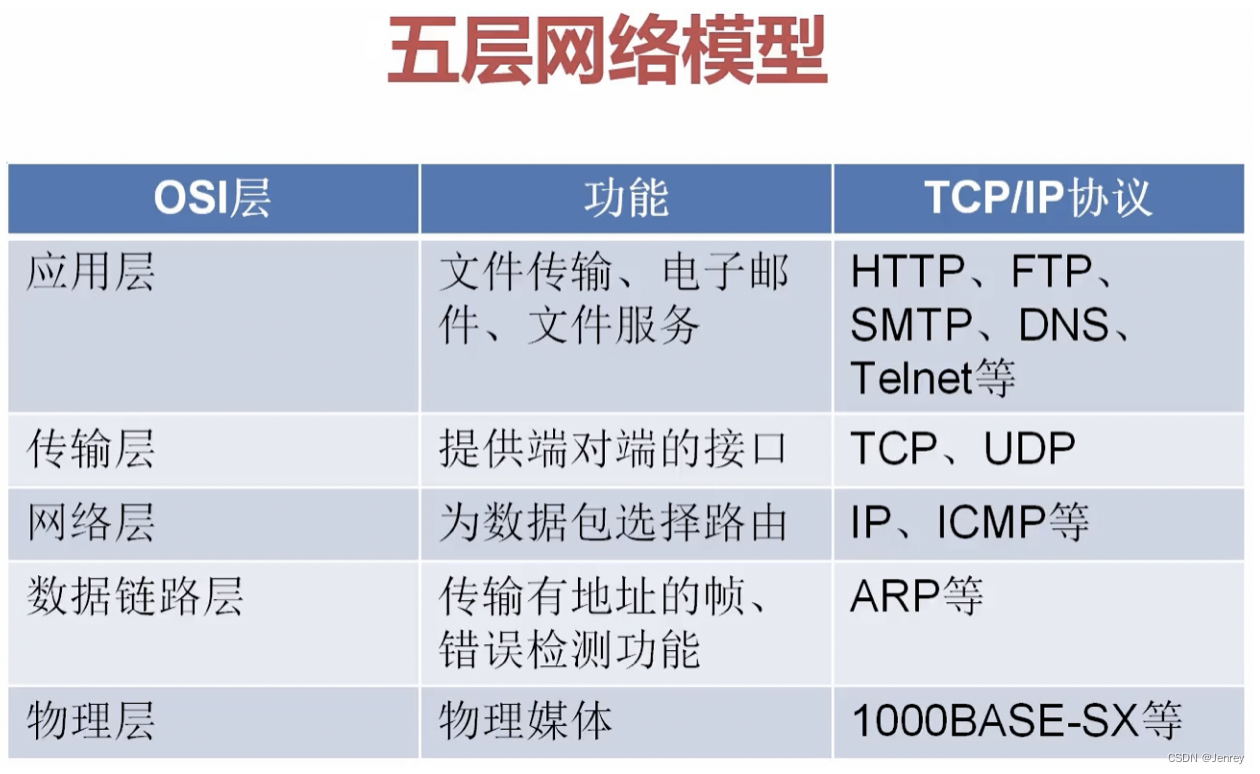
五层网络模型
- OSI的标准网络模型是有7层的。应用层和传输层下面还有个表示层、还有个会话层。
- 应用层中最常用的库就是
requests这个第三方的包,走的就是HTTP协议;浏览器也是实现了HTTP协议。 HTTP协议是构建与TCP/IP协议之上的。- 例如我们要写一个聊天工具,这就不属于这里的应用层任何协议,那么我们如何与TCP/UDP这些底层协议打交道呢?如果我们要手动实现协议与TCP/UDP打交道是非常繁琐的,所以我们不会去实现协议与TCP/UDP打交道,这些与TCP/UDP协议打交道的活都是操作系统帮我们提供的。
- 操作系统会提供给我们Socket,Socket我们可以理解为是一个API,Socket不属于任何协议,我们通过Socket就可以直接和TCP/UDP传输层打交道,因为聊天工具属于新的应用,而这里的应用层协议都无法满足我们的需求,所以我们就只需要使用操作系统提供的Socket编程即可,Windows、Linux、macOS等操作系统都给我们提供了Socket接口。
- 所以我们只需要通过Socket就可以和底层的这些传输层、网络层、数据链路层、物理层进行打交道。
- Socket在整个网络模型中,可以让我们直接脱离应用层而自动帮我们与底层协议打交道,这样我们就可以完成很多的功能哦。
- Socket本身不属于计算机网络模型。Socket是用来连接我们的应用和TCP层,Socket使得我们自己的应用可以直接和TCP打交道,这样我们就可以实现自己的应用层协议。而这个我们自己定义的应用层协议就是使用Socket与TCP打交道,我们自己定义的应用层协议是和HTTP协议是同一层级的应用层协议。
2. client和server实现通信
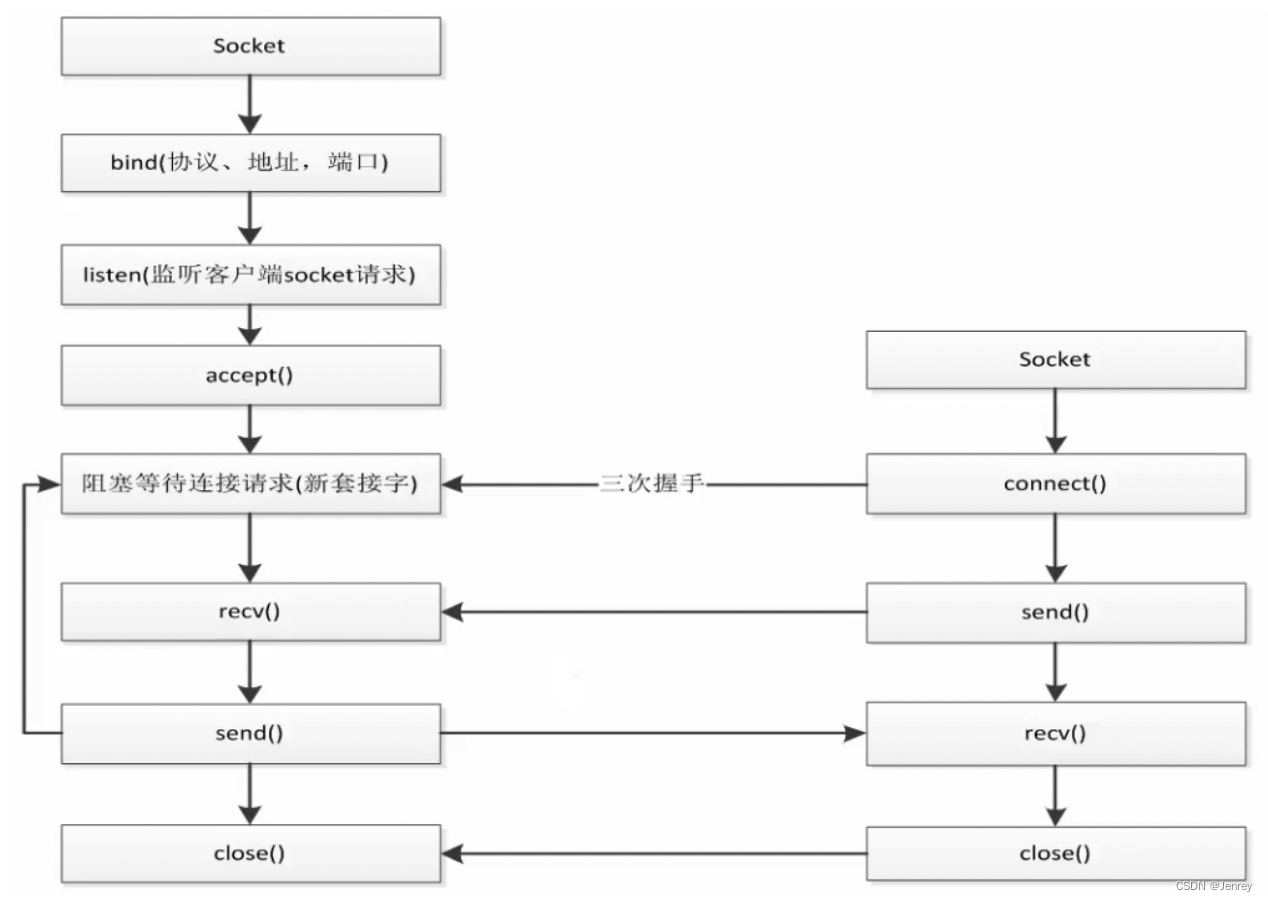
Socket编程模式指南
- 左侧就是server端:
- 特点就是随时处于监听的状态,也就是服务的状态,因为不知道客户端什么时候会发送连接过来,所以server必须时刻处于等待状态。
accept():阻塞等待连接请求recv():获取数据send():服务端可以发送数据给客户端,这里就与HTTP有很大的区别了,即只要连接不断开,就可以一直向客户端发送数据。而HTTP请求一般就是发送请求等待响应返回数据后就停止了。close():断开连接
- 右侧就是client端
代码实现
# socket_server.py
import socket
# 新建server
# 参数1:是指明使用的类型,AF_INET就是指明使用IPv4,常用还有AF_INET6就是IPv6,AF_IPX是做linux系统上的进程间通信的
# 参数2:指明这个类型对应的协议,SOCK_STREAM就是TCP,SOCK_DGRAM就是UDP
# socket.AF_INET: 基于网络的socket通信,使用IPv4
# socket.SOCK_STREAM: 基于TCP的流式socket通信
server = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
# 绑定IP地址和端口,必须传入一个tuple
# 如果你写127.0.0.1那么你通过局域网就访问不到了
server.bind(("0.0.0.0", 8000))
# 监听
server.listen()
# 等待连接
# 返回表示连接的新套接字以及客户端的地址,sock是一个新的套接字对象,addr是客户端的地址
sock, addr = server.accept()
# 接收数据,即获取从客户端发送的数据,指定最大的接收长度为1024字节(即一次获取1KB的数据),recv方法是一个阻塞方法,如果没有数据接收就会阻塞程序执行
data = sock.recv(1024) # data是一个bytes对象
print(data.decode("utf8")) # 把bytes对象转换成字符串
# 发送数据给客户端
sock.send("Hello client".encode("utf8"))
# 关闭连接
# server.close()是关闭服务器套接字,停止接受新的客户端连接,sock.close()是关闭一个已经建立的客户端连接。
# server.close() # 关闭连接,真正的server一般是不会close的
# sock.close() # 关闭套接字,表示和客户端的连接也中断了
# socket_client.py
import socket
client = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
# 建立连接
# 参数是一个tuple,包含地址和端口号,这里是本机的地址,所以是127.0.0.1,端口号是8000
client.connect(("127.0.0.1", 8000))
# 发送数据,要求发送的数据必须是bytes格式
client.send("Hello Server".encode("utf8"))
# 接收数据
data = client.recv(1024)
print(data.decode("utf8"))
# 关闭连接,一般是先关闭发送数据的一方,然后再关闭接收数据的一方,这是一个好习惯
client.close()
先启动server端,再启动client端,发现server端打印了“Hello Server”,而后client端打印了“Hello client”,最后两者程序都退出了。
3. socket实现聊天和多用户连接
# socket_server.py
import socket
server = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
server.bind(("0.0.0.0", 8000))
server.listen()
sock, addr = server.accept()
while True:
data = sock.recv(1024)
print(data.decode("utf8"))
re_data = input() # 使用终端进行发送数据的输入
sock.send(re_data.encode("utf8"))
# socket_client.py
import socket
client = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
client.connect(("127.0.0.1", 8000))
while True:
re_data = input()
client.send(re_data.encode("utf8"))
data = client.recv(1024)
print(data.decode("utf8"))
这样的代码有个问题:
- server只能连接一个client,因为当客户端连接后就在while循环中出不来了。可以使用线程,每一个socket都做一个线程,在线程里面去循环,那么我们主线程就可以不停的接收其他client的连接请求
# socket_server.py
import socket
import threading
server = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
server.bind(("0.0.0.0", 8000))
server.listen()
def handle_sock(sock, addr):
while True:
data = sock.recv(1024)
print(data.decode("utf8"))
re_data = input()
sock.send(re_data.encode("utf8"))
while True:
sock, addr = server.accept()
# 用线程去处理新接收的连接(用户)
client_thread = threading.Thread(target=handle_sock, args=(sock, addr))
client_thread.start()
4. socket模拟http请求
requests包是基于urllib完成的,而urllib是基于socket完成的。所以说最底层就是socket的。- 凡事在网络相关的连接中,比如数据库连接、进程之间的通信等,这些网络请求最底层都是用socket完成的
- 再次强调socket是操作系统所提供的接口,只是说不同的开发语言会根据不同的操作系统所提供的socket,再次封装成接口而已。
- 下面我们将实现通过
socket去完成urllib当中的去获取请求的实现。
import socket
# 用来解析URL, 会将URL解析为下面6个部分
# <scheme>://<netloc>/<path>;<params>?<query>#<fragment>
from urllib.parse import urlparse
def get_url(url):
"""通过socket请求html"""
url = urlparse(url) # 解析url
host = url.netloc # 获取域名
path = url.path # 获取域名后的子路径
if path == "":
path = "/" # 如果直接请求的域名则把子路径改成/
# 建立socket连接
client = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
client.connect((host, 80)) # HTTP是80端口
# 发送数据,注意这里的数据的格式是要按照HTTP协议的规范来写
client.send(f"GET {path} HTTP/1.1\r\nHost:{host}\r\nConnection:close\r\n\r\n".encode("utf8"))
# 接收数据
data = b""
while True:
d = client.recv(1024)
if d:
data += d
else:
break
data = data.decode("utf8")
html_data = data.split("\r\n\r\n")[1] # 丢弃响应头,只取HTML
print(html_data)
client.close()
if __name__ == "__main__":
get_url("http://www.baidu.com")
- 注意,这里每次发送请求都会先去建立socket连接,然后close。下次如果我们再发生请求的时候还要这样,这就比较耗时。这里只是体验socket编程的代码示例。而正常我们是应该保持长连接的。
- socket编程是理解异步IO、协程的基础。是必须要掌握的。
- socket编程过于底层,所以需要手动完成的功能比较多。
5. socket使用I/O多路复用模式模拟http请求
- 这里的代码了解即可。采用了 “select或者epoll + 回调 + 事件循环” 的编程模式
- 这样写的好处就是并发行高,而且这里没有线程的切换,都在一个线程里面执行。而且省内存,因为1个线程消耗的内存是远远高于回调函数的模式的。
- 回调函数其实就是一个指向函数的句柄而已。
- 这里的代码就很好的展示了协程的核心原理(事件循环 + I/O多路复用)。
- 这种方式其实就是当我们代码进行下一步操作的时候是让 事件循环loop 去驱动我们的回调函数
- 缺点会让代码割裂的四分五裂。
# socket_select_http.py
"""
通过I/O多路复用模型中的select模式或者epoll模式实现http请求
"""
import socket
# selectors包的作用是根据不同的操作系统自动选择最佳的I/O多路复用模型
# 我们不要使用select包,而是要使用基于select包再次封装的selectors包
# DefaultSelector会自动帮我们根据代码运行的操作系统去选择使用poll或者epoll
# 在Windows下就是select,在Linux下就是epoll
# 而且DefaultSelector还为我们提供了注册机制
from selectors import EVENT_READ, EVENT_WRITE, DefaultSelector
from urllib.parse import urlparse
selector = DefaultSelector() # 创建一个selector对象(选择器)
class Fetcher:
def __init__(self):
self.host = "" # 域名
self.path = "" # 路径
self.data = b"" # 存储返回的数据
self.client = None # socket对象
def get_url(self, url):
"""
通过socket请求html
"""
url = urlparse(url) # 解析url
self.host = url.netloc # 获取域名
self.path = url.path # 获取域名后的子路径
self.data = b"" # 存储返回的数据
if self.path == "":
self.path = "/" # 如果直接请求的域名则把子路径改成/
# 创建socket对象<class 'socket.socket'>, socket.AF_INET表示ipv4, socket.SOCK_STREAM表示TCP
self.client = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
# 将socket设置为阻塞(true)或非阻塞(false), 默认为阻塞
self.client.setblocking(False) # 使用非阻塞
try:
# 连接
self.client.connect((self.host, 80)) # 注意这里是非阻塞的,所以不会等待连接成功,而是会立刻返回并继续执行后续代码,所以会抛出BlockingIOError异常
except BlockingIOError as e:
pass # 抛出BlockingIOError异常是合理的,虽然抛出了异常,但是与host的建立连接请求已经发出去了。
# 将socket注册到selector中,监听socket是否是可写的状态
# 参数1: socket的文件描述符
# 参数2: 事件,有EVENT_WRITE和EVENT_READ
# 参数3: 回调函数,即当socket的状态变为可写的时候,就会调用此回调函数
selector.register(self.client.fileno(), EVENT_WRITE, self.connected) # 使用事件监听, 等待连接成功, 然后再执行后面的代码
# 注意这后面不能再写代码了,如果写了代码就是阻塞式IO了,所以我们才要使用事件监听,采用回调的方式来处理
def connected(self, key):
"""连接成功的回调函数,当socket的状态变为可写的时候,就会调用此回调函数,进行发送数据(发送HTTP请求)"""
# 注销掉监控的事件,即取消注册,因为我们已经连接成功了,所以就不需要再监听socket是否是可写的状态了,所以要注销掉,否则会一直监听下去
selector.unregister(key.fd) # fd是file descriptor文件描述符
# 发送数据,这里不用try...except...,是因为我们使用事件监听,当回调此方法的时候连接的状态一定是就绪的状态
self.client.send(f"GET {self.path} HTTP/1.1\r\nHost:{self.host}\r\nConnection:close\r\n\r\n".encode("utf8"))
# 注册,即使用事件监听,因为我们要接收服务器返回的响应数据,所以要再次监听socket是否是可读的状态,当socket的状态变为可读的时候,就会调用此回调readable方法接收数据,然后打印出来
selector.register(self.client.fileno(), EVENT_READ, self.readable)
def readable(self, key):
"""接收数据(接收HTTP响应),当socket的状态变为可读的时候,就会调用此回调函数,进行接收数据(接收HTTP响应),然后打印出来"""
d = self.client.recv(1024) # 接收数据
if d: # 当数据没有读完的时候,继续读取
self.data += d
else: # 当数据读完的时候,就注销掉监控的事件,即取消注册,因为我们已经接收完了,所以就不需要再监听socket是否是可读的状态了,所以要注销掉,否则会一直监听下去
selector.unregister(key.fd)
data = self.data.decode("utf8")
html_data = data.split("\r\n\r\n")[1]
print(html_data)
self.client.close()
def loop():
"""回调+事件循环+select(poll/epoll)
驱动整个程序运行,可以理解为心脏,这样不会去阻塞建立连接、等待请求等IO操作
"""
# 事件循环,不停的请求socket的状态并调用对应的回调函数
# 所以这是个主循环
# 1.select本身是不支持register模式
# 2.socket状态变化以后的回调是由程序员完成的
while True:
# 注意在Windows下使用的是select模式,而select(r,w,w,timeout)的参数如果为空列表会抛出OSError异常
# 而在Linux或者macOS下会使用epoll模式,就不会抛出OSError异常,会一直阻塞在这里
# 不停的向操作系统请求有哪些socket已经准备好了
ready = selector.select() # 返回的是SelectorKey数据类型,是namedtuple类型
for key, mask in ready:
# key是一个SelectorKey类型的对象,包含了文件描述符fd、事件event、回调函数data等属性
# mask是一个事件的遮罩,表示事件是可读的还是可写的,EVENT_READ或EVENT_WRITE,取决于我们注册的时候监听的是可读还是可写,即key.events
call_back = key.data # 获取回调函数,<bound method Fetcher.connected of <__main__.Fetcher object at 0x1025d55b0>>
call_back(key) # 执行回调函数,即调用connected方法
if __name__ == "__main__":
fetcher = Fetcher()
fetcher.get_url("http://www.baidu.com")
loop()
下面是解决Windows下使用的是select模式抛出OSError异常的问题
import socket
from selectors import EVENT_READ, EVENT_WRITE, DefaultSelector
from urllib.parse import urlparse
selector = DefaultSelector()
urls = ["http://www.baidu.com"]
stop = False
class Fetcher:
def get_url(self, url):
self.spider_url = url
url = urlparse(url)
self.host = url.netloc
self.path = url.path
self.data = b""
if self.path == "":
self.path = "/"
self.client = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
self.client.setblocking(False)
try:
self.client.connect((self.host, 80))
except BlockingIOError as e:
pass
selector.register(self.client.fileno(), EVENT_WRITE, self.connected)
def connected(self, key):
selector.unregister(key.fd)
self.client.send(f"GET {self.path} HTTP/1.1\r\nHost:{self.host}\r\nConnection:close\r\n\r\n".encode("utf8"))
selector.register(self.client.fileno(), EVENT_READ, self.readable)
def readable(self, key):
d = self.client.recv(1024)
if d:
self.data += d
else:
selector.unregister(key.fd)
data = self.data.decode("utf8")
html_data = data.split("\r\n\r\n")[1]
print(html_data)
self.client.close()
urls.remove(self.spider_url)
if not urls:
global stop
stop = True
def loop():
while not stop:
ready = selector.select()
for key, mask in ready:
call_back = key.data
call_back(key)
if __name__ == "__main__":
fetcher = Fetcher()
fetcher.get_url("http://www.baidu.com")
loop()