授权说明:本篇文章授权活动官方亚马逊云科技文章转发、改写权,包括不限于在 亚马逊云科技开发者社区, 知乎,自媒体平台,第三方开发者媒体等亚马逊云科技官方渠道。
近期在 re:Invent 2023 大会上,亚马逊云科技发布了一组引人注目的新功能,重点强调了生成式人工智能在塑造人工智能未来方向上的引领地位。其中,Amazon SageMaker作为一款全面托管的机器学习服务,在其新功能的引领下,能够为用户提供更高效、更强大的机器学习工具。我将在后文对Amazon SageMaker的产品进行使用体验,以及对其进行全面的总结。

目录
一、 Amazon SageMaker: 高效、便捷的机器学习全方位解决方案
二、SageMaker新功能:突破创新之路
1. SageMaker HyperPod和Inference:强大的训练与部署基础设施
2. SageMaker Clarify和Canvas:负责任AI的评估与直观工作流
三、功能测评体验
四、体验感悟和总结
一、 Amazon SageMaker: 高效、便捷的机器学习全方位解决方案
Amazon SageMaker以其全面而先进的功能和解决方案,为用户提供了更多可能性,使机器学习的构建、训练和部署过程更加便捷高效。SageMaker持续推动着机器学习技术的进步,也为用户提供了更为出色的工具和平台。这一系列优势共同构成了SageMaker在机器学习领域的引领地位。

通过专注于创新,提供面向数据科学家的IDE和无代码界面,Amazon SageMaker能够让开发者轻松利用机器学习处理结构化和非结构化数据。其优化基础设施将培训时间从几小时缩短到几分钟,专用工具提高团队生产力多达10倍。此外,自动执行和标准化MLOps实践和治理,支持组织中的透明度和可审核性。
二、SageMaker新功能:突破创新之路
Amazon SageMaker作为全面托管的机器学习服务,为我们提供了无需关注底层复杂性的机会,将重心集中在模型的构建和优化上。通过SageMaker,我们可以轻松构建和训练机器学习模型,并将其直接部署到生产就绪的托管环境中。这一服务不仅提供了集成的Jupyter编写Notebook实例,方便访问数据源进行探索和分析,还支持常见机器学习算法,为分布式环境中的高效数据处理提供了优化的解决方案。
1. SageMaker HyperPod和Inference:强大的训练与部署基础设施
亚马逊云科技最新发布的SageMaker HyperPod和Inference功能展现了其对机器学习领域的持续创新。SageMaker HyperPod是为大规模分布式训练而设计的创新基础设施,旨在解决训练模型所面临的复杂性和高成本挑战。SageMaker HyperPod通过预配置SageMaker的分布式训练库,自动将训练工作负载分发到数千个加速器中,实现并行处理以提高模型性能。

而SageMaker Inference则致力于降低模型部署的成本和延迟,满足组织对性能优化的需求。用户可以单独控制每个模型的扩展策略,以适应不同的模型使用模式,同时优化基础架构成本。通过智能路由推理请求,SageMaker主动监控处理请求的实例,并将请求平均路由到可用的实例。
2. SageMaker Clarify和Canvas:负责任AI的评估与直观工作流
SageMaker Clarify和Canvas功能的引入进一步推动了机器学习应用的发展。SageMaker Clarify为用户提供了一种负责任使用AI的便捷方式,快速评估和选择基础模型。通过支持用户有效评估模型,确保其符合负责任的AI标准。用户可以轻松提交模型进行评估,也可以通过SageMaker JumpStart选择适用于其用例的模型,同时获取详细的报告,为用户提供基于性能标准的快速比较、评估和选择最佳模型的便利。

新的Amazon SageMaker Canvas增强功能使用户更轻松、更快速地将生成式AI集成到其工作流程中。Canvas支持用户在无代码环境中构建ML模型并生成预测,无需编写任何代码。此次更新扩展了Canvas的即用型功能,使用户能够更直观地准备数据,通过自然语言指令解决常见的数据问题。
三、功能测评体验
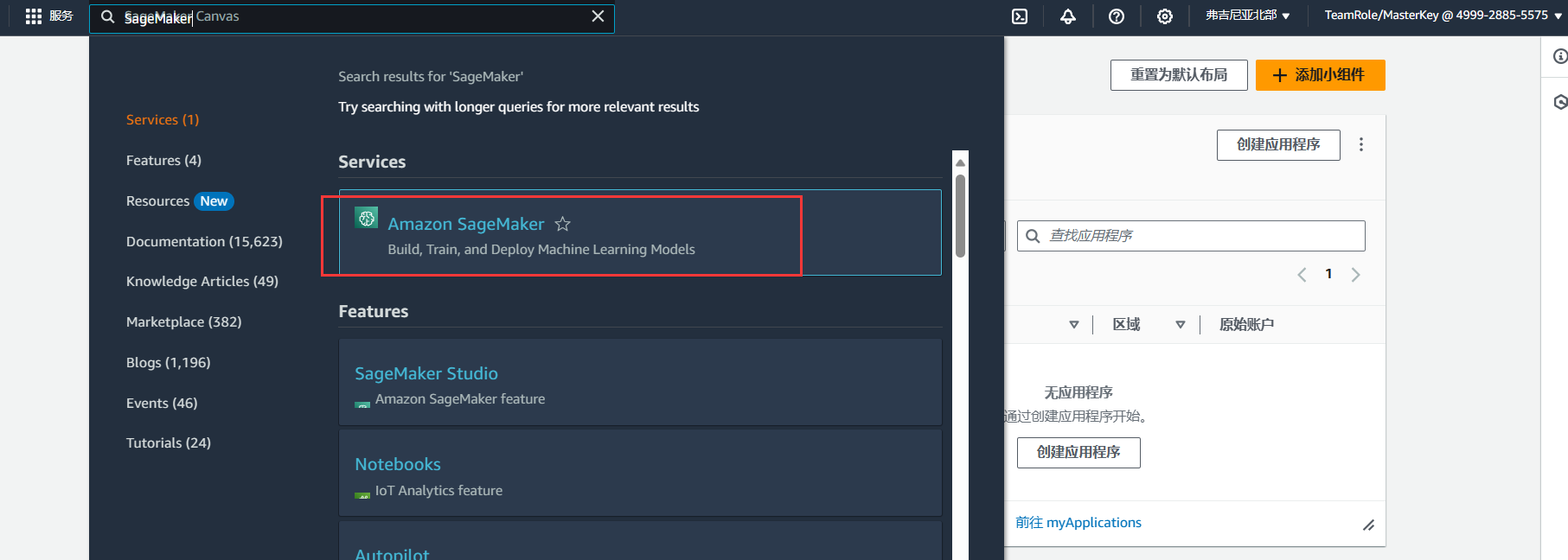
首先用户在亚马逊云科技官网完成账号登录,没有账号的需要先进行注册,登录之后来到个人控制台,在搜索栏搜索Amazon SageMaker服务:
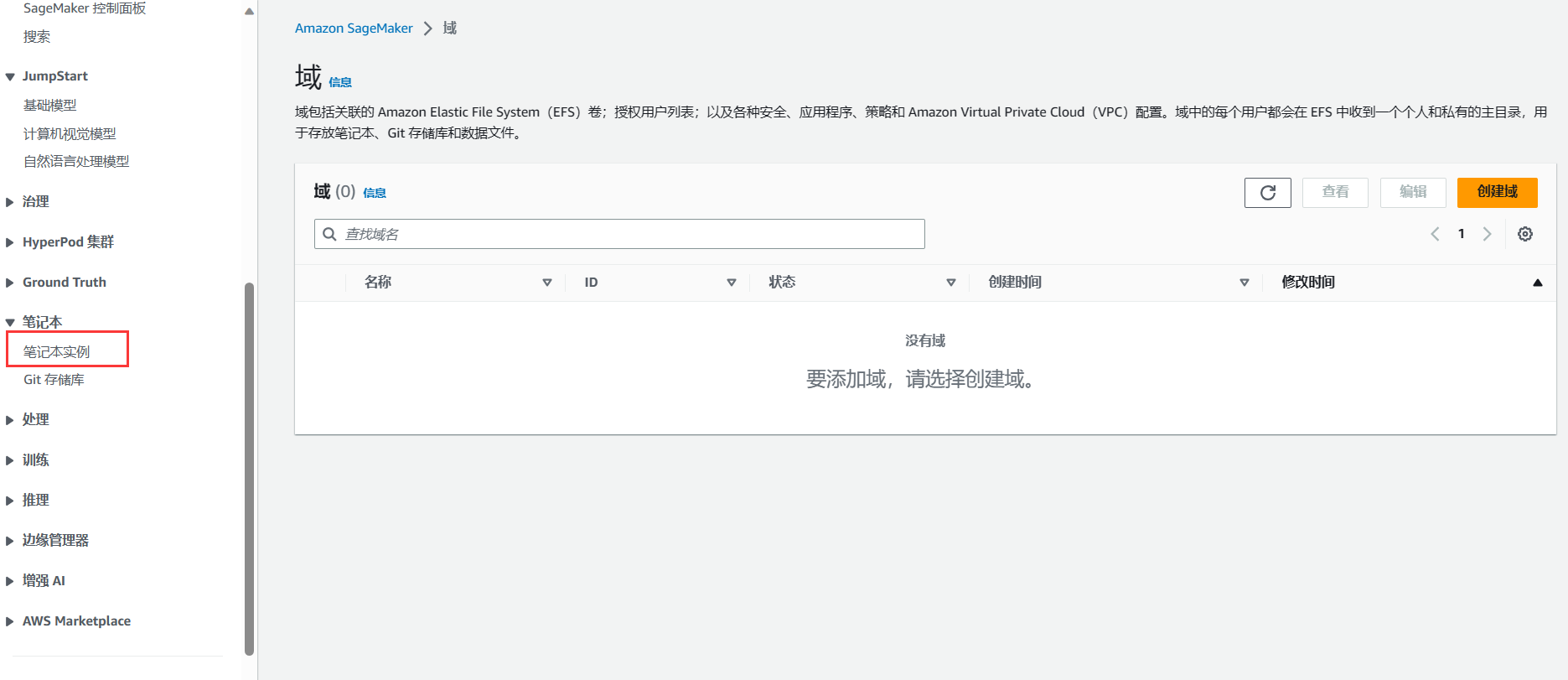
进入到Amazon SageMaker服务界面之后,在左侧导航栏找到笔记本模块,点击笔记本实例,并进行创建:
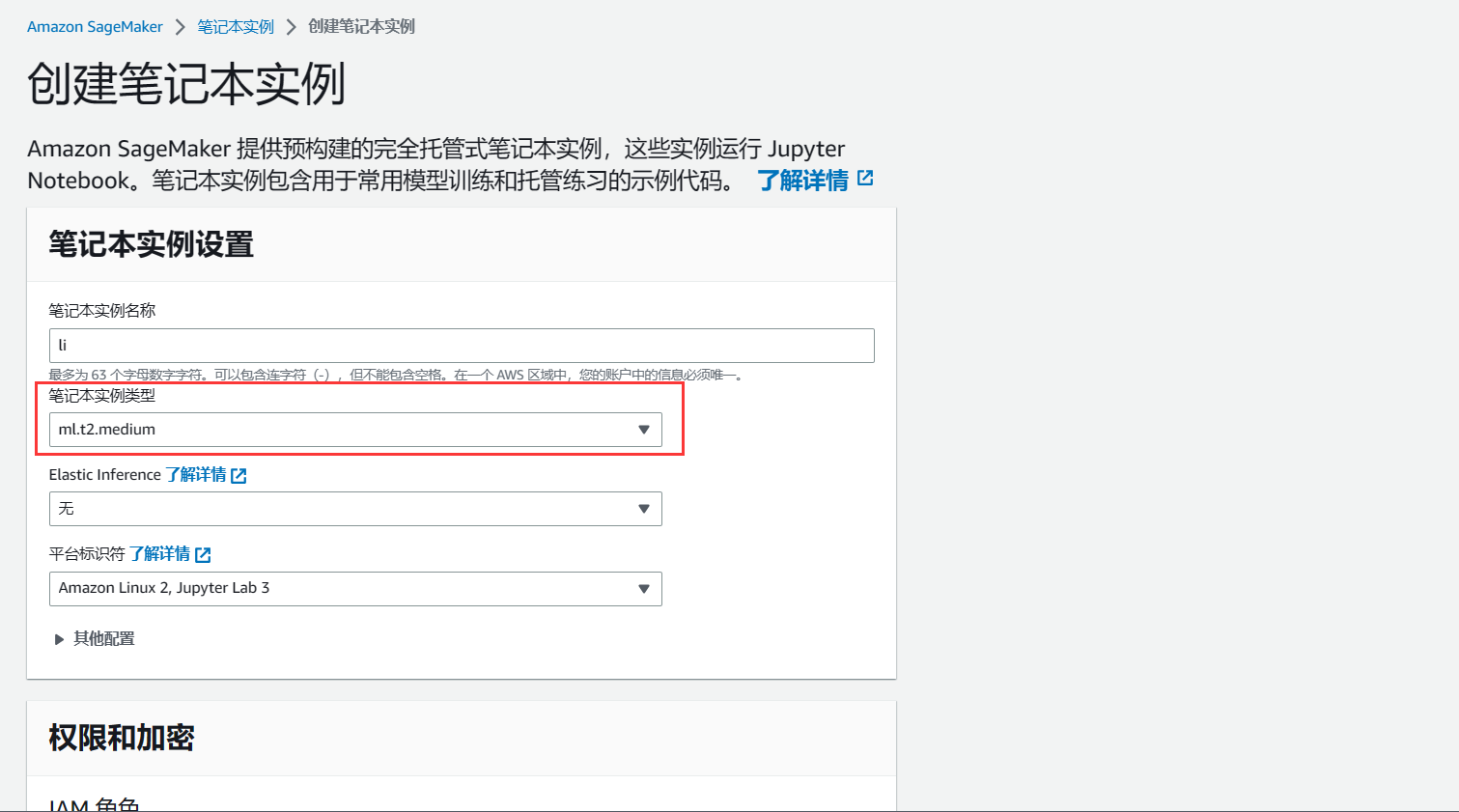
。进入创建界面后,可以根据开发需要进行配置信息选择,同时也可以新的IAM角色,也可以使用已经存在的角色。
稍等片刻,等待笔记本实例状态变为InService,即表示实例可用。
为了测试使用,我们在顶部搜索栏搜素S3存储桶服务,然后创建通用存储桶,配置完信息之后,等待存储桶的创建完毕,之后我们可以进入桶内部进行相关操作。
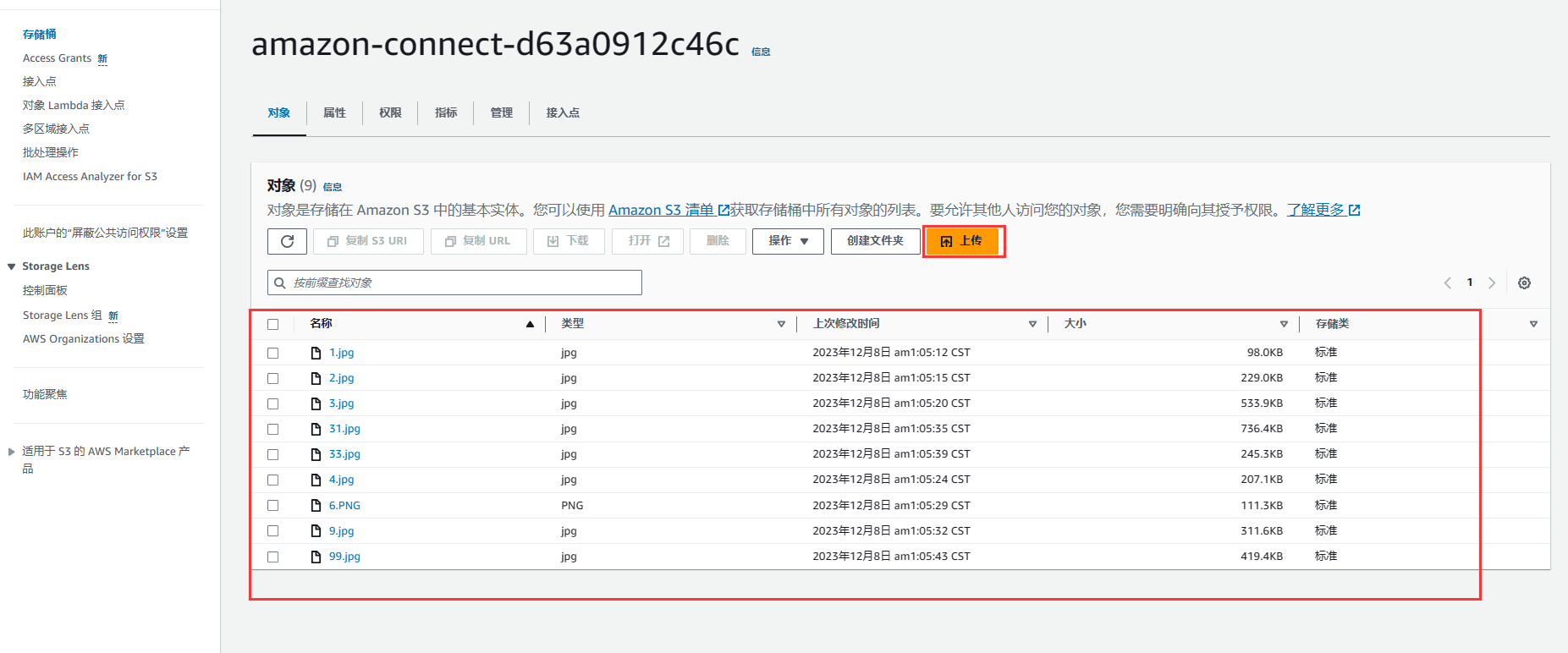
进入存储桶中之后,我们可以通过上传功能将本地的资源进行上传到S3存储桶中,如图,我将本地的一些图片资源传输到我创建的存储桶中。
回到Amazon SageMaker界面,进入Jupyter界面:
进入界面之后,选择图中所示功能进行相关操作:

然后输入如下python代码:注意,需要将其中的S3存储桶对应的信息切换为刚才咱们创建的S3通用存储桶信息才可以生效,在这一块,我贴出代码:
import sagemaker
sess = sagemaker.Session()
bucket = sess.default_bucket()
!xxx s3 sync s3://sagemaker-sample-files/datasets/image/caltech-101/inference/ s3://{bucket}/ground-truth-demo/images/
print('Copy and paste the below link into a web browser to confirm the ten images were successfully uploaded to your bucket:')
print(f'https://s3.console.xxx.amazon.com/s3/buckets/{bucket}/ground-truth-demo/images/')
print('\nWhen prompted by Sagemaker to enter the S3 location for input datasets, you can paste in the below S3 URL')
print(f's3://{bucket}/ground-truth-demo/images/')
print('\nWhen prompted by Sagemaker to Specify a new location, you can paste in the below S3 URL')
print(f's3://{bucket}/ground-truth-demo/labeled-data/')标红的一处需要将对应信息切换成我们刚才创建的S3存储桶对应信息。
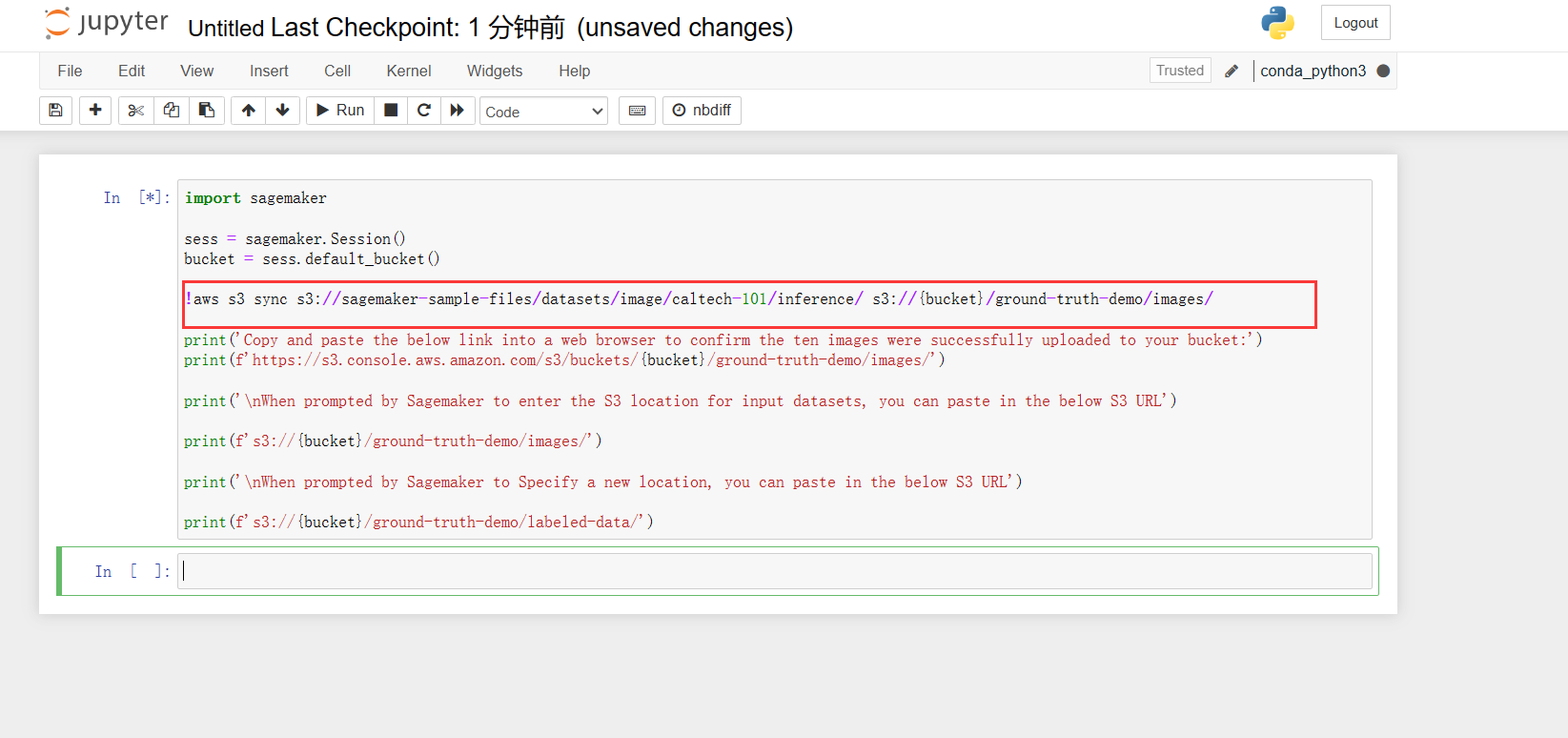
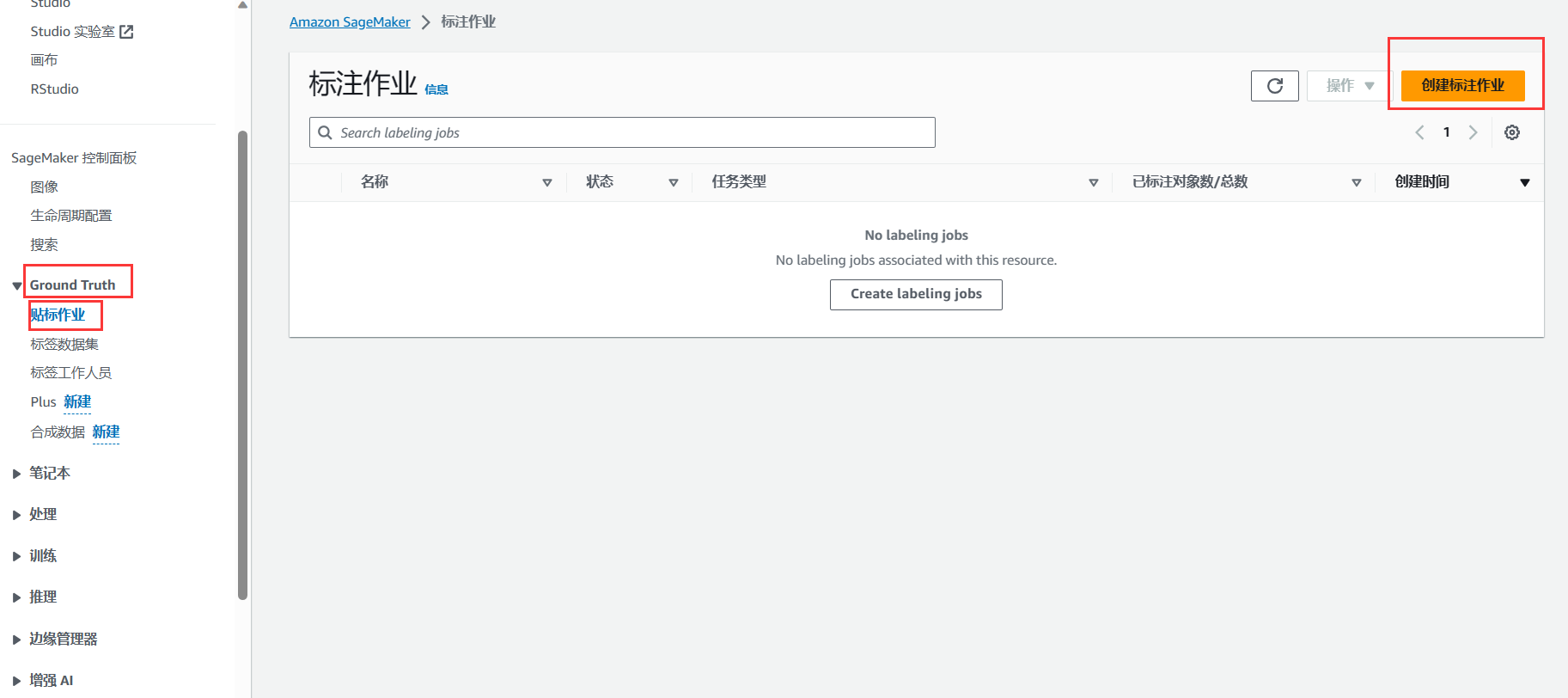
回到Amazon SageMaker界面,我们选择Ground Truth模块中的贴标作业,然后创建标准作业。
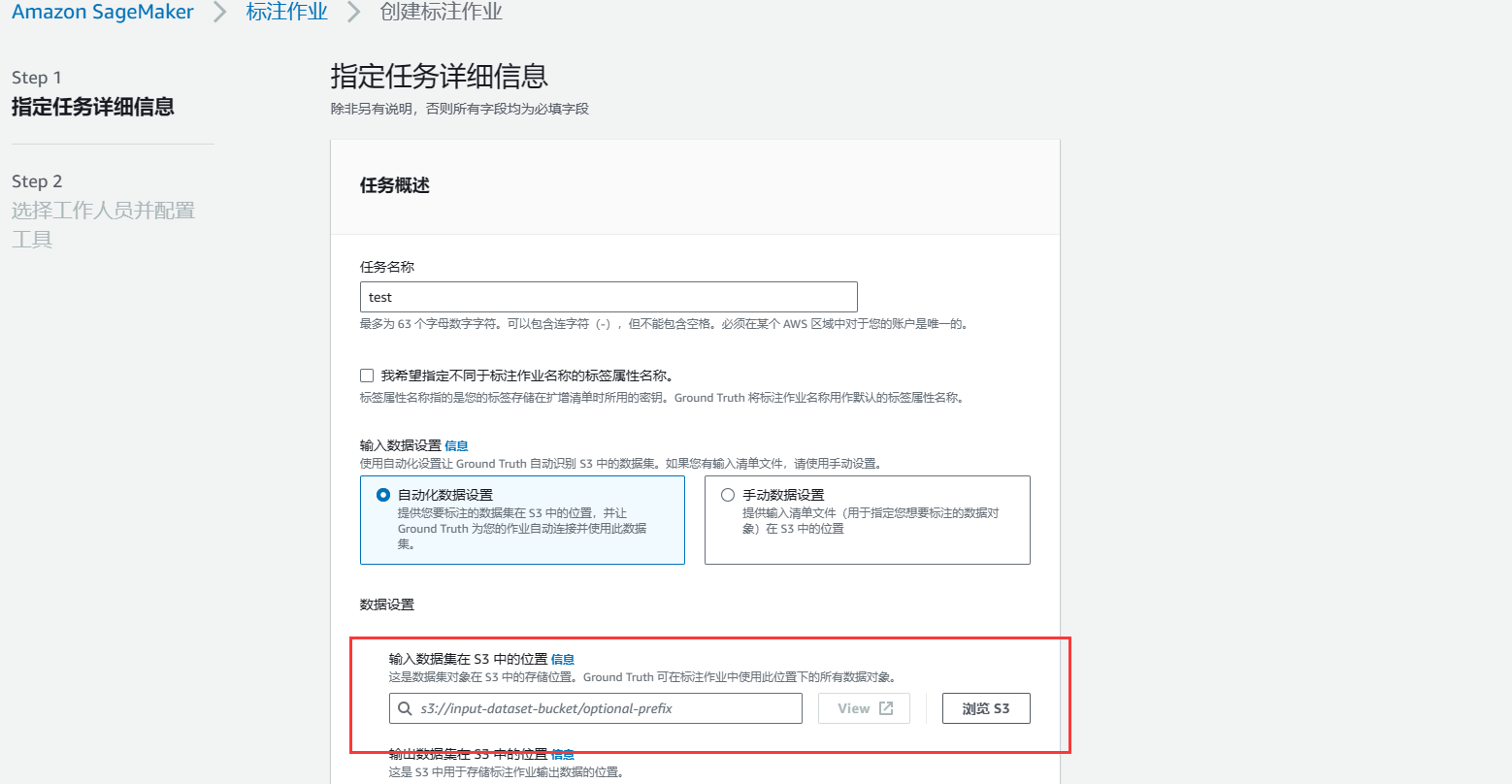
在创建的时候,选择我们刚才创建的S3存储桶,然后根据开发需求进行相关信息配置,配置完毕之后,开始创建。
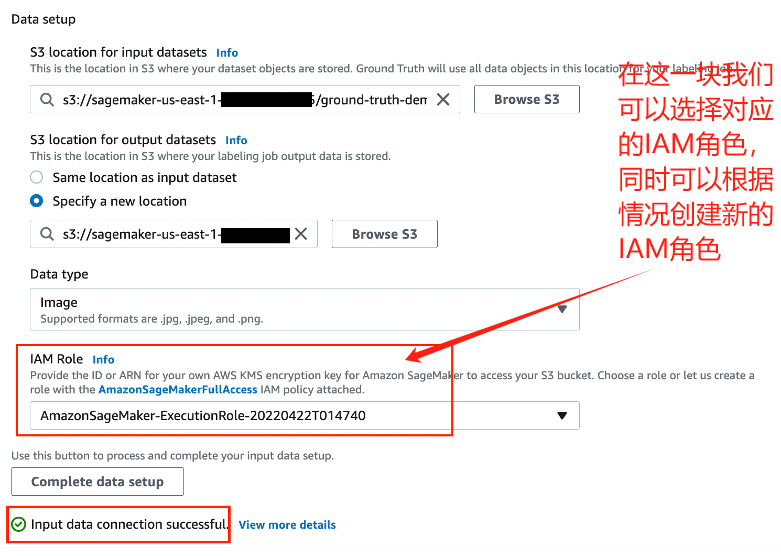
在数据设置中,将S3存储桶可以设置成我们刚才创建好的,同时数据类型选择图像,IAM角色选择创建新角色或使用早前Jupyter笔记本的对应数值:
在任务设置中,选择图像作为任务类型,选择图像分类(单个标签)作为任务类别,然后点击下一步。
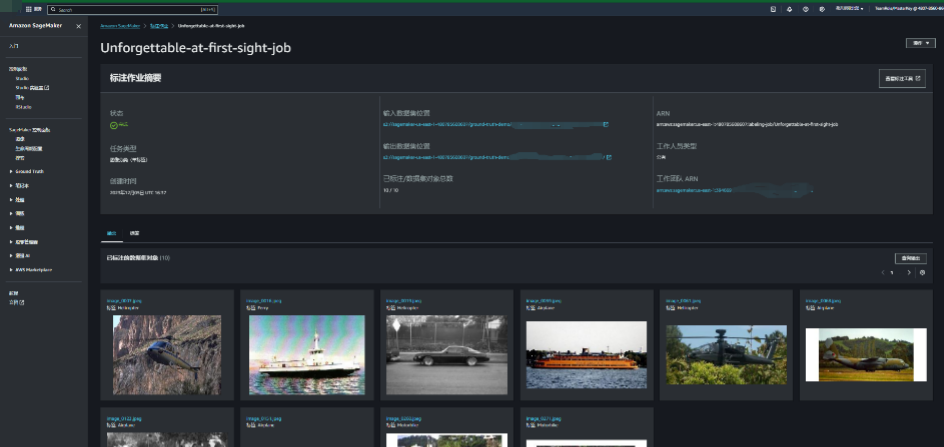
标注作业创建完毕之后,可以查看相关的信息。
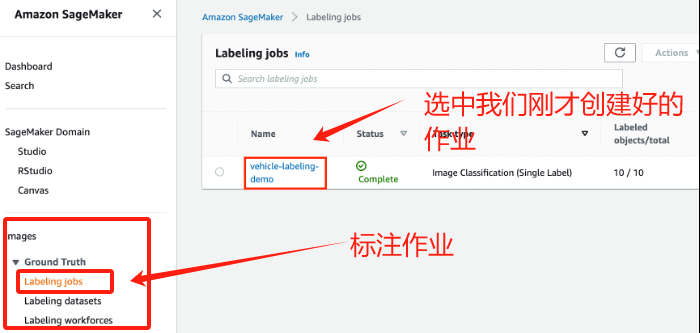
核查标注作业结果也至关重要,可评估标记质量和确定是否需要优化说明和数据。回到我们的SageMaker控制台,选择Labeling jobs标注作业,然后选择我们刚才创建好的作业,然后就可以进行对所选作业结果进行评估。
标注作业创建成功之后,我们选择左侧功能栏中的训练模块,开始根据需求进行作业训练,以便达到想要的结果。

然后训练作业,点击创建训练作业并且去配置相关训练参数,这一块信息配置可以根据开发需要进行相关设置。
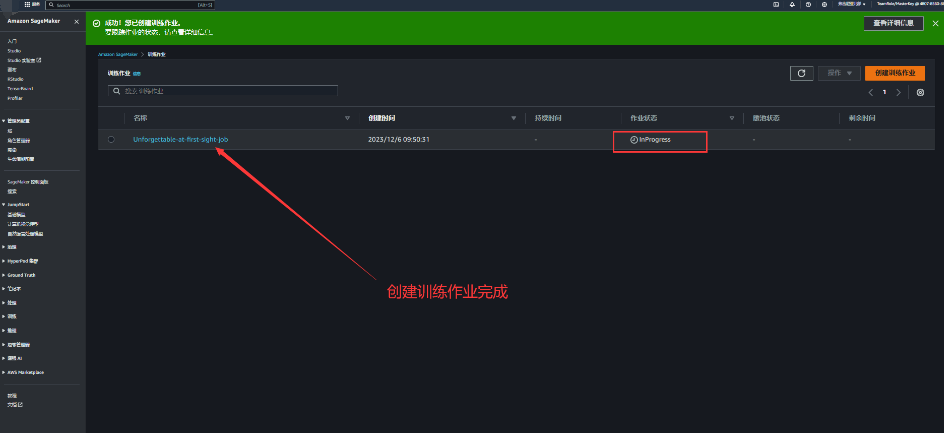
完成训练作业,当我们看到作业状态变更为success,即表示作业训练完成。
四、体验感悟和总结
作为一个机器学习爱好者,我对SageMaker HyperPod和Inference功能的引入感到非常激动。HyperPod作为一项创新性基础设施,解决了我在大规模分布式训练中所面临的挑战。以前,使用GPU和Trainium计算实例进行训练时,我常常碰到数据量增加、模型大小膨胀以及训练时间延长的问题。
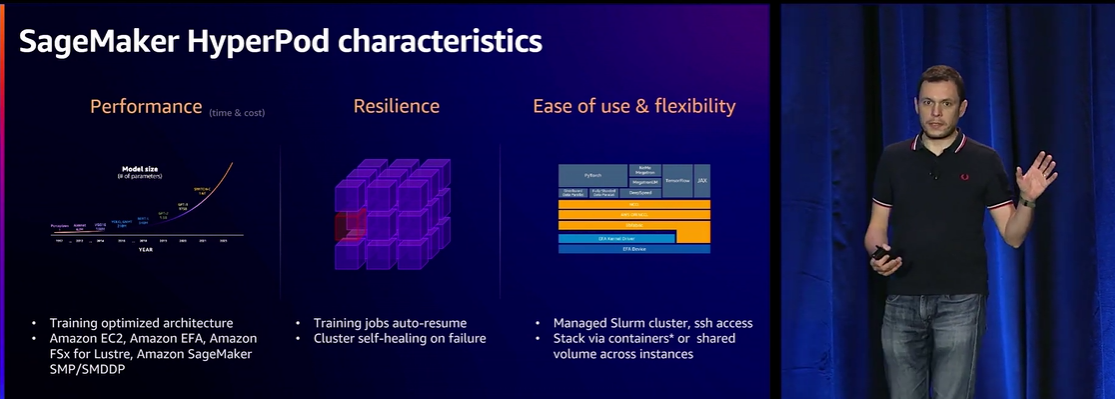
HyperPod的出现改变了这一切,通过自动分发训练工作负载到数千个加速器中,显著提高了我的模型性能。同时,它的定期保存检查点功能确保了在硬件故障发生时的平稳继续训练,省去了我繁琐的手动管理过程。现在,我能够更加高效地进行数周甚至数月的训练,为我的模型构建和优化提供了更多的便利。

而SageMaker Inference则是解决模型部署过程中成本和延迟问题的救星。通过支持将多个模型部署到同一实例,Inference平均降低了部署成本约50%。这让我可以更灵活地控制每个模型的扩展策略,更好地适应不同的模型使用模式,同时有效地优化基础架构成本。通过智能路由推理请求,SageMaker还能够主动监控实例处理请求的情况,将请求平均路由到可用的实例,降低了推理延迟约20%。

这一系列创新性功能的整合不仅在硬件基础设施的优化上取得了显著进展,同时也为我提供了更加便捷、高效的机器学习工作流。整体来说,Amazon SageMaker新推出的功能为用户在AI领域的探索之路提供了更为强大的支持,让用户更加期待未来在机器学习领域的深入应用。