Java 手写HashMap源码
一,手写源码
这是一个模仿HashMap的put,get功能的自定义的MyHashMap
package cn.wxs.demo;
import java.io.Serializable;
import java.util.*;
import java.util.function.BiConsumer;
import java.util.function.BiFunction;
import java.util.function.Function;
class MyHashMap<K, V> extends AbstractMap<K, V>
implements Map<K, V>, Cloneable, Serializable {
//数组默认长度
private static final int DEFAULT_CAPACITY = 16;
//负载因子
private static final float DEFAULT_LOAD_FACTOR = 0.75f;
//在jdk8中 链表转换红黑树阈值8 这里参考jdk11,提前进入红黑树
private static final int TREEIFY_THRESHOLD = 6;
// 在jdk8中 红黑树退回链表是6 这里参考jdk11,提高转换链表的阈值
private static final int UNTREEIFY_THRESHOLD = 8;
//数组长度低于64,出现转红黑树的情况,进行扩容,原先的二倍
private static final int MIN_TREEIFY_CAPACITY = 64;
private static Node[] table; // 存储桶数组
private static transient int size; // 键值对数量
//用于记录集合被修改的次数。在Java集合类中,如果在迭代器遍历集合时,
// 集合被修改了,就会抛出ConcurrentModificationException异常,
// 这是因为在遍历时,迭代器会检查modCount的值是否与集合的修改次数相等
//,如果不相等就会抛出异常,以此保证遍历的安全性。
private static transient int modCount;
private transient int threshold; // 扩容阈值
private final float loadFactor; // 负载因子
private static class Node<K, V> {
final int hash; // 哈希值
final K key; // 键
V value; // 值
Node<K, V> next; // 下一个节点
Node(int hash, K key, V value, Node<K, V> next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
public final K getKey() { return key; }
public final V getValue() { return value; }
public final String toString() { return key + "=" + value; }
public final int hashCode() {
return Objects.hashCode(key) ^ Objects.hashCode(value);
}
public final V setValue(V newValue) {
V oldValue = value;
value = newValue;
return oldValue;
}
public final boolean equals(Object o) {
if (o == this)
return true;
if (o instanceof Map.Entry) {
Map.Entry<?,?> e = (Map.Entry<?,?>)o;
return Objects.equals(key, e.getKey()) &&
Objects.equals(value, e.getValue());
}
return false;
}
}
public MyHashMap() {
this(DEFAULT_CAPACITY, DEFAULT_LOAD_FACTOR);
}
public MyHashMap(int initialCapacity, float loadFactor) {
if (initialCapacity <= 0)
throw new IllegalArgumentException("Invalid initial capacity");
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Invalid load factor");
table = new Node[initialCapacity];
size = 0;
this.loadFactor = loadFactor;
this.threshold = (int) (initialCapacity * loadFactor);
}
public V get(Object key) {
Node<K, V> node = getNode((K) key);
return (node != null) ? node.value : null;
}
public V put(K key, V value) {
if (key == null)
putForNullKey(value);
else
putNonNullKey(key, value);
return value;
}
private void putNonNullKey(K key, V value) {
int hash = hash(key);
int index = indexFor(hash, table.length);
// 遍历链表,查找是否已存在相同的键
for (Node node = table[index]; node != null; node = node.next) {
if (node.hash == hash && Objects.equals(node.key, key)) {
// 如果找到相同的键,更新对应的值
node.value = value;
return;
}
}
// 如果没有找到相同的键,将新的键值对添加到链表头部
addNode(hash, key, value, index);
}
private void putForNullKey(V value) {
// 对于 null 键,存储在数组的第一个位置
for (Node node = table[0]; node != null; node = node.next) {
if (node.key == null) {
// 如果找到 null 键,更新对应的值
node.value = value;
return;
}
}
// 如果没有找到 null 键,将新的键值对添加到链表头部
addNode(0, null, value, 0);
}
private void addNode(int hash, K key, V value, int bucketIndex) {
// 检查是否需要扩容
if (size >= threshold)
resize(2 * table.length);
// 将新的节点添加到链表头部
Node newNode = new Node<>(hash, key, value, table[bucketIndex]);
table[bucketIndex] = newNode;
size++;
modCount++;
}
private Node<K, V> getNode(K key) {
if (key == null)
return getNodeForNullKey();
int hash = hash(key);
int index = indexFor(hash, table.length);
// 遍历链表,查找指定的键
for (Node node = table[index]; node != null; node = node.next) {
if (node.hash == hash && Objects.equals(node.key, key))
return node;
}
return null;
}
private Node<K, V> getNodeForNullKey() {
// 对于 null 键,存储在数组的第一个位置
for (Node<K, V> node = table[0]; node != null; node = node.next) {
if (node.key == null)
return node;
}
return null;
}
private int hash(K key) {
// 计算键的哈希值
return (key == null) ? 0 : key.hashCode();
}
private int indexFor(int hash, int length) {
// 根据哈希值和数组长度计算索引位置
return hash & (length - 1);
}
private void resize(int newCapacity) {
Node<K, V>[] oldTable = table;
int oldCapacity = oldTable.length;
// 检查是否达到容量上限
if (oldCapacity >= 1 << 30)
threshold = Integer.MAX_VALUE;
else
threshold = (int) (newCapacity * loadFactor);
// 创建新的数组,将旧的键值对重新分配到新的数组中
Node<K,V>[] newTable = new Node[newCapacity];
transfer(oldTable, newTable);
table = newTable;
}
private void transfer(Node<K, V>[] src, Node<K, V>[] dest) {
// 遍历旧的数组,将键值对重新分配到新的数组中
for (Node<K, V> node : src) {
while (node != null) {
Node<K, V> next = node.next;
int index = indexFor(node.hash, dest.length);
node.next = dest[index];
dest[index] = node;
node = next;
}
}
}
@Override
public void forEach(BiConsumer<? super K, ? super V> action) {
Node[] tab;
if (action == null)
throw new NullPointerException();
if (size > 0 && (tab = table) != null) {
int mc = modCount;
for (Node kvNode : tab) {
for (Node<K, V> e = kvNode; e != null; e = e.next)
action.accept(e.key, e.value);
}
if (modCount != mc)
throw new ConcurrentModificationException();
}
}
@Override
public MyHashMap<K, V> clone() {
try {
MyHashMap clone = (MyHashMap) super.clone();
// TODO: copy mutable state here, so the clone can't change the internals of the original
return clone;
} catch (CloneNotSupportedException e) {
throw new AssertionError();
}
}
/**
* 获取hashmap的存储值数量
*
* @return 存储数量
*/
public int size() {
return size;
}
public boolean isEmpty() {
return size() == 0;
}
@Override
public void replaceAll(BiFunction<? super K, ? super V, ? extends V> function) {
super.replaceAll(function);
}
@Override
public V putIfAbsent(K key, V value) {
return super.putIfAbsent(key, value);
}
@Override
public boolean remove(Object key, Object value) {
return super.remove(key, value);
}
@Override
public boolean replace(K key, V oldValue, V newValue) {
return super.replace(key, oldValue, newValue);
}
@Override
public V replace(K key, V value) {
return super.replace(key, value);
}
@Override
public V computeIfAbsent(K key, Function<? super K, ? extends V> mappingFunction) {
return super.computeIfAbsent(key, mappingFunction);
}
@Override
public V computeIfPresent(K key, BiFunction<? super K, ? super V, ? extends V> remappingFunction) {
return super.computeIfPresent(key, remappingFunction);
}
@Override
public V compute(K key, BiFunction<? super K, ? super V, ? extends V> remappingFunction) {
return super.compute(key, remappingFunction);
}
@Override
public V merge(K key, V value, BiFunction<? super V, ? super V, ? extends V> remappingFunction) {
return super.merge(key, value, remappingFunction);
}
@Override
public Set<Entry<K, V>> entrySet() {
return null;
}
@Override
public V getOrDefault(Object key, V defaultValue) {
return super.getOrDefault(key, defaultValue);
}
public static void main(String[] args) {
Map<String,String> para = new HashMap<>();
para.remove("");
MyHashMap<String, String> param = new MyHashMap<>();
param.put("你好", "你好");
param.put("你好1", "你好1");
param.put("你好2", "你好2");
param.put("你好3", "你好3");
param.put("你好4", "你好4");
param.put("你好5", "你好4");
param.put("你好6", "你好4");
param.put("你好7", "你好4");
param.put("你好8", "你好4");
param.put("你好9", "你好4");
param.put("你好10", "你好4");
param.put("你好11", "你好4");
param.put("你好12", "你好4");
param.put("你好13", "你好4");
param.put("你好14", "你好4");
param.put("你好15", "你好4");
param.put("你好16", "你好4");
param.put("你好17", "你好4");
param.put("你好18", "你好4");
param.put("你好20", "你好4");
param.put("你好21", "你好4");
param.put("你好22", "你好4");
param.put("你好23", "你好4");
param.put("你好24", "你好4");
param.put("你好25", "你好4");
param.put("你好26", "你好4");
param.put("你好27", "你好4");
param.put("你好28", "你好4");
param.put("你好29", "你好4");
param.put("你好30", "你好4");
param.put("你好31", "你好4");
param.put("你好32", "你好4");
param.forEach((k, v) -> System.out.println(k));
System.out.println(param.get("你好4"));
System.out.println(param.size());
}
}
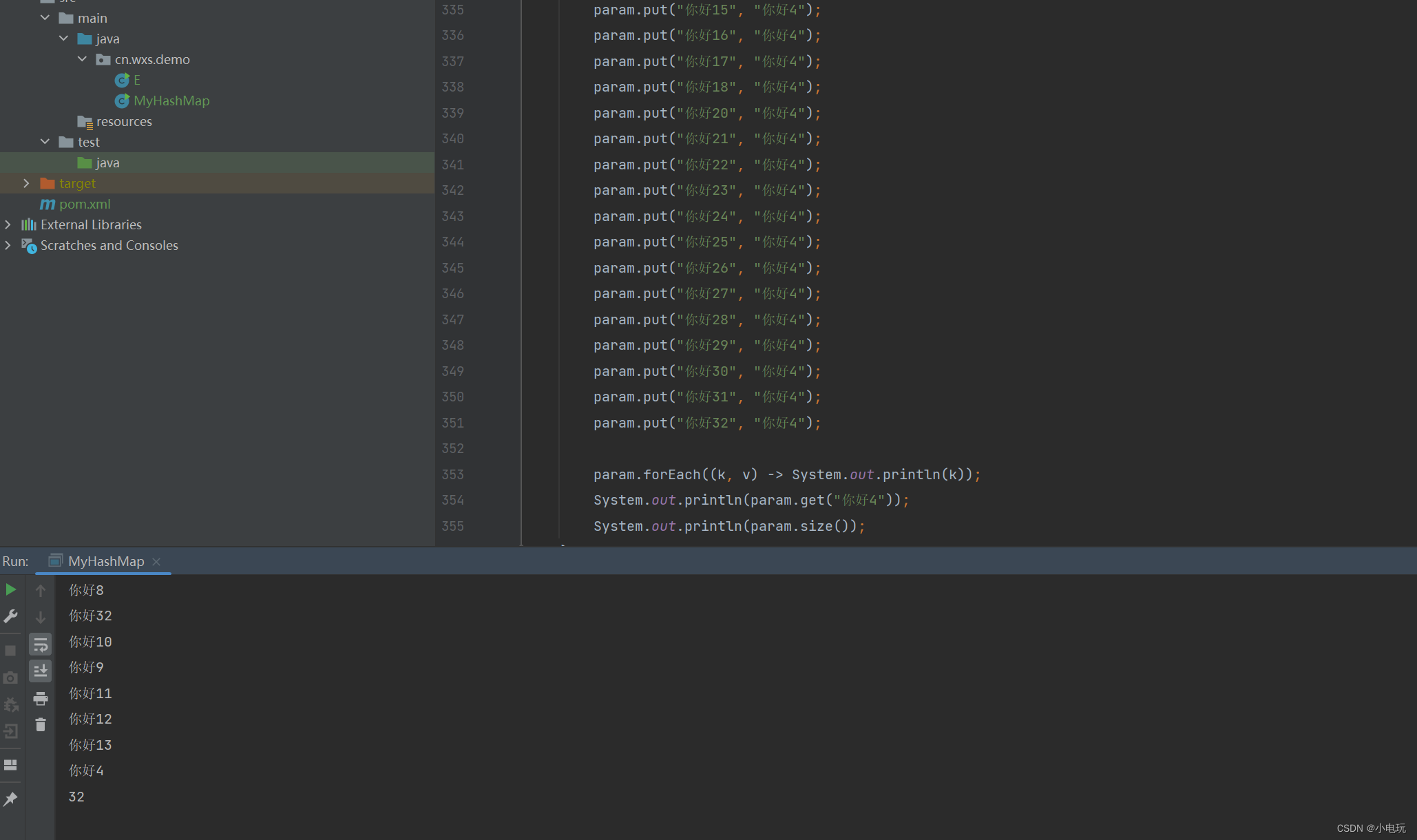
二,代码介绍
1.这是一个简单的自定义哈希映射(HashMap)的实现。功能不太完善,代码不太优雅,细节不够好,没有源码的那么好。后面我会慢慢进行优化
2.这段代码实现了一个简化版本的 HashMap,包含了 put 和 get 方法,并使用了数组+链表的存储结构。注意,这里的红黑树部分并未实现,只使用了链表来处理冲突。由于短时间没有办法能按自己的方式写出来全部的功能和底层设计,难度还是比较大的后期我会慢慢的把存储结构改成数组+链表+红黑树的数据结构
请注意,这只是一个简化版本的实现,并没有处理扩容、红黑树转换等复杂的细节。实际的 HashMap 实现要复杂得多。如果你对完整的实现感兴趣,建议你查阅 Java 的 HashMap 源代码,以便更好地理解和学习。
三,下期完善功能
存储结构 数组+链表+红黑树
三,HashMap
HashMap 是 Java 中的一个常用的数据结构,它实现了 Map 接口,并且基于哈希表实现。HashMap 允许存储键值对,并且提供了快速的插入、查找和删除操作。
下面是 HashMap 的一些重要特点和概念:
-
哈希表:
HashMap内部使用了一个数组来存储数据,这个数组被称为哈希表。哈希表的每个元素称为一个桶(bucket),每个桶可以存储一个或多个键值对。通过计算键的哈希值,可以确定键值对在哈希表中的位置。 -
哈希函数:哈希函数用于将键映射到哈希表中的索引位置。好的哈希函数能够将键均匀地分布在哈希表的不同位置上,以减少冲突的概率。在
HashMap中,键的hashCode()方法被用作哈希函数。 -
冲突:当两个不同的键通过哈希函数计算得到的索引位置相同时,就发生了冲突。
HashMap使用链表或红黑树来解决冲突。当冲突较少时,使用链表;当链表长度超过一定阈值时,转换为红黑树,以提高查找的效率。 -
键的唯一性:在
HashMap中,键是唯一的。如果尝试将一个已经存在的键插入到HashMap中,它的值将被更新为新的值。 -
null 键:
HashMap允许存储一个键为 null 的键值对。这个键将被存储在哈希表的第一个位置上。 -
迭代顺序:
HashMap不保证键值对的迭代顺序,它通常是不确定的。如果需要有序的键值对集合,可以使用LinkedHashMap。
下面是一些常用的操作方法:
put(key, value):向HashMap中插入一个键值对。get(key):根据键获取对应的值。remove(key):根据键删除对应的键值对。containsKey(key):检查是否包含指定的键。containsValue(value):检查是否包含指定的值。size():返回HashMap中键值对的数量。
需要注意的是,HashMap 是非线程安全的,如果在多线程环境中使用,需要进行适当的同步处理,或者使用线程安全的 ConcurrentHashMap。
HashMap 的时间复杂度通常是常数级别的,即 O(1),但在最坏的情况下,可能会达到 O(n),其中 n 是 HashMap 中存储的键值对数量。
希望这个简介对你理解 HashMap 有所帮助!如果你有任何其他问题,请随时提问。

![读书笔记-《数据结构与算法》-摘要5[归并排序]](https://img-blog.csdnimg.cn/direct/64be7b3c55f649b58c86cd6ddbebe3e1.gif)