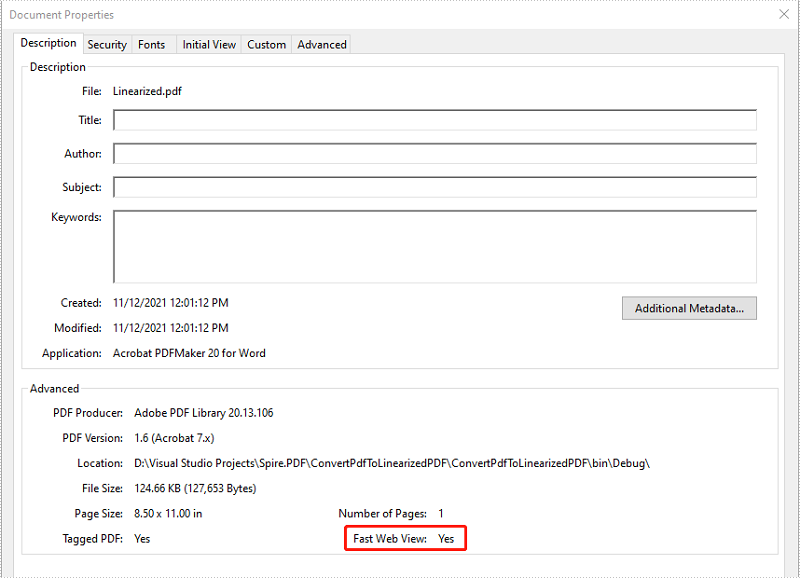
一、模型选择
1、问题导入


2、训练误差与泛化误差

3、验证数据集和测试数据集

4、K-折交叉验证
一般在没有足够多数据时使用。

二、过拟合与欠拟合

1、过拟合
过拟合的定义:
当学习器把训练样本学的“太好”了的时候,很可能已经把训练样本自身的一些特点当作了所有潜在样本都会具有的一般性质,这样就会导致泛化性能下降,这种现象称为过拟合。具体表现就是最终模型在训练集上效果好;在测试集上效果差。模型泛化能力弱。
过拟合的原因:
- 训练数据中噪音干扰过大,使得学习器认为部分噪音是特征从而扰乱学习规则。
- 建模样本选取有误,例如训练数据太少,抽样方法错误,样本label错误等,导致样本不能代表整体。
- 模型不合理,或假设成立的条件与实际不符。
- 特征维度/参数太多,导致模型复杂度太高。
2、欠拟合
欠拟合的定义:
欠拟合是指对训练样本的一般性质尚未学好。在训练集及测试集上的表现都不好。
欠拟合的原因:
- 模型复杂度过低
- 特征量过少
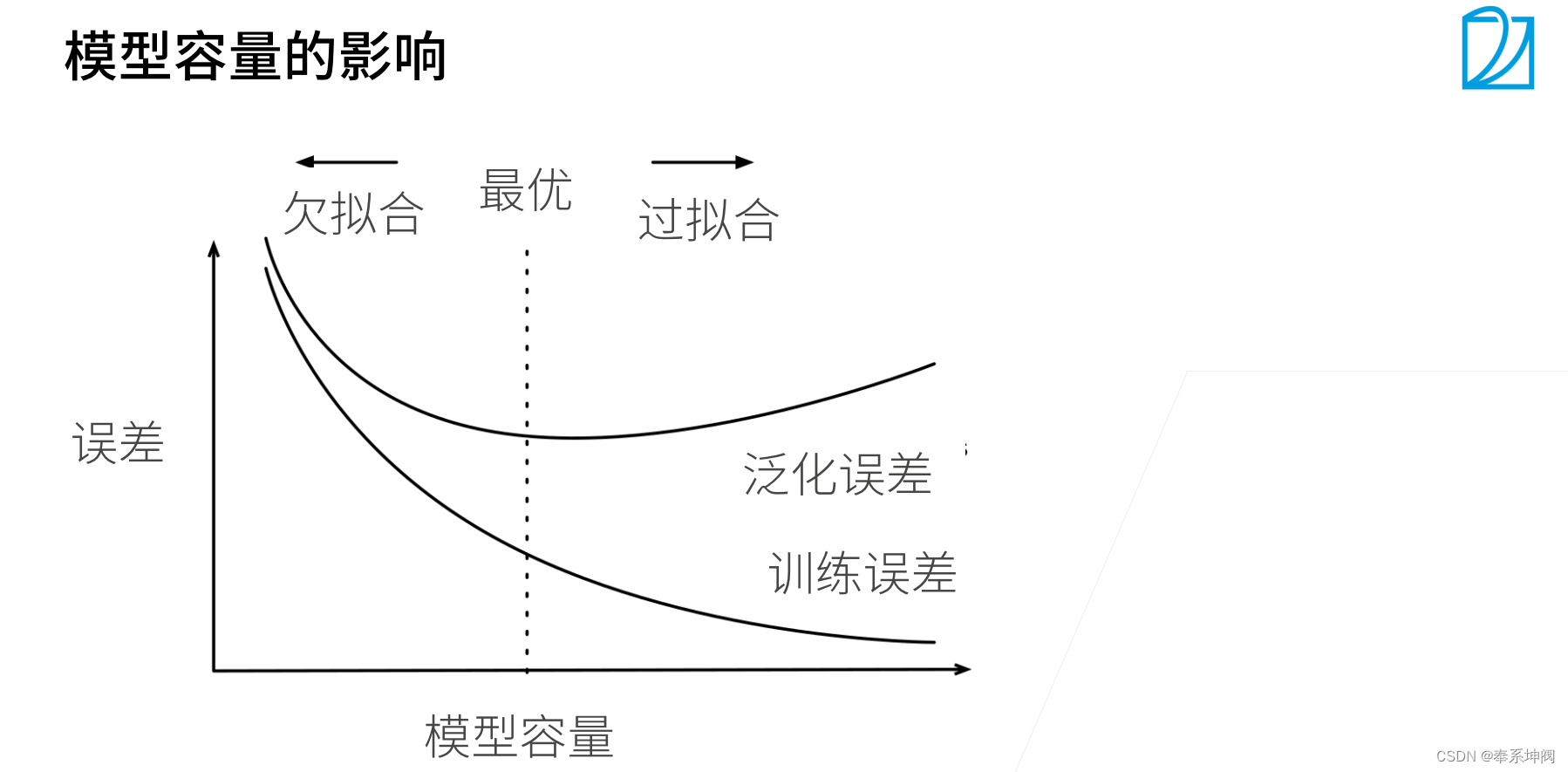
3、模型容量


4、数据复杂度