- 1.x版本架构
- 2.x版本架构
- 3.x版本架构
- 参考
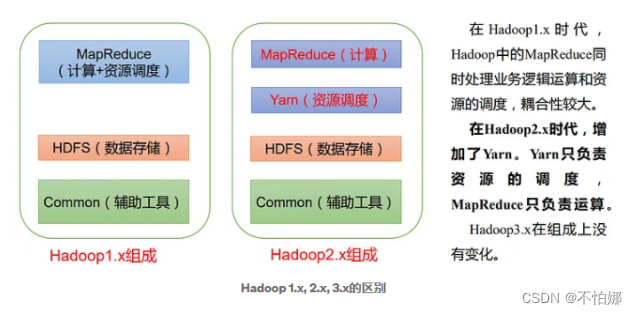
1.x版本架构
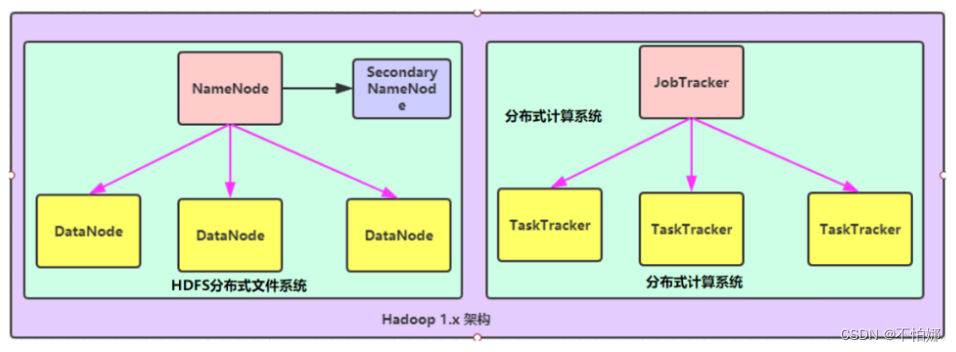
-
NameNode:,负责文件系统的名字空间(Namespace)管理以及客户端对文
件的访问。NameNode负责文件元数据的管理和操作。是单节点。
-
Secondary NameNode:它的职责是合并NameNode的edit logs到fs_image文件中,并将合并文件返回给Namenode。然后Namenode将该文件加载到内存中。Secondary Namenode不提供故障转移功能,在Namenode挂掉的情况下,Hadoop管理员必须手动从Secondary Namenode恢复数据。
-
DataNode:DataNode 是文件系统中真正存储数据的地方。
-
JobTracker:负责作业调度,首先用户程序 (JobClient) 提交了一个 job,job 的信息会发送到 Job Tracker 中,Job Tracker 是 Map-reduce 框架的中心,他需要与集群中的机器定时通信 (heartbeat), 需要管理哪些程序应该跑在哪些机器上,需要管理所有 job 失败、重启等操作,是单节点。简单来说就是接收用户的计算请求任务,并分配任务给从节点。
-
TaskTracker: TaskTracker 是 Map-reduce 集群中每台机器都有的一个部分,他做的事情主要是监视自己所在机器的资源情况。TaskTracker 同时监视当前机器的 tasks 运行状况(包括启动和监控作业、获取其输出,以及通知 JobTracker 作业完成)。TaskTracker 需要把这些信息通过 heartbeat 发送给 JobTracker,JobTracker 会搜集这些信息以给新提交的 job 分配运行在哪些机器上,是多节点。简单来说就是负责执行主节点JobTracker分配的任务。
2.x版本架构
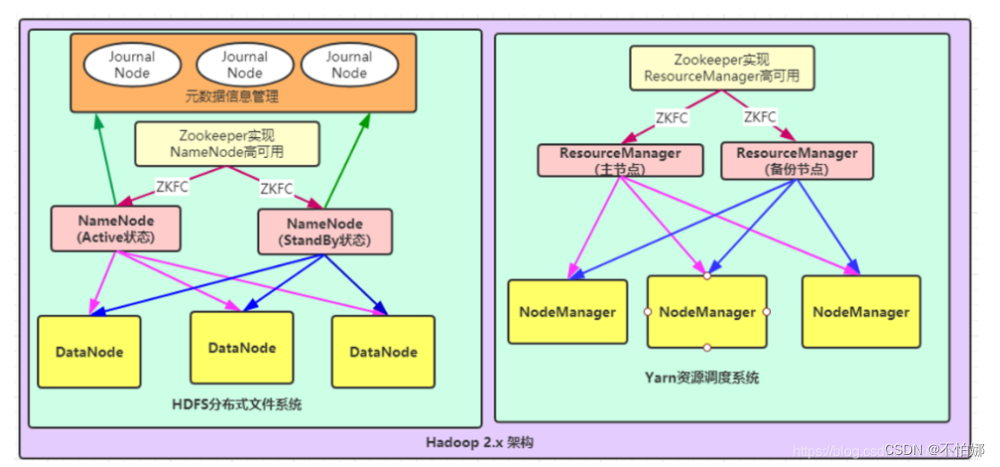
- NameNode:集群当中的主节点,主要用于管理集群当中的各种数据,一般都是使用两个,实现HA高可用
- Standby Namenode:在Hadoop 2.0中,随着HA的引入,Hadoop框架中增加了Standby Namenode。备用namenode节点是用来解决Hadoop 1.x中存在的SPOF(单点故障) 问题。Active NameNode 和 Standby NameNode两台 NameNode 形成互备,一台处于 Active 状态,为主 NameNode,另外一台处于 Standby 状态,为备 NameNode,只有主 NameNode 才能对外提供读写服务。Standby Namenode提供自动故障转移,以防Active Namenode挂掉。
- ResourceManager:MR资源管理。从某种意义上讲它就是一个纯粹的调度器,它在执行过程中不对应用进行监控和状态跟踪。同样,它也不能重启因应用失败或者硬件错误而运行失败的任务。ResourceManager是基于应用程序对资源的需求进行调度的;每一个应用程序需要不同类型的资源因此就需要不同的容器。资源包括:内存,CPU,磁盘,网络等等。资源管理器提供一个调度策略的插件,它负责将集群资源分配给多个队列和应用程序。调度插件可以基于现有的能力调度和公平调度模型。
- NodeManager:NodeManager是执行应用程序的容器,监控应用程序的资源使用情况 (CPU,内存,硬盘,网络 ) 并且向调度器汇报。
3.x版本架构
Hadoop3.x的基本架构和Hadoop2.x 类似,但是Hadoop3.x加入很多新特性,如支持多NameNode,同时对HDFS和MapReduce也进行了优化。
参考
https://cloud.tencent.com/developer/article/1887124
https://andr-robot.github.io/Hadoop%E5%9F%BA%E7%A1%80%E6%9E%B6%E6%9E%84%E5%8F%98%E5%8C%96/







![[Halcon图像] 基于多层神经网络MLP分类器的思想提取颜色区域](https://img-blog.csdnimg.cn/direct/6a21c3cbf58e4f528f532a86eb6a2f58.png)