为什么需要分库?
随着数据量的急速上升,单个数据库可能会QPS过高导致读写耗时过长而出现性能瓶颈,所以需要考虑拆分数据库,将数据库分布在不同实例上提升数据库可用性。主要的原因有如下:
- 磁盘存储。业务量剧增,MySQL单机磁盘容量会撑爆,磁盘使用率过高的情况下甚至会影响性能,拆成多个数据库,磁盘使用率大大降低。
- 并发连接限制。单个数据库的连接存在上限,如果连接数超过上限,会出现connect refused,导致有些请求无法成功请求数据库。特别在高并发场景下,单机MySQL压力很大甚至扛不住而导致MySQL连接打满造成不可用,影响业务正常运行。
为什么需要分表?
随着单表数据量的增加,对于数据的查询和更新,即使在数据库底层有一定的优化,但是随着量变必定会引起质变,导致性能急剧下降。这时可以通过分表的方法,将单表数据按一定规则水平拆分到多个表中,减小单表的数据量,提升系统性能。
如果一个查询SQL没命中索引,千百万数据量的表可能会拖垮这个数据库。即使SQL命中了索引,如果表的数据量超过一千万的话,查询也是会明显变慢的。因为索引一般是B+树结构,数据千万级别的话,B+树的高度会增高,高度越高,磁盘IO次数越多,查询就变慢。
拆分方式
- 垂直拆分。垂直拆库可以理解为把单库里的不同表拆分至不同数据库。垂直拆表可以理解为将一个表里的部分列(可以是长度较长的、不常用的等)拆分至另一个表,使得每张表的职责更明确,数据更聚焦。
- 水平拆分。水平分库是指,将表的数据量切分到不同的数据库服务器上,每个服务器具有相同的库和表,只是表中的数据集合不一样。它可以有效的缓解单机单库的性能瓶颈和压力。水平分表指一按照某种规则(如hash取模、range),把表里的数据切分到多张同样职责的表中。
分库分表带来的问题
- 不同数据库存在于不同实例上,本地事务无效,需要使用分布式事务
- 跨数据库进行Join操作,需要将sql拆成多次查询。
- 跨节点排序。需要在每个数据库都排完序后,在应用层再次合并排序。
- 分页。需要在应用层额外处理。
- 分布式ID。分库分表需要保证id不重复,需要额外使用雪花算法或者uuid生成全局id。
ShardingShpere-proxy
ShardingSphere 是一款分布式的数据库生态系统, 可以将任意数据库转换为分布式数据库,并通过数据分片、弹性伸缩、加密等能力对原有数据库进行增强。它站在数据库的上层视角,关注它们之间的协作多于数据库自身。
我们系统使用ShardingSphere-proxy,并部署为一个单独的分片服务。ShardingShphere生态中还有ShardingShpere-JDBC,其作为sdk的方式附载在业务项目中。主要是用shardingShpere-proxy的数据分片能力来提供逻辑SQL的功能。
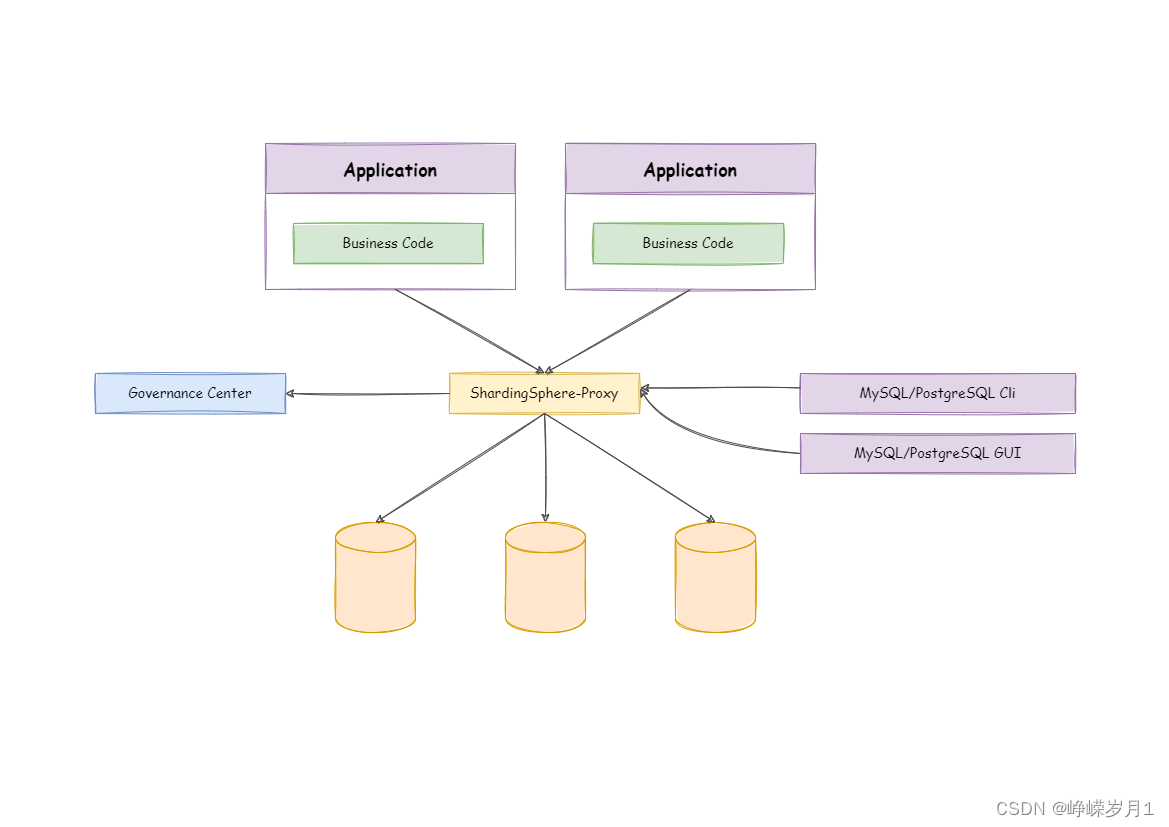
数据分片
用户使用时,只需要传入基于逻辑库/表的sql操作即可,提升使用效率,简化流程。
数据分片流程:
sql 解析 - 词法解析和语法解析;
sql 路由 - 根据解析上下文匹配数据库和表的分片策略,并生成路由路径;
sql 改写 - 将逻辑 SQL 改写为在真实数据库中可以正确执行的 SQL;
sql 执行 - 使用多线程并发执行 sql;
结果归并 - 将从各个数据节点获取的多数据结果集,组合成为一个结果集并正确的返回至请求客户端;
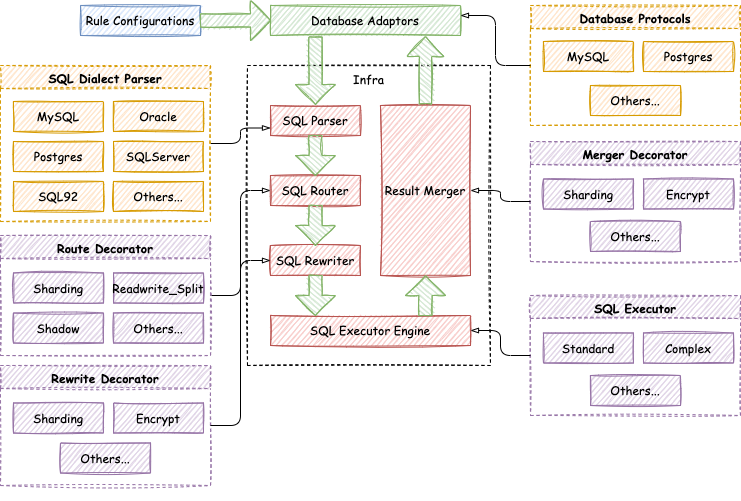
https://shardingsphere.apache.org/document/current/cn/reference/sharding/route/




![[Halcon图像] 基于多层神经网络MLP分类器的思想提取颜色区域](https://img-blog.csdnimg.cn/direct/6a21c3cbf58e4f528f532a86eb6a2f58.png)