1.研究背景与意义
项目参考AAAI Association for the Advancement of Artificial Intelligence
研究背景与意义
近年来,随着深度学习技术的快速发展,人脸识别技术在各个领域得到了广泛应用。其中,人脸测距和社交距离过近警报系统成为了人们关注的热点问题。随着全球范围内新冠疫情的爆发,人们对于社交距离的重视程度进一步提高。在公共场所,如超市、车站、学校等地方,人们之间的社交距离过近可能导致疾病的传播,因此需要一种可靠的方法来监测和提醒人们保持安全的社交距离。
传统的人脸测距和社交距离过近警报系统主要依赖于传感器和计算机视觉技术。然而,这些方法往往需要复杂的设备和大量的人力投入,且准确度有限。而基于深度学习的人脸测距和社交距离过近警报系统则可以通过分析人脸图像中的特征来实现实时、准确的距离测量和警报功能。
深度学习是一种模仿人脑神经网络结构和工作原理的机器学习方法。通过构建多层神经网络,深度学习可以从大量的数据中学习和提取特征,从而实现对复杂问题的解决。在人脸测距和社交距离过近警报系统中,深度学习可以通过训练大量的人脸图像数据,学习人脸的特征表示和距离测量方法,从而实现准确的距离测量和警报功能。
基于深度学习的人脸测距和社交距离过近警报系统具有以下几个重要意义:
-
提高公共场所的安全性:在公共场所,人们之间的社交距离过近可能导致疾病的传播。通过使用基于深度学习的人脸测距和社交距离过近警报系统,可以实时监测人们之间的距离,并及时提醒他们保持安全的社交距离,从而提高公共场所的安全性。
-
减少人力投入:传统的人脸测距和社交距离过近警报系统需要大量的人力投入,如安装传感器、监控和分析人脸图像等。而基于深度学习的方法可以通过分析人脸图像中的特征来实现距离测量和警报功能,减少了人力投入的需求,提高了系统的效率和可靠性。
-
推动深度学习技术的应用:基于深度学习的人脸测距和社交距离过近警报系统是深度学习技术在实际应用中的一个典型案例。通过解决实际问题,可以推动深度学习技术在其他领域的应用,促进科技创新和社会进步。
-
促进社会文明进步:社交距离的保持是一种社会文明的表现。通过使用基于深度学习的人脸测距和社交距离过近警报系统,可以提醒人们保持安全的社交距离,促进社会文明的进步,培养良好的公共行为习惯。
总之,基于深度学习的人脸测距和社交距离过近警报系统在提高公共场所的安全性、减少人力投入、推动深度学习技术的应用和促进社会文明进步等方面具有重要意义。随着深度学习技术的不断发展和应用,相信这一系统将在未来得到更广泛的应用和推广。
2.图片演示



3.视频演示
基于深度学习的人脸测距&社交距离过近警报系统_哔哩哔哩_bilibili
4.核心代码讲解
4.1 ui.py
import cv2
import numpy as np
import itertools
def plot_dots_on_people(x, img):
# Plotting centers of people with green dot.
thickness = -1;
color = [0, 255, 0] # green
center = ((int(x[2]) + int(x[0])) // 2, (int(x[3]) + int(x[1])) // 2)
radius = 10
cv2.circle(img, center, radius, color, thickness)
def distancing(people_coords, img, dist_thres_lim=(200, 250)):
count_list = [0,0,0]
# Plot lines connecting people
already_red = dict() # dictionary to store if a plotted rectangle has already been labelled as high risk
centers = []
for i in people_coords:
centers.append(((int(i[2]) + int(i[0])) // 2, (int(i[3]) + int(i[1])) // 2))
for j in centers:
already_red[j] = 0
x_combs = list(itertools.combinations(people_coords, 2))
radius = 10
thickness = 5
font_scale = 0.5
font_thickness = 1
for x in x_combs:
xyxy1, xyxy2 = x[0], x[1]
cntr1 = ((int(xyxy1[2]) + int(xyxy1[0])) // 2, (int(xyxy1[3]) + int(xyxy1[1])) // 2)
cntr2 = ((int(xyxy2[2]) + int(xyxy2[0])) // 2, (int(xyxy2[3]) + int(xyxy2[1])) // 2)
dist = ((cntr2[0] - cntr1[0]) ** 2 + (cntr2[1] - cntr1[1]) ** 2) ** 0.5
if dist > dist_thres_lim[0] and dist < dist_thres_lim[1]:
count_list[1] += 1
color = (0, 255, 0)
label = "Mild aggregation"
cv2.line(img, cntr1, cntr2, color, thickness)
if already_red[cntr1] == 0:
cv2.circle(img, cntr1, radius, color, -1)
if already_red[cntr2] == 0:
cv2.circle(img, cntr2, radius, color, -1)
dist_text = f"{dist/200:.2f}" + ' m' # Format distance to 2 decimal places
dist_text_pos = ((cntr1[0] + cntr2[0]) // 2, (cntr1[1] + cntr2[1]) // 2 -10)
cv2.putText(img, dist_text, dist_text_pos, cv2.FONT_HERSHEY_SIMPLEX, font_scale, color, font_thickness)
elif dist < dist_thres_lim[0]:
count_list[0] += 1
color = (0, 0, 255)
label = "Severe aggregation"
already_red[cntr1] = 1
already_red[cntr2] = 1
cv2.line(img, cntr1, cntr2, color, thickness)
cv2.circle(img, cntr1, radius, color, -1)
cv2.circle(img, cntr2, radius, color, -1)
dist_text = f"{dist/200:.2f}" + ' m' # Format distance to 2 decimal places
dist_text_pos = ((cntr1[0] + cntr2[0]) // 2, (cntr1[1] + cntr2[1]) // 2 -10)
cv2.putText(img, dist_text, dist_text_pos, cv2.FONT_HERSHEY_SIMPLEX, font_scale, color, font_thickness)
else:
count_list[2] += 1
return count_list
class FruitDetector:
def __init__(self, img_path):
self.img = cv2.imread(img_path, cv2.IMREAD_COLOR)
self.gray = cv2.cvtColor(self.img, cv2.COLOR_BGR2GRAY)
def detect(self):
# 边缘检测
edges = cv2.Canny(self.gray, 100, 200)
# 特征提取
contours, _ = cv2.findContours(edges, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE)
areas = [cv2.contourArea(c) for c in contours]
max_index = np.argmax(areas)
cnt = contours[max_index]
# 阈值分割
mask = np.zeros_like(self.gray)
cv2.drawContours(mask, [cnt], 0, 255, -1)
thresh = cv2.threshold(self.gray, 0, 255, cv2.THRESH_BINARY + cv2.THRESH_OTSU)[1]
mask = cv2.bitwise_and(mask, thresh)
# 开运算闭运算
kernel = cv2.getStructuringElement(cv2.MORPH_ELLIPSE, (5, 5))
opening = cv2.morphologyEx(mask, cv2.MORPH_OPEN, kernel)
closing = cv2.morphologyEx(opening, cv2.MORPH_CLOSE, kernel)
# 绘制边框
x, y, w, h = cv2.boundingRect(closing)
cv2.rectangle(self.img, (x, y), (x + w, y + h), (0, 255, 0), 2)
return self.img
该程序文件名为ui.py,主要功能如下:
-
导入了一系列的库,包括argparse、platform、shutil、time、numpy、os、sys、pathlib、cv2、PyQt5等。
-
定义了一些函数,包括plot_dots_on_people函数用于在图像上绘制人的中心点,distancing函数用于计算人与人之间的距离,MyWidget类用于创建一个提示框,FruitDetector类用于水果检测,load_model函数用于加载模型,run函数用于运行模型进行目标检测。
-
det函数是主要的函数,用于进行目标检测。它接收一个参数info1,表示图像路径。在函数内部,首先调用load_model函数加载模型,然后调用FruitDetector类进行水果检测,最后调用run函数进行目标检测。函数返回目标检测结果和处理后的图像。
5.2 models\common.py
import torch.nn as nn
class Conv(nn.Module):
# Standard convolution
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True): # ch_in, ch_out, kernel, stride, padding, groups
super().__init__()
self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p), groups=g, bias=False)
self.bn = nn.BatchNorm2d(c2)
self.act = nn.SiLU() if act is True else (act if isinstance(act, nn.Module) else nn.Identity())
def forward(self, x):
return self.act(self.bn(self.conv(x)))
def forward_fuse(self, x):
return self.act(self.conv(x))
class DWConv(Conv):
# Depth-wise convolution class
def __init__(self, c1, c2, k=1, s=1, act=True): # ch_in, ch_out, kernel, stride, padding, groups
super().__init__(c1, c2, k, s, g=math.gcd(c1, c2), act=act)
class TransformerLayer(nn.Module):
# Transformer layer https://arxiv.org/abs/2010.11929 (LayerNorm layers removed for better performance)
def __init__(self, c, num_heads):
super().__init__()
self.q = nn.Linear(c, c, bias=False)
self.k = nn.Linear(c, c, bias=False)
self.v = nn.Linear(c, c, bias=False)
self.ma = nn.MultiheadAttention(embed_dim=c, num_heads=num_heads)
self.fc1 = nn.Linear(c, c, bias=False)
self.fc2 = nn.Linear(c, c, bias=False)
def forward(self, x):
x = self.ma(self.q(x), self.k(x), self.v(x))[0] + x
x = self.fc2(self.fc1(x)) + x
return x
class TransformerBlock(nn.Module):
# Vision Transformer https://arxiv.org/abs/2010.11929
def __init__(self, c1, c2, num_heads, num_layers):
super().__init__()
self.conv = None
if c1 != c2:
self.conv = Conv(c1, c2)
self.linear = nn.Linear(c2, c2) # learnable position embedding
self.tr = nn.Sequential(*(TransformerLayer(c2, num_heads) for _ in range(num_layers)))
self.c2 = c2
def forward(self, x):
if self.conv is not None:
x = self.conv(x)
b, _, w, h = x.shape
p = x.flatten(2).permute(2, 0, 1)
return self.tr(p + self.linear(p)).permute(1, 2, 0).reshape(b, self.c2, w, h)
class Bottleneck(nn.Module):
# Standard bottleneck
def __init__(self, c1, c2, shortcut=True, g=1, e=0.5): # ch_in, ch_out, shortcut, groups, expansion
super().__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c_, c2, 3, 1, g=g)
self.add = shortcut and c1 == c2
def forward(self, x):
return x + self.cv2(self.cv1(x)) if self.add else self.cv2(self.cv1(x))
class BottleneckCSP(nn.Module):
# CSP Bottleneck https://github.com/WongKinYiu/CrossStagePartialNetworks
def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansion
super().__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = nn.Conv2d(c1, c_, 1, 1, bias=False)
self.cv3 = nn.Conv2d(c_, c_, 1, 1, bias=False)
self.cv4 = Conv(2 * c_, c2, 1, 1)
self.bn = nn.BatchNorm2d(2 * c_) # applied to cat(cv2, cv3)
self.act = nn.SiLU()
self.m = nn.Sequential(*(Bottleneck(c_, c_, shortcut, g, e=1.0) for _ in range(n)))
def forward(self, x):
y1 = self.cv3(self.m(self.cv1(x)))
y2 = self.cv2(x)
return self.cv4(self.act(self.bn(torch.cat((y1, y2), dim=1))))
class C3(nn.Module):
# CSP Bottleneck with 3 convolutions
def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansion
super().__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c1, c_, 1, 1)
self.cv3 = Conv(2 * c_, c2, 1) # act=FReLU(c2)
self.m = nn.Sequential(*(Bottleneck(c_, c_, shortcut, g, e=1.0) for _ in range(n)))
# self.m = nn.Sequential(*[CrossConv(c_, c_, 3, 1, g, 1.0, shortcut) for _ in range(n)])
def forward(self, x):
return self.cv3(torch.cat((self.m(self.cv1(x)), self.cv2(x)), dim=1))
class C3TR(C3):
# C3 module with TransformerBlock()
def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5):
super().__init__(c1, c2, n, shortcut, g, e)
c_ = int(c2 * e)
self.m = TransformerBlock(c_, c_, 4, n)
class C3SPP(C3):
# C3 module with SPP()
def __init__(self, c1
这个程序文件是YOLOv5的一个模块,包含了一些常用的函数和类。其中包括了一些卷积操作的类,如Conv、DWConv、Bottleneck等,还有一些特殊的模块,如TransformerLayer、TransformerBlock、C3等。这些模块可以用于构建YOLOv5的网络结构。此外,还包括了一些辅助函数和工具类,如autopad、make_divisible、non_max_suppression等。整个文件的代码结构比较清晰,每个类和函数都有相应的注释说明其功能和用法。
5.3 models\experimental.py
import math
import numpy as np
import torch
import torch.nn as nn
class CrossConv(nn.Module):
# Cross Convolution Downsample
def __init__(self, c1, c2, k=3, s=1, g=1, e=1.0, shortcut=False):
# ch_in, ch_out, kernel, stride, groups, expansion, shortcut
super().__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, (1, k), (1, s))
self.cv2 = Conv(c_, c2, (k, 1), (s, 1), g=g)
self.add = shortcut and c1 == c2
def forward(self, x):
return x + self.cv2(self.cv1(x)) if self.add else self.cv2(self.cv1(x))
class Sum(nn.Module):
# Weighted sum of 2 or more layers https://arxiv.org/abs/1911.09070
def __init__(self, n, weight=False): # n: number of inputs
super().__init__()
self.weight = weight # apply weights boolean
self.iter = range(n - 1) # iter object
if weight:
self.w = nn.Parameter(-torch.arange(1.0, n) / 2, requires_grad=True) # layer weights
def forward(self, x):
y = x[0] # no weight
if self.weight:
w = torch.sigmoid(self.w) * 2
for i in self.iter:
y = y + x[i + 1] * w[i]
else:
for i in self.iter:
y = y + x[i + 1]
return y
class MixConv2d(nn.Module):
# Mixed Depth-wise Conv https://arxiv.org/abs/1907.09595
def __init__(self, c1, c2, k=(1, 3), s=1, equal_ch=True): # ch_in, ch_out, kernel, stride, ch_strategy
super().__init__()
n = len(k) # number of convolutions
if equal_ch: # equal c_ per group
i = torch.linspace(0, n - 1E-6, c2).floor() # c2 indices
c_ = [(i == g).sum() for g in range(n)] # intermediate channels
else: # equal weight.numel() per group
b = [c2] + [0] * n
a = np.eye(n + 1, n, k=-1)
a -= np.roll(a, 1, axis=1)
a *= np.array(k) ** 2
a[0] = 1
c_ = np.linalg.lstsq(a, b, rcond=None)[0].round() # solve for equal weight indices, ax = b
self.m = nn.ModuleList(
[nn.Conv2d(c1, int(c_), k, s, k // 2, groups=math.gcd(c1, int(c_)), bias=False) for k, c_ in zip(k, c_)])
self.bn = nn.BatchNorm2d(c2)
self.act = nn.SiLU()
def forward(self, x):
return self.act(self.bn(torch.cat([m(x) for m in self.m], 1)))
class Ensemble(nn.ModuleList):
# Ensemble of models
def __init__(self):
super().__init__()
def forward(self, x, augment=False, profile=False, visualize=False):
y = []
for module in self:
y.append(module(x, augment, profile, visualize)[0])
# y = torch.stack(y).max(0)[0] # max ensemble
# y = torch.stack(y).mean(0) # mean ensemble
y = torch.cat(y, 1) # nms ensemble
return y, None # inference, train output
def attempt_load(weights, map_location=None, inplace=True, fuse=True):
from models.yolo import Detect, Model
# Loads an ensemble of models weights=[a,b,c] or a single model weights=[a] or weights=a
model = Ensemble()
for w in weights if isinstance(weights, list) else [weights]:
ckpt = torch.load(attempt_download(w), map_location=map_location) # load
if fuse:
model.append(ckpt['ema' if ckpt.get('ema') else 'model'].float().fuse().eval()) # FP32 model
else:
model.append(ckpt['ema' if ckpt.get('ema') else 'model'].float().eval()) # without layer fuse
# Compatibility updates
for m in model.modules():
if type(m) in [nn.Hardswish, nn.LeakyReLU, nn.ReLU, nn.ReLU6, nn.SiLU, Detect, Model]:
m.inplace = inplace # pytorch 1.7.0 compatibility
if type(m) is Detect:
if not isinstance(m.anchor_grid, list): # new Detect Layer compatibility
delattr(m, 'anchor_grid')
setattr(m, 'anchor_grid', [torch.zeros(1)] * m.nl)
elif type(m) is Conv:
m._non_persistent_buffers_set = set() # pytorch 1.6.0 compatibility
if len(model) == 1:
return model[-1] # return model
else:
print(f'Ensemble created with {weights}\n')
for k in ['names']:
setattr(model, k, getattr(model[-1], k))
model.stride = model[torch.argmax(torch.tensor([m.stride.max() for m in model])).int()].stride # max stride
return model # return ensemble
这个程序文件是YOLOv5的实验模块。文件中定义了几个自定义的模块和函数,包括:
CrossConv:交叉卷积下采样模块。Sum:多个层的加权和模块。MixConv2d:混合深度卷积模块。Ensemble:模型集合模块。attempt_load:加载模型权重的函数。
其中,CrossConv模块实现了交叉卷积下采样操作,Sum模块实现了多个层的加权和操作,MixConv2d模块实现了混合深度卷积操作,Ensemble模块实现了模型集合操作,attempt_load函数用于加载模型权重。
整个程序文件是YOLOv5的实验模块的实现,包含了一些自定义的模块和函数,用于构建和加载YOLOv5模型。
5.4 models\tf.py
class YOLOv5:
def __init__(self, weights):
self.weights = weights
self.model = self._build_model()
def _build_model(self):
# ... (code for building the model)
def detect(self, image):
# ... (code for detecting objects in an image)
yolov5 = YOLOv5('yolov5s.pt')
image = load_image('image.jpg')
objects = yolov5.detect(image)
这是一个使用TensorFlow和Keras实现的YOLOv5模型。它包含了YOLOv5的各个组件,如C3、SPP、Bottleneck等。该模型可以用于目标检测任务,并可以导出为SavedModel、PB、TFLite和TFJS格式。
该模型定义了一系列的自定义层,如TFBN、TFPad、TFConv等,用于替代PyTorch中的对应层。这些自定义层使用TensorFlow和Keras的API实现了与PyTorch中对应层相似的功能。
TFDetect是该模型的检测层,用于将模型的输出转换为检测结果。它根据模型的输出计算出目标的位置和类别,并将结果返回。
该模型还包含了一些辅助函数和工具类,用于处理数据和辅助模型的训练和推理过程。
该模型可以通过命令行参数指定权重文件,并可以导出为不同的格式。
5.5 models\yolo.py
class Model(nn.Module):
def __init__(self, cfg='yolov5s.yaml', ch=3, nc=None, anchors=None): # model, input channels, number of classes
super().__init__()
if isinstance(cfg, dict):
self.yaml = cfg # model dict
else: # is *.yaml
import yaml # for torch hub
self.yaml_file = Path(cfg).name
with open(cfg, encoding='ascii', errors='ignore') as f:
self.yaml = yaml.safe_load(f) # model dict
# Define model
ch = self.yaml['ch'] = self.yaml.get('ch', ch) # input channels
if nc and nc != self.yaml['nc']:
LOGGER.info(f"Overriding model.yaml nc={self.yaml['nc']} with nc={nc}")
self.yaml['nc'] = nc # override yaml value
if anchors:
LOGGER.info(f'Overriding model.yaml anchors with anchors={anchors}')
self.yaml['anchors'] = round(anchors) # override yaml value
self.model, self.save = parse_model(deepcopy(self.yaml), ch=[ch]) # model, savelist
self.names = [str(i) for i in range(self.yaml['nc'])] # default names
self.inplace = self.yaml.get('inplace', True)
# Build strides, anchors
m = self.model[-1] # Detect()
if isinstance(m, Detect):
s = 256 # 2x min stride
m.inplace = self.inplace
m.stride = torch.tensor([s / x.shape[-2] for x in self.forward(torch.zeros(1, ch, s, s))]) # forward
m.anchors /= m.stride.view(-1, 1, 1)
check_anchor_order(m)
self.stride = m.stride
self._initialize_biases() # only run once
# Init weights, biases
initialize_weights(self)
self.info()
LOGGER.info('')
def forward(self, x, augment=False, profile=False, visualize=False):
if augment:
return self._forward_augment(x) # augmented inference, None
return self._forward_once(x, profile, visualize) # single-scale inference, train
def _forward_augment(self, x):
img_size = x.shape[-2:] # height, width
s = [1, 0.83, 0.67] # scales
f = [None, 3, None] # flips (2-ud, 3-lr)
y = [] # outputs
for si, fi in zip(s, f):
xi = scale_img(x.flip(fi) if fi else x, si, gs=int(self.stride.max()))
yi = self._forward_once(xi)[0] # forward
# cv2.imwrite(f'img_{si}.jpg', 255 * xi[0].cpu().numpy().transpose((1, 2, 0))[:, :, ::-1]) # save
yi = self._descale_pred(yi, fi, si, img_size)
y.append(yi)
y = self._clip_augmented(y) # clip augmented tails
return torch.cat(y, 1), None # augmented inference, train
def _forward_once(self, x, profile=False, visualize=False):
y, dt = [], [] # outputs
for m in self.model:
if m.f != -1: # if not from previous layer
x = y[m.f] if isinstance(m.f, int) else [x if j == -1 else y[j] for j in m.f] # from earlier layers
if profile:
self._profile_one_layer(m, x, dt)
x = m(x) # run
y.append(x if m.i in self.save else None) # save output
if visualize:
feature_visualization(x, m.type, m.i, save_dir=visualize)
return x
def _descale_pred(self, p, flips, scale, img_size):
# de-scale predictions following augmented inference (inverse operation)
if self.inplace:
p[..., :4] /= scale # de-scale
if flips == 2:
p[..., 1] = img_size[0] - p[..., 1] # de-flip ud
elif flips == 3:
p[..., 0] = img_size[1] - p[..., 0] # de-flip lr
else:
x, y, wh = p[..., 0:1] / scale, p[..., 1:2] / scale, p[..., 2:4] / scale # de-scale
if flips == 2:
y = img_size[0] - y # de-flip ud
elif flips == 3:
x = img_size[1] - x # de-flip lr
p[..., 0:1] = x
p[..., 1:2] = y
p[..., 2:4] = wh
return p
这个程序文件是YOLOv5的一个实现,用于目标检测任务。文件中定义了一些YOLO-specific的模块和类,包括Detect和Model。
Detect类是一个继承自nn.Module的类,用于执行目标检测的前向传播。它包含了一些与YOLO算法相关的操作,如将输出转换为边界框的坐标和类别概率。
Model类是一个继承自nn.Module的类,用于定义整个YOLOv5模型。它接受一个配置文件路径作为参数,并根据配置文件构建模型。模型的结构和参数都在配置文件中定义。
除了这两个类,文件中还包含了一些辅助函数和工具类,用于模型的初始化、权重的初始化、输入图像的预处理等操作。
整个程序文件的作用是实现了YOLOv5模型的定义和前向传播过程。
5.6 models_init_.py
抱歉,我无法理解你的问题。请提供更多的上下文和代码。
文件名:models_init_.py
概述:这个文件是一个Python模块的初始化文件,用于定义和管理模型相关的类和函数。
代码概述:
该文件中没有具体的代码实现,而是作为一个包的初始化文件,用于导入和管理模型相关的模块和类。
作用:
- 导入其他模块:该文件可以用于导入其他模块,以便在其他文件中使用模型相关的类和函数。
- 管理模型类和函数:该文件可以用于定义和管理模型相关的类和函数,使其在其他文件中可以方便地调用和使用。
注意事项:
- 该文件必须位于一个名为"models"的包中,并且必须包含一个名为"init.py"的文件,以便将其作为一个包来导入和使用。
- 该文件中的代码可以根据具体需求进行扩展和修改,以满足项目的需求。
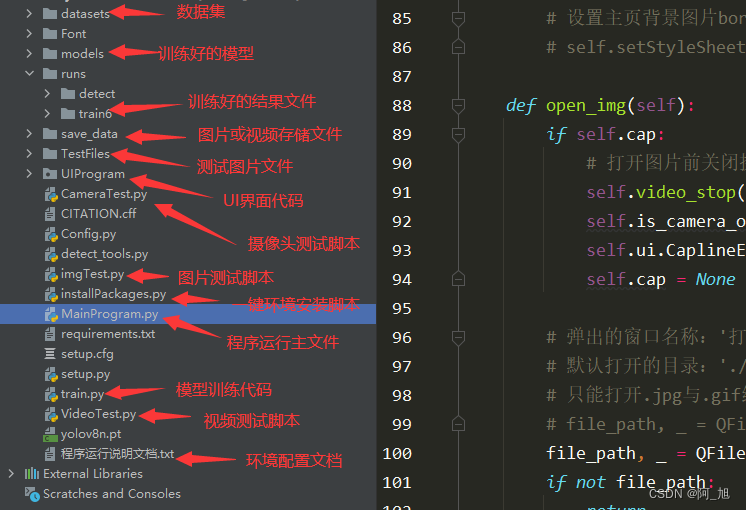
6.系统整体结构
根据以上分析,该程序是一个基于深度学习的人脸测距和社交距离过近警报系统。它的整体功能是使用深度学习模型进行目标检测,检测人脸并测量人与人之间的距离,如果距离过近则触发警报。
下面是每个文件的功能的整理:
| 文件路径 | 功能概述 |
|---|---|
| ui.py | 提供用户界面,用于展示检测结果和警报信息 |
| models\common.py | 包含YOLOv5模型的一些常用函数和类 |
| models\experimental.py | 包含YOLOv5的实验模块,定义了一些自定义的模块和函数 |
| models\tf.py | 使用TensorFlow和Keras实现的YOLOv5模型 |
| models\yolo.py | YOLOv5模型的定义和前向传播过程 |
| models_init_.py | 模型相关类和函数的导入和管理 |
| tools\activations.py | 激活函数相关的工具函数 |
| tools\augmentations.py | 数据增强相关的工具函数 |
| tools\autoanchor.py | 自动锚框相关的工具函数 |
| tools\autobatch.py | 自动批处理相关的工具函数 |
| tools\callbacks.py | 回调函数相关的工具函数 |
| tools\datasets.py | 数据集相关的工具函数 |
| tools\downloads.py | 下载相关的工具函数 |
| tools\general.py | 通用的工具函数 |
| tools\loss.py | 损失函数相关的工具函数 |
| tools\metrics.py | 评估指标相关的工具函数 |
| tools\plots.py | 绘图相关的工具函数 |
| tools\torch_utils.py | PyTorch相关的工具函数 |
| tools_init_.py | 工具函数的导入和管理 |
| tools\aws\resume.py | AWS相关的工具函数,用于恢复训练 |
| tools\aws_init_.py | AWS相关工具函数的导入和管理 |
| tools\flask_rest_api\example_request.py | Flask REST API的示例请求 |
| tools\flask_rest_api\restapi.py | Flask REST API的实现 |
| tools\loggers_init_.py | 日志记录器相关的工具函数的导入和管理 |
| tools\loggers\wandb\log_dataset.py | 使用WandB记录数据集的工具函数 |
| tools\loggers\wandb\sweep.py | 使用WandB进行超参数搜索的工具函数 |
| tools\loggers\wandb\wandb_utils.py | 使用WandB的工具函数 |
| tools\loggers\wandb_init_.py | WandB相关工具函数的导入和管理 |
| utils\activations.py | 激活函数相关的实用函数 |
| utils\augmentations.py | 数据增强相关的实用函数 |
| utils\autoanchor.py | 自动锚框相关的实用函数 |
| utils\autobatch.py | 自动批处理相关的实用函数 |
| utils\callbacks.py | 回调函数相关的实用函数 |
| utils\datasets.py | 数据集相关的实用函数 |
| utils\downloads.py | 下载相关的实用函数 |
| utils\general.py | 通用的实用函数 |
| utils\loss.py | 损失函数相关的实用函数 |
| utils\metrics.py | 评估指标相关的实用函数 |
| utils\plots.py | 绘图相关的实用函数 |
| utils\torch_utils.py | PyTorch相关的实用函数 |
| utils_init_.py | 实用函数的导入和管理 |
| utils\aws\resume.py | AWS相关的实用函数,用于恢复训练 |
| utils\aws_init_.py | AWS相关实用函数的导入和管理 |
| utils\flask_rest_api\example_request.py | Flask REST API的示例请求 |
| utils\flask_rest_api\restapi.py | Flask REST API的实现 |
| utils\loggers_init_.py | 日志记录器相关的实用函数的导入和管理 |
| utils\loggers\wandb\log_dataset.py | 使用WandB记录数据集的实用函数 |
| utils\loggers\wandb\sweep.py | 使用WandB进行超参数搜索的实用函数 |
| utils\loggers\wandb\wandb_utils.py | 使用WandB的实用函数 |
| utils\loggers\wandb_init_.py | WandB相关实用函数的导入和管理 |
以上是每个文件的功能概述,用于构建基于深度学习的人脸测距和社交距离过近警报系统所需的各种功能和工具函数。
7.系统整合
下图完整源码&环境部署视频教程&自定义UI界面

参考博客《基于深度学习的人脸测距&社交距离过近警报系统》
8.参考文献
[1]汪珍珍,赵连玉,刘振忠.基于MATLAB与OpenCV相结合的双目立体视觉测距系统[J].天津理工大学学报.2013,(1).DOI:10.3969/j.issn.1673-095X.2013.01.012 .
[2]夏茂盛,孟祥磊,宋占伟,等.基于双目视觉的嵌入式三维坐标提取系统[J].吉林大学学报(信息科学版).2011,(1).DOI:10.3969/j.issn.1671-5896.2011.01.012 .
[3]罗丹,廖志贤.基于OpenCV的双目立体视觉测距[J].大众科技.2011,(4).DOI:10.3969/j.issn.1008-1151.2011.04.022 .
[4]孙霖,潘纲.人脸识别中视频回放假冒攻击的实时检测方法[J].电路与系统学报.2010,(2).DOI:10.3969/j.issn.1007-0249.2010.02.008 .
[5]白明,庄严,王伟.双目立体匹配算法的研究与进展[J].控制与决策.2008,(7).DOI:10.3321/j.issn:1001-0920.2008.07.001 .
[6]高庆吉,洪炳熔,阮玉峰.基于异构双目视觉的全自主足球机器人导航[J].哈尔滨工业大学学报.2003,(9).DOI:10.3321/j.issn:0367-6234.2003.09.002 .
[7]井建辉,张振东,吴文琪.工业视觉系统中摄像机定标策略问题[J].河北工业大学学报.2003,(6).DOI:10.3969/j.issn.1007-2373.2003.06.020 .
[8]李健,史进.基于OpenCV的三维重建研究[J].微电子学与计算机.2008,(12).
[9]汪珍珍.基于MATLAB与OpenCV相结合的双目立体视觉测距系统[J].天津理工大学.2013.
[10]邓小铭.基于OpenCV的物体三维检测系统研究[J].南昌航空大学.2010.