场景: 前端传来了一个大的字符串 发现请求不通 一番调试发现SpringGateway 默认内存缓冲区262144字节
网上查了很多种常见的解决方案无效之后 直接重写底层
网友的解决方案
方案1(无效)
直接修改缓冲区大小
spring:
codec:
max-in-memory-size: 1048576方案2(无效)
方案3 无效
gateway-2.2.3以上版本修复了该bug,在GatewayAutoConfiguration中加入了配置写入,但只限ReadBodyPredicateFactory类,如自定义类型需要使用方案二。
package org.springframework.cloud.gateway.handler.predicate;
...
public class ReadBodyPredicateFactory
extends AbstractRoutePredicateFactory<ReadBodyPredicateFactory.Config> {
...
private final List<HttpMessageReader<?>> messageReaders;
public ReadBodyPredicateFactory() {
super(Config.class);
this.messageReaders = HandlerStrategies.withDefaults().messageReaders();
}
/**
* GatewayAutoConfiguration初始化配置写入相关配置
*/
public ReadBodyPredicateFactory(List<HttpMessageReader<?>> messageReaders) {
super(Config.class);
this.messageReaders = messageReaders;
}
...
}方案4(无效)
重写ReadBodyPredicateFactory,注入ServerCodecConfigurer,使用ServerCodecConfigurer.getReaders()获取相关配置。
...
/**
* @description: 自定义ReadBodyPredicateFactory,copy之ReadBodyPredicateFactory
* @author: lizz
* @date: 2020/6/8 14:22
*/
@Component
public class GwReadBodyPredicateFactory extends AbstractRoutePredicateFactory<GwReadBodyPredicateFactory.Config> {
/**
* 获取Spring配置,解决最大body问题
*/
@Autowired
ServerCodecConfigurer codecConfigurer;
@Override
@SuppressWarnings("unchecked")
public AsyncPredicate<ServerWebExchange> applyAsync(GwReadBodyPredicateFactory.Config config) {
...
return new AsyncPredicate<ServerWebExchange>() {
@Override
public Publisher<Boolean> apply(ServerWebExchange exchange) {
return ServerWebExchangeUtils.cacheRequestBodyAndRequest(exchange,
(serverHttpRequest) -> ServerRequest
.create(exchange.mutate().request(serverHttpRequest)
.build(), codecConfigurer.getReaders())
.bodyToMono(inClass)
.doOnNext(objectValue -> exchange.getAttributes().put(
CACHE_REQUEST_BODY_OBJECT_KEY, objectValue))
.map(objectValue -> config.getPredicate()
.test(objectValue)));
...
}方案5 有效
直接重写SpringGateway底层处理请求请求的
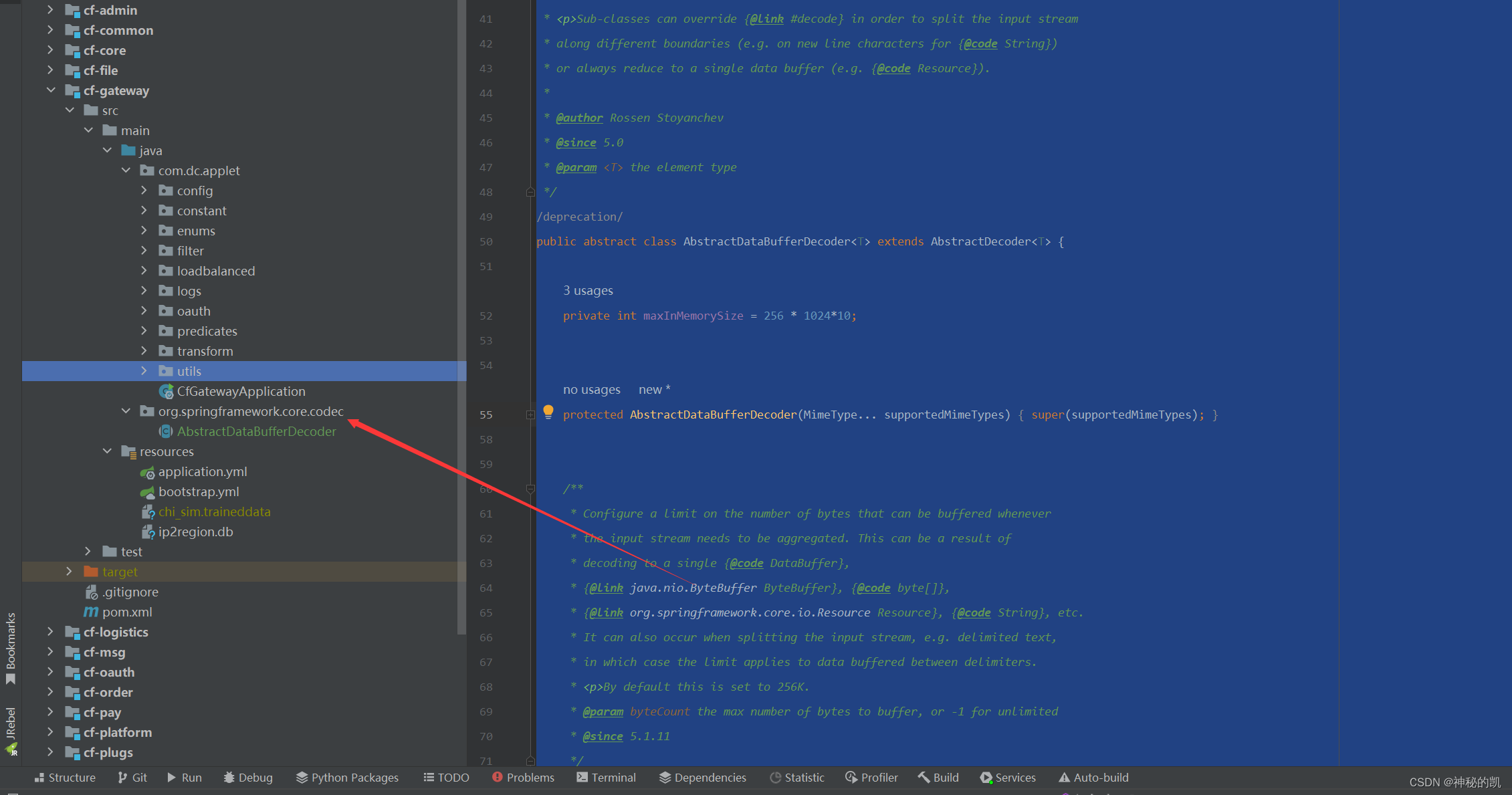
org.springframework.core.codec.AbstractDataBufferDecoder类
/*
* Copyright 2002-2019 the original author or authors.
*
* Licensed under the Apache License, Version 2.0 (the "License");
* you may not use this file except in compliance with the License.
* You may obtain a copy of the License at
*
* https://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package org.springframework.core.codec;
import java.util.Map;
import org.reactivestreams.Publisher;
import reactor.core.publisher.Flux;
import reactor.core.publisher.Mono;
import org.springframework.core.ResolvableType;
import org.springframework.core.io.buffer.DataBuffer;
import org.springframework.core.io.buffer.DataBufferUtils;
import org.springframework.lang.Nullable;
import org.springframework.util.MimeType;
/**
* 重写SpringWebFex底层 为了解决GateWay报错:Exceeded limit on max bytes to buffer : 262144 错误
* Abstract base class for {@code Decoder} implementations that can decode
* a {@code DataBuffer} directly to the target element type.
*
* <p>Sub-classes must implement {@link #decodeDataBuffer} to provide a way to
* transform a {@code DataBuffer} to the target data type. The default
* {@link #decode} implementation transforms each individual data buffer while
* {@link #decodeToMono} applies "reduce" and transforms the aggregated buffer.
*
* <p>Sub-classes can override {@link #decode} in order to split the input stream
* along different boundaries (e.g. on new line characters for {@code String})
* or always reduce to a single data buffer (e.g. {@code Resource}).
*
* @author Rossen Stoyanchev
* @since 5.0
* @param <T> the element type
*/
@SuppressWarnings("deprecation")
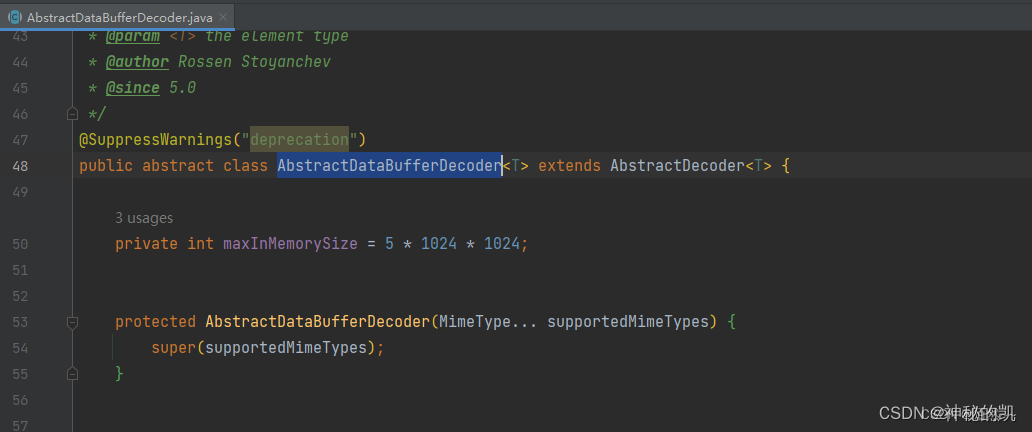
public abstract class AbstractDataBufferDecoder<T> extends AbstractDecoder<T> {
private int maxInMemorySize = 256 * 1024*10;
protected AbstractDataBufferDecoder(MimeType... supportedMimeTypes) {
super(supportedMimeTypes);
}
/**
* Configure a limit on the number of bytes that can be buffered whenever
* the input stream needs to be aggregated. This can be a result of
* decoding to a single {@code DataBuffer},
* {@link java.nio.ByteBuffer ByteBuffer}, {@code byte[]},
* {@link org.springframework.core.io.Resource Resource}, {@code String}, etc.
* It can also occur when splitting the input stream, e.g. delimited text,
* in which case the limit applies to data buffered between delimiters.
* <p>By default this is set to 256K.
* @param byteCount the max number of bytes to buffer, or -1 for unlimited
* @since 5.1.11
*/
public void setMaxInMemorySize(int byteCount) {
this.maxInMemorySize = byteCount;
}
/**
* Return the {@link #setMaxInMemorySize configured} byte count limit.
* @since 5.1.11
*/
public int getMaxInMemorySize() {
return this.maxInMemorySize;
}
@Override
public Flux<T> decode(Publisher<DataBuffer> input, ResolvableType elementType,
@Nullable MimeType mimeType, @Nullable Map<String, Object> hints) {
return Flux.from(input).map(buffer -> decodeDataBuffer(buffer, elementType, mimeType, hints));
}
@Override
public Mono<T> decodeToMono(Publisher<DataBuffer> input, ResolvableType elementType,
@Nullable MimeType mimeType, @Nullable Map<String, Object> hints) {
return DataBufferUtils.join(input, this.maxInMemorySize)
.map(buffer -> decodeDataBuffer(buffer, elementType, mimeType, hints));
}
/**
* How to decode a {@code DataBuffer} to the target element type.
* @deprecated as of 5.2, please implement
* {@link #decode(DataBuffer, ResolvableType, MimeType, Map)} instead
*/
@Deprecated
@Nullable
protected T decodeDataBuffer(DataBuffer buffer, ResolvableType elementType,
@Nullable MimeType mimeType, @Nullable Map<String, Object> hints) {
return decode(buffer, elementType, mimeType, hints);
}
}












![被围绕的区域[中等]](https://img-blog.csdnimg.cn/direct/0b0373b831a64b3480d7d410377f82bf.png)