Py之scikit-surprise:scikit-surprise的简介、安装、使用方法之详细攻略
目录
scikit-surprise的简介
1、基准测试
Movielens 100k
Movielens 1M
scikit-surprise的安装
scikit-surprise的使用方法
1、基础用法
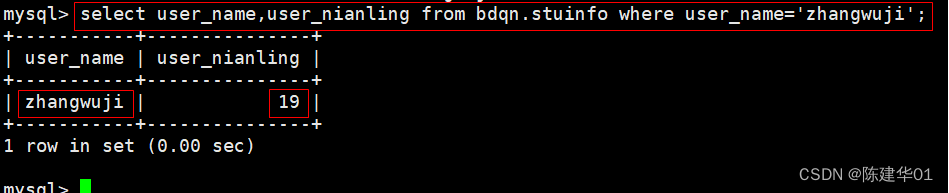
(1)、简单的示例,展示如何(下)载数据集,将其拆分为5折交叉验证,并计算SVD算法的MAE和RMSE
scikit-surprise的简介
Surprise,Simple Python RecommendatIon System Engine,是一个用于构建和分析处理显式评分数据的Python scikit推荐系统工具。Surprise的设计目的包括:
>> 为用户提供对实验的完全控制。为此,我们强调文档,试图通过指出算法的每个细节使其尽可能清晰和精确。
>> 缓解数据集处理的痛苦。用户可以使用内置数据集(Movielens、Jester)和自定义数据集。
>> 提供各种可用的预测算法,如基线算法、邻域方法、基于矩阵分解的算法(SVD、PMF、SVD++、NMF)等。此外,还内置了各种相似度度量(余弦、MSD、皮尔逊等)。
>> 使新算法思路的实现变得简单。
>> 提供评估、分析和比较算法性能的工具。可以使用强大的CV迭代器(受scikit-learn优秀工具启发)轻松运行交叉验证过程,以及对一组参数进行详尽搜索。
请注意,Surprise不支持隐式评分或基于内容的信息。
1、基准测试
以下是各种算法(使用默认参数)在5折交叉验证过程中的平均RMSE、MAE和总执行时间。数据集包括Movielens 100k和1M数据集,所有算法使用相同的折叠。所有实验在一台搭载Intel i5第11代2.60GHz处理器的笔记本电脑上运行。生成这些表格的代码可以在基准测试示例中找到。
Movielens 100k
| Movielens 100k | RMSE | MAE | Time |
|---|---|---|---|
| SVD | 0.934 | 0.737 | 0:00:06 |
| SVD++ (cache_ratings=False) | 0.919 | 0.721 | 0:01:39 |
| SVD++ (cache_ratings=True) | 0.919 | 0.721 | 0:01:22 |
| NMF | 0.963 | 0.758 | 0:00:06 |
| Slope One | 0.946 | 0.743 | 0:00:09 |
| k-NN | 0.98 | 0.774 | 0:00:08 |
| Centered k-NN | 0.951 | 0.749 | 0:00:09 |
| k-NN Baseline | 0.931 | 0.733 | 0:00:13 |
| Co-Clustering | 0.963 | 0.753 | 0:00:06 |
| Baseline | 0.944 | 0.748 | 0:00:02 |
| Random | 1.518 | 1.219 | 0:00:01 |
Movielens 1M
| Movielens 1M | RMSE | MAE | Time |
|---|---|---|---|
| SVD | 0.873 | 0.686 | 0:01:07 |
| SVD++ (cache_ratings=False) | 0.862 | 0.672 | 0:41:06 |
| SVD++ (cache_ratings=True) | 0.862 | 0.672 | 0:34:55 |
| NMF | 0.916 | 0.723 | 0:01:39 |
| Slope One | 0.907 | 0.715 | 0:02:31 |
| k-NN | 0.923 | 0.727 | 0:05:27 |
| Centered k-NN | 0.929 | 0.738 | 0:05:43 |
| k-NN Baseline | 0.895 | 0.706 | 0:05:55 |
| Co-Clustering | 0.915 | 0.717 | 0:00:31 |
| Baseline | 0.909 | 0.719 | 0:00:19 |
| Random | 1.504 | 1.206 | 0:00:19 |
scikit-surprise的安装
pip install numpy
pip install scikit-surprise
pip install -i https://mirrors.aliyun.com/pypi/simple scikit-surprise
或者利用conda
conda install -c conda-forge scikit-surprise
或者从最新的源代码构建
pip install numpy cython
git clone https://github.com/NicolasHug/surprise.git
cd surprise
python setup.py install
scikit-surprise的使用方法
1、基础用法
(1)、简单的示例,展示如何(下)载数据集,将其拆分为5折交叉验证,并计算SVD算法的MAE和RMSE
from surprise import SVD
from surprise import Dataset
from surprise.model_selection import cross_validate
# Load the movielens-100k dataset (download it if needed).
data = Dataset.load_builtin('ml-100k')
# Use the famous SVD algorithm.
algo = SVD()
# Run 5-fold cross-validation and print results.
cross_validate(algo, data, measures=['RMSE', 'MAE'], cv=5, verbose=True)
Evaluating RMSE, MAE of algorithm SVD on 5 split(s).
Fold 1 Fold 2 Fold 3 Fold 4 Fold 5 Mean Std
RMSE (testset) 0.9367 0.9355 0.9378 0.9377 0.9300 0.9355 0.0029
MAE (testset) 0.7387 0.7371 0.7393 0.7397 0.7325 0.7375 0.0026
Fit time 0.62 0.63 0.63 0.65 0.63 0.63 0.01
Test time 0.11 0.11 0.14 0.14 0.14 0.13 0.02 


![被围绕的区域[中等]](https://img-blog.csdnimg.cn/direct/0b0373b831a64b3480d7d410377f82bf.png)
![输入一组数据,以-1结束输入[c]](https://img-blog.csdnimg.cn/direct/f5d8d179cbc940d7b4d08db682813c0e.png)