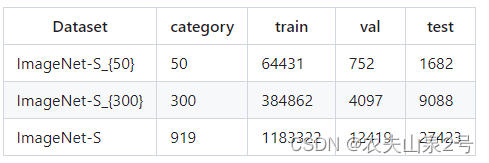
DOTA数据集
DOTA数据集包含2806张航空图像,尺寸大约从800x800到4000x4000不等,包含15个类别共计188282个实例。其标注方式为四点确定的任意形状和方向的四边形(区别于传统的对边平行bbox)。类别分别为:plane, ship, storage tank, baseball dia- mond, tennis court, swimming pool, ground track field, har- bor, bridge, large vehicle, small vehicle, helicopter, round- about, soccer ball field , basketball court。
提取感兴趣类别数据
我们需求可能只感兴趣某一个或几个类别,这时候我们需要剔除掉不包含我们感兴趣类别的数据。下面,以船只ship为例,为大家介绍提取感兴趣类别数据的代码:
import os
from shutil import copyfile
def filterTxt(srcTxtPah, dstTxtPath, selected_class):
selected_class_num = 0
# r:读取文件,若文件不存在则会报错
with open(srcTxtPah, "r") as rf:
for line in rf.readlines():
if(selected_class in line):
selected_class_num += 1
# a:写入文件,若文件不存在则会先创建再写入,但不会覆盖原文件,而是追加在文件末尾
with open(dstTxtPath,"a") as af:
af.write(line) # 自带文件关闭功能,不需要再写f.close()
rf.close()
return selected_class_num
# DOTA数据的txt文件夹
txtFolder = r"I:\Remote_Sensing_Data\DOTA_Dataset\train\labelTxt-v1.0\labelTxt"
# DOTA数据的image文件夹
imgFolder = r"I:\Remote_Sensing_Data\DOTA_Dataset\train\images\images"
# 要复制到的image文件夹
copy_imageFolder = r"I:\ship_detect\Data\DOTA_ship\train\images"
# 要复制到的txt文件夹
copy_txtFolder = r"I:\ship_detect\Data\DOTA_ship\train\labelTxt-v1.0"
# 感兴趣类别
selected_class = "ship"
txtNameList = os.listdir(txtFolder)
for i in range(len(txtNameList)):
# 判断当前文件是否为txt文件
if(os.path.splitext(txtNameList[i])[1] == ".txt"):
txt_path = txtFolder + "\\" + txtNameList[i]
# 设置文件对象
f = open(txt_path, "r")
# 读取一行文件,包括换行符
line = f.readline()
while line:
# 若该类是selected_class,则将对应图像复制粘贴,并停止循环
if(selected_class in line):
# 获取txt的索引,不带扩展名的文件名
txt_index = os.path.splitext(txtNameList[i])[0]
# 获取对应图像文件的地址
src = imgFolder + "\\" + txt_index + ".png"
dst = copy_imageFolder + "\\" + txt_index + ".png"
# 复制图像文件至指定位置
copyfile(src, dst)
# 筛选txt文件中的selected_class信息并写至指定位置
selected_class_num = filterTxt(txt_path, copy_txtFolder + "\\" + txt_index + ".txt", selected_class)
print(txt_index,".png have", selected_class_num, selected_class)
break
# 若第一行不是selected_class,继续向下读,直到读取完文件
else:
line = f.readline()
f.close() #关闭文件输出:
P0001 .png have 17 ship
P0011 .png have 1 ship
P0020 .png have 1 ship
P0129 .png have 138 ship
......
P2769 .png have 15 ship
P2770 .png have 33 ship
P2792 .png have 601 ship这样就实现了将含有船只的数据集单独挑选出来了。
可视化边界框
我们将船只数据集单独挑选出来后,可以可视化一下边界框。DOTA提供的是OBB有向边界框,我们也可以转换成HBB水平边界框。
from PIL import Image, ImageDraw
imgPath = r"I:\ship_detect\Data\DOTA_ship\train\images\P0340.png"
txtPath = r"I:\ship_detect\Data\DOTA_ship\train\labelTxt-v1.0\P0340.txt"
savePath = "obb.jpg"
drawType = "obb"
img =Image.open(imgPath)
draw =ImageDraw.Draw(img)
with open(txtPath, "r") as f:
for line in f.readlines():
# 去掉列表中每一个元素的换行符
line = line.strip('\n')
line = line.split(" ")
#print(line)
if(drawType == "obb"):
# 绘制OBB有向边界框
polygon = []
for i in range(8):
polygon.append(int(line[i]))
polygon = tuple(polygon)
draw.polygon(polygon, outline = 'red')
elif(drawType == "hbb"):
# 绘制HBB水平边界框
xmin = min(int(line[0]), int(line[2]), int(line[4]), int(line[6]))
xmax = max(int(line[0]), int(line[2]), int(line[4]), int(line[6]))
ymin = min(int(line[1]), int(line[3]), int(line[5]), int(line[7]))
ymax = max(int(line[1]), int(line[3]), int(line[5]), int(line[7]))
draw.rectangle(
[xmin, ymin, xmax, ymax],
outline = 'red')
img.save(savePath, quality = 95)
OBB

HBB
来源:应用推广部
供稿:技术研发部
编辑:方梅