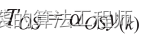背景
强化学习
- 背景
- 方向
- 马尔可夫决策过程
- 动态规划
方向
从数据中学习,或者从演示中学习包含丰富的门类,例如以模仿学习为代表的来自专家的数据中学习策略、以强化逆学习,代表来自数据中学习奖励函数以及来自人类反馈中学习,为代表的来自人类色素的数据中学习奖励模型来进行调节。此外,还包括离线强化学习、世界模型,等等这些方法都利用了数据来辅助强化学习,因此本书将它们归为一类从数据中学习的方法。注意,这些方法的思路实际上是大相径庭的,完全可以作为一个单独的子方向来研究。
修改学习是指在奖励函数中难以明确定义或者策略本身就很难学出来的情况下,我们可以通过修改人类的行为来学习到一个更好的策略。最典型的修改策略就是行为克隆,即将每个状态动作视为一个训练样本,并使用监督学习的方法(如神经网络)来学习一个策略。但这种方法很容易分散分布的影响。智能体可能会遇到从未见过的状态,导致错误策略。
逆强化学习是指通过观察人类的行为来学习到一个奖励函数,然后通过强化学习来学习一个策略。由于需要专家数据,逆强化学习会受到噪声的影响,因此如何从噪声数据中学习到一个较好的奖励函数也是一个难题。
马尔可夫决策过程
马尔可夫决策过程是强化学习的基本问题模型,它能够以数学的形式来描述智能体在与交互环境的过程中学习一个目标的过程。这里智能体扮演的是做出决策或动作,并且在交互过程中学习的角色中,环境是指智能体交互中事物外部的一切,不包括智能体本身。
把马尔可夫决策过程描述成一个今天常用的写法,即用一个五元组
S
,
A
,
R
,
P
,
θ
{S,A,R,P,\theta }
S,A,R,P,θ 来表示。其中,S表示状态空间,即所有状态的集合,A表示动作空间,R表示奖励函数,P表示状态分布矩阵,
θ
{\theta}
θ表示重要性。
动态规划
动态规划其实不是强化学习领域中强调的算法,它在数学、管理科学、经济学和生物信息学等领域都有广泛的应用。动态规划具体指在某些复杂问题中,将问题转化为几个子问题,并在活化每个子问题的过程中保存已经活化的结果,以便后续使用。实际上动态规划原来是一种通用的思路,是具体的某种算法。在强化中学习中,动态规划被用于激励值函数和优化策略。常见的动态规划算法包括值迭代、迭代策略和Q-Learning算法等。
以寻找路径的经典问题为例,动态规划的核心就是在维护如下的状态转移矩阵: