目录
- pod
- 介绍
- Pod的概念:
- Pod的特性:
- Pod的配置:
- Pod的控制:
- 示例 YAML 文件:
- pod启动流程
- 问题
- 两种方式启动
- 镜像的升级和回滚
- 更新 Deployment:
- 回滚
- 检查 Deployment 历史版本
- 回滚到之前的修订版本
- 缩放 Deployment
- 比例缩放
- 暂停、恢复 Deployment 的上线过程
- Deployment 状态
- 进行中的 Deployment
- 完成的 Deployment
- 失败的 Deployment
- 对失败 Deployment 的操作
- 清理策略
- 金丝雀部署
- 编写 Deployment 规约
- 设置资源限制
- HAP
- 增加负载
- 停止产生负载
- init容器
- 1. 用途和优势:
- 2. 特点和工作方式:
- 3. 使用示例:
- 4. 生命周期和状态:
- 5. 多个 Init 容器:
- 6. 注意事项:
- pause容器
- 1. 作用和目的:
- 2. 镜像和进程:
- 3. 生命周期和状态:
- 4. 网络隔离:
- 5. 进程隔离:
- 6. 使用示例:
- 7. 其他示例
- 8. 其他容器启动依赖:
- pod安全策略
- 获取 Pod 安全策略列表
- 修改 Pod 安全策略
- 删除 Pod 安全策略
- pod生命周期
- pod状态
- pod hook
- pod preset(1.11-19 可用 1.20取消了此功能)
- pod优先级和抢占
- 创建优先级和抢占
- PriorityClass
- PriorityClass示例
- 非抢占式 PriorityClass(1.24)
- 非抢占式 PriorityClass 示例
- pod优先级
- Pod 优先级对调度顺序的影响
- 抢占
- 用户暴露的信息
- 抢占的限制
- 被抢占牺牲者的体面终止
- 支持 PodDisruptionBudget,但不保证
- 与低优先级 Pod 之间的 Pod 间亲和性
- 跨节点抢占
- 故障排除
- Pod 被不必要地抢占
- 有 Pod 被抢占,但抢占者并没有被调度
- 优先级较高的 Pod 在优先级较低的 Pod 之前被抢占
- Pod 优先级和服务质量之间的相互作用
- Node
- Node 的状态
- Node 管理
- 问题
- 删除了node怎么重新加入
- 如何回滚k8s升级的问题?降级k8s
pod
介绍
Kubernetes(通常被缩写为K8s)是一个用于自动部署、扩展和管理容器化应用程序的开源容器编排平台。Pod是Kubernetes中最小的可部署和可管理的计算单元。以下是关于Kubernetes中的Pod的详细解释:
Pod的概念:
- Pod的定义: Pod是Kubernetes中的最小调度单元,它可以包含一个或多个紧密耦合的容器。这些容器共享相同的网络命名空间、IP地址和端口空间。
- 容器的组合: Pod中的容器通常协同工作,它们可以共享存储卷(Volumes)、环境变量等资源。这使得它们能够更容易地共享数据和通信。
- 生命周期: Pod是一个短暂的资源,其生命周期由包含的容器决定。当Pod内的所有容器都终止时,Pod也会终止。
Pod的特性:
- 共享网络命名空间: Pod中的所有容器共享相同的网络命名空间,它们可以通过localhost相互通信,使用相同的IP地址和端口。
- 共享存储卷: Pod中的容器可以通过存储卷共享数据。这允许它们之间共享文件系统状态。
- 共享进程空间: Pod中的容器可以共享相同的进程空间,这意味着它们可以通过进程间通信进行交互。
Pod的配置:
- Pod规约: Pod的规约定义了一个或多个容器的运行规范,包括容器的镜像、环境变量、资源限制等。
- 标签(Labels): Pod可以被附上标签,这些标签可以用于选择和过滤Pod,从而进行操作和管理。
Pod的控制:
- 控制器(Controllers): 控制器是用来确保Pod按照用户定义的规约运行的组件。常见的控制器有Deployment、StatefulSet等。
- 调度器(Scheduler): 调度器负责将Pod调度到集群中的节点上,并确保它们按照规约运行。
示例 YAML 文件:
以下是一个简单的Pod的YAML示例:
apiVersion: v1
kind: Pod
metadata:
name: mypod
spec:
containers:
- name: mycontainer
image: nginx:latest
这个示例定义了一个Pod,其中包含一个名为mycontainer的容器,该容器使用Nginx的最新镜像。
总的来说,Pod是Kubernetes中非常重要的概念,它为容器提供了一个逻辑主机,使得容器可以共享资源并协同工作。 Pod的设计使得在Kubernetes中部署和管理应用程序变得更加灵活和强大。
pod启动流程

问题
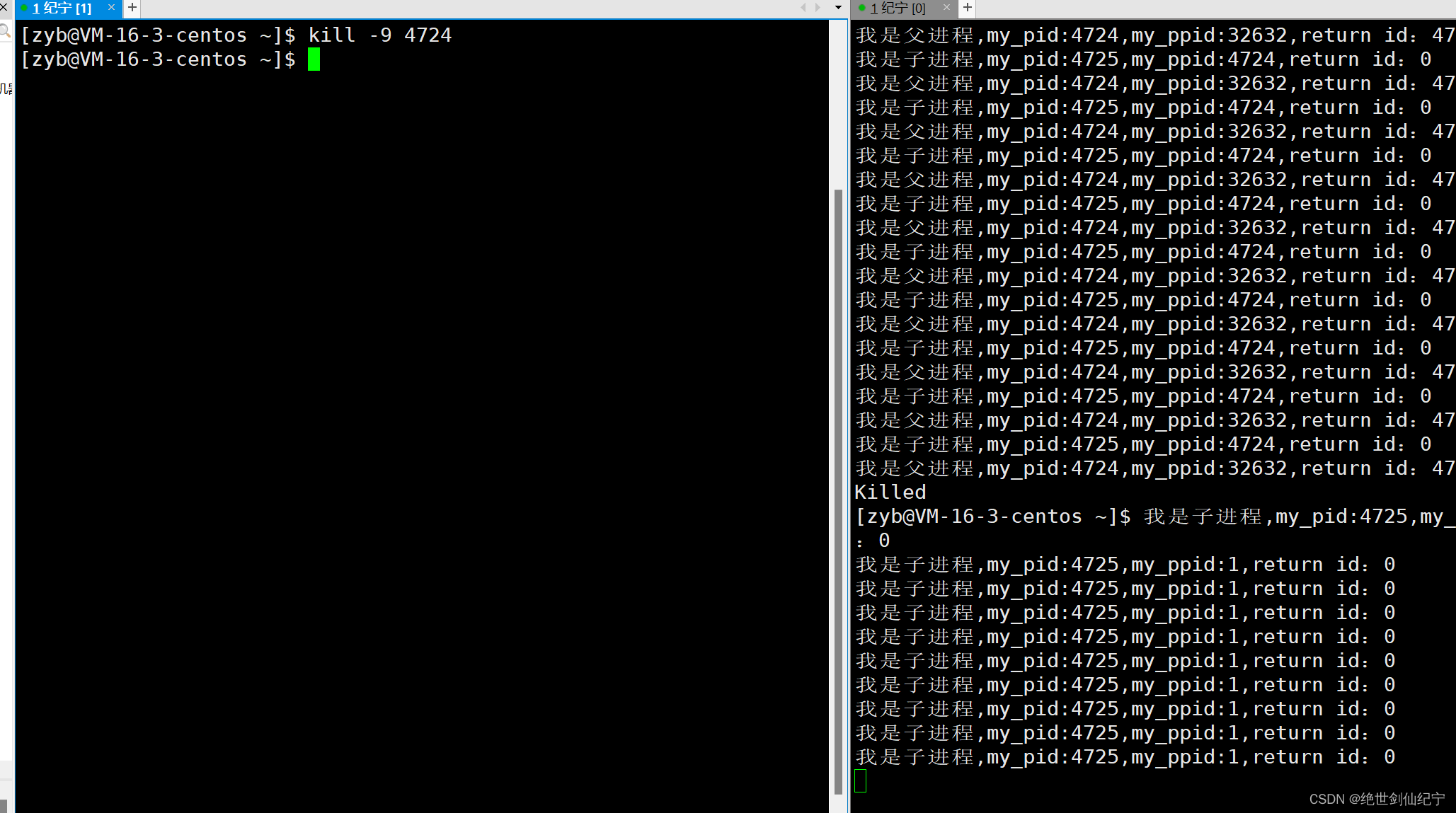
1.kubelet是定期主动访问api server知道有哪些pod需要启动,还是scheduler主动去通知kubelet去访问api server的?
192.168.2.210
[root@k8smaster1 ~]# netstat -anplut|grep kubelet
tcp 0 0 127.0.0.1:10248 0.0.0.0:* LISTEN 17335/kubelet
tcp 0 0 127.0.0.1:34513 0.0.0.0:* LISTEN 17335/kubelet
tcp 0 0 192.168.2.210:43032 192.168.2.210:6443 ESTABLISHED 17335/kubelet
tcp6 0 0 :::10250 :::* LISTEN 17335/kubelet
192.168.2.211
[root@k8snode1 ~]# netstat -anplut|grep kubelet
tcp 0 0 127.0.0.1:10248 0.0.0.0:* LISTEN 25050/kubelet
tcp 0 0 127.0.0.1:44939 0.0.0.0:* LISTEN 25050/kubelet
tcp 0 0 192.168.2.211:49362 192.168.2.210:6443 ESTABLISHED 25050/kubelet
tcp6 0 0 :::10250 :::* LISTEN 25050/kubelet
192.168.2.212
[root@k8snode2 ~]# netstat -anpult|grep kubelet
tcp 0 0 127.0.0.1:34325 0.0.0.0:* LISTEN 4194/kubelet
tcp 0 0 127.0.0.1:10248 0.0.0.0:* LISTEN 4194/kubelet
tcp 0 0 192.168.2.212:58678 192.168.2.210:6443 ESTABLISHED 4194/kubelet
tcp6 0 0 :::10250 :::* LISTEN 4194/kubelet
2.etcd数据发生了变化,哪些控制器是如何知道的?是其他程序通知的还是,定时去检查的?
在Kubernetes中,
etcd是一个分布式的键值存储系统,被用作集群中所有组件共享配置信息和状态的后端存储。当etcd中的数据发生变化时,Kubernetes 中的控制器是通过轮询(polling)机制来感知这些变化的,而不是通过事件通知。以下是控制器如何知道
etcd数据变化的一般流程:
- 轮询机制: Kubernetes中的控制器通过轮询的方式定期查询
etcd,检查与它们关联的对象(例如Pod、Service、ReplicaSet等)的状态是否发生变化。这是一种主动的方式,控制器定期查询etcd数据库,看是否有更新。- Watch机制: Kubernetes也使用了一种叫做Watch的机制,它允许组件注册在
etcd上某个特定资源路径上的事件。当etcd中的数据发生变化时,相关的Watch事件将被触发,然后组件可以收到这些事件并作出相应的处理。虽然Watch机制用于实现事件驱动,但目前(截至我知识截断日期2022年),Kubernetes控制器主要仍然以轮询为主。- Informers: Kubernetes客户端库中提供了Informers的概念,这是一种缓存和事件处理的机制。Informers会定期从
etcd中获取资源的最新状态,并将其缓存在本地。当本地缓存中的对象状态发生变化时,它可以触发相应的事件,这样控制器可以监听这些事件来感知状态的变化。总的来说,Kubernetes控制器通过定期查询
etcd数据库,使用Watch机制或者Informers等机制,以轮询方式感知etcd中数据的变化。尽管有一些机制支持事件驱动,但当前实现主要还是基于轮询。未来的Kubernetes版本可能引入更多的事件驱动机制以提高效率。
两种方式启动
在 Kubernetes(通常简称为 K8s)中,有两种主要的方式来启动 Pod:使用 Deployment 和使用 Pod 直接。
-
使用 Deployment 启动 Pod(部署控制器启动):
Deployments 是 Kubernetes 中的一种资源类型,用于管理 Pod 的部署和更新。Deployment 提供了很多高级功能,如滚动升级、自动恢复、回滚等。
步骤:
- 创建一个 Deployment 定义文件(通常是 YAML 格式),其中包含 Pod 模板、副本数和其他配置。
- 使用
kubectl apply -f <deployment.yaml>命令将 Deployment 定义应用到集群。 - Kubernetes 控制平面会创建一个或多个 Pod 副本,以满足 Deployment 定义中指定的副本数目。
- 如果需要更新 Pod,只需更新 Deployment 定义文件,然后使用
kubectl apply -f <updated-deployment.yaml>进行更新。Kubernetes 会自动执行滚动升级,逐步替换旧的 Pod 副本为新的。
-
使用 Pod 直接启动 Pod(标准启动):
这种方式相对较少使用,因为它没有 Deployment 那样的自动化管理功能,但在某些情况下仍然有用,比如需要直接控制 Pod 的生命周期。
步骤:
- 创建一个 Pod 定义文件,其中包含容器镜像、环境变量、卷挂载等配置。
- 使用
kubectl apply -f <pod.yaml>命令将 Pod 定义应用到集群。 - Kubernetes 控制平面会直接创建一个 Pod,该 Pod 不会受到 Deployment 控制和管理,需要手动管理升级、回滚等操作。
- 如果需要更新 Pod,必须手动修改 Pod 定义文件,然后使用
kubectl apply -f <updated-pod.yaml>进行更新。
需要注意的是,大多数情况下推荐使用 Deployment 来管理 Pod,因为它提供了更高级的管理功能,如自动扩展、滚动升级和回滚,以及更好的容错性。只有在特定需求下,或者为了特定的控制,才会考虑直接使用 Pod。
镜像的升级和回滚
要查看 Deployment 创建的 ReplicaSet(rs),运行 kubectl get rs。 输出类似于:
NAME DESIRED CURRENT READY AGE
nginx-deployment-75675f5897 3 3 3 18s
更新 Deployment:
-
先来更新 nginx Pod 以使用
nginx:1.16.1镜像,而不是nginx:1.14.2镜像。kubectl set image deployment.v1.apps/nginx-deployment nginx=nginx:1.16.1或者使用下面的命令:
kubectl set image deployment/nginx-deployment nginx=nginx:1.16.1在这里,
deployment/nginx-deployment表明 Deployment 的名称,nginx表明需要进行更新的容器, 而nginx:1.16.1则表示镜像的新版本以及它的标签。输出类似于:
deployment.apps/nginx-deployment image updated或者,可以对 Deployment 执行
edit操作并将.spec.template.spec.containers[0].image从nginx:1.14.2更改至nginx:1.16.1。kubectl edit deployment/nginx-deployment输出类似于:
deployment.apps/nginx-deployment edited -
要查看上线状态,运行:
kubectl rollout status deployment/nginx-deployment输出类似于:
Waiting for rollout to finish: 2 out of 3 new replicas have been updated...或者
deployment "nginx-deployment" successfully rolled out
获取关于已更新的 Deployment 的更多信息:
-
在上线成功后,可以通过运行
kubectl get deployments来查看 Deployment: 输出类似于:NAME READY UP-TO-DATE AVAILABLE AGE nginx-deployment 3/3 3 3 36s -
运行
kubectl get rs以查看 Deployment 通过创建新的 ReplicaSet 并将其扩容到 3 个副本并将旧 ReplicaSet 缩容到 0 个副本完成了 Pod 的更新操作:kubectl get rs输出类似于:
NAME DESIRED CURRENT READY AGE nginx-deployment-1564180365 3 3 3 6s nginx-deployment-2035384211 0 0 0 36s -
现在运行
get pods应仅显示新的 Pod:kubectl get pods输出类似于:
NAME READY STATUS RESTARTS AGE nginx-deployment-1564180365-khku8 1/1 Running 0 14s nginx-deployment-1564180365-nacti 1/1 Running 0 14s nginx-deployment-1564180365-z9gth 1/1 Running 0 14s -
获取 Deployment 的更多信息
kubectl describe deployments
回滚
说明:
Deployment 被触发上线时,系统就会创建 Deployment 的新的修订版本。 这意味着仅当 Deployment 的 Pod 模板(.spec.template)发生更改时,才会创建新修订版本 – 例如,模板的标签或容器镜像发生变化。 其他更新,如 Deployment 的扩缩容操作不会创建 Deployment 修订版本。 这是为了方便同时执行手动缩放或自动缩放。 换言之,当你回滚到较早的修订版本时,只有 Deployment 的 Pod 模板部分会被回滚。
-
假设你在更新 Deployment 时犯了一个拼写错误,将镜像名称命名设置为
nginx:1.161而不是nginx:1.16.1:kubectl set image deployment/nginx-deployment nginx=nginx:1.161输出类似于:
deployment.apps/nginx-deployment image updated -
此上线进程会出现停滞。你可以通过检查上线状态来验证:
kubectl rollout status deployment/nginx-deployment输出类似于:
Waiting for rollout to finish: 1 out of 3 new replicas have been updated... -
按 Ctrl-C 停止上述上线状态观测。有关上线停滞的详细信息,参考这里。
-
你可以看到旧的副本有两个(
nginx-deployment-1564180365和nginx-deployment-2035384211), 新的副本有 1 个(nginx-deployment-3066724191):kubectl get rs输出类似于:
NAME DESIRED CURRENT READY AGE nginx-deployment-1564180365 3 3 3 25s nginx-deployment-2035384211 0 0 0 36s nginx-deployment-3066724191 1 1 0 6s -
查看所创建的 Pod,你会注意到新 ReplicaSet 所创建的 1 个 Pod 卡顿在镜像拉取循环中。
kubectl get pods输出类似于:
NAME READY STATUS RESTARTS AGE nginx-deployment-1564180365-70iae 1/1 Running 0 25s nginx-deployment-1564180365-jbqqo 1/1 Running 0 25s nginx-deployment-1564180365-hysrc 1/1 Running 0 25s nginx-deployment-3066724191-08mng 0/1 ImagePullBackOff 0 6s说明:
Deployment 控制器自动停止有问题的上线过程,并停止对新的 ReplicaSet 扩容。 这行为取决于所指定的 rollingUpdate 参数(具体为
maxUnavailable)。 默认情况下,Kubernetes 将此值设置为 25%。 -
获取 Deployment 描述信息:
kubectl describe deployment输出类似于:
Name: nginx-deployment Namespace: default CreationTimestamp: Tue, 15 Mar 2016 14:48:04 -0700 Labels: app=nginx Selector: app=nginx Replicas: 3 desired | 1 updated | 4 total | 3 available | 1 unavailable StrategyType: RollingUpdate MinReadySeconds: 0 RollingUpdateStrategy: 25% max unavailable, 25% max surge Pod Template: Labels: app=nginx Containers: nginx: Image: nginx:1.161 Port: 80/TCP Host Port: 0/TCP Environment: <none> Mounts: <none> Volumes: <none> Conditions: Type Status Reason ---- ------ ------ Available True MinimumReplicasAvailable Progressing True ReplicaSetUpdated OldReplicaSets: nginx-deployment-1564180365 (3/3 replicas created) NewReplicaSet: nginx-deployment-3066724191 (1/1 replicas created) Events: FirstSeen LastSeen Count From SubObjectPath Type Reason Message --------- -------- ----- ---- ------------- -------- ------ ------- 1m 1m 1 {deployment-controller } Normal ScalingReplicaSet Scaled up replica set nginx-deployment-2035384211 to 3 22s 22s 1 {deployment-controller } Normal ScalingReplicaSet Scaled up replica set nginx-deployment-1564180365 to 1 22s 22s 1 {deployment-controller } Normal ScalingReplicaSet Scaled down replica set nginx-deployment-2035384211 to 2 22s 22s 1 {deployment-controller } Normal ScalingReplicaSet Scaled up replica set nginx-deployment-1564180365 to 2 21s 21s 1 {deployment-controller } Normal ScalingReplicaSet Scaled down replica set nginx-deployment-2035384211 to 1 21s 21s 1 {deployment-controller } Normal ScalingReplicaSet Scaled up replica set nginx-deployment-1564180365 to 3 13s 13s 1 {deployment-controller } Normal ScalingReplicaSet Scaled down replica set nginx-deployment-2035384211 to 0 13s 13s 1 {deployment-controller } Normal ScalingReplicaSet Scaled up replica set nginx-deployment-3066724191 to 1要解决此问题,需要回滚到以前稳定的 Deployment 版本。
检查 Deployment 历史版本
按照如下步骤检查回滚历史:
-
首先,检查 Deployment 修订历史:
kubectl rollout history deployment/nginx-deployment输出类似于:
deployments "nginx-deployment" REVISION CHANGE-CAUSE 1 kubectl apply --filename=https://k8s.io/examples/controllers/nginx-deployment.yaml 2 kubectl set image deployment/nginx-deployment nginx=nginx:1.16.1 3 kubectl set image deployment/nginx-deployment nginx=nginx:1.161CHANGE-CAUSE的内容是从 Deployment 的kubernetes.io/change-cause注解复制过来的。 复制动作发生在修订版本创建时。你可以通过以下方式设置CHANGE-CAUSE消息:- 使用
kubectl annotate deployment/nginx-deployment kubernetes.io/change-cause="image updated to 1.16.1"为 Deployment 添加注解。 - 手动编辑资源的清单。
- 使用
-
要查看修订历史的详细信息,运行:
kubectl rollout history deployment/nginx-deployment --revision=2输出类似于:
deployments "nginx-deployment" revision 2 Labels: app=nginx pod-template-hash=1159050644 Annotations: kubernetes.io/change-cause=kubectl set image deployment/nginx-deployment nginx=nginx:1.16.1 Containers: nginx: Image: nginx:1.16.1 Port: 80/TCP QoS Tier: cpu: BestEffort memory: BestEffort Environment Variables: <none> No volumes.
回滚到之前的修订版本
按照下面给出的步骤将 Deployment 从当前版本回滚到以前的版本(即版本 2)。
-
假定现在你已决定撤消当前上线并回滚到以前的修订版本:
kubectl rollout undo deployment/nginx-deployment输出类似于:
deployment.apps/nginx-deployment rolled back或者,你也可以通过使用
--to-revision来回滚到特定修订版本:kubectl rollout undo deployment/nginx-deployment --to-revision=2输出类似于:
deployment.apps/nginx-deployment rolled back与回滚相关的指令的更详细信息,请参考
kubectl rollout。现在,Deployment 正在回滚到以前的稳定版本。正如你所看到的,Deployment 控制器生成了回滚到修订版本 2 的
DeploymentRollback事件。 -
检查回滚是否成功以及 Deployment 是否正在运行,运行:
kubectl get deployment nginx-deployment输出类似于:
NAME READY UP-TO-DATE AVAILABLE AGE nginx-deployment 3/3 3 3 30m -
获取 Deployment 描述信息:
kubectl describe deployment nginx-deployment输出类似于:
Name: nginx-deployment Namespace: default CreationTimestamp: Sun, 02 Sep 2018 18:17:55 -0500 Labels: app=nginx Annotations: deployment.kubernetes.io/revision=4 kubernetes.io/change-cause=kubectl set image deployment/nginx-deployment nginx=nginx:1.16.1 Selector: app=nginx Replicas: 3 desired | 3 updated | 3 total | 3 available | 0 unavailable StrategyType: RollingUpdate MinReadySeconds: 0 RollingUpdateStrategy: 25% max unavailable, 25% max surge Pod Template: Labels: app=nginx Containers: nginx: Image: nginx:1.16.1 Port: 80/TCP Host Port: 0/TCP Environment: <none> Mounts: <none> Volumes: <none> Conditions: Type Status Reason ---- ------ ------ Available True MinimumReplicasAvailable Progressing True NewReplicaSetAvailable OldReplicaSets: <none> NewReplicaSet: nginx-deployment-c4747d96c (3/3 replicas created) Events: Type Reason Age From Message ---- ------ ---- ---- ------- Normal ScalingReplicaSet 12m deployment-controller Scaled up replica set nginx-deployment-75675f5897 to 3 Normal ScalingReplicaSet 11m deployment-controller Scaled up replica set nginx-deployment-c4747d96c to 1 Normal ScalingReplicaSet 11m deployment-controller Scaled down replica set nginx-deployment-75675f5897 to 2 Normal ScalingReplicaSet 11m deployment-controller Scaled up replica set nginx-deployment-c4747d96c to 2 Normal ScalingReplicaSet 11m deployment-controller Scaled down replica set nginx-deployment-75675f5897 to 1 Normal ScalingReplicaSet 11m deployment-controller Scaled up replica set nginx-deployment-c4747d96c to 3 Normal ScalingReplicaSet 11m deployment-controller Scaled down replica set nginx-deployment-75675f5897 to 0 Normal ScalingReplicaSet 11m deployment-controller Scaled up replica set nginx-deployment-595696685f to 1 Normal DeploymentRollback 15s deployment-controller Rolled back deployment "nginx-deployment" to revision 2 Normal ScalingReplicaSet 15s deployment-controller Scaled down replica set nginx-deployment-595696685f to 0
缩放 Deployment
你可以使用如下指令缩放 Deployment:
kubectl scale deployment/nginx-deployment --replicas=10
输出类似于:
deployment.apps/nginx-deployment scaled
假设集群启用了Pod 的水平自动缩放, 你可以为 Deployment 设置自动缩放器,并基于现有 Pod 的 CPU 利用率选择要运行的 Pod 个数下限和上限。
kubectl autoscale deployment/nginx-deployment --min=10 --max=15 --cpu-percent=80
输出类似于:
deployment.apps/nginx-deployment scaled
比例缩放
RollingUpdate 的 Deployment 支持同时运行应用程序的多个版本。 当自动缩放器缩放处于上线进程(仍在进行中或暂停)中的 RollingUpdate Deployment 时, Deployment 控制器会平衡现有的活跃状态的 ReplicaSets(含 Pod 的 ReplicaSets)中的额外副本, 以降低风险。这称为 比例缩放(Proportional Scaling)。
例如,你正在运行一个 10 个副本的 Deployment,其 maxSurge=3,maxUnavailable=2。
-
确保 Deployment 的这 10 个副本都在运行。
kubectl get deploy输出类似于:
NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE nginx-deployment 10 10 10 10 50s -
更新 Deployment 使用新镜像,碰巧该镜像无法从集群内部解析。
kubectl set image deployment/nginx-deployment nginx=nginx:sometag输出类似于:
deployment.apps/nginx-deployment image updated -
镜像更新使用 ReplicaSet
nginx-deployment-1989198191启动新的上线过程, 但由于上面提到的maxUnavailable要求,该进程被阻塞了。检查上线状态:kubectl get rs输出类似于:
NAME DESIRED CURRENT READY AGE nginx-deployment-1989198191 5 5 0 9s nginx-deployment-618515232 8 8 8 1m -
然后,出现了新的 Deployment 扩缩请求。自动缩放器将 Deployment 副本增加到 15。 Deployment 控制器需要决定在何处添加 5 个新副本。如果未使用比例缩放,所有 5 个副本 都将添加到新的 ReplicaSet 中。使用比例缩放时,可以将额外的副本分布到所有 ReplicaSet。 较大比例的副本会被添加到拥有最多副本的 ReplicaSet,而较低比例的副本会进入到 副本较少的 ReplicaSet。所有剩下的副本都会添加到副本最多的 ReplicaSet。 具有零副本的 ReplicaSets 不会被扩容。
在上面的示例中,3 个副本被添加到旧 ReplicaSet 中,2 个副本被添加到新 ReplicaSet。 假定新的副本都很健康,上线过程最终应将所有副本迁移到新的 ReplicaSet 中。 要确认这一点,请运行:
kubectl get deploy
输出类似于:
NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE
nginx-deployment 15 18 7 8 7m
上线状态确认了副本是如何被添加到每个 ReplicaSet 的。
kubectl get rs
输出类似于:
NAME DESIRED CURRENT READY AGE
nginx-deployment-1989198191 7 7 0 7m
nginx-deployment-618515232 11 11 11 7m
暂停、恢复 Deployment 的上线过程
在你更新一个 Deployment 的时候,或者计划更新它的时候, 你可以在触发一个或多个更新之前暂停 Deployment 的上线过程。 当你准备应用这些变更时,你可以重新恢复 Deployment 上线过程。 这样做使得你能够在暂停和恢复执行之间应用多个修补程序,而不会触发不必要的上线操作。
-
例如,对于一个刚刚创建的 Deployment:
获取该 Deployment 信息:
kubectl get deploy输出类似于:
NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE nginx 3 3 3 3 1m获取上线状态:
kubectl get rs输出类似于:
NAME DESIRED CURRENT READY AGE nginx-2142116321 3 3 3 1m -
使用如下指令暂停上线:
kubectl rollout pause deployment/nginx-deployment输出类似于:
deployment.apps/nginx-deployment paused -
接下来更新 Deployment 镜像:
kubectl set image deployment/nginx-deployment nginx=nginx:1.16.1输出类似于:
deployment.apps/nginx-deployment image updated -
注意没有新的上线被触发:
kubectl rollout history deployment/nginx-deployment输出类似于:
deployments "nginx" REVISION CHANGE-CAUSE 1 <none> -
获取上线状态验证现有的 ReplicaSet 没有被更改:
kubectl get rs输出类似于:
NAME DESIRED CURRENT READY AGE nginx-2142116321 3 3 3 2m -
你可以根据需要执行很多更新操作,例如,可以要使用的资源:
kubectl set resources deployment/nginx-deployment -c=nginx --limits=cpu=200m,memory=512Mi输出类似于:
deployment.apps/nginx-deployment resource requirements updated暂停 Deployment 上线之前的初始状态将继续发挥作用,但新的更新在 Deployment 上线被暂停期间不会产生任何效果。
-
最终,恢复 Deployment 上线并观察新的 ReplicaSet 的创建过程,其中包含了所应用的所有更新:
kubectl rollout resume deployment/nginx-deployment输出类似于这样:
deployment.apps/nginx-deployment resumed -
观察上线的状态,直到完成。
kubectl get rs -w输出类似于:
NAME DESIRED CURRENT READY AGE nginx-2142116321 2 2 2 2m nginx-3926361531 2 2 0 6s nginx-3926361531 2 2 1 18s nginx-2142116321 1 2 2 2m nginx-2142116321 1 2 2 2m nginx-3926361531 3 2 1 18s nginx-3926361531 3 2 1 18s nginx-2142116321 1 1 1 2m nginx-3926361531 3 3 1 18s nginx-3926361531 3 3 2 19s nginx-2142116321 0 1 1 2m nginx-2142116321 0 1 1 2m nginx-2142116321 0 0 0 2m nginx-3926361531 3 3 3 20s -
获取最近上线的状态:
kubectl get rs输出类似于:
NAME DESIRED CURRENT READY AGE nginx-2142116321 0 0 0 2m nginx-3926361531 3 3 3 28s
说明:
你不可以回滚处于暂停状态的 Deployment,除非先恢复其执行状态。
Deployment 状态
Deployment 的生命周期中会有许多状态。上线新的 ReplicaSet 期间可能处于 Progressing(进行中),可能是 Complete(已完成),也可能是 Failed(失败)以至于无法继续进行。
进行中的 Deployment
执行下面的任务期间,Kubernetes 标记 Deployment 为进行中(Progressing)_:
- Deployment 创建新的 ReplicaSet
- Deployment 正在为其最新的 ReplicaSet 扩容
- Deployment 正在为其旧有的 ReplicaSet(s) 缩容
- 新的 Pod 已经就绪或者可用(就绪至少持续了 MinReadySeconds 秒)。
当上线过程进入“Progressing”状态时,Deployment 控制器会向 Deployment 的 .status.conditions 中添加包含下面属性的状况条目:
type: Progressingstatus: "True"reason: NewReplicaSetCreated|reason: FoundNewReplicaSet|reason: ReplicaSetUpdated
你可以使用 kubectl rollout status 监视 Deployment 的进度。
完成的 Deployment
当 Deployment 具有以下特征时,Kubernetes 将其标记为完成(Complete);
- 与 Deployment 关联的所有副本都已更新到指定的最新版本,这意味着之前请求的所有更新都已完成。
- 与 Deployment 关联的所有副本都可用。
- 未运行 Deployment 的旧副本。
当上线过程进入“Complete”状态时,Deployment 控制器会向 Deployment 的 .status.conditions 中添加包含下面属性的状况条目:
type: Progressingstatus: "True"reason: NewReplicaSetAvailable
这一 Progressing 状况的状态值会持续为 "True",直至新的上线动作被触发。 即使副本的可用状态发生变化(进而影响 Available 状况),Progressing 状况的值也不会变化。
你可以使用 kubectl rollout status 检查 Deployment 是否已完成。 如果上线成功完成,kubectl rollout status 返回退出代码 0。
kubectl rollout status deployment/nginx-deployment
输出类似于:
Waiting for rollout to finish: 2 of 3 updated replicas are available...
deployment "nginx-deployment" successfully rolled out
从 kubectl rollout 命令获得的返回状态为 0(成功):
echo $?
0
失败的 Deployment
你的 Deployment 可能会在尝试部署其最新的 ReplicaSet 受挫,一直处于未完成状态。 造成此情况一些可能因素如下:
- 配额(Quota)不足
- 就绪探测(Readiness Probe)失败
- 镜像拉取错误
- 权限不足
- 限制范围(Limit Ranges)问题
- 应用程序运行时的配置错误
检测此状况的一种方法是在 Deployment 规约中指定截止时间参数: (.spec.progressDeadlineSeconds)。 .spec.progressDeadlineSeconds 给出的是一个秒数值,Deployment 控制器在(通过 Deployment 状态) 标示 Deployment 进展停滞之前,需要等待所给的时长。
以下 kubectl 命令设置规约中的 progressDeadlineSeconds,从而告知控制器 在 10 分钟后报告 Deployment 的上线没有进展:
kubectl patch deployment/nginx-deployment -p '{"spec":{"progressDeadlineSeconds":600}}'
输出类似于:
deployment.apps/nginx-deployment patched
超过截止时间后,Deployment 控制器将添加具有以下属性的 Deployment 状况到 Deployment 的 .status.conditions 中:
type: Progressingstatus: "False"reason: ProgressDeadlineExceeded
这一状况也可能会比较早地失败,因而其状态值被设置为 "False", 其原因为 ReplicaSetCreateError。 一旦 Deployment 上线完成,就不再考虑其期限。
参考 Kubernetes API Conventions 获取更多状态状况相关的信息。
说明:
除了报告 Reason=ProgressDeadlineExceeded 状态之外,Kubernetes 对已停止的 Deployment 不执行任何操作。更高级别的编排器可以利用这一设计并相应地采取行动。 例如,将 Deployment 回滚到其以前的版本。
说明:
如果你暂停了某个 Deployment 上线,Kubernetes 不再根据指定的截止时间检查 Deployment 上线的进展。 你可以在上线过程中间安全地暂停 Deployment 再恢复其执行,这样做不会导致超出最后时限的问题。
Deployment 可能会出现瞬时性的错误,可能因为设置的超时时间过短, 也可能因为其他可认为是临时性的问题。例如,假定所遇到的问题是配额不足。 如果描述 Deployment,你将会注意到以下部分:
kubectl describe deployment nginx-deployment
输出类似于:
<...>
Conditions:
Type Status Reason
---- ------ ------
Available True MinimumReplicasAvailable
Progressing True ReplicaSetUpdated
ReplicaFailure True FailedCreate
<...>
如果运行 kubectl get deployment nginx-deployment -o yaml,Deployment 状态输出 将类似于这样:
status:
availableReplicas: 2
conditions:
- lastTransitionTime: 2016-10-04T12:25:39Z
lastUpdateTime: 2016-10-04T12:25:39Z
message: Replica set "nginx-deployment-4262182780" is progressing.
reason: ReplicaSetUpdated
status: "True"
type: Progressing
- lastTransitionTime: 2016-10-04T12:25:42Z
lastUpdateTime: 2016-10-04T12:25:42Z
message: Deployment has minimum availability.
reason: MinimumReplicasAvailable
status: "True"
type: Available
- lastTransitionTime: 2016-10-04T12:25:39Z
lastUpdateTime: 2016-10-04T12:25:39Z
message: 'Error creating: pods "nginx-deployment-4262182780-" is forbidden: exceeded quota:
object-counts, requested: pods=1, used: pods=3, limited: pods=2'
reason: FailedCreate
status: "True"
type: ReplicaFailure
observedGeneration: 3
replicas: 2
unavailableReplicas: 2
最终,一旦超过 Deployment 进度限期,Kubernetes 将更新状态和进度状况的原因:
Conditions:
Type Status Reason
---- ------ ------
Available True MinimumReplicasAvailable
Progressing False ProgressDeadlineExceeded
ReplicaFailure True FailedCreate
可以通过缩容 Deployment 或者缩容其他运行状态的控制器,或者直接在命名空间中增加配额 来解决配额不足的问题。如果配额条件满足,Deployment 控制器完成了 Deployment 上线操作, Deployment 状态会更新为成功状况(Status=True 和 Reason=NewReplicaSetAvailable)。
Conditions:
Type Status Reason
---- ------ ------
Available True MinimumReplicasAvailable
Progressing True NewReplicaSetAvailable
type: Available 加上 status: True 意味着 Deployment 具有最低可用性。 最低可用性由 Deployment 策略中的参数指定。 type: Progressing 加上 status: True 表示 Deployment 处于上线过程中,并且正在运行, 或者已成功完成进度,最小所需新副本处于可用。 请参阅对应状况的 Reason 了解相关细节。 在我们的案例中 reason: NewReplicaSetAvailable 表示 Deployment 已完成。
你可以使用 kubectl rollout status 检查 Deployment 是否未能取得进展。 如果 Deployment 已超过进度限期,kubectl rollout status 返回非零退出代码。
kubectl rollout status deployment/nginx-deployment
输出类似于:
Waiting for rollout to finish: 2 out of 3 new replicas have been updated...
error: deployment "nginx" exceeded its progress deadline
kubectl rollout 命令的退出状态为 1(表明发生了错误):
echo $?
1
对失败 Deployment 的操作
可应用于已完成的 Deployment 的所有操作也适用于失败的 Deployment。 你可以对其执行扩缩容、回滚到以前的修订版本等操作,或者在需要对 Deployment 的 Pod 模板应用多项调整时,将 Deployment 暂停。
清理策略
你可以在 Deployment 中设置 .spec.revisionHistoryLimit 字段以指定保留此 Deployment 的多少个旧有 ReplicaSet。其余的 ReplicaSet 将在后台被垃圾回收。 默认情况下,此值为 10。
说明:
显式将此字段设置为 0 将导致 Deployment 的所有历史记录被清空,因此 Deployment 将无法回滚。
金丝雀部署
如果要使用 Deployment 向用户子集或服务器子集上线版本, 则可以遵循资源管理所描述的金丝雀模式, 创建多个 Deployment,每个版本一个。
编写 Deployment 规约
同其他 Kubernetes 配置一样, Deployment 需要 .apiVersion,.kind 和 .metadata 字段。 有关配置文件的其他信息,请参考部署 Deployment、 配置容器和使用 kubectl 管理资源等相关文档。
当控制面为 Deployment 创建新的 Pod 时,Deployment 的 .metadata.name 是命名这些 Pod 的部分基础。 Deployment 的名称必须是一个合法的 DNS 子域值, 但这会对 Pod 的主机名产生意外的结果。为获得最佳兼容性,名称应遵循更严格的 DNS 标签规则。
Deployment 还需要 .spec` 部分
设置资源限制
$ kubectl set resources deployment nginx -c=nginx --limits=cpu=200m,memory=512Mi
deployment "nginx" resource requirements updated
HAP
需要提前安装
HorizontalPodAutoscaler(简称 HPA ) 自动更新工作负载资源(例如 Deployment 或者 StatefulSet), 目的是自动扩缩工作负载以满足需求。
水平扩缩意味着对增加的负载的响应是部署更多的 Pod。 这与“垂直(Vertical)”扩缩不同,对于 Kubernetes, 垂直扩缩意味着将更多资源(例如:内存或 CPU)分配给已经为工作负载运行的 Pod。
[root@k8smaster hpa]# kubectl get pod -o wide
[root@k8smaster hpa]# kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 20d
创建 HorizontalPodAutoscaler:
kubectl autoscale deployment php-apache --cpu-percent=50 --min=1 --max=10
你可以通过运行以下命令检查新制作的 HorizontalPodAutoscaler 的当前状态:
kubectl get hpa
输出类似于:
NAME REFERENCE TARGET MINPODS MAXPODS REPLICAS AGE
php-apache Deployment/php-apache/scale 0% / 50% 1 10 1 18s
增加负载
接下来,看看自动扩缩器如何对增加的负载做出反应。 为此,你将启动一个不同的 Pod 作为客户端。 客户端 Pod 中的容器在无限循环中运行,向 php-apache 服务发送查询。
# 在单独的终端中运行它
# 以便负载生成继续,你可以继续执行其余步骤
kubectl run -i --tty load-generator --rm --image=busybox:1.28 --restart=Never -- /bin/sh -c "while sleep 0.01; do wget -q -O- http://php-apache; done"
现在执行:
# 准备好后按 Ctrl+C 结束观察
kubectl get hpa php-apache --watch
一分钟时间左右之后,通过以下命令,我们可以看到 CPU 负载升高了;例如:
NAME REFERENCE TARGET MINPODS MAXPODS REPLICAS AGE
php-apache Deployment/php-apache/scale 305% / 50% 1 10 1 3m
然后,更多的副本被创建。例如:
NAME REFERENCE TARGET MINPODS MAXPODS REPLICAS AGE
php-apache Deployment/php-apache/scale 305% / 50% 1 10 7 3m
这时,由于请求增多,CPU 利用率已经升至请求值的 305%。 可以看到,Deployment 的副本数量已经增长到了 7:
kubectl get deployment php-apache
你应该会看到与 HorizontalPodAutoscaler 中的数字与副本数匹配
NAME READY UP-TO-DATE AVAILABLE AGE
php-apache 7/7 7 7 19m
说明: 有时最终副本的数量可能需要几分钟才能稳定下来。由于环境的差异, 不同环境中最终的副本数量可能与本示例中的数量不同。
停止产生负载
要完成该示例,请停止发送负载。
在我们创建 busybox 容器的终端中,输入 <Ctrl> + C 来终止负载的产生。
然后验证结果状态(大约一分钟后):
# 准备好后按 Ctrl+C 结束观察
kubectl get hpa php-apache --watch
输出类似于:
NAME REFERENCE TARGET MINPODS MAXPODS REPLICAS AGE
php-apache Deployment/php-apache/scale 0% / 50% 1 10 1 11m
Deployment 也显示它已经缩小了:
kubectl get deployment php-apache
NAME READY UP-TO-DATE AVAILABLE AGE
php-apache 1/1 1 1 27m
一旦 CPU 利用率降至 0,HPA 会自动将副本数缩减为 1。
自动扩缩完成副本数量的改变可能需要几分钟的时间。
init容器
在 Kubernetes(K8s)中,Init 容器(Init Containers)是一种特殊类型的容器,它负责在主容器运行之前执行一些初始化任务。Init 容器与主容器是串行运行的,即 Init 容器中的任务完成后,主容器才会启动。
以下是有关 Kubernetes 中 Init 容器的详细解释:
1. 用途和优势:
- 初始化任务: Init 容器用于执行初始化任务,例如加载配置、预热缓存、初始化数据库等。这些任务通常是主容器运行之前必须完成的操作。
- 解耦初始化逻辑: 使用 Init 容器可以将初始化逻辑从主容器中解耦,使主容器只关注应用程序的业务逻辑,提高了可维护性和可重用性。
2. 特点和工作方式:
- 串行运行: Init 容器和主容器是串行运行的,即 Init 容器中的任务完成后,主容器才会启动。
- 共享存储和网络: Init 容器与主容器共享相同的存储卷(Volume)和网络命名空间,因此它们可以在相同的环境中运行。
3. 使用示例:
以下是一个简单的 Pod YAML 文件,其中包含了一个 Init 容器和一个主容器:
apiVersion: v1
kind: Pod
metadata:
name: mypod
spec:
containers:
- name: main-container
image: nginx:latest
initContainers:
- name: init-container
image: busybox:latest
command: ['sh', '-c', 'echo "Initialization complete; starting main container"']
在这个示例中,init-container 是一个使用 BusyBox 镜像的 Init 容器,它执行了一个简单的 echo 命令。一旦 init-container 完成任务,主容器 main-container 就会启动。
4. 生命周期和状态:
- Init 容器的生命周期: Init 容器的生命周期与主容器类似,包括创建、启动、停止和删除。
- 状态传递: Init 容器的状态对主容器是不可见的,但如果 Init 容器失败(非零退出码),主容器不会启动。
5. 多个 Init 容器:
- 多个初始化容器: 一个 Pod 可以包含多个 Init 容器,它们按照声明的顺序依次执行。
- 依赖关系: 可以通过 init 容器的执行结果作为后续 init 容器的输入,实现一些复杂的初始化逻辑。
6. 注意事项:
- 超时和重试: 可以配置 Init 容器的超时时间,如果在规定时间内未完成,Pod 将被认为启动失败。
- 并发初始化: Init 容器是串行执行的,如果需要并发执行,可以考虑使用多个 Init 容器。
总体而言,Init 容器是 Kubernetes 中一项强大的功能,它允许开发者在容器启动之前执行一些必要的初始化任务,提高了容器化应用的灵活性和可维护性。
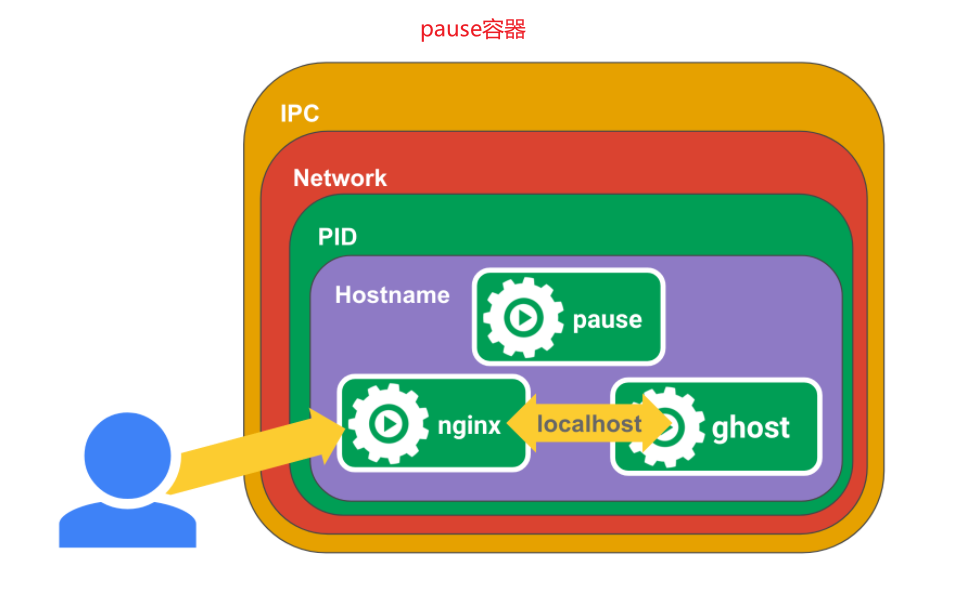
pause容器
在 Kubernetes 中,Pause 容器是每个 Pod 中的一个特殊容器,它的主要目的是保持 Pod 的网络命名空间(Network Namespace)以及其他共享的命名空间(例如 PID 命名空间)的存在。Pause 容器是 Kubernetes 实现多容器 Pod 的一部分,它在 Pod 启动时运行,而且在 Pod 中的其他容器启动之前一直运行。
以下是 Pause 容器的一些详细解释:
1. 作用和目的:
- 保持命名空间: Pause 容器的主要目的是保持 Pod 的网络命名空间,确保其他容器能够在相同的网络环境中运行。这有助于实现容器之间的网络隔离。
- 协调容器启动: Pause 容器还用于协调其他容器的启动顺序,确保它们按照正确的顺序启动。
- 启用 pid 命名空间,
2. 镜像和进程:
- 基础镜像: Pause 容器通常使用一个极小的基础镜像,其中包含最小化的文件系统和可执行文件。在 Docker 中,通常使用
busybox或alpine作为 Pause 容器的基础镜像。 - 无限循环: Pause 容器启动后通常执行一个无限循环的命令,以保持容器处于运行状态。
3. 生命周期和状态:
- 持续运行: Pause 容器一直运行,直到 Pod 被终止。
- 无法被用户访问: Pause 容器通常不对用户提供服务,也不对用户可见。用户主要与 Pod 中的其他业务容器交互。
4. 网络隔离:
- 共享网络: Pause 容器与其他容器共享相同的网络命名空间,这意味着它们可以通过 localhost 进行通信。
- Pod 中的其他容器: Pod 中的其他容器可以通过网络共享与 Pause 容器通信,从而实现容器之间的网络隔离。
5. 进程隔离:
- PID 命名空间: Pause 容器通常也会与其他容器共享相同的 PID 命名空间,以便它们能够看到同一组进程。
6. 使用示例:
-
Pod YAML 示例:
apiVersion: v1 kind: Pod metadata: name: mypod spec: containers: - name: main-container image: nginx:latest在这个示例中,
mypodPod 包含一个
main-container和一个 Pause 容器。Pause 容器将保持网络和 PID 命名空间的存在。
7. 其他示例
我们首先在节点上运行一个 pause 容器。
docker run -d --name pause -p 8880:80 --ipc=shareable jimmysong/pause-amd64:3.0
这个 Docker 命令是在后台运行一个名为 “pause” 的容器,使用了 “jimmysong/pause-amd64:3.0” 镜像。以下是各个选项的解释:
docker run: 运行容器的命令。-d: 在后台运行容器,即以守护进程方式运行。--name pause: 为容器指定一个名字,这里是 “pause”。-p 8880:80: 将容器的端口映射到主机的端口,将容器内部的端口 80 映射到主机的端口 8880。--ipc=shareable: 允许与其他容器共享 IPC(Inter-Process Communication)命名空间。IPC 共享是容器间进程通信的一种方式。镜像:
jimmysong/pause-amd64:3.0: 使用名为 “pause-amd64” 的镜像,该镜像的版本是 “3.0”。这个镜像通常被用作 Kubernetes 等容器编排系统中的 Pause 容器。Pause 容器的作用是维持 Pod 中的网络命名空间,确保其他容器能够在相同的网络环境中运行,并且也被用于协调容器启动顺序。通过这个命令,你创建了一个后台运行的容器,它使用指定的镜像,并映射容器端口到主机端口。这个容器是一个示例,通常在实际应用中,“pause” 容器是由容器编排系统(如 Kubernetes)自动创建和管理的。
然后再运行一个 nginx 容器,nginx 将为 localhost:2368 创建一个代理。
#编辑nginx.conf文件
$ cat <<EOF >> nginx.conf
error_log stderr;
events { worker_connections 1024; }
http {
access_log /dev/stdout combined;
server {
listen 80 default_server;
server_name example.com www.example.com;
location / {
proxy_pass http://127.0.0.1:2368;
}
}
}
EOF
# 运行
$ docker run -d --name nginx -v `pwd`/nginx.conf:/etc/nginx/nginx.conf --net=container:pause --ipc=container:pause --pid=container:pause nginx
这个命令涉及创建一个名为 “nginx” 的 Docker 容器,运行 Nginx 服务,并将 Nginx 的配置文件从主机挂载到容器内。以下是命令的详解:
cat <<EOF >> nginx.conf:
- 这是一个 shell 的 Here 文档,用于将多行文本追加到
nginx.conf文件。EOF是 Here 文档的结束标记。- 配置文件内容:
- 在 Here 文档中,你提供了 Nginx 的配置文件内容,其中包括:
- 将错误日志输出到标准错误流(
error_log stderr;)。- 配置 Nginx 事件(
events)和 HTTP 部分,指定 worker 连接数、访问日志位置等。- 配置一个简单的 Nginx 服务器,监听在80端口,将请求代理到 http://127.0.0.1:2368。
docker run -d --name nginx ...:
docker run: 运行容器的命令。-d: 后台运行容器,即以守护进程方式运行。--name nginx: 为容器指定一个名字,这里是 “nginx”。-vpwd/nginx.conf:/etc/nginx/nginx.conf: 将主机上的nginx.conf文件挂载到容器内的/etc/nginx/nginx.conf,这样 Nginx 将使用这个配置文件。--net=container:pause: 共享网络命名空间,使得 Nginx 和 “pause” 容器共享相同的网络环境。这通常用于确保容器在相同的网络环境中运行。--ipc=container:pause: 共享 IPC 命名空间,容器间可以通过 IPC 进行通信。--pid=container:pause: 共享 PID 命名空间,容器间可以看到相同的进程 ID。nginx: 使用的 Docker 镜像,即运行 Nginx 服务。通过这个命令,你创建了一个后台运行的 Nginx 容器,并在运行时将 Nginx 的配置文件加载进来。这样,你可以在主机上编辑
nginx.conf,并且不需要重新启动容器即可应用新的配置。容器共享网络、IPC、PID 命名空间,这通常在某些场景下是有用的,比如容器编排系统中的多容器协同工作。
然后再为 ghost 创建一个应用容器,这是一款博客软件。
$ docker run -d --name ghost --net=container:pause --ipc=container:pause --pid=container:pause ghost
docker run: Docker 命令,用于运行容器。-d: 后台运行容器,即以守护进程方式运行。--name ghost: 为容器指定一个名字,这里是 “ghost”。--net=container:pause: 共享网络命名空间,即与指定的 “pause” 容器共享相同的网络环境。这通常用于确保容器在相同的网络环境中运行。--ipc=container:pause: 共享 IPC 命名空间,与指定的 “pause” 容器共享相同的 IPC 资源。这使得容器之间可以进行进程间通信。--pid=container:pause: 共享 PID 命名空间,与指定的 “pause” 容器共享相同的进程 ID。这使得容器之间能够看到相同的进程视图。ghost: 使用的 Docker 镜像,这里是 “ghost”。Ghost 是一个开源的博客平台。
现在访问 http://localhost:8880/ 就可以看到 ghost 博客的界面了。
解析
pause 容器将内部的 80 端口映射到宿主机的 8880 端口,pause 容器在宿主机上设置好了网络 namespace 后,nginx 容器加入到该网络 namespace 中,我们看到 nginx 容器启动的时候指定了 --net=container:pause,ghost 容器同样加入到了该网络 namespace 中,这样三个容器就共享了网络,互相之间就可以使用 localhost 直接通信,--ipc=container:pause --pid=container:pause 就是三个容器处于同一个 namespace 中,init 进程为 pause,这时我们进入到 ghost 容器中查看进程情况。
# ps aux
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
root 1 0.0 0.0 1024 4 ? Ss 13:49 0:00 /pause
root 5 0.0 0.1 32432 5736 ? Ss 13:51 0:00 nginx: master p
systemd+ 9 0.0 0.0 32980 3304 ? S 13:51 0:00 nginx: worker p
node 10 0.3 2.0 1254200 83788 ? Ssl 13:53 0:03 node current/in
root 79 0.1 0.0 4336 812 pts/0 Ss 14:09 0:00 sh
root 87 0.0 0.0 17500 2080 pts/0 R+ 14:10 0:00 ps aux
在 ghost 容器中同时可以看到 pause 和 nginx 容器的进程,并且 pause 容器的 PID 是 1。而在 Kubernetes 中容器的 PID=1 的进程即为容器本身的业务进程。
8. 其他容器启动依赖:
- 协调容器启动: Pause 容器的存在确保其他容器在正确的顺序启动。这对于依赖于共享网络命名空间的容器启动顺序非常重要。
总体而言,Pause 容器在 Kubernetes 中扮演着维持网络隔离和协调其他容器启动的重要角色。虽然用户通常不与 Pause 容器直接交互,但它在底层确保了多容器 Pod 的正常运行。
pod安全策略
Pod 安全策略(Pod Security Policy) 是集群级别的资源,它能够控制Pod规约 中与安全性相关的各个方面。PodSecurityPolicy 对象定义了一组Pod运行时必须遵循的条件及相关字段的默认值,只有 Pod 满足这些条件才会被系统接受。
下列PodSecurityPolicy表示是不允许创建特权模式的Pod
apiVersion: policy/v1beta1
kind: PodSecurityPolicy
metadata:
name: permissive
spec:
privileged: false
allowPrivilegeEscalation: true
readOnlyRootFilesystem: false
seLinux:
rule: RunAsAny
supplementalGroups:
rule: RunAsAny
runAsUser:
rule: RunAsAny
fsGroup:
rule: RunAsAny
allowedCapabilities:
- '*'
hostPorts:
- min: 8000
max: 8080
volumes:
- '*'
创建之后查看:
kubectl get psp
或者
kubectl get podSecurityPolicy

上面的PodSecurytiPolicy是设置了不允许创建特权模式的Pod,例如,在下面的YAML配置文件pod-privileged.yaml中为Pod设置了特权模式:
获取 Pod 安全策略列表
获取已存在策略列表,使用 kubectl get:
[root@k8smaster security]# kubectl get psp
NAME PRIV CAPS SELINUX RUNASUSER FSGROUP SUPGROUP READONLYROOTFS VOLUMES
permissive false * RunAsAny RunAsAny RunAsAny RunAsAny false *
修改 Pod 安全策略
通过交互方式修改策略,使用 kubectl edit:
kubectl edit psp permissive

该命令将打开一个默认文本编辑器,在这里能够修改策略。
删除 Pod 安全策略
一旦不再需要一个策略,很容易通过 kubectl 删除它:
[root@k8smaster security]# kubectl delete psp permissive
podsecuritypolicy.policy "permissive" deleted
[root@k8smaster security]# kubectl get psp
No resources found
pod生命周期
Kubernetes 中 Pod 的生命周期,包括生命周期的不同阶段、存活和就绪探针(在容器探针一篇)、重启策略等
Kubernetes 中的 Pod 生命周期包括多个阶段,从 Pod 创建到终止,其中包括一系列的生命周期事件。以下是 Pod 生命周期的主要阶段(phase):
- Pending(挂起):
- Pod 已经被创建,但还没有被调度到一个节点上运行。这个阶段可能是由于调度问题、等待容器镜像下载等原因导致的。
- ContainerCreating(创建容器):
- Pod 已经被调度到节点上,但正在创建容器。这包括拉取容器镜像、创建容器等过程。
- Running(运行中):
- 所有容器已经成功创建并且正在运行。Pod 进入这个阶段表示应用程序或服务已经在容器中运行。
- Succeeded(成功):
- 所有容器成功运行并已经退出,Pod 处于完成状态。这通常发生在一次性任务完成后,例如 Job 类型的任务。
- Failed(失败):
- Pod 中的一个或多个容器已经失败。这可能是由于应用程序错误、配置问题或其他故障导致的。
- Unknown(未知):
- 由于某种原因,Pod 的状态无法被确定。这可能是由于调度问题、通信问题等导致的。
- Terminating(终止中):
- Pod 正在被终止。这包括停止运行中的容器、清理资源等操作。Pod 在终止过程中可能会经历一些阶段,例如删除容器、释放网络和存储资源等。
- Terminated(已终止):
- Pod 已经终止,不再运行。这可能是因为正常完成、手动删除、或者发生了无法恢复的错误。

Kubernetes 控制器负责监控和管理 Pod 的生命周期。例如,Deployment 控制器负责创建和维护副本集,确保指定数量的 Pod 在运行。Job 控制器则负责确保指定数量的 Pod 成功运行一次。
Pod 生命周期中的事件和状态转换可以通过 kubectl describe pod <pod-name> 命令查看详细信息。这提供了对 Pod 中容器运行和终止的详细记录。
pod状态
Pod 有一个 PodStatus 对象,其中包含一个 PodCondition 数组。 PodCondition 数组的每个元素都有一个 type 字段和一个 status 字段。type 字段是字符串,可能的值有 PodScheduled、Ready、Initialized、Unschedulable和ContainersReady。status 字段是一个字符串,可能的值有 True、False 和 Unknown。
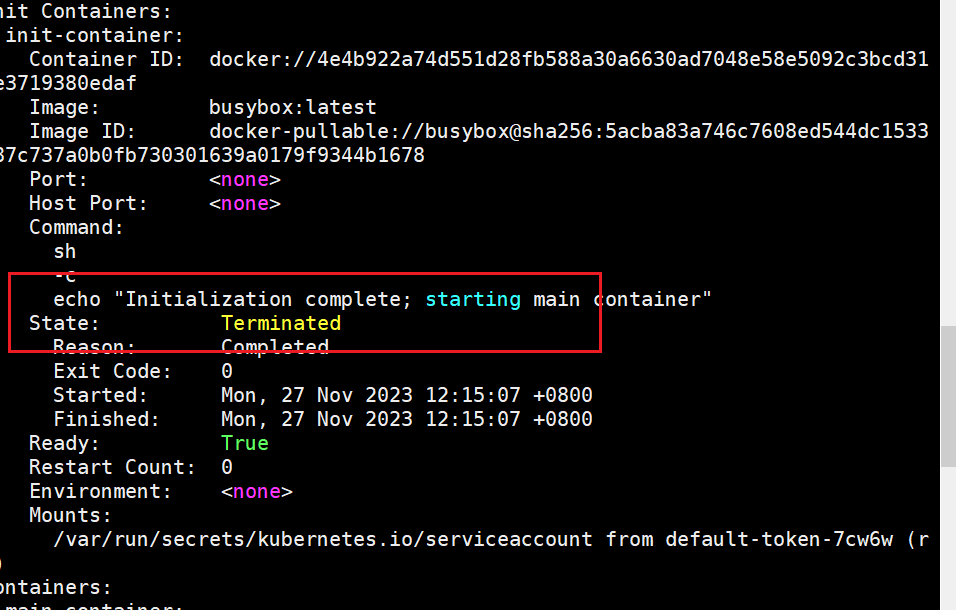
查看pod的详细信息
kubectl describe pod podname
查看pod的state
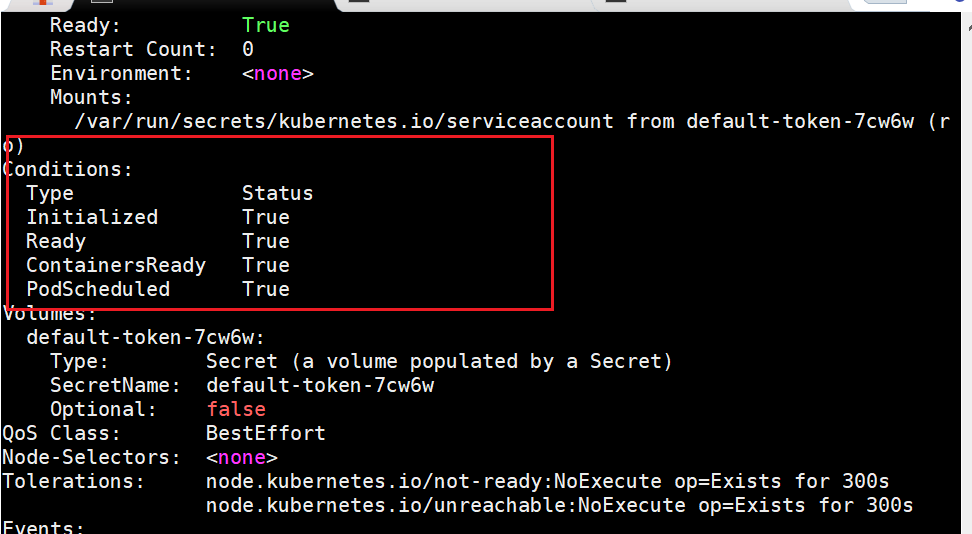
查看pod的type
字段说明
- Initialized:
- Type: Initialized 表示 Pod 是否已经完成了初始化阶段。在这个阶段,Kubernetes 正在为 Pod 设置网络和存储,确保所有容器都已启动。
- Status: True 表示初始化已完成。
- Ready:
- Type: Ready 表示 Pod 是否已经准备好接收网络流量。Ready 为 True 表示 Pod 已经准备好,容器已经启动并且已经可以接受请求。
- Status: True 表示 Pod 已经准备好。
- ContainersReady:
- Type: ContainersReady 表示 Pod 中的所有容器是否都已经准备好接收请求。Ready 仅表示主容器的准备状态,而 ContainersReady 表示所有容器都已准备好。
- Status: True 表示所有容器都已准备好。
- PodScheduled:
- Type: PodScheduled 表示 Pod 是否已经被成功地调度到某个节点上。调度是指 Kubernetes 决定将 Pod 放置在哪个节点上运行。
- Status: True 表示 Pod 已经成功调度。
pod hook
Kubernetes中的Pod Hook(也称为Pod生命周期钩子或Pod钩子)是一种机制,允许您在Pod的生命周期中执行自定义操作。这些操作可以包括在Pod创建前、创建后、删除前、删除后等特定时刻运行的命令或脚本。Pod Hook可用于执行与Pod相关的任务,例如初始化、清理或监控。
Pod Hook主要有以下几种类型:
- PostStart:这是一个在容器启动后执行的钩子。它通常用于执行初始化任务,例如等待依赖服务启动或执行某些设置操作。如果PostStart钩子失败,Pod将被认为处于失败状态,并且Kubernetes可能会尝试重新启动该Pod。
- PreStop:这是一个在容器终止之前执行的钩子。它通常用于执行清理任务,例如保存数据或发送信号给应用程序,以便它可以正确地停止。如果PreStop钩子失败,Pod仍会终止,但Kubernetes会记录错误。
- PostStop:Kubernetes不直接支持PostStop钩子,但您可以通过容器内的进程来实现类似的功能。当容器内的进程终止时,您可以在容器中运行一些附加的操作,例如清理文件或发送通知。
为了使用Pod Hook,您需要将它们定义在Pod的规范中。以下是一个Pod定义的示例,其中包含PostStart和PreStop钩子:
apiVersion: v1
kind: Pod
metadata:
name: lifecycle-demo
spec:
containers:
- name: lifecycle-demo-container
image: nginx
lifecycle:
postStart:
exec:
command: ["/bin/sh", "-c", "echo Hello from the postStart handler> /usr/share/message"]
preStop:
exec:
command: ["/usr/sbin/nginx","-s","quit"]
这是一个Kubernetes Pod的YAML定义文件,其中定义了一个名为
lifecycle-demo的Pod,它包含一个名为lifecycle-demo-container的容器,并使用了生命周期钩子来定义容器的行为。逐一解释这个YAML文件的各个部分:
apiVersion: v1:这指定了Kubernetes API版本,这里使用的是v1版本。kind: Pod:这定义了资源类型为Pod。metadata:这是元数据部分,用于指定Pod的元数据信息,包括名称。在这个示例中,Pod的名称为lifecycle-demo。spec:这是Pod规范部分,用于定义Pod的规范,包括容器的定义。containers:这是容器列表,包含了Pod中的容器的定义。在这个示例中,只有一个容器,名称为lifecycle-demo-container,并且它使用了Nginx镜像。lifecycle:这是定义容器生命周期钩子的部分。在这个示例中,有两个生命周期钩子:
postStart:这是在容器启动后执行的钩子。它使用exec来执行一个命令,即在容器启动后向/usr/share/message文件中写入一条消息,消息内容是 “Hello from the postStart handler”。preStop:这是在容器终止之前执行的钩子。它使用exec来执行一个命令,即在容器终止前通过执行/usr/sbin/nginx -s quit命令来优雅地停止Nginx服务。这个YAML文件定义了一个带有生命周期钩子的Pod,这些钩子将在容器启动和终止时执行特定的操作。这可以用来执行初始化或清理任务,以确保容器在启动和终止时执行所需的操作。
进入pod内查看输出
kubectl exec -it lifecycle-demo -c lifecycle-demo-container -- /bin/sh
您运行的命令是
kubectl exec,它用于在Kubernetes中的一个正在运行的Pod中的容器中执行一个特定的命令。下面是您运行的命令的详细解释:
kubectl:这是Kubernetes命令行工具,用于与Kubernetes集群进行交互。exec:这是kubectl的一个子命令,用于在一个容器中执行命令。-it:这是kubectl exec命令的标志,它表示您要与命令的标准输入和标准输出进行交互(Interactive Terminal)。这使您可以与容器中的命令进行交互,就像在本地终端中一样。lifecycle-demo:这是要在其中执行命令的Pod的名称。-c lifecycle-demo-container:这是kubectl exec命令的另一个标志,它指定了要在哪个容器中执行命令。在这种情况下,您指定了lifecycle-demo-container,这是Pod中唯一的容器名称。-- /bin/sh:这是您要在容器中执行的实际命令。它启动一个Shell(/bin/sh),这将允许您在容器中交互式地执行命令。当您运行这个命令后,您将进入
lifecycle-demo-container中的Shell,从那里您可以执行各种命令,与容器内部进行交互,检查容器中的文件和状态,以及进行其他与容器相关的操作。这对于调试和管理容器非常有用。

postStart 在容器创建之后(但并不能保证钩子会在容器 ENTRYPOINT 之前)执行,这时候 Pod 已经被调度到某台 node 上,被某个 kubelet 管理了,这时候 kubelet 会调用 postStart 操作,该操作跟容器的启动命令是在同步执行的,也就是说在 postStart 操作执行完成之前,kubelet 会锁住容器,不让应用程序的进程启动,只有在 postStart 操作完成之后容器的状态才会被设置成为 RUNNING。
PreStop 在容器终止之前被同步阻塞调用,常用于在容器结束前优雅的释放资源。
如果 postStart 或者 preStop hook 失败,将会终止容器。
pod preset(1.11-19 可用 1.20取消了此功能)
Pod Preset(Pod配置)是Kubernetes中的一个功能,允许您定义一组默认的环境变量、卷挂载和其他Pod配置,并将它们自动注入到Pod的容器中。这对于自动化和简化Pod配置非常有用,特别是当您需要在多个Pod中使用相同的配置时。
以下是有关Pod Preset的详细解释:
- 定义默认配置:Pod Preset允许您在Kubernetes中定义默认的配置,包括环境变量、卷挂载、资源限制、资源请求等等。
- 命名空间范围:Pod Preset在特定的命名空间内生效,这意味着您可以在每个命名空间内定义不同的配置。
- 注入配置:一旦您定义了Pod Preset,Kubernetes将根据Pod的标签选择合适的Preset,并将Preset中定义的配置注入到Pod的容器中。这可以在Pod规范中自动完成,而不需要手动添加每个配置。
- 标签选择器:您可以使用标签选择器来将Pod Preset应用于特定的Pod。这意味着您可以选择哪些Pod将使用Preset中定义的配置。
- 继承:Pod Preset支持继承,这意味着一个Pod可以继承多个Preset中的配置,从而使配置更加灵活。
以下是一个简单的示例,演示如何创建一个Pod Preset并将其应用于Pod:
apiVersion: settings.k8s.io/v1alpha1
kind: PodPreset
metadata:
name: my-pod-preset
spec:
selector:
matchLabels:
role: frontend
env:
- name: DATABASE_URL
value: "mysql://mydbserver:3306"
volumeMounts:
- name: config-volume
mountPath: /etc/config
volumes:
- name: config-volume
configMap:
name: my-config
在这个示例中,我们创建了一个名为 my-pod-preset 的Pod Preset,它将适用于具有 role: frontend 标签的Pod。这个Preset定义了一个环境变量 DATABASE_URL,一个卷挂载,以及一个与ConfigMap my-config 相关的卷。一旦Preset定义完毕,任何带有 role: frontend 标签的Pod都将自动继承这些配置。
Pod Preset对于简化和自动化Pod配置非常有用,特别是在需要共享相似配置的多个Pod的情况下。您可以创建一次配置,并将其应用于多个Pod,以减少重复工作并确保配置的一致性。
要使用定义好的Pod Preset YAML 文件,您需要执行以下步骤:
-
创建 Pod Preset:首先,您需要将定义的 Pod Preset YAML 文件应用到您的 Kubernetes 集群中。您可以使用
kubectl create或kubectl apply命令来创建 Pod Preset。例如:kubectl create -f your-pod-preset.yaml或
kubectl apply -f your-pod-preset.yaml这将在集群中创建名为
my-pod-preset的 Pod Preset。 -
应用 Pod Preset 到 Pod:要将 Pod Preset 应用到 Pod,您需要确保将 Pod 的标签匹配到 Pod Preset 的选择器条件。在您的 Pod YAML 文件中,确保您的 Pod 具有与 Pod Preset 选择器条件匹配的标签。例如,如果您的 Pod 需要使用
my-pod-preset,则可以在 Pod 的标签中添加role: frontend,以匹配 Pod Preset 的选择器条件。apiVersion: v1 kind: Pod metadata: name: my-pod labels: role: frontend # 匹配 Pod Preset 的选择器条件 spec: containers: - name: my-container image: my-image在这个示例中,
role: frontend标签将与my-pod-preset匹配,因此 Pod 将自动继承 Pod Preset 中定义的配置。 -
部署 Pod:使用
kubectl apply -f your-pod.yaml或kubectl create -f your-pod.yaml部署 Pod,确保它具有匹配 Pod Preset 的标签。 -
验证配置:一旦 Pod 被部署,您可以验证配置是否正确注入到 Pod 中。可以通过执行
kubectl describe pod your-pod命令来检查 Pod 的详细信息,以查看配置是否正确注入。
注意事项:
- Pod Preset 是 Kubernetes 的扩展功能,确保您的集群支持 Pod Preset。某些 Kubernetes 发行版可能需要启用 Pod Preset 支持。
- Pod Preset 通常在 Pod 创建时才会应用,如果您想更新一个正在运行的 Pod 的配置,通常需要删除并重新创建该 Pod。
- Pod Preset 只在同一命名空间内生效,确保 Pod Preset 和要应用它的 Pod 在同一命名空间内。
- 需要管理员或具有足够权限的用户才能创建 Pod Preset。
pod优先级和抢占
Pod 可以有优先级。 优先级表示一个 Pod 相对于其他 Pod 的重要性。 如果一个 Pod 无法被调度,调度程序会尝试抢占(驱逐)较低优先级的 Pod, 以使悬决 Pod 可以被调度。
警告:
在一个并非所有用户都是可信的集群中,恶意用户可能以最高优先级创建 Pod, 导致其他 Pod 被驱逐或者无法被调度。 管理员可以使用 ResourceQuota 来阻止用户创建高优先级的 Pod。 参见默认限制优先级消费。
创建优先级和抢占
- 新增一个或多个 PriorityClass。
- 创建 Pod,并将其
priorityClassName设置为新增的 PriorityClass。 当然你不需要直接创建 Pod;通常,你将会添加priorityClassName到集合对象(如 Deployment) 的 Pod 模板中。
PriorityClass清单
apiVersion: scheduling.k8s.io/v1
kind: PriorityClass
metadata:
name: high-priority
value: 1000000
globalDefault: false
description: "此优先级类应仅用于 XYZ 服务 Pod。"
声明清单
[root@k8smaster priority]# kubectl apply -f priority.yaml
查看详情
[root@k8smaster priority]# kubectl get PriorityClass
NAME VALUE GLOBAL-DEFAULT AGE
high-priority 1000000 false 24s
system-cluster-critical 2000000000 false 27d
system-node-critical 2000001000 false 27d
PriorityClass
PriorityClass 是 Kubernetes 中的一个无命名空间对象,用于定义从优先级类名称到优先级整数值的映射。PriorityClass 对象有一些关键属性:
- 名称(Name): 在 PriorityClass 对象的元数据
name字段中指定。这个名称必须是有效的 DNS 子域名,而且不能以 “system-” 为前缀。 - 值(Value): 在
value字段中指定,是一个必填字段。这个值表示优先级整数,而且值越大,优先级越高。PriorityClass 对象的值范围是从 -2,147,483,648 到 1,000,000,000。 - 全局默认(Global Default): PriorityClass 对象可以有一个可选字段
globalDefault,如果设置为true,表示这个 PriorityClass 的值应该用于没有指定priorityClassName的 Pod。一个集群中只能存在一个globalDefault设置为true的 PriorityClass。如果没有设置globalDefault的 PriorityClass,那么没有指定priorityClassName的 Pod 的优先级为零。 - 描述(Description): PriorityClass 还有一个可选字段
description,是一个任意字符串,用于提供关于此 PriorityClass 何时应该使用的描述。
注意事项
如果你升级一个已经存在但尚未使用 PodPriority 特性的 Kubernetes 集群,以及在集群中已经存在的 Pod,以下是一些注意事项:
- 已存在 Pod 的优先级等效于零:对于已经存在的 Pod,它们的优先级等效于零,即它们不受
PodPriority的影响。PodPriority特性的引入并不会自动改变现有 Pod 的优先级。 - 添加
globalDefault为 true 的 PriorityClass:如果你添加一个globalDefault设置为 true 的PriorityClass,它将成为全局默认的优先级类。然而,这并不会改变已经存在 Pod 的优先级。这个全局默认的优先级类的值仅用于添加PriorityClass后创建的 Pod。 - 删除 PriorityClass 对象:如果你删除一个
PriorityClass对象,已存在 Pod 使用被删除的PriorityClass名称的优先级仍然保持不变。但是,你将不能再创建使用已删除的PriorityClass名称的新 Pod。这是因为删除PriorityClass并不会影响已经存在 Pod 的优先级,但不再允许新 Pod 使用这个已删除的PriorityClass。
这些注意事项有助于理解在升级和修改 PriorityClass 设置时,现有 Pod 的行为和影响。
PriorityClass示例
apiVersion: scheduling.k8s.io/v1
kind: PriorityClass
metadata:
name: high-priority
value: 1000000
globalDefault: false
description: "此优先级类应仅用于 XYZ 服务 Pod。"
apiVersion: scheduling.k8s.io/v1: 指定了PriorityClass对象的 API 版本,表明使用的是 Kubernetes 调度 API 的版本。kind: PriorityClass: 定义了资源的优先级类别。metadata: 包含了优先级类别对象的元数据,如名称等。
name: high-priority: 设置了优先级类别的名称为 “high-priority”。value: 1000000: 定义了该优先级类别的优先级值。在这里,设置为 1000000,表示较高的优先级。该数值用于在调度中进行优先级比较。globalDefault: false: 指定该优先级类别不是全局默认的。即使不是全局默认,你仍然可以将该优先级类别分配给具体的 Pod。description: "此优先级类应仅用于 XYZ 服务 Pod。": 提供了对该优先级类别用途的描述。在这个例子中,建议将此优先级类别仅用于 XYZ 服务 Pod,以提供更多关于如何使用该优先级类别的信息。
非抢占式 PriorityClass(1.24)
配置了 preemptionPolicy: Never 的 Pod 将被放置在调度队列中较低优先级 Pod 之前, 但它们不能抢占其他 Pod。等待调度的非抢占式 Pod 将留在调度队列中,直到有足够的可用资源, 它才可以被调度。非抢占式 Pod,像其他 Pod 一样,受调度程序回退的影响。 这意味着如果调度程序尝试这些 Pod 并且无法调度它们,它们将以更低的频率被重试, 从而允许其他优先级较低的 Pod 排在它们之前。
非抢占式 Pod 仍可能被其他高优先级 Pod 抢占。
preemptionPolicy 默认为 PreemptLowerPriority, 这将允许该 PriorityClass 的 Pod 抢占较低优先级的 Pod(现有默认行为也是如此)。 如果 preemptionPolicy 设置为 Never,则该 PriorityClass 中的 Pod 将是非抢占式的。
数据科学工作负载是一个示例用例。用户可以提交他们希望优先于其他工作负载的作业, 但不希望因为抢占运行中的 Pod 而导致现有工作被丢弃。 设置为 preemptionPolicy: Never 的高优先级作业将在其他排队的 Pod 之前被调度, 只要足够的集群资源“自然地”变得可用。
非抢占式 PriorityClass 示例
apiVersion: scheduling.k8s.io/v1
kind: PriorityClass
metadata:
name: high-priority-nonpreempting
value: 1000000
preemptionPolicy: Never
globalDefault: false
description: "This priority class will not cause other pods to be preempt
pod优先级
一旦你创建了一个或多个 PriorityClass 对象,你可以在创建 Pod 时引用这些优先级类别。Pod 的 priorityClassName 字段用于指定 Pod 使用的优先级类别的名称。在以下示例中,我们使用了先前创建的 PriorityClass 名称为 “high-priority” 的优先级类别:
apiVersion: v1
kind: Pod
metadata:
name: nginx
labels:
env: test
spec:
containers:
- name: nginx
image: nginx
imagePullPolicy: IfNotPresent
priorityClassName: high-priority
这个 Pod 的配置中,priorityClassName 字段被设置为 “high-priority”,这意味着该 Pod 将使用名为 “high-priority” 的 PriorityClass 的优先级。对应的 PriorityClass 对象具有一个整数值为 1000000 的优先级。当这个 Pod 被创建时,优先级准入控制器将检查 PriorityClass 并将其优先级解析为 1000000。
如果在集群中找不到指定名称的 PriorityClass,将拒绝创建该 Pod。这有助于确保只有已定义的优先级类别才能用于 Pod 的调度。
Pod 优先级对调度顺序的影响
当启用 Pod 优先级时,调度程序会按优先级对悬决 Pod 进行排序, 并且每个悬决的 Pod 会被放置在调度队列中其他优先级较低的悬决 Pod 之前。 因此,如果满足调度要求,较高优先级的 Pod 可能会比具有较低优先级的 Pod 更早调度。 如果无法调度此类 Pod,调度程序将继续并尝试调度其他较低优先级的 Pod。
抢占
Pod 被创建后会进入队列等待调度。 调度器从队列中挑选一个 Pod 并尝试将它调度到某个节点上。 如果没有找到满足 Pod 的所指定的所有要求的节点,则触发对悬决 Pod 的抢占逻辑。 让我们将悬决 Pod 称为 P。抢占逻辑试图找到一个节点, 在该节点中删除一个或多个优先级低于 P 的 Pod,则可以将 P 调度到该节点上。 如果找到这样的节点,一个或多个优先级较低的 Pod 会被从节点中驱逐。 被驱逐的 Pod 消失后,P 可以被调度到该节点上。
用户暴露的信息
当 Pod P 抢占节点 N 上的一个或多个 Pod 时, Pod P 状态的 nominatedNodeName 字段被设置为节点 N 的名称。 该字段帮助调度程序跟踪为 Pod P 保留的资源,并为用户提供有关其集群中抢占的信息。
请注意,Pod P 不一定会调度到“被提名的节点(Nominated Node)”。 调度程序总是在迭代任何其他节点之前尝试“指定节点”。 在 Pod 因抢占而牺牲时,它们将获得体面终止期。 如果调度程序正在等待牺牲者 Pod 终止时另一个节点变得可用, 则调度程序可以使用另一个节点来调度 Pod P。 因此,Pod 规约中的 nominatedNodeName 和 nodeName 并不总是相同。 此外,如果调度程序抢占节点 N 上的 Pod,但随后比 Pod P 更高优先级的 Pod 到达, 则调度程序可能会将节点 N 分配给新的更高优先级的 Pod。 在这种情况下,调度程序会清除 Pod P 的 nominatedNodeName。 通过这样做,调度程序使 Pod P 有资格抢占另一个节点上的 Pod。
指定节点和实际节点可能不一致,原因:在指点节点的体面终止值存在更合适的点(时间来的更早)
抢占的限制
被抢占牺牲者的体面终止
当 Pod 被抢占时,牺牲者会得到他们的 体面终止期。 它们可以在体面终止期内完成工作并退出。如果它们不这样做就会被杀死。 这个体面终止期在调度程序抢占 Pod 的时间点和待处理的 Pod § 可以在节点 (N) 上调度的时间点之间划分出了一个时间跨度。 同时,调度器会继续调度其他待处理的 Pod。当牺牲者退出或被终止时, 调度程序会尝试在待处理队列中调度 Pod。 因此,调度器抢占牺牲者的时间点与 Pod P 被调度的时间点之间通常存在时间间隔。 为了最小化这个差距,可以将低优先级 Pod 的体面终止时间设置为零或一个小数字。
支持 PodDisruptionBudget,但不保证
PodDisruptionBudget (PDB) 允许多副本应用程序的所有者限制因自愿性质的干扰而同时终止的 Pod 数量。 Kubernetes 在抢占 Pod 时支持 PDB,但对 PDB 的支持是基于尽力而为原则的。 调度器会尝试寻找不会因被抢占而违反 PDB 的牺牲者,但如果没有找到这样的牺牲者, 抢占仍然会发生,并且即使违反了 PDB 约束也会删除优先级较低的 Pod。
与低优先级 Pod 之间的 Pod 间亲和性
只有当这个问题的答案是肯定的时,才考虑在一个节点上执行抢占操作: “如果从此节点上删除优先级低于悬决 Pod 的所有 Pod,悬决 Pod 是否可以在该节点上调度?”
说明:
抢占并不一定会删除所有较低优先级的 Pod。 如果悬决 Pod 可以通过删除少于所有较低优先级的 Pod 来调度, 那么只有一部分较低优先级的 Pod 会被删除。 即便如此,上述问题的答案必须是肯定的。 如果答案是否定的,则不考虑在该节点上执行抢占。
如果悬决 Pod 与节点上的一个或多个较低优先级 Pod 具有 Pod 间亲和性, 则在没有这些较低优先级 Pod 的情况下,无法满足 Pod 间亲和性规则。 在这种情况下,调度程序不会抢占节点上的任何 Pod。 相反,它寻找另一个节点。调度程序可能会找到合适的节点, 也可能不会。无法保证悬决 Pod 可以被调度。
我们针对此问题推荐的解决方案是仅针对同等或更高优先级的 Pod 设置 Pod 间亲和性。
悬挂 Pod 具有 Pod 间亲和性规则:悬挂 Pod 与某些较低优先级的 Pod 具有 Pod 间亲和性规则,意味着它希望与这些 Pod 共同存在于同一节点上。
跨节点抢占
假设正在考虑在一个节点 N 上执行抢占,以便可以在 N 上调度待处理的 Pod P。 只有当另一个节点上的 Pod 被抢占时,P 才可能在 N 上变得可行。 下面是一个例子:
- 调度器正在考虑将 Pod P 调度到节点 N 上。
- Pod Q 正在与节点 N 位于同一区域的另一个节点上运行。
- Pod P 与 Pod Q 具有 Zone 维度的反亲和(
topologyKey:topology.kubernetes.io/zone)设置。 - Pod P 与 Zone 中的其他 Pod 之间没有其他反亲和性设置。
- 为了在节点 N 上调度 Pod P,可以抢占 Pod Q,但调度器不会进行跨节点抢占。 因此,Pod P 将被视为在节点 N 上不可调度。
如果将 Pod Q 从所在节点中移除,则不会违反 Pod 间反亲和性约束, 并且 Pod P 可能会被调度到节点 N 上。
如果有足够的需求,并且如果我们找到性能合理的算法, 我们可能会考虑在未来版本中添加跨节点抢占。
Pod P 与 Pod Q 具有 Zone 维度的反亲和性:这表示 Pod P 和 Pod Q 不希望在同一 Zone 中运行。这可能是为了提高容错性,确保它们在不同的可用性区域运行,以防发生某种故障。
故障排除
Pod 优先级和抢占可能会产生不必要的副作用。以下是一些潜在问题的示例以及处理这些问题的方法。
Pod 被不必要地抢占
抢占在资源压力较大时从集群中删除现有 Pod,为更高优先级的悬决 Pod 腾出空间。 如果你错误地为某些 Pod 设置了高优先级,这些无意的高优先级 Pod 可能会导致集群中出现抢占行为。 Pod 优先级是通过设置 Pod 规约中的 priorityClassName 字段来指定的。 优先级的整数值然后被解析并填充到 podSpec 的 priority 字段。
为了解决这个问题,你可以将这些 Pod 的 priorityClassName 更改为使用较低优先级的类, 或者将该字段留空。默认情况下,空的 priorityClassName 解析为零。
当 Pod 被抢占时,集群会为被抢占的 Pod 记录事件。只有当集群没有足够的资源用于 Pod 时, 才会发生抢占。在这种情况下,只有当悬决 Pod(抢占者)的优先级高于受害 Pod 时才会发生抢占。 当没有悬决 Pod,或者悬决 Pod 的优先级等于或低于牺牲者时,不得发生抢占。 如果在这种情况下发生抢占,请提出问题。
有 Pod 被抢占,但抢占者并没有被调度
当 Pod 被抢占时,它们会收到请求的体面终止期,默认为 30 秒。 如果受害 Pod 在此期限内没有终止,它们将被强制终止。 一旦所有牺牲者都离开,就可以调度抢占者 Pod。
在抢占者 Pod 等待牺牲者离开的同时,可能某个适合同一个节点的更高优先级的 Pod 被创建。 在这种情况下,调度器将调度优先级更高的 Pod 而不是抢占者。
这是预期的行为:具有较高优先级的 Pod 应该取代具有较低优先级的 Pod。
优先级较高的 Pod 在优先级较低的 Pod 之前被抢占
调度程序尝试查找可以运行悬决 Pod 的节点。如果没有找到这样的节点, 调度程序会尝试从任意节点中删除优先级较低的 Pod,以便为悬决 Pod 腾出空间。 如果具有低优先级 Pod 的节点无法运行悬决 Pod, 调度器可能会选择另一个具有更高优先级 Pod 的节点(与其他节点上的 Pod 相比)进行抢占。 牺牲者的优先级必须仍然低于抢占者 Pod。
当有多个节点可供执行抢占操作时,调度器会尝试选择具有一组优先级最低的 Pod 的节点。 但是,如果此类 Pod 具有 PodDisruptionBudget,当它们被抢占时, 则会违反 PodDisruptionBudget,那么调度程序可能会选择另一个具有更高优先级 Pod 的节点。
当存在多个节点抢占且上述场景均不适用时,调度器会选择优先级最低的节点。
Pod 优先级和服务质量之间的相互作用
Pod 优先级和 QoS 类 是两个正交特征,交互很少,并且对基于 QoS 类设置 Pod 的优先级没有默认限制。 调度器的抢占逻辑在选择抢占目标时不考虑 QoS。 抢占会考虑 Pod 优先级并尝试选择一组优先级最低的目标。 仅当移除优先级最低的 Pod 不足以让调度程序调度抢占式 Pod, 或者最低优先级的 Pod 受 PodDisruptionBudget 保护时,才会考虑优先级较高的 Pod。
kubelet 使用优先级来确定 节点压力驱逐 Pod 的顺序。 你可以使用 QoS 类来估计 Pod 最有可能被驱逐的顺序。kubelet 根据以下因素对 Pod 进行驱逐排名:
- 对紧俏资源的使用是否超过请求值
- Pod 优先级
- 相对于请求的资源使用量
有关更多详细信息,请参阅 kubelet 驱逐时 Pod 的选择。
当某 Pod 的资源用量未超过其请求时,kubelet 节点压力驱逐不会驱逐该 Pod。 如果优先级较低的 Pod 的资源使用量没有超过其请求,则不会被驱逐。 另一个优先级较高且资源使用量超过其请求的 Pod 可能会被驱逐。
Node
Node 的状态
Node 包括如下状态信息:
- Address
- HostName:可以被 kubelet 中的
--hostname-override参数替代。 - ExternalIP:可以被集群外部路由到的 IP 地址。
- InternalIP:集群内部使用的 IP,集群外部无法访问。
- HostName:可以被 kubelet 中的
- Condition
- OutOfDisk:磁盘空间不足时为
True - Ready:Node controller 40 秒内没有收到 node 的状态报告为
Unknown,健康为True,否则为False。 - MemoryPressure:当 node 有内存压力时为
True,否则为False。 - DiskPressure:当 node 有磁盘压力时为
True,否则为False。
- OutOfDisk:磁盘空间不足时为
- Capacity
- CPU
- 内存
- 可运行的最大 Pod 个数
- Info:节点的一些版本信息,如 OS、kubernetes、docker 等
Node 管理
禁止 Pod 调度到该节点上。
kubectl cordon <node>
驱逐该节点上的所有 Pod。
kubectl drain <node>
该命令会删除该节点上的所有 Pod(DaemonSet 除外),在其他 node 上重新启动它们,通常该节点需要维护时使用该命令。直接使用该命令会自动调用kubectl cordon <node>命令。当该节点维护完成,启动了 kubelet 后,再使用kubectl uncordon <node> 即可将该节点添加到 kubernetes 集群中。
问题
删除了node怎么重新加入
-
Docker 容器运行时未启动:
错误信息中显示Cannot connect to the Docker daemon at unix:///var/run/docker.sock. Is the docker daemon running?,这表明 Docker 容器运行时未启动。 -
kubelet 配置文件已存在:
错误信息中显示/etc/kubernetes/kubelet.conf already exists,这表示 kubelet 配置文件已经存在,可能是由于之前的加入尝试导致的。 -
启动 Docker 服务:
systemctl start docker.service systemctl enable docker.service -
删除已存在的 kubelet 配置文件:
sudo rm /etc/kubernetes/kubelet.conf -
重置节点,删除 Kubernetes 相关配置和数据
kubeadm reset -
在
maste查看加入加入命令node执行 kubeadm 加入命令:kubeadm token create --print-join-command #查看命令 kubeadm join 192.168.2.210:6443 --token l2kvho.a4qottxzcnuzm99x --discovery-token-ca-cert-hash sha256:6253b7c03d20c41bcaa1585740168ba76deea54ddbc7f2c6ec71d636acb34bca
执行了上面的命令最开始都事好的,随后就NotReady了
[root@k8smaster1 ~]# kubectl get node
NAME STATUS ROLES AGE VERSION
k8smaster Ready control-plane,master 3h38m v1.20.6
k8snode1 NotReady worker 8m11s v1.20.6
k8snode2 Ready worker 3h27m v1.20.6
问题所在
[root@k8smaster1 ~]# kubectl get pod -n kube-system
NAME READY STATUS RESTARTS AGE
calico-kube-controllers-6949477b58-5g9g9 1/1 Running 0 3h25m
calico-node-762tq 0/1 Running 0 3h25m
calico-node-s794v 0/1 CrashLoopBackOff 59 3h25m
calico-node-vkbt6 0/1 Running 0 15m
coredns-7f89b7bc75-69kjz 1/1 Running 0 16m
coredns-7f89b7bc75-zkdrw 1/1 Running 0 3h45m
etcd-k8smaster 1/1 Running 0 3h45m
kube-apiserver-k8smaster 1/1 Running 0 3h45m
kube-controller-manager-k8smaster 1/1 Running 0 3h45m
kube-proxy-2jbvz 1/1 Running 0 3h45m
kube-proxy-794kj 1/1 Running 0 15m
kube-proxy-g4g2f 1/1 Running 0 3h34m
kube-scheduler-k8smaster 1/1 Running 0 3h45m
如何回滚k8s升级的问题?降级k8s
CentOS软件降级操作如下:
首先查看软件升级的事务ID:
yum history list all
根据ID查看变更的内容:
yum history info ID
确认ID确认,执行回滚操作:
yum history undo ID[root@k8smaster ~]# yum history info 6
已加载插件:fastestmirror
事务 ID: 6
起始时间 : Thu Mar 23 17:22:20 2023
启动 RPM 数据库 : 432:d9b0370070fa41485e6e95bcd666c64590af68c2
结束时间 : 17:22:31 2023 (11 秒)
结束 RPM 数据库 : 437:0c6f05ddaaf2432092702713a3fbbf0eea054b29
用户 : root
返回码 : 成功
命令行 : install -y kubelet-1.20.6 kubeadm-1.20.6 kubectl-1.20.6
事务完成属主:
已安装 rpm-4.11.3-45.el7.x86_64 @anaconda
已安装 yum-3.4.3-168.el7.centos.noarch @anaconda
已安装 yum-metadata-parser-1.1.4-10.el7.x86_64 @anaconda
已安装 yum-plugin-fastestmirror-1.1.31-54.el7_8.noarch @anaconda
已变更的包:
依赖安装 cri-tools-1.26.0-0.x86_64 @kubernetes
安装 kubeadm-1.20.6-0.x86_64 @kubernetes
安装 kubectl-1.20.6-0.x86_64 @kubernetes
安装 kubelet-1.20.6-0.x86_64 @kubernetes
依赖安装 kubernetes-cni-1.2.0-0.x86_64 @kubernetes
history info