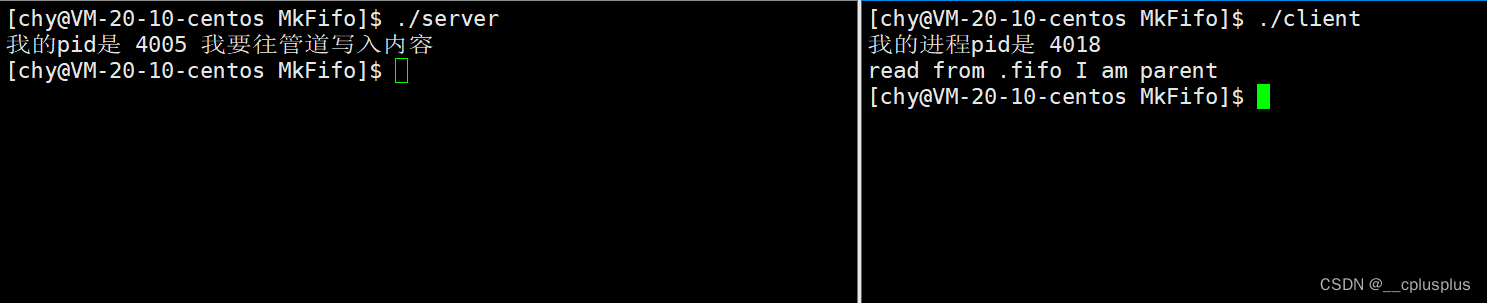
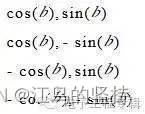并发线程池示例(两个示例程序分别用线程 及java自带程池执行一样的程序查看时间):
public class ThreadTest {
public static void main(String[] args) throws InterruptedException {
Long start = System.currentTimeMillis();
final Random random = new Random();
final List<Integer> list = new ArrayList<>();
//循环10万次 创建了 10万零一个线程
for (int i = 0; i < 100000; i++) {
Thread thread = new Thread() {
@Override
public void run() {
list.add(random.nextInt());
}
};
thread.start();
thread.join();
}
//用8秒
System.out.println("花费的时间"+(System.currentTimeMillis()-start));
System.out.println("list大小"+list.size());
}
}
public class ThreadPoolTest {
public static void main(String[] args) throws InterruptedException {
Long start =System.currentTimeMillis();
final Random random = new Random();
final List<Integer> list = new ArrayList<>();
//java自带的线程池
ExecutorService executorService = Executors.newSingleThreadExecutor();
//这里也创建了10w个对象,但是这里只创建了两个线程
for (int i = 0; i < 100000; i++) {
executorService.execute(
new Runnable() {
@Override
public void run() {
list.add(random.nextInt());
}
}
);
}
executorService.shutdown();
executorService.awaitTermination(1, TimeUnit.DAYS);
//用25毫秒
System.out.println("花费时间:"+(System.currentTimeMillis()-start));
System.out.println("list大小:"+list.size());
}
}这里为什么创建了10w的对象 只创建了两个线程,因为都是调用的run方法,run()和start方式启动是不一样的;
示例:
public class ThreadDemo extends Thread{
private String name;
public ThreadDemo(String name){
this.name=name;
}
@Override
public void run() {
System.out.println(name);
}
public static void main(String[] args) {
//方法调用
// new ThreadDemo("eric").run();
//线程启动
new ThreadDemo("lily").start();
//线程的名字不一样
}如果调用run方法是调用自己重写的run方法,只有一个线程,debug快照可对比:
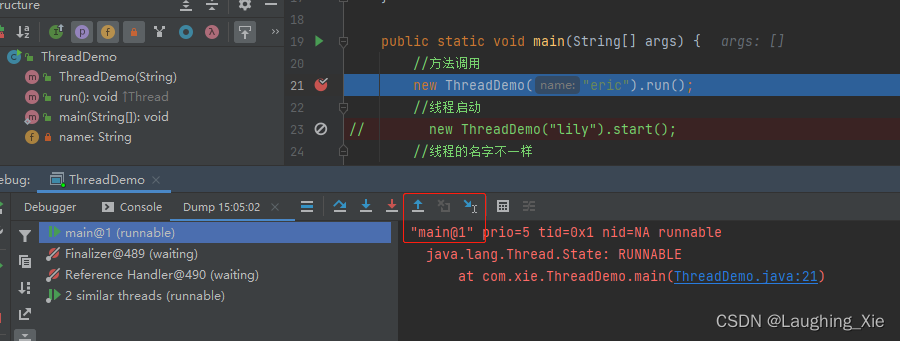
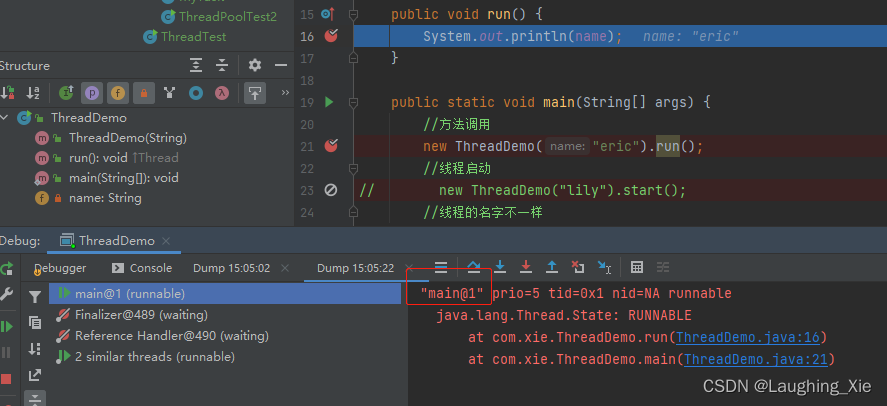
start()启动是调用另一个线程
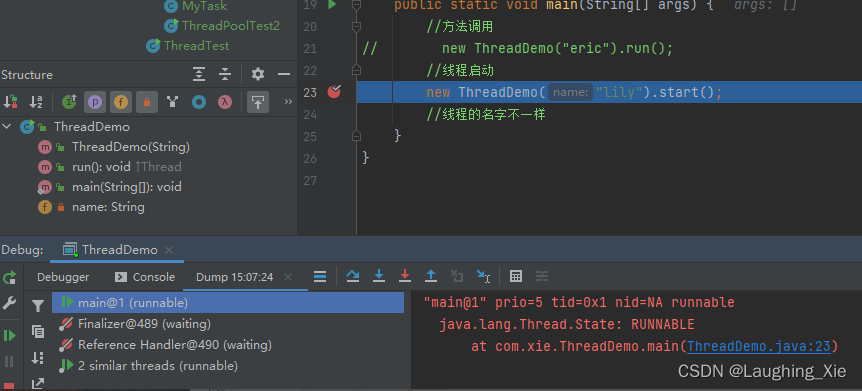
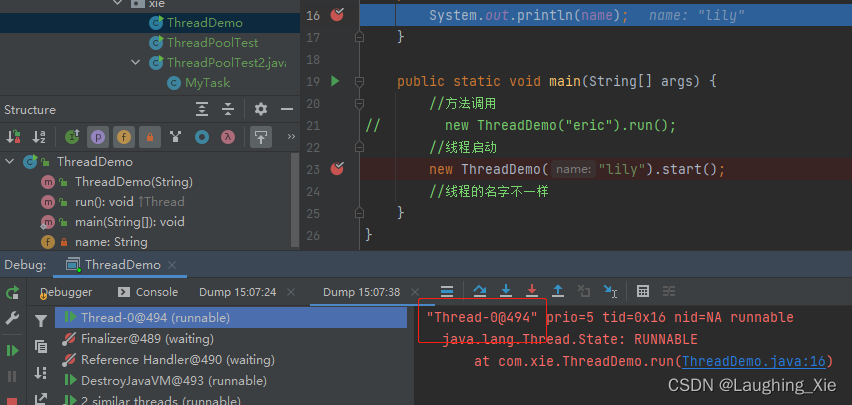
线程池底层很多是run()方法的调用,这也是为什么线程池相对而言更快一点的原因。
从1.5开始的,针对java线程池的工具类
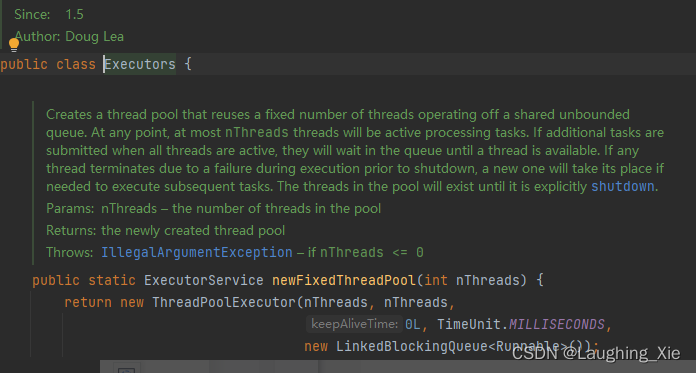

并不是只要用线程池就一定是最快的,例子如下:
ublic class ThreadPoolTest2 {
//一般不推荐用java自带工具类写线程池
public static void main(String[] args) {
//快
ExecutorService executorService1 = Executors.newCachedThreadPool();
//比上面的慢 一共用10个线程去执行那100个任务
ExecutorService executorService2 = Executors.newFixedThreadPool(10);
//最慢的 线程池用一个线程去执行这100个任务
ExecutorService executorService3 = Executors.newSingleThreadExecutor();
//执行了100个项目 每个项目需要执行三秒,分别用这三种线程池去执行
for (int i = 0; i < 100; i++) {
// executorService1.execute(new MyTask(i));
// executorService2.execute(new MyTask(i));
executorService3.execute(new MyTask(i));
}
}
}
/**
* 项目
*/
class MyTask implements Runnable {
int i;
public MyTask(int i) {
this.i = i;
}
@Override
public void run() {
System.out.println(Thread.currentThread().getName()+"做的第"+i+"个项目");
//业务逻辑执行3秒
try {
Thread.sleep(3000L);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
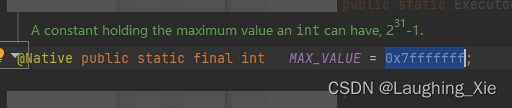
MAX_VALUE:
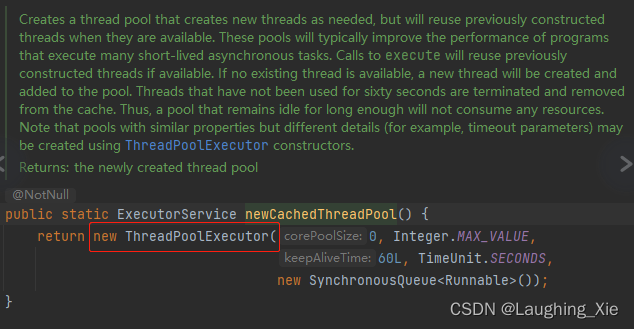
核心线程数:0,任务进来后是没有核心线程去做的
会用临时线程去做,目前最大线程数是:MAX_VALUE
任务进来后,由于没有核心线程,所以会先放到工作队列里面workQueue中,这里用的SynchronousQueue<Runnable> 同步队列(典型的生产消费方式),当放了一个任务进来后,就需要消费掉,否则后面的任务没法放进来,相当于只能存一个对象进来,存一个对象进来后,就需要有临时线程去进行消费,执行此任务。
当把任务执行时间注释掉,
就会出现线程复用的情况
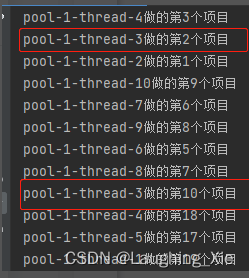
由于项目执行很快,一个线程可以做多个任务。这种线程池相对于其他线程池容易造成CPU100%问题,因为最大线程数没有限制
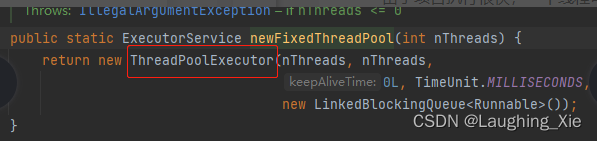
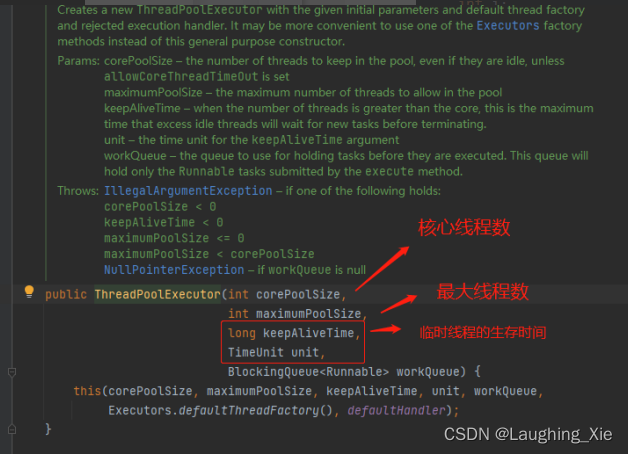
这里用的核心线程数为10,最大线程数也为10(意味着没有临时线程),临时线程存活时间为0,用了无界队列(队列的结构特点是FIFO),这个队列无限大可以接收N个任务放里面
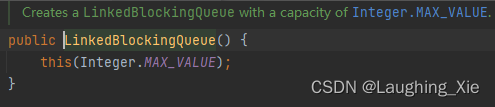
只有10个线程去处理任务
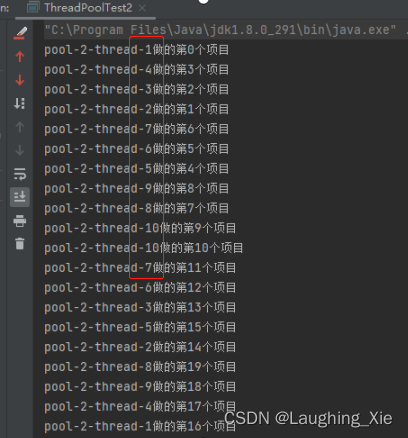
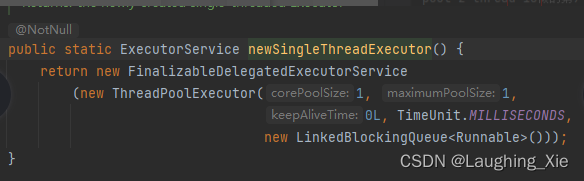
只有1个核心线程,最大线程也是1,无界队列,始终只有一个线程去执行任务。
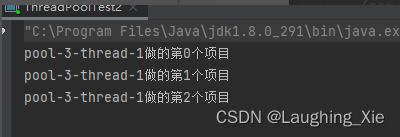
是否需要用线程池,及用哪种线程池,取决于我们项目执行时间的长短
一般都用自定义线程池,可自行规定参数
//自定义线程池 队列指定容量10 额外多出的临时线程生命周期为1秒
ThreadPoolExecutor threadPoolExecutor = new ThreadPoolExecutor(10,20,
0L, TimeUnit.MILLISECONDS, new LinkedBlockingQueue<>(10)); 
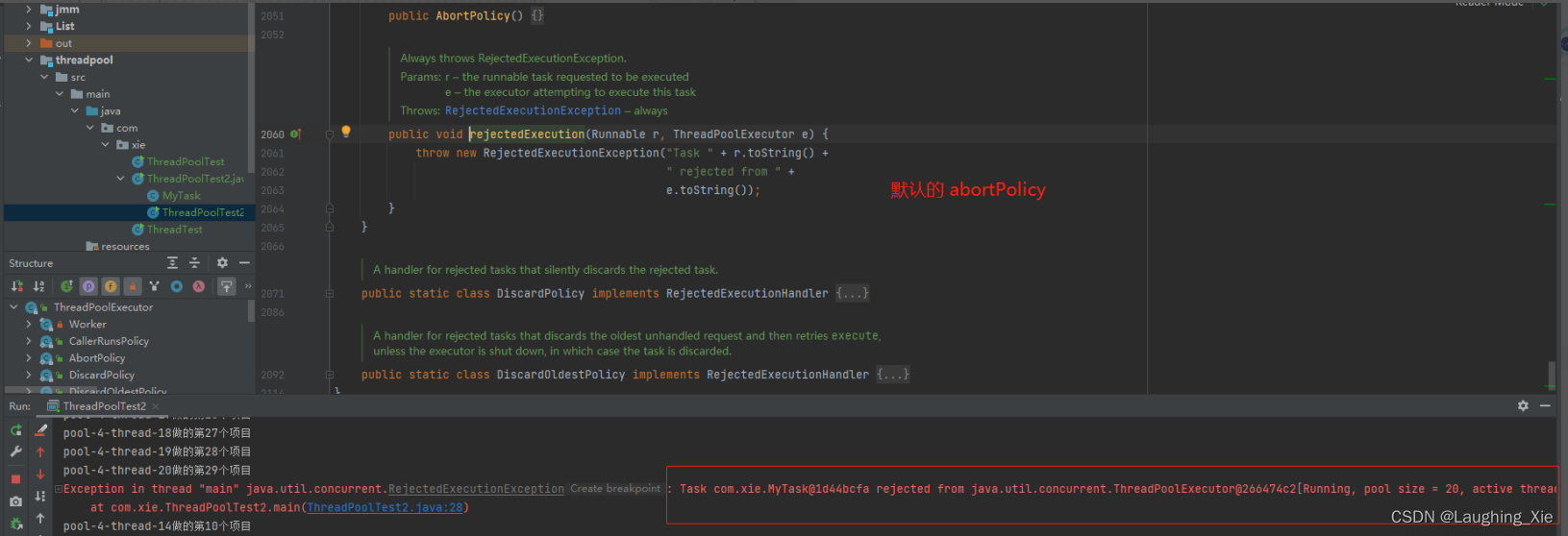
执行任务的时候,有自己的执行逻辑,30个任务后,拒绝了,最后线程执行队列里面剩余的任务。这里是执行优先级,优先核心、非核心 获取任务执行,都没有 才从队列里面获取任务去进行执行
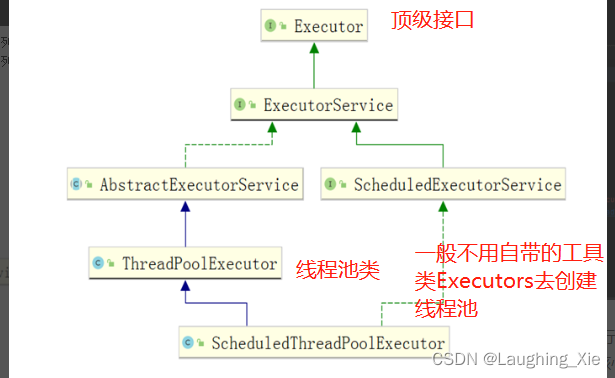
Executor顶级接口只有一个execute方法,没有返回值,

AbstractExecutorService 实现了接口
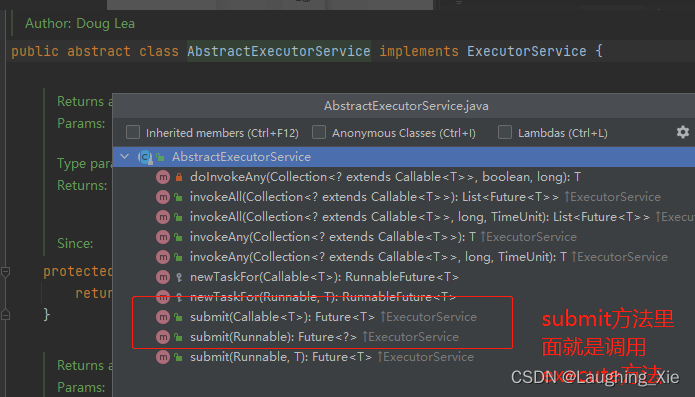

submit方法调用了execute执行方法,同时有返回值 这也是跟execute方法的一个区别
我们自定义的线程池ThreadPoolExecutor继承自AbstractExecutorService
底层执行原理:
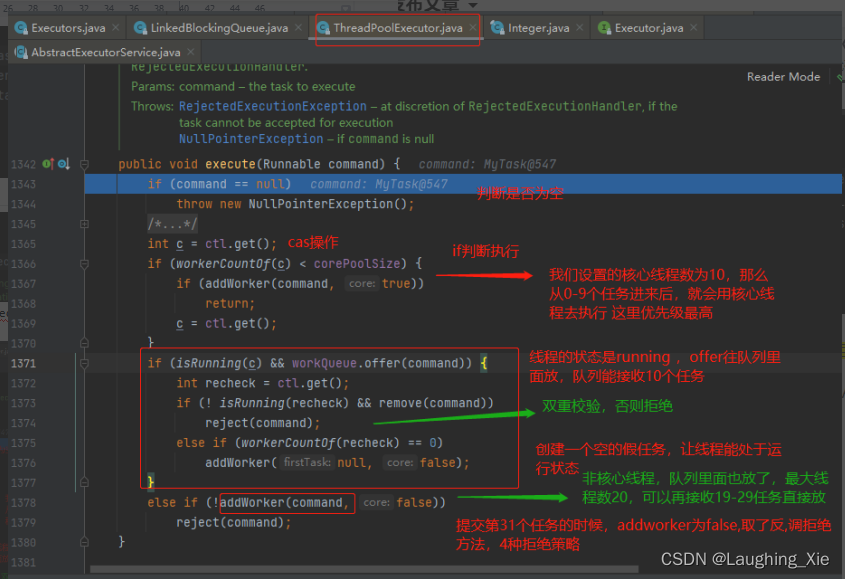
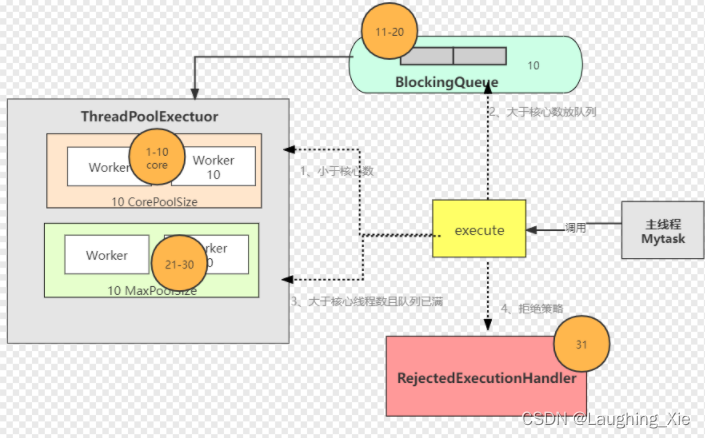
线程池处理流程:
自带拒绝策略:
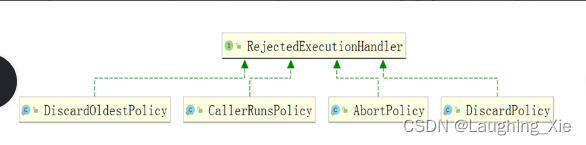
ThreadPoolExecutor内部有实现4个拒绝策略:
(1)CallerRunsPolicy,由调用execute方法提交任务的线程来执行这个任务;
(2)AbortPolicy,抛出异常RejectedExecutionException拒绝提交任务;
(3)DiscardPolicy,直接抛弃任务,不做任何处理;
(4)DiscardOldestPolicy,去除任务队列中的第一个任务(最旧的),重新提交;
一般都是自定义拒绝策略。