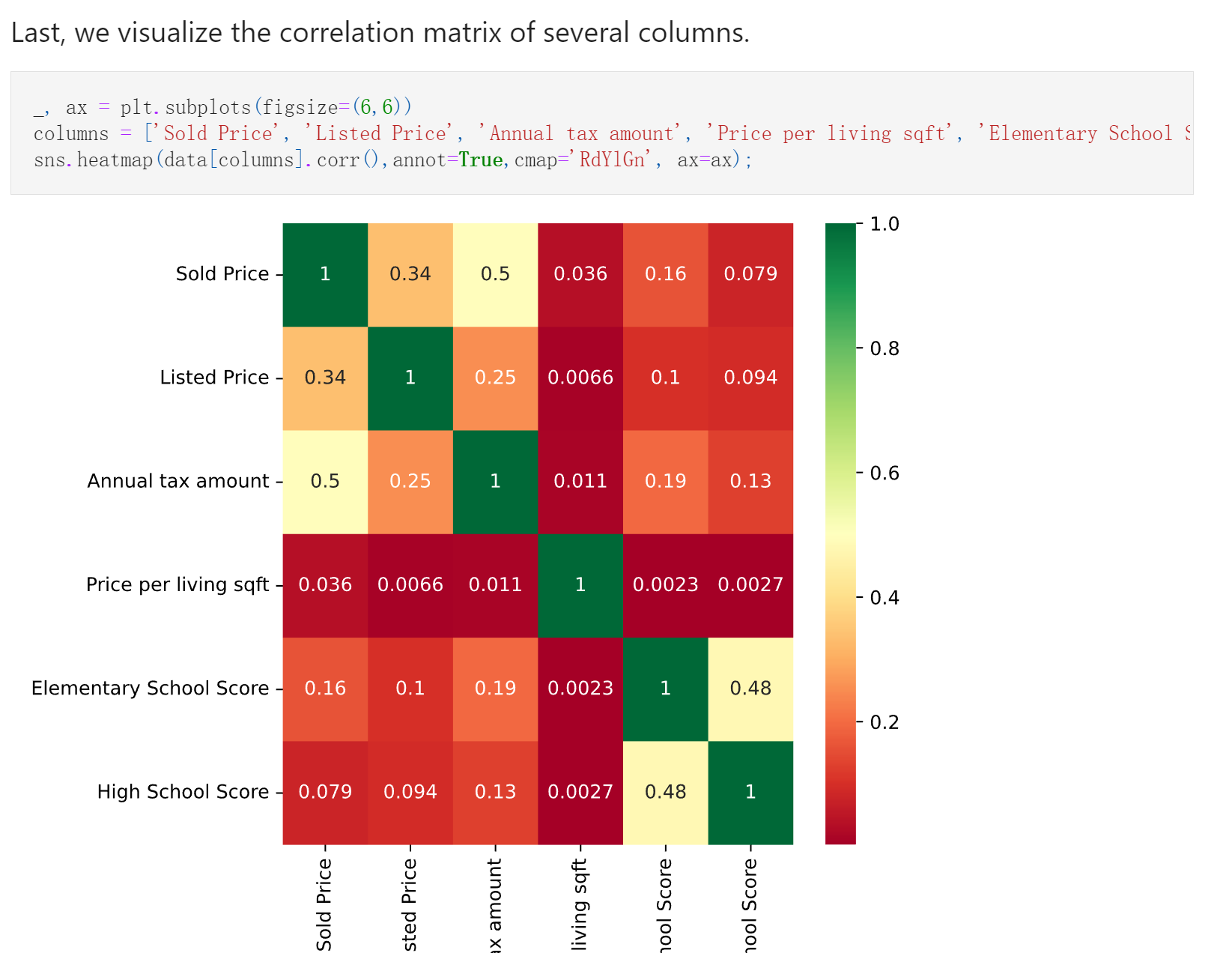
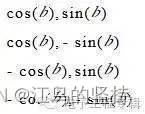点云 3D 分割 - SqueezeSegV2(ICRA 2019)
- 摘要
- 1. 引言
- 2. 相关工作
- 3. 改进模型结构
- A. 上下文聚合模块
- B. 焦点损失
- C. 其他改进
- 4. 领域适应训练
- A. GTA-LiDAR数据集
- B. 学习强度渲染
- C. 测地相关对齐
- D. 渐进域校准
- 5. 实验
- A. 实验设置
- B. 改进的模型结构
- C. 域适配管道
- 6. 结论
- REFERENCES
声明:此翻译仅为个人学习记录
文章信息
- 标题:SqueezeSegV2: Improved Model Structure and Unsupervised Domain Adaptation for Road-Object Segmentation from a LiDAR Point Cloud (ICRA 2019)
- 作者:Bichen Wu*, Xuanyu Zhou*, Sicheng Zhao*, Xiangyu Yue, Kurt Keutzer ( * Authors contributed equally)
- 文章链接:https://arxiv.org/pdf/1809.08495v1.pdf
- 文章代码:https://github.com/xuanyuzhou98/SqueezeSegV2
摘要
早期的工作证明了基于深度学习的点云分割方法的前景;然而,这些方法需要改进,以使其实用。为此,我们引入了一个新模型SquezeSegV2,它对LiDAR点云中的脱落噪声更为鲁棒。通过改进的模型结构、训练损失、批量标准化和额外的输入通道,SquezeSegV2在实际数据上训练时实现了显著的准确性提高。用于点云分割的训练模型需要大量标记的点云数据,这很难获得。为了避免收集和注释的成本,可以使用GTA-V等模拟器来创建无限量的标记合成数据。然而,由于领域转移,基于合成数据训练的模型通常不能很好地推广到现实世界。我们使用由三个主要组件组成的域自适应训练管道来解决这个问题:1)学习强度渲染,2)测地相关对齐,和3)渐进域校准。当在真实数据上进行训练时,我们的新模型显示出比原始SquezeSeg提高6.0-8.6%的分割精度。当使用所提出的领域自适应管道在合成数据上训练我们的新模型时,我们对真实世界数据的测试精度几乎翻倍,从29.0%提高到57.4%。我们的源代码和合成数据集将是开源的。
1. 引言
对环境的准确、实时和鲁棒感知是自动驾驶系统中不可或缺的组成部分。对于高端自动驾驶汽车的感知,LiDAR(光探测和测距)传感器发挥着重要作用。LiDAR传感器可以直接提供距离测量,其分辨率和视野超过雷达和超声波传感器[1]。LiDAR传感器在几乎所有的照明条件下都是鲁棒的:白天或夜晚,有或没有眩光和阴影[2]。因此,基于激光雷达的感知已经引起了重大的研究关注。
最近,深度学习被证明对激光雷达感知任务非常有效。具体地说,Wu等人提出了SquezeSeg[2],它专注于点云分割问题。SquezeSeg将3D LiDAR点云投影到球面上,并使用2D CNN预测点云的逐点标签。SquezeSeg非常高效——最快的版本可以达到每秒100帧以上的推理速度。然而,SquezeSeg仍然有几个局限性:首先,它的精度仍然需要提高,才能实际使用。精度下降的一个重要原因是脱落噪声——由有限的传感范围、传感激光的镜面扩散或入射角抖动引起的传感点云中的缺失点。这种脱落噪声会破坏SquezeSeg早期层的输出,从而降低精度。第二,训练SquezeSeg等深度学习模型需要数万个标记的点云;然而,收集和注释这些数据甚至比从相机收集相当的数据更耗时和昂贵。GTAV用于合成LiDAR点云,作为训练数据的额外来源[2];然而,这种方法存在域转移问题[3]-在合成数据上训练的模型通常在真实数据上灾难性地失败,如图1所示。域移位来自不同的源,但GTA-V中没有脱落噪声和强度信号是两个重要因素。模拟真实的脱落噪声和强度非常困难,因为它需要对LiDAR设备和环境进行复杂的建模,这两者都包含大量非确定性因素。因此,GTA-V生成的LiDAR点云不包含脱落噪声和强度信号。模拟数据与实际数据的比较如图1(a),(b)所示。

图1. 域转移的一个例子。将点云投影到球形表面上进行可视化(红色为汽车,蓝色为行人)。我们的领域自适应流水线改进了从(c)到(d)的分段,同时对合成数据进行了训练。
在本文中,我们着重于应对上述挑战。首先,为了提高准确性,我们通过提出上下文聚合模块(CAM)来减轻脱落噪声的影响,这是一种新的CNN模块,它聚合来自更大感受野的上下文信息,并提高网络对脱落噪声的鲁棒性。将CAM添加到SquezeSegV2的早期层中,不仅显著提高了在真实数据上训练时的性能,还有效地减少了域差距,提高了在合成数据上训练的网络的真实世界测试精度。除了CAM,我们对SquezeSeg进行了几项改进,包括使用焦点损失[4]、批量归一化[5]和LiDAR掩模作为输入通道。这些改进一起将转换后的KITTI数据集上所有类别的SquezeSegV2的准确性提高了6.0%-8.6%[2]。
第二,为了更好地利用合成数据来训练模型,我们提出了一种域自适应训练流水线,该流水线包含以下步骤:首先,在训练之前,我们通过学习的强度渲染在合成数据中渲染强度通道。我们训练一个以点坐标为输入的神经网络,并预测强度值。该渲染网络可以在未标记的真实数据上以“自我监督”的方式进行训练。训练网络后,我们将合成数据输入网络,并渲染原始模拟中缺少的强度通道。其次,我们使用增强了渲染强度的合成数据来训练网络。同时,我们遵循[6],并使用测地相关对齐来对齐真实数据和合成数据之间的批次统计。3) 在训练之后,我们提出渐进域校准,以进一步减少目标域和训练网络之间的差距。实验表明,上述领域自适应训练流水线在真实世界测试数据上显著提高了用合成数据训练的模型的准确性,从29.0%提高到57.4%。
本文的贡献有三方面:1)我们用CAM改进了SquezeSeg的模型结构,以提高其对脱落噪声的鲁棒性,这导致不同类别的准确度显著提高6.0%至8.6%。我们将新模型命名为SquezeSegV2。2) 我们提出了一种领域自适应训练管道,该管道显著减少了合成数据和真实数据之间的分布差距。在合成数据上训练的模型比实际测试数据的精度提高了28.4%。3) 我们创建了一个大规模的3D激光雷达点云数据集GTA-LiDAR,它由100000个合成点云样本组成,并增强了渲染强度。源代码和数据集将是开源的。
2. 相关工作
3D LiDAR点云分割旨在通过预测逐点标签从点云中识别目标。非深度学习方法[1]、[7]、[8]通常涉及几个阶段,如地面移除、聚类和分类。SquezeSeg[2]是将深度学习应用于这个问题的一项早期工作。Piewak等人[9]采用了与SquezeSeg类似的问题阐述方式和管道,并提出了一种称为LiLaNet的新网络架构。他们利用基于图像的语义分割为LiDAR点云生成标签,从而创建了一个数据集。然而,数据集没有发布,因此我们无法与他们的工作进行直接比较。另一类方法基于PointNet[10],[11],它将点云视为一组无序的3D点。这对于诸如分类和分割之类的3D感知问题是有效的。受限于其计算复杂性;然而,PointNet主要用于处理点数有限的室内场景。Frustum PointNet[12]被提出用于室外目标检测,但它依赖于图像对象检测来首先定位对象簇,并将簇(而不是整个点云)馈送到PointNet。
无监督域适配(UDA)旨在将模型从一个标记的源域适配到另一个未标记的目标域。最近的UDA方法专注于传递深度神经网络表示[13],[14]。通常,深度UDA方法使用具有两个流的联合架构来分别表示源域和目标域的模型。除了根据标记的源数据计算的任务相关损失外,深度UDA模型通常与另一损失一起训练,例如差异损失[15]、[16]、[17]、[18]、[6]、对抗性损失[19]、[20]、[21]、[22]、[23]、[24]、标记分布损失[18]或重建损失[25]、[26]。
最相关的工作是对合成数据的探索[22],[18],[24]。通过实施自正则化损失,Shrivastava等人[22]提出了SimGAN,以使用未标记的真实数据提高合成数据的真实性。另一类相关工作采用差异损失[15],[16],[17],[6],其明确地测量了两个网络流的相应激活层上的源域和目标域之间的差异。我们尝试通过一种新的适应管道来适应合成的3D激光雷达点云,而不是处理2D图像。
模拟最近被用于创建用于训练目的的大规模真值数据。Richter等人[27]提供了一种为合成游戏图像提取语义分割的方法。在[28]中,相同的游戏引擎用于提取图像中对象的真值2D边界框。Yue等人[29]提出了一种生成合成LiDAR点云的框架。Richter等人[30]和Kr¨ahenb¨uhl[31]从视频游戏中提取了更多类型的信息。
3. 改进模型结构
我们提出了SqueezeSegV2,通过改进基础SqueezSeg模型,添加上下文聚合模块(CAM),添加LiDAR掩模作为输入通道,使用批量归一化[5],并采用焦点损失[4]。SquezeSegV2的网络结构如图2所示。
A. 上下文聚合模块
LiDAR点云数据包含许多缺失点,我们称之为脱落噪声,如图1(b)所示。衰减噪声主要由1)有限的传感器范围,2)传感激光器在光滑表面上的镜面反射(而不是扩散反射),以及3)入射角的抖动引起。脱落噪声对SquezeSeg有重大影响,尤其是在网络的早期层。在卷积滤波器的接收场非常小的早期层,小邻域中的缺失点会严重破坏滤波器的输出。为了说明这一点,我们进行了一个简单的数值实验,其中我们随机采样输入张量,并将其输入到3×3卷积滤波器中。我们从输入张量中随机丢弃一些像素,如图4所示,随着丢弃概率的增加,受损输出和原始输出之间的误差也会增加。

图2. 用于从3D LiDAR点云分割道路目标的SqueezeSegV2模型的网络结构。

图3. 上下文聚合模块的结构。

图4. 我们将一个随机张量输入卷积滤波器,一个在3×3卷积滤波器之前具有CAM,另一个没有CAM。我们随机地在输入端加入脱落噪声,并测量输出误差。当我们增加丢失概率时,误差也会增加。对于所有丢失概率,添加CAM提高了对丢失噪声的鲁棒性,因此,误差总是较小。
这个问题不仅影响在真实数据上训练时的SquezeSeg,而且还导致合成数据和真实数据之间存在严重的域差距,因为模拟来自相同分布的真实脱落噪声非常困难。
为了解决这个问题,我们提出了一种新的上下文聚合模块(CAM)来降低对脱落噪声的敏感性。如图3所示,CAM从具有相对较大内核大小的最大池开始。最大池聚合了像素周围的上下文信息,像素具有更大的感受野,并且它对其感受野中缺失的数据不太敏感。此外,即使内核大小较大,也可以有效地计算最大池。最大池化层之后是两个级联卷积层,其间有ReLU激活。在[32]之后,我们使用S形函数对模块的输出进行归一化,并使用元素乘法将输出与输入组合。如图4所示,所提出的模块对脱落噪声的敏感度要低得多——在相同的损坏输入数据下,误差显著降低。
在SquezeSegV2中,我们在前三个模块(1个卷积层和2个FireModules)的输出之后插入CAM,其中滤波器的接收场很小。从后面的实验中可以看出,CAM 1)在真实数据上训练时显著提高了准确性,2)在合成数据上训练和在真实数据测试时显著减少了域差距。
B. 焦点损失
LiDAR点云具有非常不平衡的点类别分布——背景点比前景对象(如汽车、行人等)多得多。这种不平衡的分布使得模型更加关注于易于分类的背景点,这些背景点没有提供有用的学习信号,而前景对象在训练期间没有得到充分处理。
为了解决这个问题,我们将SquezeSeg[2]的原始交叉熵损失替换为焦点损失[4]。焦点损失调制来自不同像素的损失贡献,并聚焦于困难的样本。对于给定的像素标签t和预测的pt概率,焦点损失[4]将调制因子(1−pt)γ添加到交叉熵损失中。因此,该像素的焦点损失

当像素被错误分类并且pt很小时,调制因子接近1,并且损失不受影响。作为pt→ 1,因子变为0,并且对分类良好的像素的损失进行下加权。聚焦参数γ平滑地调整了分类良好的样本向下加权的速率。当γ=0时,焦损相当于交叉熵损失。随着γ的增加,调制因子的作用也会增加。我们在实验中选择γ为2。
C. 其他改进
LiDAR掩模:除了原始(x、y、z、强度、深度)通道外,我们还添加了一个通道——一个二进制掩模,指示每个像素是否缺失或存在。正如我们从表1中看到的,添加掩模通道显著提高了骑车人的分割精度。
批归一化:与SquezeSeg[2]不同,我们还在每个卷积层之后添加批归一化(BN)[5]。BN层旨在缓解内部协变移位的问题,这是训练深度神经网络的常见问题。我们在表I中观察到使用BN层后汽车分割的改进。

图5. 用于从合成GTA-LiDAR数据集到真实世界KITTI数据集的道路目标分割的所提出的无监督域自适应方法的框架。
4. 领域适应训练
在本节中,我们将介绍我们的无监督域自适应流水线,该流水线在合成数据上训练SquezeSegV2,并提高其在真实数据上的性能。我们构建了一个大型3D激光雷达点云数据集GTA-LiDAR,在GTA-V上模拟了100000次激光雷达扫描。为了处理域偏移问题,我们采用了三种策略:学习强度渲染、测地相关对齐和渐进域校准,如图5所示。
A. GTA-LiDAR数据集
我们在GTA-V中合成了100000个LiDAR点云,以训练SquezeSegV2。我们使用[31]中的框架生成深度语义分割图,并使用[29]中的方法在GTA-V中进行图像LiDAR配准。在[29]之后,我们通过部署虚拟汽车在虚拟世界中自主驾驶,收集了100000个点云扫描。GTA-V提供了各种各样的场景、汽车类型、交通状况等,这确保了我们合成数据的多样性。合成点云中的每个点都包含一个标签、一个距离和x、y、z坐标。然而,它不包含代表反射激光信号大小的强度。此外,合成数据不包含真实数据中的脱落噪声。由于这种分布差异,基于合成数据训练的模型无法转换为真实数据。
B. 学习强度渲染
合成数据仅包含x、y、z和深度通道,没有强度。如SquezeSeg[2]所示,强度是一个重要的信号。缺乏强度会导致严重的精度损失。渲染真实的强度是一项非常重要的任务,因为影响强度的许多因素,例如表面材料和激光雷达灵敏度,我们通常都不知道。
为了解决这个问题,我们提出了一种称为学习强度渲染的方法。其想法是使用网络将点云的x、y、z、深度通道作为输入,并预测强度。这种渲染网络可以用未标记的LiDAR数据训练,只要LiDAR传感器可用,就可以容易地收集这些数据。如图5(a)所示,我们以自我监督的方式训练渲染网络,将x、y、z通道作为网络的输入,将强度通道作为标签。渲染网络的结构几乎与SquezeSeg相同,只是移除了CRF层。
强度渲染可以看作是一个回归问题,其中l2损失是一个自然选择。然而,l2无法捕捉强度的多模态分布——给定相同的x、y、z输入,强度可能不同。为了对这一特性进行建模,我们设计了一个包含分类和回归的混合损失函数。我们将强度划分为n=10个区域,每个区域都有一个参考强度值。网络首先预测强度属于哪个区域。一旦选择了该区域,网络进一步预测与参考强度的偏差。这样,分类预测可以捕获强度的多模态分布,而偏差预测导致更准确的估计。我们使用混合损失函数在KITTI[33]数据集上训练渲染网络,并使用均方误差(MSE)测量其精度。与l2损失相比,收敛MSE从0.033显著下降3倍至0.011。图6显示了使用两种不同损耗的几个渲染结果。训练渲染网络后,我们将合成GTA-LiDAR数据输入到网络中,以渲染逐点强度。
C. 测地相关对齐
渲染强度后,我们在具有焦点损失的合成数据上训练SquezeSegV2。然而,由于合成数据和真实数据之间的分布差异,训练后的模型通常无法推广到真实数据。
为了减少这种区域差异,我们在训练期间采用测地相关对齐。如图5(b)所示,在训练的每一步,我们向网络输入一批合成数据和一批真实数据。我们计算合成批次上的焦点损失,其中标签可用。同时,我们计算了两个批次的输出分布之间的测地线距离[6]。总损失现在包含焦点损失和测地线损失。当焦点损失集中于训练网络以从点云学习语义时,测地线损失惩罚来自两个域的批统计之间的差异。注意,其他距离(例如欧几里德距离)也可以用于对齐域统计。然而,我们选择测地线距离而不是欧几里德距离,因为它考虑了流形曲率。更多详情见[6]。

图6. 在KITTI数据集中渲染的v.s.真值强度。

我们将输入的合成数据表示为Xsim,合成标签表示为Ysim,将输入的真实数据表示为Xreal。我们的损失函数可以计算为

其中FL表示合成标签和网络预测之间的焦点损失,GL表示合成数据和真实数据的批次统计之间的测地线损失。λ是权重系数,我们在实验中将其设置为10。注意,在这一步中,我们只需要未标记的真实数据,只要LiDAR传感器可用,这比注释数据更容易获得。
D. 渐进域校准
在使用测地相关对齐对合成数据进行SquezeSegV2训练后,网络的每一层都学习从其输入中识别模式并提取更高级别的特征。然而,由于网络的非线性性质,只有当其输入被限制在一定范围内时,每个层才能正常工作。以ReLU函数为例,如果其输入分布以某种方式低于0,则ReLU的输出将全部为零。否则,如果输入移向大于0,则ReLU变为线性函数。对于具有多层的深度学习模型,来自输入数据的分布差异会导致每一层输出的分布偏移,这会在整个网络中累积甚至放大,最终导致性能严重下降,如图5(c)所示。
为了解决这个问题,我们采用了一种称为渐进域校准(PDC)的后训练程序。其思想是通过渐进的逐层校准来打破分布偏移在每个层中的传播。对于基于合成数据训练的网络,我们将真实数据输入网络。从第一层开始,我们计算给定输入下的输出统计(均值和方差),然后将输出的均值重新归一化为0,标准偏差为1,如图5(c)所示。同时,我们使用新的统计信息更新层的批处理标准化参数(均值和方差)。我们对网络的所有层逐步重复这个过程,直到最后一层。与测地相关对齐类似,该过程只需要未标记的真实数据,而这些数据可能非常丰富。该算法总结在算法1中。[34]中提出了类似的想法,但PDC不同,因为它逐步执行校准,确保早期层的校准不会影响后期层的校准。
5. 实验
在本节中,我们将介绍实验的细节。我们在转换后的KITTI[33]数据集上训练和测试SquezeSegV2,如[2]。为了验证泛化能力,我们进一步在合成GTA-LiDAR数据集上训练SquezeSegV2,并在真实世界KITTI数据集上测试它。
A. 实验设置
我们将所提出的方法与SquezeSeg[2]进行了比较,Squezeseg[2]是一种用于从3D LiDAR点云进行语义分割的最先进模型。我们使用KITTI[33]作为真实世界数据集。KITTI提供图像、激光雷达扫描和按顺序组织的3D边界框。根据[2],我们从3D边界框获得逐点标签,其中所有点都被视为目标对象的一部分。总共收集了10848个带有逐点标签的样本。对于SquezeSegV2,数据集被分成具有8057个样本的训练集和具有2791个样本的测试集。对于域自适应,我们在GTA-LiDAR上训练该模型,并在KITTI上对其进行测试以进行比较。
与[2]类似,我们通过逐点比较预测结果与真值标签来评估我们的模型在类级分割任务上的性能。我们使用intersection-over-union(IoU)作为我们的评估度量,其定义为IoUc= ∣ P c ∩ G c ∣ ∣ P c ∪ G c ∣ \frac{|P_c∩G_c|}{|P_c∪G_c|} ∣Pc∪Gc∣∣Pc∩Gc∣,其中Pc和Gc分别表示属于c类的预测和真值点集。|·|表示集合的基数。
B. 改进的模型结构
表I显示了所提出的SquezeSegV2模型和基线之间的性能比较(以IoU为单位)。图7显示了一些分割结果。
从结果来看,我们有以下观察结果。(1) 批量归一化和掩模通道都可以产生更好的分割结果&批量归一化促进了汽车的分割,而掩模通道促进了骑车人的分割。(2) 焦点损失改善了行人和骑车人的分割。相对于大量背景点,行人和骑车人相对应的点的数量较少。这种类别失衡导致网络对行人和骑车人类别的关注度降低。焦点损失通过将网络集中于这两个类别的优化来缓解这个问题。(3) CAM通过降低网络对脱落噪声的敏感性,显著提高了所有类的性能。

图7. SqueezSeg[2]和SqueezsegV2(红色:汽车,绿色:自行车)之间的分割结果比较。注意,在第一行中,SquezeSegV2为骑车人生成了更精确的分割。在第二排中,SqueezeSegV2避开了一辆被错误检测到的汽车。

图8. 域自适应前后的分割结果比较(红色:汽车,蓝色:行人)。
表I. 在KITTI数据集上,所提出的SqueezeSegV2(+BN+M+FL+CAM)模型与最新基线之间的分割性能(IOU,%)比较。

表II. 从GTA-LIDAR到KITTI的提出的域自适应流水线的分割性能(IOU,%)。

C. 域适配管道
表II显示了提出的领域适应管道和基线之间的性能比较(以IoU为单位)。一些分割结果如图8所示。从结果来看,我们有以下观察结果。(1) 在源域上训练而没有任何调整的模型表现不佳。由于区域差异的影响,观测到的激光雷达和道路物体的联合概率分布在两个区域中有很大差异。这导致模型从源域到目标域的低可转移性。(2) 所有的适应方法都是有效的,组合管道表现最好,证明了其有效性。(3) 将CAM添加到网络中也显著提高了真实数据的性能,支持了我们的假设,即脱落噪声是域差异的重要来源。因此,改进网络以使其对脱落噪声更为鲁棒,可以帮助减少域间隙。(4) 与[2]相比,SqueezeSeg模型在真实KITTI数据集上训练,但没有强度,我们的SqueezSegV2模型仅在合成数据和未标记的真实数据上训练,获得了更好的精度,显示了我们领域自适应训练管道的有效性。(5) 与我们在真实KITTI数据集上训练的最新SquezeSegV2模型相比,仍然存在明显的性能差距。从合成激光雷达点云调整分割模型仍然是一个具有挑战性的问题。
6. 结论
在本文中,我们提出了具有比原始SquezeSeg更好的分割性能的SquezesegV2,以及具有更强传输性的域自适应流水线。我们设计了一个上下文聚合模块来减轻脱落噪声的影响。与其他改进(如焦点损失、批量归一化和LiDAR掩模通道)一起,SqueezeSegV2在各种像素类别中的精度比原始SqueezSeg提高了6.0%至8.6%。我们还提出了一个具有三个组件的领域自适应管道:学习强度渲染、测地相关对齐和渐进领域校准。所提出的管道显著提高了在合成数据上训练的模型的真实世界准确性28.4%,甚至超过了在真实数据集上训练的基线模型[2]。
ACKNOWLEDGEMENT
This work is partially supported by Berkeley Deep Drive (BDD), and partially sponsored by individual gifts from Intel and Samsung. We would like to thank Alvin Wan and Ravi Krishna for their constructive feedback.
REFERENCES
[1] F. Moosmann, O. Pink, and C. Stiller, “Segmentation of 3d lidar data in non-flflat urban environments using a local convexity criterion,” in IV, 2009, pp. 215–220.
[2] B. Wu, A. Wan, X. Yue, and K. Keutzer, “Squeezeseg: Convolutional neural nets with recurrent crf for real-time road-object segmentation from 3d lidar point cloud,” in ICRA, 2018.
[3] A. Torralba and A. A. Efros, “Unbiased look at dataset bias,” in CVPR, 2011, pp. 1521–1528.
[4] T.-Y. Lin, P. Goyal, R. Girshick, K. He, and P. Doll´ar, “Focal loss for dense object detection,” IEEE TPAMI, 2018.
[5] S. Ioffe and C. Szegedy, “Batch normalization: Accelerating deep network training by reducing internal covariate shift,” in ICML, 2015, pp. 448–456.
[6] P. Morerio, J. Cavazza, and V. Murino, “Minimal-entropy correlation alignment for unsupervised deep domain adaptation,” in ICLR, 2018.
[7] B. Douillard, J. Underwood, N. Kuntz, V. Vlaskine, A. Quadros, P. Morton, and A. Frenkel, “On the segmentation of 3d lidar point clouds,” in ICRA, 2011, pp. 2798–2805.
[8] D. Zermas, I. Izzat, and N. Papanikolopoulos, “Fast segmentation of 3d point clouds: A paradigm on lidar data for autonomous vehicle applications,” in ICRA, 2017, pp. 5067–5073.
[9] F. Piewak, P. Pinggera, M. Sch¨afer, D. Peter, B. Schwarz, N. Schneider, D. Pfeiffer, M. Enzweiler, and M. Z¨ollner, “Boosting lidar-based semantic labeling by cross-modal training data generation,” arXiv preprint arXiv:1804.09915, 2018.
[10] C. R. Qi, H. Su, K. Mo, and L. J. Guibas, “Pointnet: Deep learning on point sets for 3d classifification and segmentation,” in CVPR, 2017, pp. 77–85.
[11] C. R. Qi, L. Yi, H. Su, and L. J. Guibas, “Pointnet++: Deep hierarchical feature learning on point sets in a metric space,” in NIPS, 2017, pp. 5099–5108.
[12] C. R. Qi, W. Liu, C. Wu, H. Su, and L. J. Guibas, “Frustum pointnets for 3d object detection from rgb-d data,” arXiv preprint arXiv:1711.08488, 2017.
[13] V. M. Patel, R. Gopalan, R. Li, and R. Chellappa, “Visual domain adaptation: A survey of recent advances,” IEEE SPM, vol. 32, no. 3, pp. 53–69, 2015.
[14] G. Csurka, “Domain adaptation for visual applications: A comprehensive survey,” arXiv:1702.05374, 2017.
[15] M. Long, Y. Cao, J. Wang, and M. Jordan, “Learning transferable features with deep adaptation networks,” in ICML, 2015, pp. 97–105.
[16] B. Sun, J. Feng, and K. Saenko, “Correlation alignment for unsupervised domain adaptation,” in Domain Adaptation in Computer Vision Applications, 2017, pp. 153–171.
[17] J. Zhuo, S. Wang, W. Zhang, and Q. Huang, “Deep unsupervised convolutional domain adaptation,” in ACM MM, 2017, pp. 261–269.
[18] Y. Zhang, P. David, and B. Gong, “Curriculum domain adaptation for semantic segmentation of urban scenes,” in ICCV, 2017, pp. 2039–2049.
[19] M.-Y. Liu and O. Tuzel, “Coupled generative adversarial networks,” in NIPS, 2016, pp. 469–477.
[20] Y. Ganin, E. Ustinova, H. Ajakan, P. Germain, H. Larochelle, F. Laviolette, M. Marchand, and V. Lempitsky, “Domain-adversarial training of neural networks,” JMLR, vol. 17, no. 1, pp. 2096–2030, 2016.
[21] E. Tzeng, J. Hoffman, K. Saenko, and T. Darrell, “Adversarial discriminative domain adaptation,” in CVPR, 2017, pp. 2962–2971.
[22] A. Shrivastava, T. Pfister, O. Tuzel, J. Susskind, W. Wang, and R. Webb, “Learning from simulated and unsupervised images through adversarial training,” in CVPR, 2017, pp. 2242–2251.
[23] K. Bousmalis, N. Silberman, D. Dohan, D. Erhan, and D. Krishnan, “Unsupervised pixel-level domain adaptation with generative adversarial networks,” in CVPR, 2017, pp. 3722–3731.
[24] J. Hoffman, E. Tzeng, T. Park, J.-Y. Zhu, P. Isola, K. Saenko, A. A. Efros, and T. Darrell, “Cycada: Cycle-consistent adversarial domain adaptation,” in ICML, 2018.
[25] M. Ghifary, W. Bastiaan Kleijn, M. Zhang, and D. Balduzzi, “Domain generalization for object recognition with multi-task autoencoders,” in ICCV, 2015, pp. 2551–2559.
[26] M. Ghifary, W. B. Kleijn, M. Zhang, D. Balduzzi, and W. Li, “Deep reconstruction-classification networks for unsupervised domain adaptation,” in ECCV, 2016, pp. 597–613.
[27] S. R. Richter, V. Vineet, S. Roth, and V. Koltun, “Playing for data: Ground truth from computer games,” in ECCV, 2016, pp. 102–118.
[28] M. Johnson-Roberson, C. Barto, R. Mehta, S. N. Sridhar, K. Rosaen, and R. Vasudevan, “Driving in the matrix: Can virtual worlds replace human-generated annotations for real world tasks?” in ICRA, 2017, pp. 746–753.
[29] X. Yue, B. Wu, S. A. Seshia, K. Keutzer, and A. L. SangiovanniVincentelli, “A lidar point cloud generator: from a virtual world to autonomous driving,” in ICMR, 2018, pp. 458–464.
[30] S. R. Richter, Z. Hayder, and V. Koltun, “Playing for benchmarks,” in ICCV, 2017, pp. 2232–2241.
[31] P. Kr¨ahenb¨uhl, “Free supervision from video games,” in CVPR, 2018, pp. 2955–2964.
[32] J. Hu, L. Shen, and G. Sun, “Squeeze-and-excitation networks,” in CVPR, 2018, pp. 7132–7141.
[33] A. Geiger, P. Lenz, and R. Urtasun, “Are we ready for autonomous driving? the kitti vision benchmark suite,” in CVPR, 2012, pp. 3354–3361.
[34] Y. Li, N. Wang, J. Shi, X. Hou, and J. Liu, “Adaptive batch normalization for practical domain adaptation,” PR, vol. 80, pp. 109–117, 2018.
[35] Y. Wang, T. Shi, P. Yun, L. Tai, and M. Liu, “Pointseg: Real-time semantic segmentation based on 3d lidar point cloud,” arXiv preprint arXiv:1807.06288, 2018.