数据结构之----数组、链表、列表
什么是数组?
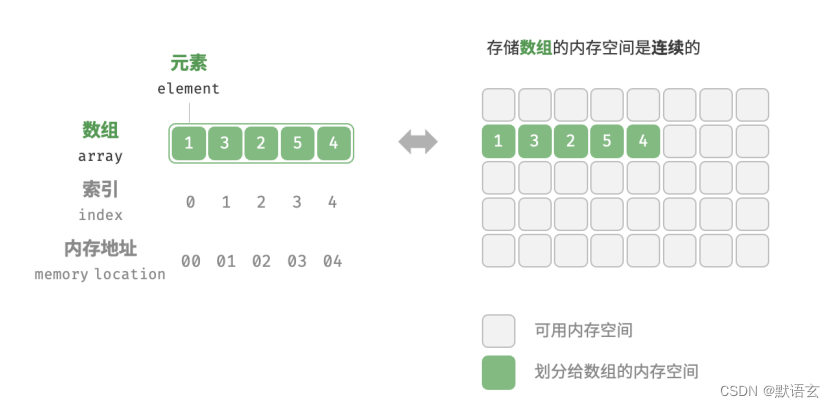
数组是一种线性数据结构,它将相同类型的元素存储在连续的内存空间中。
我们将元素在数组中的位置称为该元素的索引。
数组常用操作
1. 初始化数组
我们可以根据需求选用数组的两种初始化方式:无初始值、给定初始值。在未指定初始值的情况下,大多数编程语言会将数组元素初始化为 0 。
/* 初始化数组 */
int[] arr = new int[5]; // { 0, 0, 0, 0, 0 }
int[] nums = { 1, 3, 2, 5, 4 };
2.访问元素
数组元素被存储在连续的内存空间中,这意味着计算数组元素的内存地址非常容易。
给定数组内存地址(即首元素内存地址)和某个元素的索引,我们可以使用下图所示的公式计算得到该元素的内存地址,从而直接访问此元素。
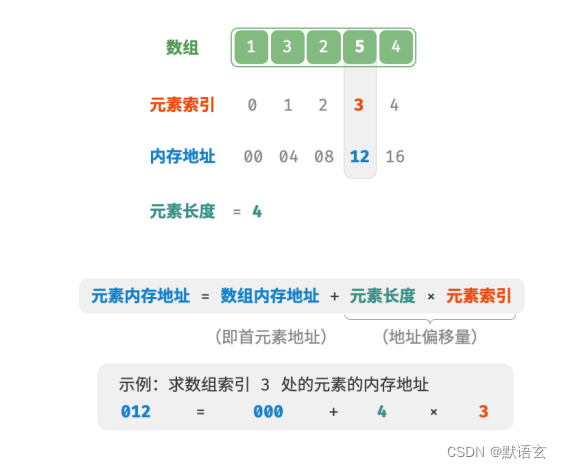
我们发现数组首个元素的索引为 0 ,这似乎有些反直觉,因为从 1 开始计数会更自然。但从地址计算公式的角度看,索引的含义本质上是内存地址的偏移量。首个元素的地址偏移量是 0 ,因此它的索引为 0 也是合理的。
在数组中访问元素是非常高效的,我们可以在 𝑂(1) 时间内随机访问数组中的任意一个元素。
/* 随机访问元素 */
int randomAccess(int[] nums) {
// 在区间 [0, nums.length) 中随机抽取一个数字
int randomIndex = ThreadLocalRandom.current().nextInt(0, nums.length);
// 获取并返回随机元素
int randomNum = nums[randomIndex];
return randomNum;
}
3.插入元素
数组元素在内存中是 紧挨着的 ,它们之间没有空间再存放任何数据。如图所示,如果想要在数组中间插入一个元素,则需要将该元素之后的所有元素都向后移动一位,之后再把元素赋值给该索引。
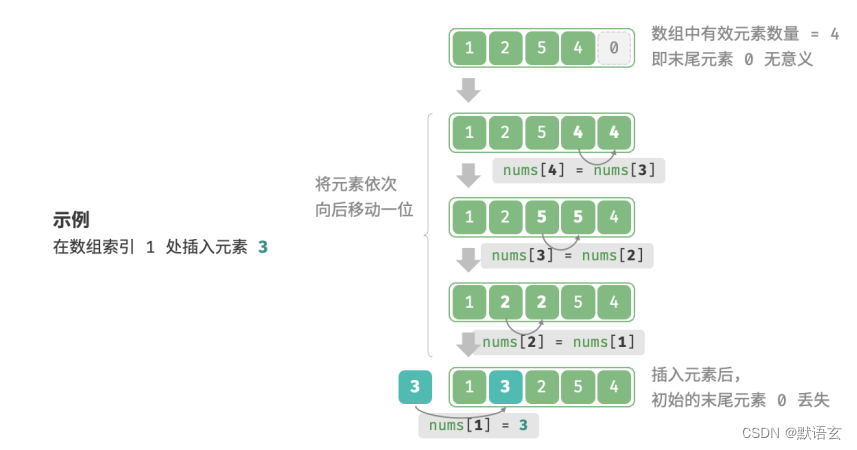
值得注意的是,由于数组的长度是固定的,因此插入一个元素必定会导致数组尾部元素的“丢失”。
/* 在数组的索引 index 处插入元素 num */
void insert(int[] nums, int num, int index) {
// 把索引 index 以及之后的所有元素向后移动一位
for (int i = nums.length - 1; i > index; i--) {
nums[i] = nums[i - 1];
}
// 将 num 赋给 index 处元素
nums[index] = num;
}
4.删除元素
同理,如图所示,若想要删除索引 𝑖 处的元素,则需要把索引 𝑖 之后的元素都向前移动一位。
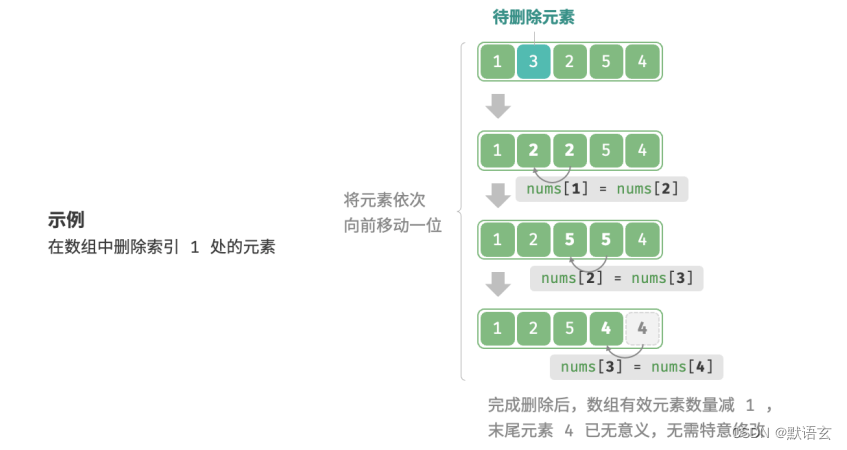
请注意,删除元素完成后,原先末尾的元素变得“无意义”了,所以我们无须特意去修改它。
/* 删除索引 index 处元素 */
void remove(int[] nums, int index) {
// 把索引 index 之后的所有元素向前移动一位
for (int i = index; i < nums.length - 1; i++) {
nums[i] = nums[i + 1];
}
}
总的来看,数组的插入与删除操作有以下缺点:
- 时间复杂度高:数组的插入和删除的平均时间复杂度均为 𝑂(𝑛) ,其中 𝑛 为数组长度。
- 丢失元素:由于数组的长度不可变,因此在插入元素后,超出数组长度范围的元素会丢失。
- 内存浪费:我们可以初始化一个比较长的数组,只用前面一部分,这样在插入数据时,丢失的末尾元素都是“无意义”的,但这样做也会造成部分内存空间的浪费。
5.遍历数组
在大多数编程语言中,我们既可以通过索引遍历数组,也可以直接遍历获取数组中的每个元素。
/* 遍历数组 */
void traverse(int[] nums) {
int count = 0;
// 通过索引遍历数组
for (int i = 0; i < nums.length; i++) {
count++;
}
// 直接遍历数组
for (int num : nums) {
count++;
}
}
6.查找元素
在数组中查找指定元素需要遍历数组,每轮判断元素值是否匹配,若匹配则输出对应索引。
因为数组是线性数据结构,所以上述查找操作被称为线性查找。
/* 在数组中查找指定元素 */
int find(int[] nums, int target) {
for (int i = 0; i < nums.length; i++) {
if (nums[i] == target)
return i;
}
return -1;
}
7.扩容数组
在复杂的系统环境中,程序难以保证数组之后的内存空间是可用的,从而无法安全地扩展数组容量。因此在大多数编程语言中,数组的长度是不可变的。
如果我们希望扩容数组,则需重新建立一个更大的数组,然后把原数组元素依次拷贝到新数组。这是一个𝑂(𝑛) 的操作,在数组很大的情况下是非常耗时的。
/* 扩展数组长度 */
int[] extend(int[] nums, int enlarge) {
// 初始化一个扩展长度后的数组
int[] res = new int[nums.length + enlarge];
// 将原数组中的所有元素复制到新数组
for (int i = 0; i < nums.length; i++) {
res[i] = nums[i];
}
// 返回扩展后的新数组
return res;
}
数组的优缺点
数组存储在连续的内存空间内,且元素类型相同。这种做法包含丰富的先验信息,系统可以利用这些信息来优化数据结构的操作效率。
有以下优点:
- 空间效率高: 数组为数据分配了连续的内存块,无须额外的结构开销。
- 支持随机访问: 数组允许在 𝑂(1) 时间内访问任何元素。
- 缓存局部性: 当访问数组元素时,计算机不仅会加载它,还会缓存其周围的其他数据,从而借助高速缓存来提升后续操作的执行速度。
以下缺点:
- 插入与删除效率低: 当数组中元素较多时,插入与删除操作需要移动大量的元素。
- 长度不可变: 数组在初始化后长度就固定了,扩容数组需要将所有数据复制到新数组,开销很大。
- 空间浪费: 如果数组分配的大小超过了实际所需,那么多余的空间就被浪费了。
数组的应用场景
数组是一种基础且常见的数据结构,既频繁应用在各类算法之中,也可用于实现各种复杂数据结构。
如:
- 随机访问:如果我们想要随机抽取一些样本,那么可以用数组存储,并生成一个随机序列,根据索引实现样本的随机抽取。
- 排序和搜索:数组是排序和搜索算法最常用的数据结构。快速排序、归并排序、二分查找等都主要在数组上进行。
- 查找表:当我们需要快速查找一个元素或者需要查找一个元素的对应关系时,可以使用数组作为查找表。假如我们想要实现字符到 ASCII 码的映射,则可以将字符的 ASCII 码值作为索引,对应的元素存放在数组中的对应位置。
- 机器学习:神经网络中大量使用了向量、矩阵、张量之间的线性代数运算,这些数据都是以数组的形式构建的。数组是神经网络编程中最常使用的数据结构。
- 数据结构实现:数组可以用于实现栈、队列、哈希表、堆、图等数据结构。例如,图的邻接矩阵表示实际上是一个二维数组。
什么是链表?
链表是一种线性数据结构,其中的每个元素都是一个节点对象,各个节点通过“节点指针”相连接。
节点指针记录了下一个节点的内存地址,通过它可以从当前节点访问到下一个节点。
链表的设计使得各个节点可以被分散存储在内存各处,它们的内存地址是无须连续的。
链表的组成单位是「节点 node」对象。每个节点都包含两项数据:节点的“值”和指向下一节点的“指针”。
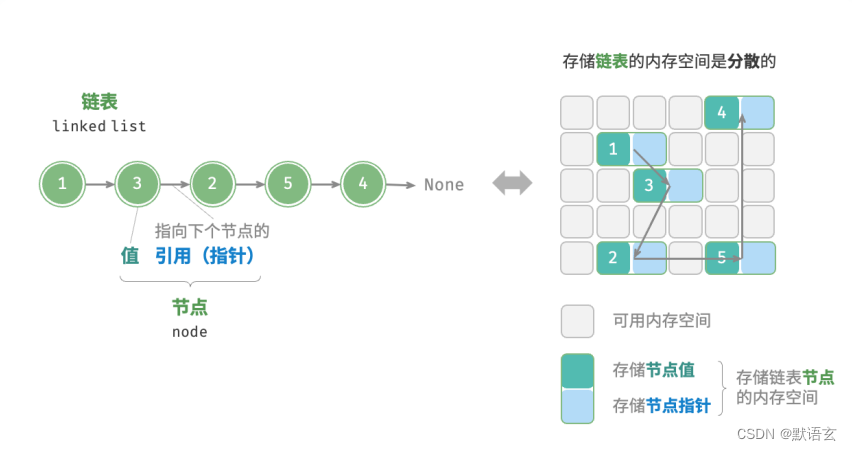
链表节点 ListNode 除了包含值,还需额外保存一个引用(指针)。因此在相同数据量下,链表比数组占用更多的内存空间。
/* 链表节点类 */
class ListNode {
int val; // 节点值
ListNode next; // 指向下一节点的引用
// 构造函数
ListNode(int x) {
val = x;
}
}
链表常用操作
1. 初始化链表
建立链表分为两步,第一步是初始化各个节点对象,第二步是构建引用指向关系。
初始化完成后,我们就可以从链表的头节点出发,通过引用指向 next 依次访问所有节点。
/* 初始化链表 1 -> 3 -> 2 -> 5 -> 4 */
// 初始化各个节点
ListNode n0 = new ListNode(1);
ListNode n1 = new ListNode(3);
ListNode n2 = new ListNode(2);
ListNode n3 = new ListNode(5);
ListNode n4 = new ListNode(4);
// 构建引用指向
n0.next = n1;
n1.next = n2;
n2.next = n3;
n3.next = n4;
数组整体是一个变量,比如数组 nums 包含元素 nums[0] 和 nums[1] 等,而链表是由多个独立的节点对象组成的。
我们通常将头节点当作链表的代称,比如以上代码中的链表可被记做链表 n0 。
2.插入节点
在链表中插入节点非常容易。如图所示,假设我们想在相邻的两个节点 n0 和 n1 之间插入一个新节点 P ,则只需要改变两个节点引用(指针)即可,时间复杂度为 𝑂(1) 。
相比之下,在数组中插入元素的时间复杂度为 𝑂(𝑛) ,在大数据量下的效率较低。
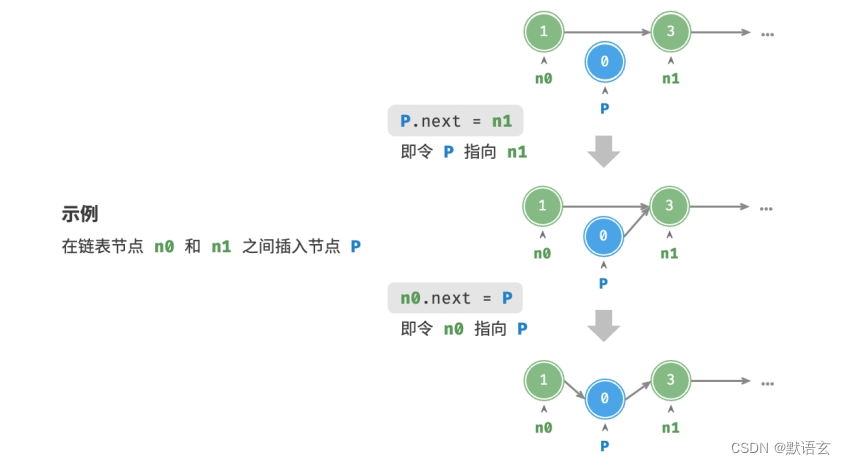
/* 在链表的节点 n0 之后插入节点 P */
void insert(ListNode n0, ListNode P) {
ListNode n1 = n0.next;
P.next = n1;
n0.next = P;
}
3.删除节点
如图所示,在链表中删除节点也非常方便,只需改变一个节点的引用(指针)即可。
请注意,尽管在删除操作完成后节点 P 仍然指向 n1 ,但实际上遍历此链表已经无法访问到 P ,这意味着 P 已经不再属于该链表了。

/* 删除链表的节点 n0 之后的首个节点 */
void remove(ListNode n0) {
if (n0.next == null) return;
// n0 -> P -> n1
ListNode P = n0.next;
ListNode n1 = P.next;
n0.next = n1;
}
4.访问节点
在链表访问节点的效率较低。
如上所述,我们可以在 𝑂(1) 时间下访问数组中的任意元素。
链表则不然,程序需要从头节点出发,逐个向后遍历,直至找到目标节点。也就是说,访问链表的第 𝑖 个节点需要循环 𝑖 − 1轮,时间复杂度为 𝑂(𝑛) 。
/* 访问链表中索引为 index 的节点 */
ListNode access(ListNode head, int index) {
for (int i = 0; i < index; i++) {
if (head == null)
return null;
head = head.next;
}
return head;
}
5.查找节点
遍历链表,查找链表内值为 target 的节点,输出节点在链表中的索引。此过程也属于线性查找。
/* 在链表中查找值为 target 的首个节点 */
int find(ListNode head, int target) {
int index = 0;
while (head != null) {
if (head.val == target)
return index;
head = head.next;
index++;
}
return -1;
}
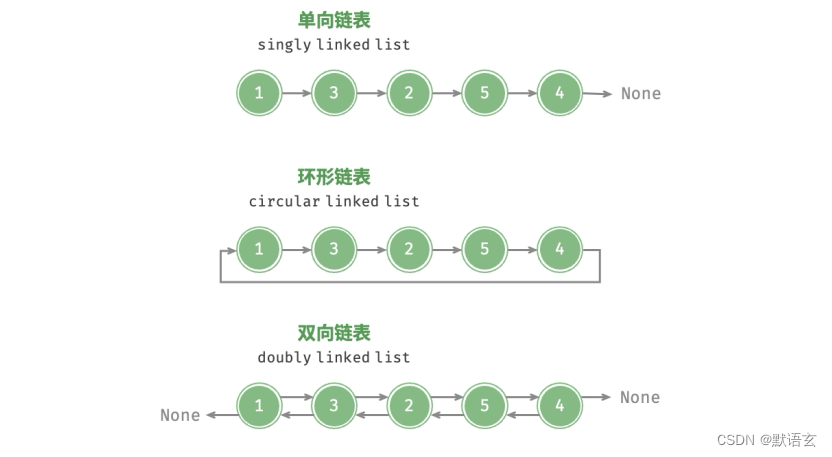
常见链表类型
常见的链表类型包括以下三种:
- 单向链表:即上述介绍的普通链表。单向链表的节点包含值和指向下一节点的引用两项数据。我们将首个节点称为头节点,将最后一个节点称为尾节点,尾节点指向空 None 。
- 环形链表:如果我们令单向链表的尾节点指向头节点(即首尾相接),则得到一个环形链表。在环形链表中,任意节点都可以视作头节点。
- 双向链表:与单向链表相比,双向链表记录了两个方向的引用。双向链表的节点定义同时包含指向后继节点(下一个节点)和前驱节点(上一个节点)的引用(指针)。相较于单向链表,双向链表更具灵活性,可以朝两个方向遍历链表,但相应地也需要占用更多的内存空间。
/* 双向链表节点类 */
class ListNode {
int val; // 节点值
ListNode next; // 指向后继节点的引用
ListNode prev; // 指向前驱节点的引用
ListNode(int x) { val = x; } // 构造函数
}
链表典型应用
单向链表通常用于实现栈、队列、哈希表和图等数据结构。
- 栈与队列:当插入和删除操作都在链表的一端进行时,它表现出先进后出的的特性,对应栈;当插入操作在链表的一端进行,删除操作在链表的另一端进行,它表现出先进先出的特性,对应队列。
- 哈希表:链地址法是解决哈希冲突的主流方案之一,在该方案中,所有冲突的元素都会被放到一个链表中。
- 图:邻接表是表示图的一种常用方式,在其中,图的每个顶点都与一个链表相关联,链表中的每个元素都代表与该顶点相连的其他顶点。
双向链表常被用于需要快速查找前一个和下一个元素的场景。
- 高级数据结构:比如在红黑树、B 树中,我们需要访问节点的父节点,这可以通过在节点中保存一个指向父节点的引用来实现,类似于双向链表。
- 浏览器历史:在网页浏览器中,当用户点击前进或后退按钮时,浏览器需要知道用户访问过的前一个和后一个网页。双向链表的特性使得这种操作变得简单。
- LRU 算法:在缓存淘汰算法(LRU)中,我们需要快速找到最近最少使用的数据,以及支持快速地添加和删除节点。这时候使用双向链表就非常合适。
循环链表常被用于需要周期性操作的场景,比如操作系统的资源调度。
- 时间片轮转调度算法:在操作系统中,时间片轮转调度算法是一种常见的 CPU 调度算法,它需要对一组进程进行循环。每个进程被赋予一个时间片,当时间片用完时,CPU 将切换到下一个进程。这种循环的操作就可以通过循环链表来实现。
- 数据缓冲区:在某些数据缓冲区的实现中,也可能会使用到循环链表。比如在音频、视频播放器中,数据流可能会被分成多个缓冲块并放入一个循环链表,以便实现无缝播放。
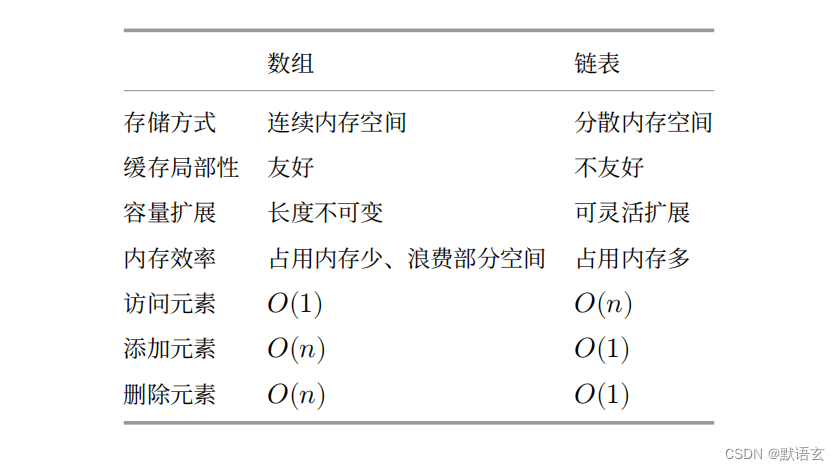
数组 VS 链表
下图总结对比了数组和链表的各项特点与操作效率。
由于它们采用两种相反的存储策略,因此各种性质和操作效率也呈现对立的特点。
什么是列表?
列表是一个抽象的数据结构概念,它表示元素的有序集合,支持元素访问、修改、添加、删除和遍历等操作,无需使用者考虑容量限制的问题。
列表可以基于链表或数组实现:
- 链表天然可以被看作是一个列表,其支持元素增删查改操作,并且可以灵活动态扩容。
- 数组也支持元素增删查改,但由于其长度不可变,因此只能被看作是一个具有长度限制的列表。
当使用数组实现列表时,长度不可变的性质会导致列表的实用性降低。这是因为我们通常无法事先确定需要存储多少数据,从而难以选择合适的列表长度。
若长度过小,则很可能无法满足使用需求;
若长度过大,则会造成内存空间的浪费。
为解决此问题,我们可以使用「动态数组 dynamic array」来实现列表。它继承了数组的各项优点,并且可以在程序运行过程中进行动态扩容。
实际上,许多编程语言中的标准库提供的列表都是基于动态数组实现的,例如 Python 中的 list 、Java 中的 ArrayList 、C++ 中的 vector 和 C# 中的 List 等。
列表常用操作
1.初始化列表
我们通常使用“无初始值”和“有初始值”这两种初始化方法。
/* 初始化列表 */
// 无初始值
List<Integer> nums1 = new ArrayList<>();
// 有初始值(注意数组的元素类型需为 int[] 的包装类 Integer[])
Integer[] numbers = new Integer[] { 1, 3, 2, 5, 4 };
List<Integer> nums = new ArrayList<>(Arrays.asList(numbers));
2.访问元素
列表本质上是数组,因此可以在 𝑂(1) 时间内访问和更新元素,效率很高。
/* 访问元素 */
int num = nums.get(1); // 访问索引 1 处的元素
/* 更新元素 */
nums.set(1, 0); // 将索引 1 处的元素更新为 0
3. 插入与删除元素
相较于数组,列表可以自由地添加与删除元素。在列表尾部添加元素的时间复杂度为 𝑂(1) ,但插入和删除元素的效率仍与数组相同,时间复杂度为 𝑂(𝑛) 。
/* 清空列表 */
nums.clear();
/* 尾部添加元素 */
nums.add(1);
nums.add(3);
nums.add(2);
nums.add(5);
nums.add(4);
/* 中间插入元素 */
nums.add(3, 6); // 在索引 3 处插入数字 6
/* 删除元素 */
nums.remove(3); // 删除索引 3 处的元素
4.遍历数组
与数组一样,列表可以根据索引遍历,也可以直接遍历各元素。
/* 通过索引遍历列表 */
int count = 0;
for (int i = 0; i < nums.size(); i++) {
count++;
}
/* 直接遍历列表元素 */
count = 0;
for (int num : nums) {
count++;
}
5.拼接列表
给定一个新列表 nums1 ,我们可以将该列表拼接到原列表的尾部。
/* 拼接两个列表 */
List<Integer> nums1 = new ArrayList<>(Arrays.asList(new Integer[] { 6, 8, 7, 10, 9 }));
nums.addAll(nums1); // 将列表 nums1 拼接到 nums 之后
6.排序列表
完成列表排序后,我们便可以使用在数组类算法题中经常考察的“二分查找”和“双指针”算法。
/* 排序列表 */
Collections.sort(nums); // 排序后,列表元素从小到大排列
列表实现
下面实现一个简易版列表,包括以下三个重点设计:
- 初始容量:选取一个合理的数组初始容量。在本示例中,我们选择 10 作为初始容量。
- 数量记录:声明一个变量 size ,用于记录列表当前元素数量,并随着元素插入和删除实时更新。根据此变量,我们可以定位列表尾部,以及判断是否需要扩容。
- 扩容机制:若插入元素时列表容量已满,则需要进行扩容。首先根据扩容倍数创建一个更大的数组,再将当前数组的所有元素依次移动至新数组。在本示例中,我们规定每次将数组扩容至之前的 2 倍。
/* 列表类简易实现 */
class MyList {
private int[] arr; // 数组(存储列表元素)
private int capacity = 10; // 列表容量
private int size = 0; // 列表长度(即当前元素数量)
private int extendRatio = 2; // 每次列表扩容的倍数
/* 构造方法 */
public MyList() {
arr = new int[capacity];
}
/* 获取列表长度(即当前元素数量) */
public int size() {
return size;
}
/* 获取列表容量 */
public int capacity() {
return capacity;
}
/* 访问元素 */
public int get(int index) {
// 索引如果越界则抛出异常,下同
if (index < 0 || index >= size)
throw new IndexOutOfBoundsException(" 索引越界");
return arr[index];
}
/* 更新元素 */
public void set(int index, int num) {
if (index < 0 || index >= size)
throw new IndexOutOfBoundsException(" 索引越界");
arr[index] = num;
}
/* 尾部添加元素 */
public void add(int num) {
// 元素数量超出容量时,触发扩容机制
if (size == capacity())
extendCapacity();
arr[size] = num;
// 更新元素数量
size++;
}
/* 中间插入元素 */
public void insert(int index, int num) {
if (index < 0 || index >= size)
throw new IndexOutOfBoundsException(" 索引越界");
// 元素数量超出容量时,触发扩容机制
if (size == capacity())
extendCapacity();
// 将索引 index 以及之后的元素都向后移动一位
for (int j = size - 1; j >= index; j--) {
arr[j + 1] = arr[j];
}
arr[index] = num;
// 更新元素数量
size++;
}
/* 删除元素 */
public int remove(int index) {
if (index < 0 || index >= size)
throw new IndexOutOfBoundsException(" 索引越界");
int num = arr[index];
// 将索引 index 之后的元素都向前移动一位
for (int j = index; j < size - 1; j++) {
arr[j] = arr[j + 1];
}
// 更新元素数量
size--;
// 返回被删除元素
return num;
}
/* 列表扩容 */
public void extendCapacity() {
// 新建一个长度为原数组 extendRatio 倍的新数组,并将原数组拷贝到新数组
arr = Arrays.copyOf(arr, capacity() * extendRatio);
// 更新列表容量
capacity = arr.length;
}
/* 将列表转换为数组 */
public int[] toArray() {
int size = size();
// 仅转换有效长度范围内的列表元素
int[] arr = new int[size];
for (int i = 0; i < size; i++) {
arr[i] = get(i);
}
return arr;
}
}
总结
- 数组和链表是两种基本的数据结构,分别代表数据在计算机内存中的两种存储方式:连续空间存储和分散空间存储。两者的特点呈现出互补的特性。
- 数组支持随机访问、占用内存较少;但插入和删除元素效率低,且初始化后长度不可变。
- 链表通过更改引用(指针)实现高效的节点插入与删除,且可以灵活调整长度;但节点访问效率低、占用内存较多。
- 常见的链表类型包括单向链表、循环链表、双向链表,它们分别具有各自的应用场景。
- 列表是一种支持增删查改的元素有序集合,通常基于动态数组实现,其保留了数组的优势,同时可以灵活调整长度。
- 列表的出现大幅地提高了数组的实用性,但可能导致部分内存空间浪费。
Q & A
数组存储在栈上和存储在堆上,对时间效率和空间效率是否有影响?
存储在栈上和堆上的数组都被存储在连续内存空间内,数据操作效率是基本一致的。然而,栈
和堆具有各自的特点,从而导致以下不同点:
- 分配和释放效率:栈是一块较小的内存,分配由编译器自动完成;而堆内存相对更大,
可以在代码中动态分配,更容易碎片化。因此,堆上的分配和释放操作通常比栈上的慢。 - 大小限制:栈内存相对较小,堆的大小一般受限于可用内存。因此堆更加适合存储大型
数组。 - 灵活性:栈上的数组的大小需要在编译时确定,而堆上的数组的大小可以在运行时动态
确定。
为什么数组要求相同类型的元素,而在链表中却没有强调同类型呢?
链表由节点组成,节点之间通过引用(指针)连接,各个节点可以存储不同类型的数据,
例如 int、double、string、object 等。
相对地,数组元素则必须是相同类型的,这样才能通过计算偏移量来获取对应元素位置。例如,如果数组同时包含 int 和 long 两种类型,单个元素分别占用 4 bytes 和 8 bytes ,那么此时就不能用以下公式计算偏移量了,因为数组中包含了两种长度的元素。
元素内存地址 = 数组内存地址 + 元素长度 * 元素索引
删除节点后,是否需要把 P.next 设为 None 呢?
不修改 P.next 也可以。从该链表的角度看,从头节点遍历到尾节点已经遇不到 P 了。这意味着节点 P 已经从链表中删除了,此时节点 P 指向哪里都不会对这条链表产生影响了。
从垃圾回收的角度看,对于 Java、Python、Go 等拥有自动垃圾回收的语言来说,节点 P 是否被回收取决于是否有仍存在指向它的引用,而不是 P.next 的值。在 C 和 C++ 等语言中,我们需要手动释放节点内存。
在链表中插入和删除操作的时间复杂度是 𝑂(1) 。但是增删之前都需要 𝑂(𝑛) 查找元素,那为什么时间复杂度不是 𝑂(𝑛) 呢?
如果是先查找元素、再删除元素,确实是 𝑂(𝑛) 。然而,链表的 𝑂(1) 增删的优势可以在其他应用上得到体现。
例如,双向队列适合使用链表实现,我们维护一个指针变量始终指向头节点、尾节点,每次插入与删除操作都是 𝑂(1) 。
图片“链表定义与存储方式”中,浅蓝色的存储节点指针是占用一块内存地址吗?还是和节点值各占一半呢?
文中的示意图只是定性表示,定量表示需要根据具体情况进行分析。
- 不同类型的节点值占用的空间是不同的,比如 int、long、double 和实例对象等。
- 指针变量占用的内存空间大小根据所使用的操作系统及编译环境而定,大多为 8 字节或4 字节。
在列表末尾添加元素是否时时刻刻都为 𝑂(1) ?
如果添加元素时超出列表长度,则需要先扩容列表再添加。系统会申请一块新的内存,并将原列表的所有元素搬运过去,这时候时间复杂度就会是 𝑂(𝑛) 。
“列表的出现大大提升了数组的实用性,但副作用是会造成部分内存空间浪费”,这里的空间浪费是指额外增加的变量如容量、长度、扩容倍数所占的内存吗?
这里的空间浪费主要有两方面含义:
一方面,列表都会设定一个初始长度,我们不一定需要用这么多。
另一方面,为了防止频繁扩容,扩容一般都会乘以一个系数,比如 ×1.5 。这样一来,也会出现很多空位,我们通常不能完全填满它们。
在 Python 中 初 始 化 n = [1, 2, 3] 后, 这 3 个 元 素 的 地 址 是 相 连 的, 但 是 初 始 化m = [2, 1, 3] 会发现它们每个元素的 id 并不是连续的,而是分别跟 n 中的相同。这些元素地址不连续,那么 m 还是数组吗?
一方面,我们往往更青睐使用数组实现算法,而只有在必要时才使用链表,主要有两个原因:
- 空间开销:由于每个元素需要两个额外的指针(一个用于前一个元素,一个用于后一个元素),所以 std::list 通常比 std::vector 更占用空间。
- 缓存不友好:由于数据不是连续存放的,std::list 对缓存的利用率较低。一般情况下,std::vector 的性能会更好。
另一方面,必要使用链表的情况主要是二叉树和图。栈和队列往往会使用编程语言提供的stack 和 queue ,而非链表。
初始化列表 res = [ 0 ] * self.size ( ) 操作,会导致 res 的每个元素引用相同的地址吗?
不会。但二维数组会有这个问题,例如初始化二维列表 res = [ [ 0 ] * self.size ( ) ] ,则多次引用了同一个列表 [ 0 ] 。
在删除节点中,需要断开该节点与其后继节点之间的引用指向吗?
从数据结构与算法(做题)的角度看,不断开没有关系,只要保证程序的逻辑是正确的就行。
从标准库的角度看,断开更加安全、逻辑更加清晰。如果不断开,假设被删除节点未被正常回收,那么它也会影响后继节点的内存回收。