一、说明
本文分享基于 Fate 使用 横向联邦 神经网络算法 对 多分类 的数据进行 模型训练,并使用该模型对数据进行 多分类预测。
- 二分类算法:是指待预测的 label 标签的取值只有两种;直白来讲就是每个实例的可能类别只有两种 (0 或者 1),例如性别只有 男 或者 女;此时的分类算法其实是在构建一个分类线将数据划分为两个类别。
- 多分类算法:是指待预测的 label 标签的取值可能有多种情况,例如个人爱好可能有 篮球、足球、电影 等等多种类型。常见算法:Softmax、SVM、KNN、决策树。
关于 Fate 的核心概念、单机部署、训练以及预测请参考以下相关文章:
- 《隐私计算 FATE - 关键概念与单机部署指南》
- 《隐私计算 FATE - 模型训练》
- 《隐私计算 FATE - 离线预测》
二、准备训练数据
上传到 Fate 里的数据有两个字段名必需是规定的,分别是主键为 id 字段和分类字段为 y 字段,y 字段就是所谓的待预测的 label 标签;其他的特征字段 (属性) 可任意填写,例如下面例子中的 x0 - x9
例如有一条用户数据为:
收入: 10000,负债: 5000,是否有还款能力: 1 ;数据中的收入和负债就是特征字段,而是否有还款能力就是分类字段。
本文只描述关键部分,关于详细的模型训练步骤,请查看文章《隐私计算 FATE - 模型训练》
2.1. guest 端
10 条数据,包含 1 个分类字段 y 和 10 个标签字段 x0 - x9
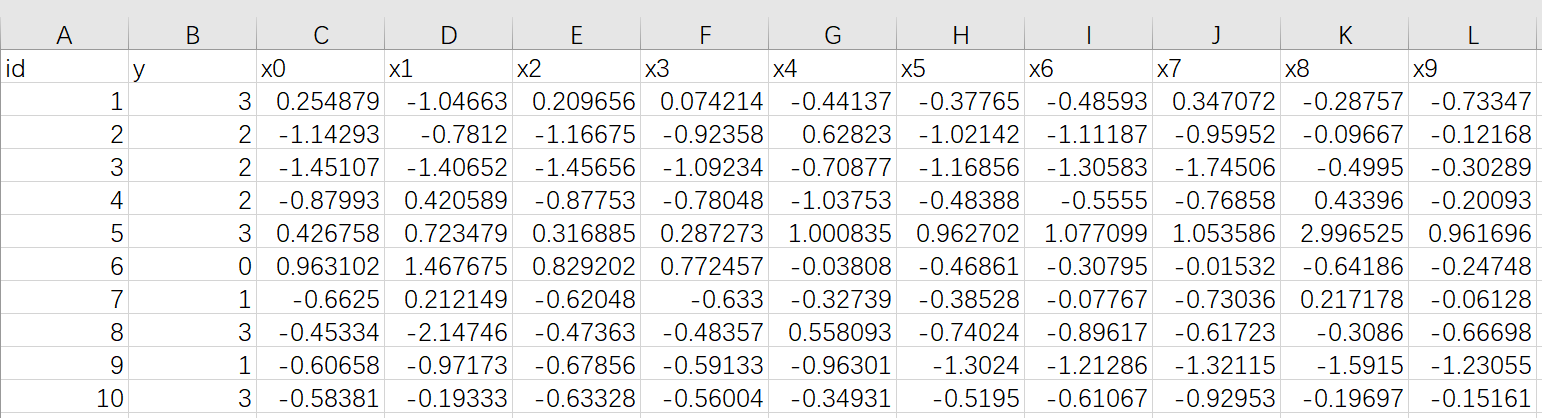
y 值有 0、1、2、3 四个分类
上传到 Fate 中,表名为 muti_breast_homo_guest 命名空间为 experiment
2.2. host 端
10 条数据,字段与 guest 端一样,但是内容不一样
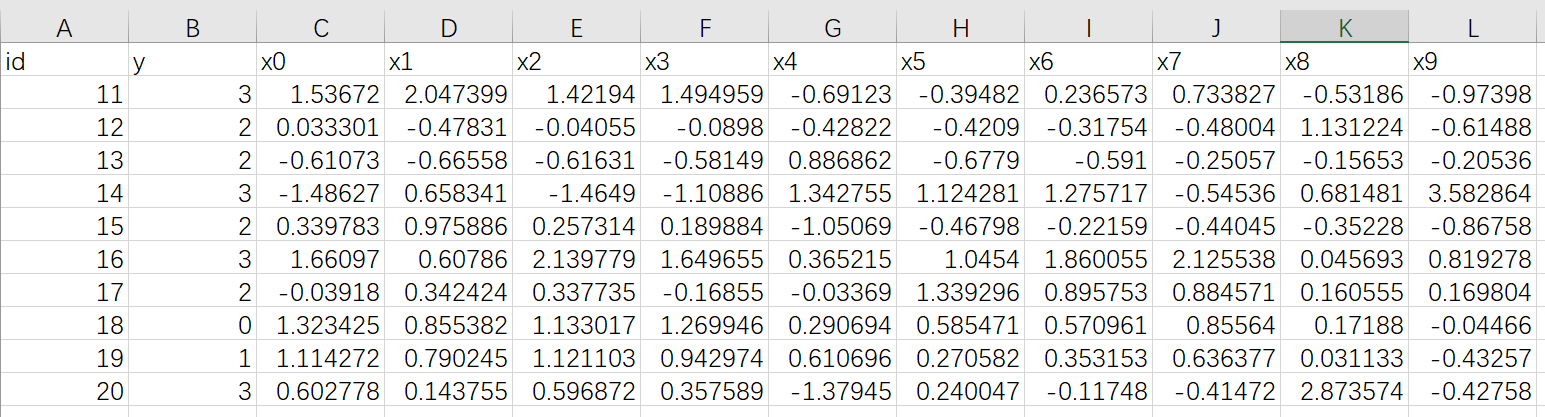
上传到 Fate 中,表名为 muti_breast_homo_host 命名空间为 experiment
三、执行训练任务
3.1. 准备 dsl 文件
创建文件 homo_nn_dsl.json 内容如下 :
{
"components": {
"reader_0": {
"module": "Reader",
"output": {
"data": [
"data"
]
}
},
"data_transform_0": {
"module": "DataTransform",
"input": {
"data": {
"data": [
"reader_0.data"
]
}
},
"output": {
"data": [
"data"
],
"model": [
"model"
]
}
},
"homo_nn_0": {
"module": "HomoNN",
"input": {
"data": {
"train_data": [
"data_transform_0.data"
]
}
},
"output": {
"data": [
"data"
],
"model": [
"model"
]
}
}
}
}
3.2. 准备 conf 文件
创建文件 homo_nn_multi_label_conf.json 内容如下 :
{
"dsl_version": 2,
"initiator": {
"role": "guest",
"party_id": 9999
},
"role": {
"arbiter": [
10000
],
"host": [
10000
],
"guest": [
9999
]
},
"component_parameters": {
"common": {
"data_transform_0": {
"with_label": true
},
"homo_nn_0": {
"encode_label": true,
"max_iter": 15,
"batch_size": -1,
"early_stop": {
"early_stop": "diff",
"eps": 0.0001
},
"optimizer": {
"learning_rate": 0.05,
"decay": 0.0,
"beta_1": 0.9,
"beta_2": 0.999,
"epsilon": 1e-07,
"amsgrad": false,
"optimizer": "Adam"
},
"loss": "categorical_crossentropy",
"metrics": [
"accuracy"
],
"nn_define": {
"class_name": "Sequential",
"config": {
"name": "sequential",
"layers": [
{
"class_name": "Dense",
"config": {
"name": "dense",
"trainable": true,
"batch_input_shape": [
null,
18
],
"dtype": "float32",
"units": 5,
"activation": "relu",
"use_bias": true,
"kernel_initializer": {
"class_name": "GlorotUniform",
"config": {
"seed": null,
"dtype": "float32"
}
},
"bias_initializer": {
"class_name": "Zeros",
"config": {
"dtype": "float32"
}
},
"kernel_regularizer": null,
"bias_regularizer": null,
"activity_regularizer": null,
"kernel_constraint": null,
"bias_constraint": null
}
},
{
"class_name": "Dense",
"config": {
"name": "dense_1",
"trainable": true,
"dtype": "float32",
"units": 4,
"activation": "sigmoid",
"use_bias": true,
"kernel_initializer": {
"class_name": "GlorotUniform",
"config": {
"seed": null,
"dtype": "float32"
}
},
"bias_initializer": {
"class_name": "Zeros",
"config": {
"dtype": "float32"
}
},
"kernel_regularizer": null,
"bias_regularizer": null,
"activity_regularizer": null,
"kernel_constraint": null,
"bias_constraint": null
}
}
]
},
"keras_version": "2.2.4-tf",
"backend": "tensorflow"
},
"config_type": "keras"
}
},
"role": {
"host": {
"0": {
"reader_0": {
"table": {
"name": "muti_breast_homo_host",
"namespace": "experiment"
}
}
}
},
"guest": {
"0": {
"reader_0": {
"table": {
"name": "muti_breast_homo_guest",
"namespace": "experiment"
}
}
}
}
}
}
}
注意
reader_0组件的表名和命名空间需与上传数据时配置的一致。
3.3. 提交任务
执行以下命令:
flow job submit -d homo_nn_dsl.json -c homo_nn_multi_label_conf.json
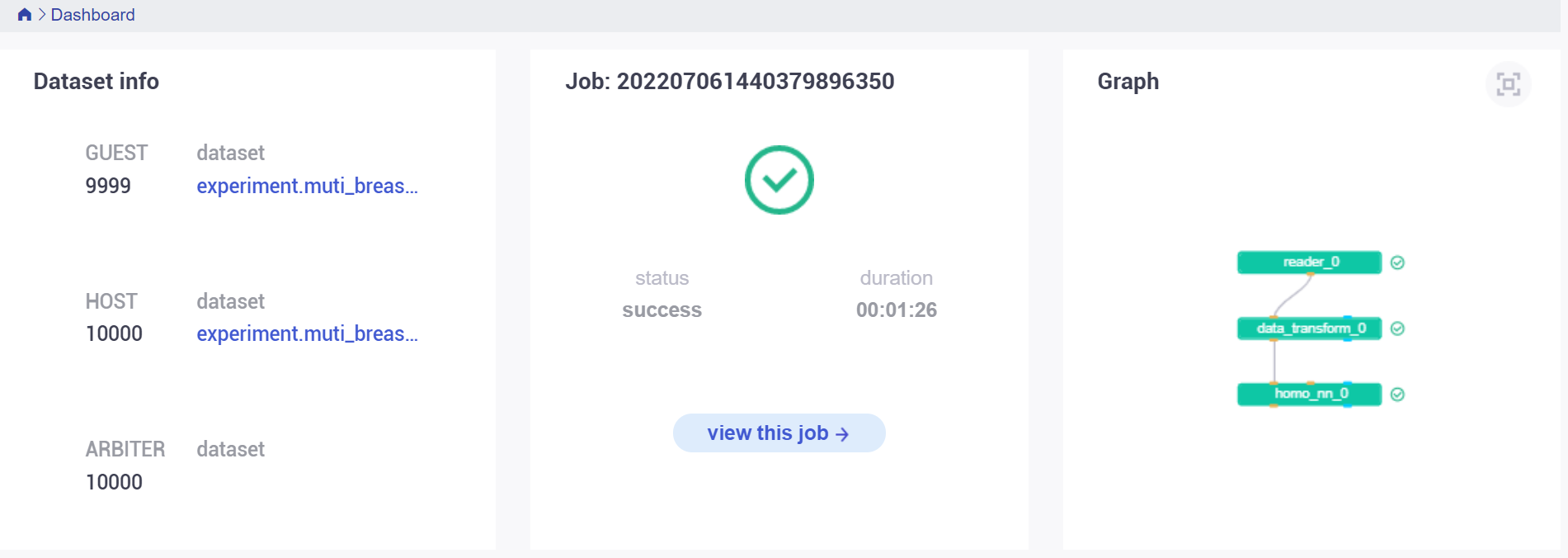
执行成功后,查看 dashboard 显示:
四、准备预测数据
与前面训练的数据字段一样,但是内容不一样,y 值全为 0
4.1. guest 端
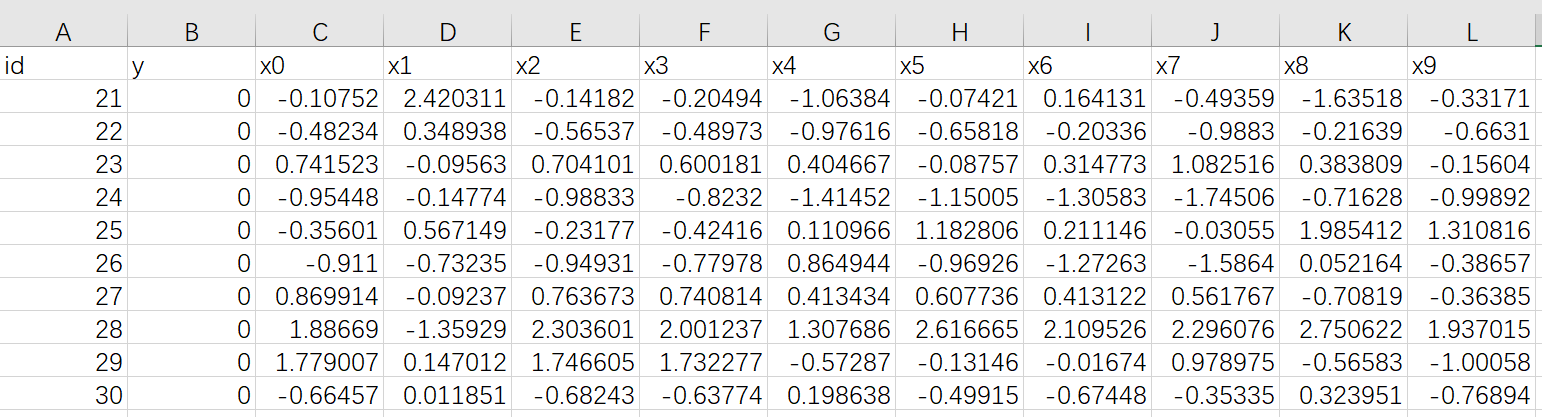
上传到 Fate 中,表名为 predict_muti_breast_homo_guest 命名空间为 experiment
4.2. host 端
上传到 Fate 中,表名为 predict_muti_breast_homo_host 命名空间为 experiment
五、准备预测配置
本文只描述关键部分,关于详细的预测步骤,请查看文章《隐私计算 FATE - 离线预测》
创建文件 homo_nn_multi_label_predict.json 内容如下 :
{
"dsl_version": 2,
"initiator": {
"role": "guest",
"party_id": 9999
},
"role": {
"arbiter": [
10000
],
"host": [
10000
],
"guest": [
9999
]
},
"job_parameters": {
"common": {
"model_id": "arbiter-10000#guest-9999#host-10000#model",
"model_version": "202207061504081543620",
"job_type": "predict"
}
},
"component_parameters": {
"role": {
"guest": {
"0": {
"reader_0": {
"table": {
"name": "predict_muti_breast_homo_guest",
"namespace": "experiment"
}
}
}
},
"host": {
"0": {
"reader_0": {
"table": {
"name": "predict_muti_breast_homo_host",
"namespace": "experiment"
}
}
}
}
}
}
}
注意以下两点:
model_id和model_version需修改为模型部署后的版本号。
reader_0组件的表名和命名空间需与上传数据时配置的一致。
六、执行预测任务
执行以下命令:
flow job submit -c homo_nn_multi_label_predict.json
执行成功后,查看 homo_nn_0 组件的数据输出:
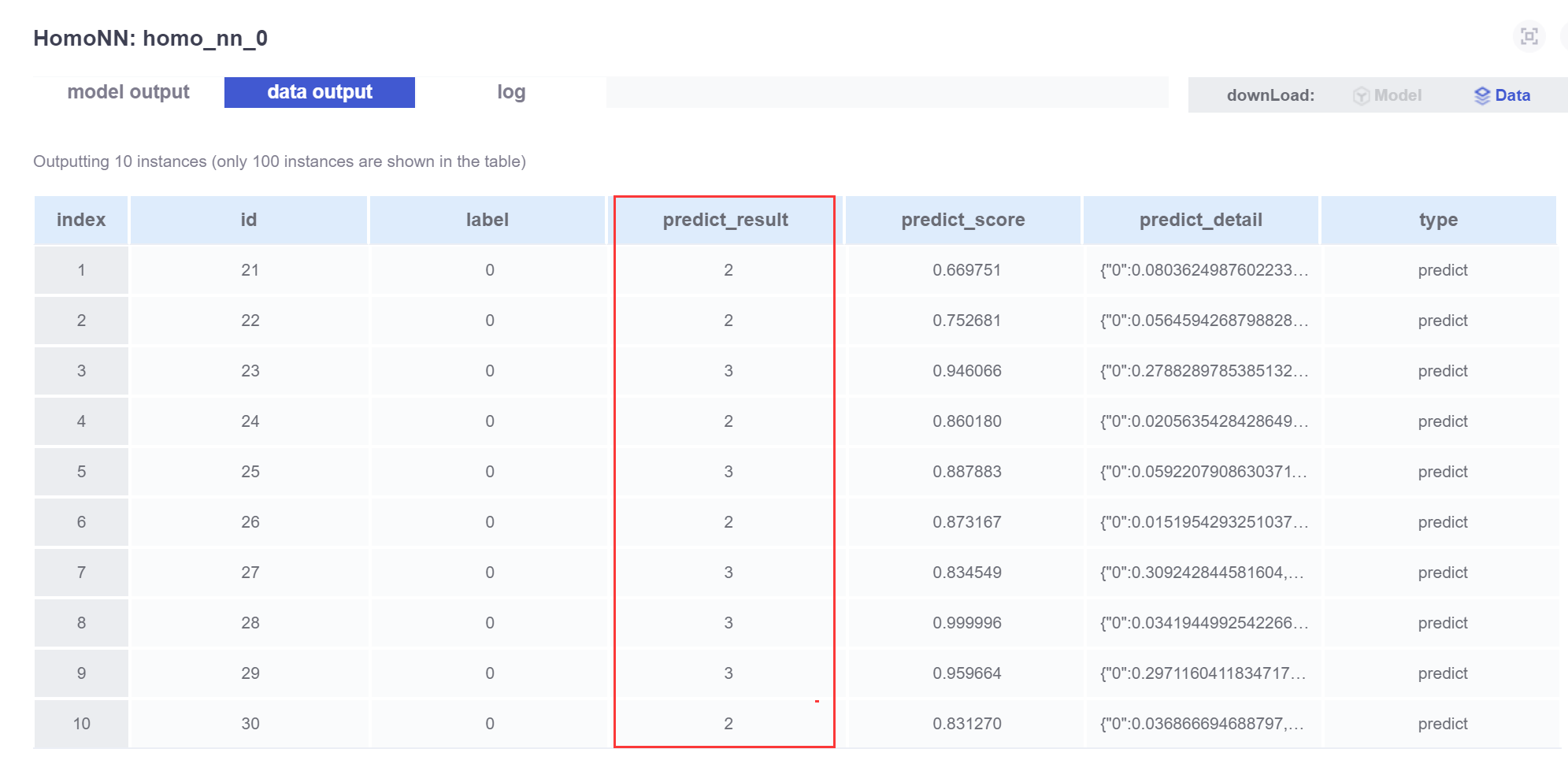
可以看到算法输出的预测结果。