SL-Swin: A Transformer-Based Deep Learning Approach for Macro- and Micro-Expression Spotting on Small-Size Expression Datasets
在本文中,我们致力于解决从视频中检测面部宏观和微观表情的问题,并通过使用深度学习方法分析光流特征提出了引人注目的结果。与主要基于卷积神经网络(CNNs)的其他深度学习方法不同,我们提出了一种基于Transformer的深度学习方法,该方法预测一个分数,指示一帧可能处于表情区间的概率。与其他基于Transformer的模型不同,这些模型通过在大型数据集上进行预训练而获得高性能,我们的深度学习模型,称为SL-Swin,通过在小型表情数据集上从头开始训练,有效地检测宏观和微观表情。
通常,面部表情经历三个明显的阶段:起始阶段、顶峰阶段和结束阶段。如[2]所述,起始阶段标志着面部肌肉收缩的开始(表情开始的第一帧),顶峰阶段代表面部动作达到峰值强度,结束阶段表示面部肌肉返回到中性状态(表情结束的最后一帧)。表情分析的概念包括两个方面,即检测和识别[3]。检测任务旨在确定给定视频是否包含表情,并在视频中找到从起始阶段到结束阶段的表情间隔。
现有的宏观和微观表情检测方法大致可分为传统方法和深度学习方法[5]。
Davison等人提出的方法[6]涉及将面部分割成块,并计算每帧的HOG。然后,该方法使用χ2
距离计算在一定间隔内帧之间的不相似性,从而检测微表情。Duque等人[7]提出了基于Riesz金字塔的方法。Wang等人[4]使用他们提出的主方向最大差异(MDMD)方法,表征光流主方向的最大差异的幅度。Zhang等人[8]和MEGC2020的基准方法[9]都使用基于光流的方法来检测表情,证明通过使用光流特征描述面部运动,尤其是提取微表情,是可能的,这些微表情更为微妙且持续时间更短[10]。
传统方法对微观表情的检测能力就不太令人信服。Zhang等人[11]首次引入深度学习用于微表情检测,利用卷积神经网络(CNN)检测表情的顶点帧,然后使用他们提出的特征工程方法合并附近检测到的样本。Pan等人[12]提出了选择感兴趣区域(ROI)的有用性,并采用双线性卷积神经网络(BCNN)进行表情检测。在MEGC2021[13]和MEGC2022[14]的基础上,Yap等人[15]应用了基于3D-CNN网络的帧跳过和对比度增强。此外,Verburg等人[16]提出了一种方法,其中通过滑动窗口提取的定向光流直方图特征作为输入特征,输入到由LSTM单元组成的RNN中,这是首次利用循环神经网络(RNN)进行表情检测。
研究者们尝试将CNNs与Transformers结合用于表情检测。Pan等人[20]提出了时空卷积情感注意网络(STCEAN),该网络通过卷积神经网络提取空间特征,并使用自注意力模型分析时间维度上不同情感的权重进行检测。BERT网络[21]是基于双向自注意机制的Transformer编码器堆叠,对自然语言处理(NLP)任务非常成功。在Zhou等人提出的方法中[22],BERT与3D-CNN结合,在提取时空特征方面表现出色。Guo等人[23]提出了一个使用多尺度本地Transformer模块的卷积Transformer网络,以根据3D卷积子网络提取的视觉特征获得帧之间的相关性。然而,与表情识别相比,Transformers在表情检测中的应用还相对有限。
检测任务可以被构建为一个回归问题,预测一帧在宏观或微观表情区间内的概率。
受到以上工作的启发,我们提出了一种基于Transformer的深度学习方法,通过分析从视频中提取的光流特征来检测宏观和微观表情。我们的深度学习模型被称为SL-Swin,采用了Shifted Patch Tokenization(SPT)[26]和Locality Self-Attention(LSA)[26]应用于骨干Swin Transformer [27],在小型表情数据集上从零开始训练后取得了引人注目的结果。此外,我们在训练阶段应用了伪标签技术[25]来促进特征学习过程,并通过在平滑处理后使用峰值检测技术[28]来预测每个视频中的顶峰帧。本文的贡献如下:
•我们提出了一种深度学习方法,使用Swin Transformer作为骨干来通过分析光流特征生成一个用于检测表情的分数。
• 我们实现了SPT,它在训练阶段通过提供比标准标记更宽的感受野,将更多的空间光流信息嵌入到视觉标记中。
• 我们采用LSA,通过迫使每个标记更集中地关注与其自身关系较大的标记,使注意力在本地范围内工作,以使网络更多关注包含重要表情运动信息的视觉标记。
• 我们将SPT和LSA都整合到Swin Transformer的骨干中,以便在小型表情数据集上从零开始训练;我们的研究通过优于MEGC 2022检测基准方法并在MEGC 2021检测任务上取得可比较的结果,展示了基于Transformer的深度学习方法的有效性。
2. Materials and Methods
所提出的方法如图1所示。我们的方法概述了五个阶段:光流特征的初始提取,预处理,使用SL-Swin学习光流特征,伪标签生成,以及表情检测。

图一。提议方法的说明。
2.1. Feature Extraction
我们使用了光流特征作为深度学习模型的输入,这些特征携带着大量的时空运动信息[24,25]。首先,我们在每一帧中裁剪面部区域并将其调整为128 × 128像素,以进行分辨率规范化。
接下来,使用当前帧Fi和帧F(i+k)(从当前帧Fi开始的第k帧)来计算光流特征,其中k是表情区间平均长度的一半。
在[29]中测试的所有光流估计方法中,TV-L1光流估计方法是最健壮的,我们使用它来计算水平分量u和垂直分量v,它们构成了模型输入特征的第一和第二通道。此外,我们使用它们来计算光流应变ϵ,该应变从光流分量中捕捉微妙的面部变形[30]:

其中,ϵxy和ϵyx是剪切应变分量,ϵxx和ϵyy是法向应变分量。输入到模型中的特征的第三通道是光流应变的幅度|ϵ|,可以计算为:

总的来说,在模型训练阶段之前的预处理阶段,输入数据包括三个分量(u、v、|e|)的连接,它们的形状分别为(128,128,3)。
2.2. Preprocessing
我们对提取的光流特征进行了预处理,以确保数据一致性并去除噪音。受到[8]的工作的启发,我们减去了鼻部区域的均值特征,以消除每一帧的头部运动。
由于眨眼显著干扰了光流特征[31],我们在左眼和右眼区域应用了一个黑色的多边形形状的遮罩,高度和宽度各加了15个像素的额外边距。我们使用了三个各为12个像素的矩形框作为额外边距,将三个区域作为感兴趣区域(ROIs)进行包围:ROI 1,跨越左眼和左眉的区域,被获取并调整大小为21×21;ROI 2,右眼和右眉的区域,以相同的方式获取和调整大小;最后,ROI 3,源自嘴巴区域,被获取并调整大小为21×42。
最终,在训练阶段使用的最终预处理的光流特征(u、v、|ϵ|),它们的形状分别为(42, 42, 3),是通过以下步骤获取的。首先,调整大小后的ROI 1和ROI 2在水平方向堆叠,形成大小为21×42的上半部分。然后,将调整大小后的ROI 3,组成下半部分,垂直堆叠在上半部分下
为了在小型表情数据集上从零开始进行训练以检测表情,我们提出了SL-Swin,并考虑了三个进一步的因素:(1)网络的骨干是Swin Transformer [27],能够有效地考虑表情光流特征的局部和全局特征;(2)应用了Shifted Patch Tokenization(SPT)[26]和Locality Self-Attention(LSA)[26]到骨干,使网络能够即使在小型表情数据集上也能够从零开始进行训练;(3)添加了一个头模块,用于预测一个分数,指示一帧可能处于表情区间的概率。
图2展示了基于Swin Transformer(Swin-T)微型版本的SL-Swin-T模型的概览。在这里,SL表示模型同时应用了SPT和LSA。首先,在“stage 1”中,SPT模块将输入的光流特征分割成不重叠的patch,这些patch被视为“vision tokens”。在我们的方法中,patch大小p为6,并且通过SPT中的线性嵌入层将输出投影到维度C。接下来,标记通过带有LSA的多个Transformer块(L Swin Transformer块)传递,这些块将标记的分辨率保持在(H/6xW/6)处,其中H和W分别是输入模型的预处理光流特征的宽度和高度。(42, 42, 3)

图二。小型版Swin Transformer的架构适用于SPT和LSA,称为SL-Swin-T。
随着网络变得更深,使用patch合并层减少token的数量,因为骨干Swin Transformer被设计用来构建分层特征图。patch合并层通过将2×2相邻patch组的标记连接来将标记的数量减少4倍(分辨率2×下采样)。然后,patch合并层内的线性层被应用于将下采样的4C维连接特征投影到4C维输出。随后,通过多个L Swin Transformer块进行特征变换,这些块在H/12 × W/12 处保持分辨率。第一个patch合并层和多个L Swin Transformer块的组合称为“stage 2”。这个过程重复两次,分别为“stage 3”和“stage 4”,其输出分辨率分别为H/24 × W/24 和H/48 × W/48。最后,一个作为回归模块的头部(由标准化和多层感知器(MLP)组成)被应用于预测一个分数,指示一帧可能处于表情区间的概率。
2.3.1. Swin Transformer
一个单一的宏观或微观表情可能具有多个高强度的AU。因此,为了确定是否出现宏观或微观表情,模型必须考虑来自各种输入部分的局部特征、全局特征以及局部特征之间的关系。
在每个连续的Swin Transformer块的计算中,使用了两种自注意配置:使用常规窗口划分配置的基于窗口的多头自注意(W-MSA)和使用移动窗口划分配置的基于窗口的多头自注意(SW-MSA)。移动窗口方案,包括常规和移动窗口划分配置,通过将自注意计算限制在非重叠窗口内,同时利用窗口之间的交叉连接,展现了高效的建模能力。因此,网络能够有效地考虑输入光流特征不同部分的局部特征、全局特征和局部特征之间的关系。
基于Transformer的模型如ViT和Swin Transformer需要大量的训练数据或在大型数据集上进行预训练以获得高性能,但微表情检测所使用的数据集相对较小,这可能限制了基于这些Transformer的模型的性能。为了使网络在相对小规模的表情数据集上表现良好,我们实现了SPT,通过在visal token中嵌入更多的空间信息,提供给模型比标准标记更宽的感受野。此外,我们采用了LSA,使网络能够更多关注包含重要运动信息的视觉标记。下面详细描述了SPT和LSA的细节。
2.3.2. Shifted Patch Tokenization
Shifted Patch Tokenization (SPT)输出的张量与Swin Transformer或Vision Transformer的原始Patch Embedding Layer具有相同的形状。,我们将SPT用作Patch Embedding Layer。
SPT是SL-Swin模型的头部组件(位于光流输入的上游),这意味着当特征输入到模型中时,预处理的光流特征首先由SPT处理。以下描述了SPT的总体公式以及我们如何将其实现为Patch Embedding Layer。首先,应用了一种位移策略,将每个输入的预处理光流特征在四个对角方向(左上、右上、左下和右下)中的半个patch大小进行位移。位移后的特征在被裁剪为与输入相同大小后与原始输入的预处理光流特征进行串联。然后,串联的特征[x, x1s , x2s , x3s , x4s ]被划分为非重叠的patch,并将这些patch展平为一个向量序列,具体如下:\
DF ([ x, x1s , x2s , x3s , x4s ]) = [ x1p; x2p; . . . ; xNp ] (3)
其中,x代表原始的预处理光流特征,x1s , x2s , x3s , x4s分别是在左上、右上、左下和右下方向上进行位移的裁剪特征,xip ∈ RP2×C是第i个展平向量,p是patch大小,N = HW/p2是patch的数量,DP表示划分和展平过程。
接下来,通过层归一化(LN)获得视觉标记(VT),然后通过线性层(LL)进行投影。整个过程可以表示为:
VT(x) = LL ( LN ([ x1p; x2p; . . . ; xNp ])) (4)
为了将SPT用作Patch Embedding Layer,我们向SPT的输出添加了一个位置嵌入变量。整个过程可以表示为:
VTpe(x) = VT(x) + Epos
其中,Epos是可学习的位置嵌入变量,VTpe(x)是要由模型的其余部分处理的最终输出。总体而言,我们实现的SPT可以理解为原始Swin Transformer架构中“stage 1”的patch划分和线性嵌入过程的组合。
2.3.3. Locality Self-Attention
局部自注意机制(LSA)的核心包括对角掩码和可学习温度缩放。图3a展示了标准自注意机制和SL-Swin模型中使用的局部自注意之间的差异。图3b显示了LSA如何应用在连续的Swin Transformer块中形成L Swin Transformer块。图3b中显示的两个连续的Swin Transformer块中的W-MLSA和SW-MLSA分别表示使用常规和移动窗口划分配置的基于窗口的多头局部自注意;L表示LSA应用的位置。

(a)标准自我注意(左)和LSA(右) (b)两个连续的L Swin Transformer区块
图3。 (a) 标准自注意机制与局部自注意机制之间的比较。 (b) 两个连续的L Swin Transformer块;W-MLSA和SW-MLSA分别是具有常规和移动窗口配置的多头局部自注意模块。
通用ViTs的标准自注意计算操作如下。首先,通过对每个标记应用可学习的线性投影,获得Query、Key和Value。接下来,通过Query和Key的点积运算计算表示标记之间关系的相似性矩阵R。R的对角线和非对角线分量分别表示自标记和标记之间的关系:
R = QKT (6)
这里,Q和K表示Query和Key的可学习线性投影。之后,对R的对角分量施加对角遮罩,通过在以下计算中本质上排除自标记关系,强调标记之间的关系,强制将对角线分量设置为−∞。对角遮罩的公式如下:

其中,RM表示带有掩码的相似性矩阵,i和j分别表示相似性矩阵R的行和列索引。
在对角遮罩之后,应用可学习的温度缩放,以允许模型在学习阶段自行确定softmax温度。由于注意机制用于骨干Swin Transformer的SW-MSA和SW-MSA,我们包含了一个相对位置偏差B来维持骨干架构。最终,通过softmax操作获得注意力分数矩阵,其中使用注意力分数矩阵和Value的点积获得自注意力矩阵:
Attention(Q, K, V) = softmax ( Rm/τ +B ) V
其中,V是Value的可学习线性投影,τ是可学习的温度。
2.4. Pseudo-Labeling
参考微表情检测(二)----SOFTNet论文总结
2.5. Spotting
每个视频的预测分数序列S被平滑处理,以获得平滑的分数序列S
:
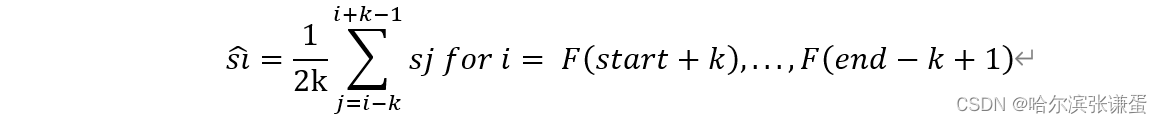
其中,sj表示原始预测分数序列S中的第j个值,ˆ si表示平滑分数序列ˆ S中的第i个值。在平滑方案中,对当前帧Fi的间隔[F(i−k), F(i+k−1)]进行平均。每个平滑的分数值ˆ si现在表示当前帧Fi在表情间隔内的概率。最后,我们使用了来自[28]的标准阈值和峰值检测技术,以发现每个视频中的峰值,其中阈值定义为:

其中,smean![]() 和smax
和smax![]() 分别是平滑分数序列S
分别是平滑分数序列S![]() 的平均值和最大值,t是用于调整的百分比参数,范围从0到1。我们检测了局部最大值(峰值之间的最小距离为k)以找到峰值帧Fp
的平均值和最大值,t是用于调整的百分比参数,范围从0到1。我们检测了局部最大值(峰值之间的最小距离为k)以找到峰值帧Fp![]() 和峰值值Sp
和峰值值Sp![]() 。被发现的峰值帧Fp
。被发现的峰值帧Fp![]() 被视为发现的顶点帧,并通过扩展k帧获得用于评估的发现的起始-结束间隔[F(p−k),F(p+k)]。发现过程的示例在附录C中展示。
被视为发现的顶点帧,并通过扩展k帧获得用于评估的发现的起始-结束间隔[F(p−k),F(p+k)]。发现过程的示例在附录C中展示。
3. Results
在这项研究中,我们对MEGC 2022和MEGC 2021的发现任务进行了实验。请注意,模型分别用于训练和推断宏观表达和微观表达。
3.1. Evaluation Datasets
3.1.1. MEGC 2022 Dataset
MEGC 2022提供了一个用于评估的单一未见过的测试数据集。该数据集包括十个长视频:从CAS(ME)3 [33]中的不同视频裁剪出的五个片段,以及来自SAMM(SAMM挑战数据集)[34]的五个长视频,它们的帧率分别为30 fps和200 fps。
CAS(ME)3使用虚构的犯罪范式以及生理和声音信号来引发具有高生态效度的微表达,有助于实际的表情分析。
3.2. Performance Metrics
我们使用标准的交并比(IoU)方法来评估我们的表达点方法,与MEGC 2021和MEGC 2022中的表达点任务一致。我们将检测到的时间窗口Wspotted与grondTruth窗口WgrondTruth进行比较,当满足以下条件时,我们将其视为真正例(TP):

其中J设置为0.5。否则,将检测到的时间窗口Wspotted视为假正例(FP)结果。此外,未能检测到的WgrondTruth被视为假负例(FN)。随后,我们计算了准确率和召回率。准确率根据公式(15)计算,衡量了一种方法在将检测到的时间窗口识别为表达时间窗口方面的准确性,而召回率则是根据公式(16)计算的,表示一种方法能够多么准确地识别出所有检测到的时间窗口中实际包含表达的时间窗口。

最后,我们使用F1分数来评估宏表达(MaE)和微表达(ME)的检测方法以及总体分析的性能。值得注意的是,MaE和ME的检测方法和评估是分开进行的。

3.3. Settings
在使用MEGC 2022数据集进行的实验中,分别在CAS(ME)2和SAMM Long Videos上训练模型,然后在CAS(ME)3和SAMM Challenge上进行评估。然后将检测到的MaE和ME时间窗口提交到大挑战系统(https://megc2022.grand-challenge.org)以获得结果。对于MEGC 2021,我们采用了(LOSO)交叉验证来消除主题偏差,并确保评估所有样本。
在这项实验中,对于CAS(ME)2和CAS(ME)3,k参数(表情间隔的平均长度的一半)计算为{6, 18},而对于SAMM Long Videos和SAMM Challenge(对于微表情采用较小的值,而对于宏表情采用较大的值),k参数计算为{37, 169}。在表情检测程序中,我们选择了t = 0.60,适用于MEGC 2022和MEGC 2021。
请注意,Swin Transformer有不同版本。我们选择了被称为Swin-T的微小版本作为我们模型的主干,它的模型大小和计算复杂度约为基本Swin Transformer(Swin-B)的0.25倍。我们在实验中使用的模型被称为SL-Swin-T,表示我们对Swin-T主干应用了SPT和LSA。我们使用了窗口大小M = 7,每个头的查询维度设置为d = 32,每个MLP的扩展层为α = 4。SL-Swin-T模型的其他架构超参数包括“Stage 1”中隐藏层的通道数C = 96和层数= {2, 2, 6, 2}。
在我们的所有实验中,模型是在NVIDIA GTX 2080 Ti上训练的。我们将epoch数设置为25,并使用学习率为5 × 10^-4的SGD优化器。在训练阶段,我们对每两个非表情帧中的一个进行采样。为了解决微表情训练过程中的小样本问题,我们应用了数据增强技术,包括高斯模糊(核大小为7 × 7),添加随机高斯噪声(N(0,1))和水平翻转。
3.4. Permormance
我们方法在MEGC 2022定位任务上的结果显示在表1中。表2将我们方法的结果与其他方法进行了比较,这些方法被分为传统方法和深度学习方法两类。结果的讨论以及MEGC 2021定位任务的详细信息在讨论部分提供。

表1。我们的方法在MEGC 2022定位任务中的性能比较。
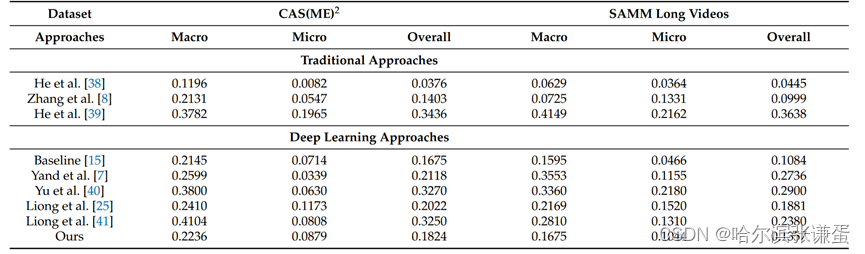
表二。在MEGC 2021定位任务中,我们的方法与其他模型的性能比较(F1分数)。
4. Discussion
4.1. MEGC 2022 Spotting Task
表1显示了我们方法在MEGC 2022定位任务上的结果。我们的模型表现优于基线方法,在CAS(ME)3数据集上获得了0.1944的F1分数,总体F1分数为0.1366。详细检查CAS(ME)3数据集的结果,我们的方法在召回率上更高,而精确率较低。这种效果归因于错误检测的间隔数量较小,导致False Negatives (FNs)的数量较少。与仅使用Swin Transformer背景的小型版本而没有SPT和LSA的方法相比,表中标记为Swin-T,我们的方法(SL-Swin-T)在所有指标上都表现更好,这表明SPT和LSA的应用提高了模型的泛化能力。

表1。我们的方法在MEGC 2022定位任务中的性能比较。
4.2. MEGC 2021 Spotting Task
为了比较,表2展示了我们方法在MEGC 2021定位任务上与其他方法的结果,这些方法分为传统方法和深度学习方法。总体而言,我们的方法优于基线,表明基于Transformer的模型可以与基于卷积神经网络的模型相比取得竞争性能。我们的方法在除了He等人提出的最先进方法之外的所有传统方法中表现优秀。在深度学习方法中,我们的方法仍然具有竞争力,特别是在CAS(ME)2数据集上进行ME定位,获得了0.0879的F1分数,仅次于Liong等人提出的方法,该方法能够定位更多的TP。通过检查表3中的细节,在CAS(ME)2数据集上,我们获得的FP数量是可比的,这归功于该数据集的优秀整体精度。

表二。在MEGC 2021定位任务中,我们的方法与其他模型的性能比较(F1分数)。

表3。SL-Swin-T模型在MEGC 2021定位任务上的详细结果。
4.3. Ablation Studies
我们进行了实验,对我们的方法进行了全面的检验,重点关注网络构建、标签函数和特征大小。实验在CAS(ME)2数据集上进行,使用了类似于MEGC 2021定位任务的设置。
4.3.1. Network Architecture
为了评估自注意机制、SPT 和 LSA 的有效性,我们进行了一项类似的实验,使用了不同的网络架构、SPT 和 LSA 的组合。这里,S 表示将 SPT 应用于网络,L 表示将 LSA 应用于网络,而 SL 表示同时应用了 SPT 和 LSA。表格 4 显示了各种网络架构的实验结果。根据我们的发现,SPT 和 LSA 的联合使用增强了网络在小规模数据集上的性能,特别是在 CAS(ME)2 上进行的 ME 定位任务。值得注意的是,Swin-T 模型及其基于它的模型的大小和计算复杂性仅为 ViT-B 和 SL-ViT-B 模型的约 0.25×。
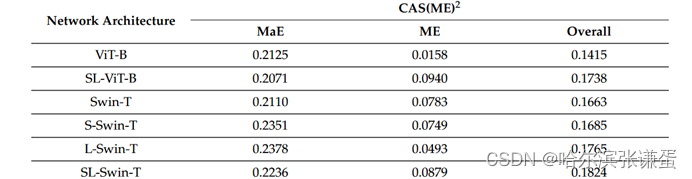
表4。我们的模型(SL-Swin-T)与其他基于变压器的模型的性能比较(F1分数)。
4.3.2. Labeling
进行了消融研究,对原始标记和伪标记函数进行了调查,以研究它们在将任务建模为回归问题时对定位的影响。我们设置参数 t = 0.60,并分别比较了在 SL-Swin-T 模型上使用原始标记和伪标记时的结果。结果如表 5 所示。可以观察到,应用伪标记减少了假阳性(FP)的数量,从而提高了精度和 F1 得分,特别是在整体分析中。

表5。伪标记和原始标记的性能比较。
4.3.3. Feature Size
在我们的方法中,SL-Swin-T 模型以大小为 (42, 42, 3) 的光流特征(u、v、|e|)作为输入。由于模型的每个阶段都进行了patch合并,特征图以 2 的倍数下采样,导致在“Stage 4”中只有原始光流特征中的 0.875 × 0.875 像素,即 42 /48 × 42/48 = 0.875 × 0.875。为了适应窗口配置,当特征图大小不是窗口大小 M = 7 的整数倍时,我们进行填充。由于这种分层结构和窗口内的自注意力计算,Swin Transformer 对于图像大小具有线性计算复杂性。这使得 Swin Transformer 适用于处理高分辨率图像,与以前基于 Transformer 的体系结构形成对比,后者生成单一分辨率的特征图并具有二次复杂性。因此,我们在特征提取和预处理中将超参数加倍,导致 (u、v、|e|) 的大小为 (84, 84, 3),允许在模型的“Stage 4”中使用来自原始光流特征的 84 ×/48 × 84 /48 = 1.75 × 1.75 像素。SL-Swin-T 模型和训练配置的超参数保持不变,用于比较的定位参数 t 设置为 0.60。ME 定位的实验结果见表 6,表明该模型在所有指标上的表现更好,尤其在 F1 得分方面表现强劲。

表6。光流特性大小的性能比较。
4.4. Limitations and Future Work
尽管我们的方法展示了令人期待的结果,但我们也认识到其局限性以及未来研究的潜在方向。首先,尽管我们使用了Swin Transformer的微小版本来构建我们的模型,但与基于CNN的模型相比,它仍然相当大且更为复杂,这在复现结果和进行LOSO实验时带来了挑战。特别是,与在MEGC 2021定位任务的SAMM Long Videos数据集上的ME定位实验相比,MaE定位实验需要额外的一周时间。此外,传统方法可以为表达的发生提供详细的解释,而我们的十二层模型基本上起到了黑盒的作用。因此,找到一种有效的方法来解释模型从训练数据中学到的内容是至关重要的。这有助于改进特征提取和预处理阶段。
其次,我们的模型在表达定位方面的性能并不像在其他任务上那么令人满意。这可能归因于其对训练配置的敏感性,如批量大小、epoch数和学习速率。因此,我们认为我们的调优并未充分展示应用SPT和LSA的优势。因此,为了优化模型性能,我们建议使用精细调整技术,例如在其他数据集上对模型进行预训练,或尝试专为小型数据集设计的不同损失和优化函数。
第三,尽管将输入特征大小增加到(84, 84, 3)已被证明可以提高模型性能,但这仍然远小于Swin Transformer假定的输入大小为224 × 224。因此,有理由期望利用更大的输入分辨率可能会进一步改善结果。然而,值得注意的是,较大的输入分辨率意味着更高的计算复杂性,需要先进的硬件和更多的实验时间。同时,使用具有更大骨干结构的模型,例如Swin Transformer的小版本(Swin-S)或基础版本(Swin-B),可能在高分辨率输入上表现更好,尽管计算成本更高。因此,在性能提升和可用资源之间取得平衡至关重要。
5. Conclusions
在本文中,我们提出了一种深度学习方法,使用一种基于Transformer的模型,称为SL-Swin,该模型将Shifted Patch Tokenization和Locality Self-Attention集成到骨干Swin Transformer网络中,通过分析光流特征预测一个表示帧可能处于表情区间内的概率分数。结果表明,我们的方法在MEGC 2022和MEGC 2021的定位任务上具有很强的性能,表明我们的方法在准确识别小型数据集中的表情方面具有潜力,并突显了我们的方法在大规模标记的表情数据集不容易获得的情况下的实用性。我们的评估结果超过了MEGC 2022定位任务的基准结果,获得了0.1366的总体F1分数。此外,我们的方法在MEGC 2021定位任务上表现良好,在CAS(ME)2上实现了0.1824的F1分数,在SAMM Long Videos上实现了0.1357的F1分数。我们的工作显示了Transformer-based模型随着数据量增加而取得更好性能的潜力。未来,研究人员可以轻松地加深提出的模型、增加其规模或应用其他针对小型数据集设计的技术,以提高其定位性能。此外,由于ME注释过程中的挑战,研究人员可能考虑实施自监督学习,使网络能够学习更有意义的潜在表示。
资助:本研究得到工程学院建设专项基金(编号46201503)资助。