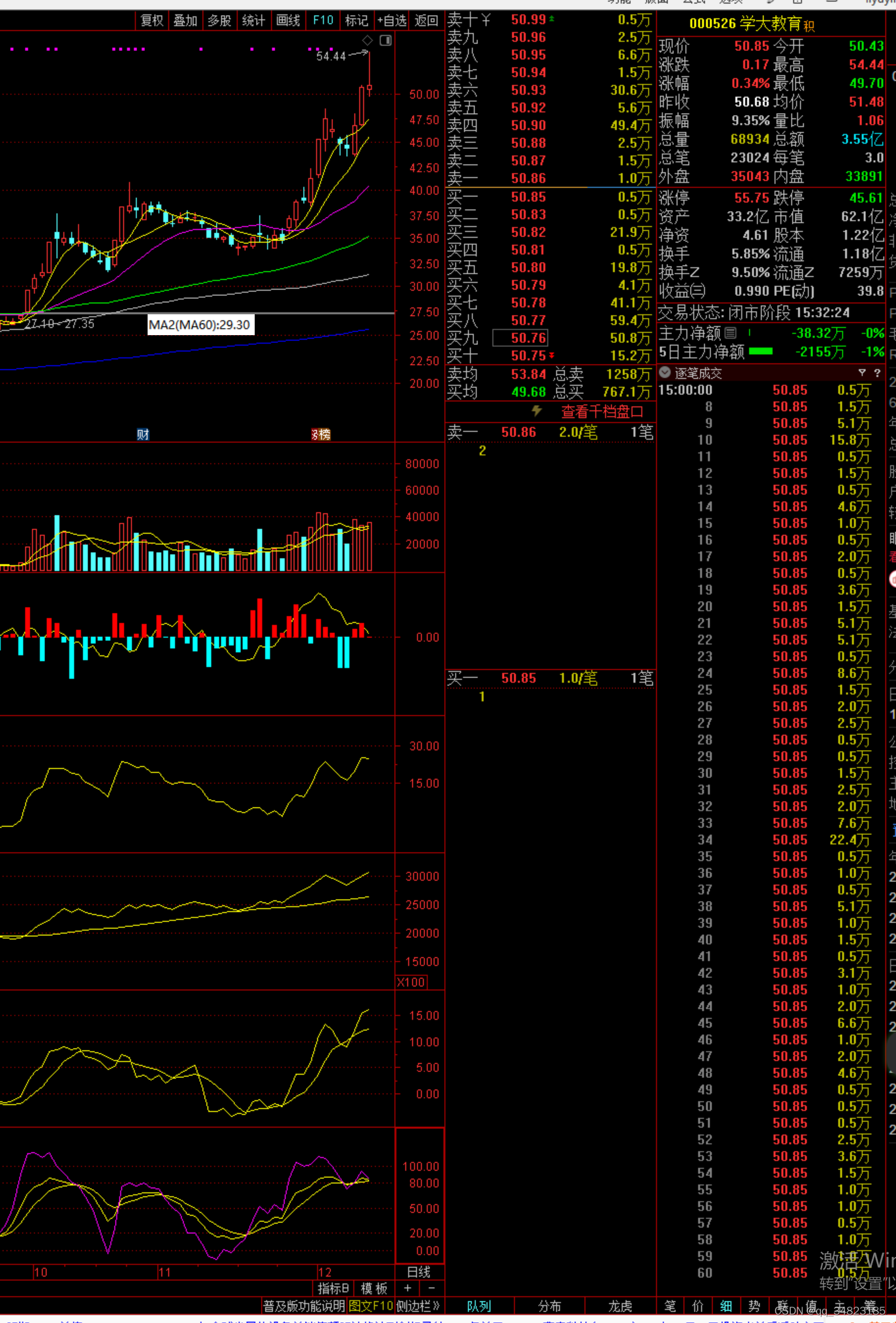
XGBoost和LightGBM都是目前非常流行的基于决策树的机器学习模型,它们都有着高效的性能表现,但是在某些情况下,它们也有着不同的特点。

XGBoost和LightGBM简单对比
训练速度
LightGBM相较于xgboost在训练速度方面有明显的优势。这是因为LightGBM使用了一些高效的算法和数据结构,比如直方图算法和基于梯度单边采样算法(GOSS),这些算法使得LightGBM在训练大规模数据集时速度更快。
内存消耗
由于LightGBM使用了一些高效的算法和数据结构,因此其内存消耗相对较小。而xgboost在处理大规模数据集时可能会需要较大的内存。
鲁棒性
xgboost在处理一些不规则数据时更加鲁棒,比如一些缺失值和异常值。而LightGBM在这方面相对较弱。
精度
在相同的数据集和参数设置下,两个模型的精度大致相当。不过在某些情况下,xgboost可能表现得更好,比如在特征数较少的情况下,或者是需要更加平滑的决策树时。
参数设置
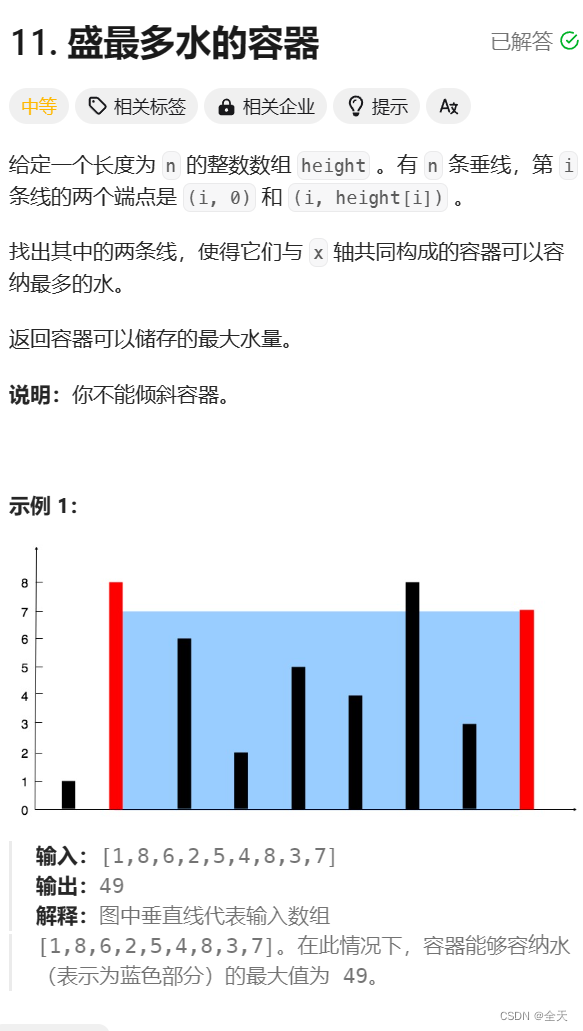
xgboost的参数比较多,需要根据实际情况进行调整。而LightGBM的参数相对较少,大多数情况下使用默认参数即可。
XGBoost和 LightGBM 算法对比
XGBoost和 LightGBM 都是基于决策树的梯度提升框架,它们的核心思想都是通过组合多个弱学习器来提升模型的预测能力。它们在实现上有很多相似之处,但在算法方面有一些明显的不同:
分裂点选择方法
在构建决策树时,xgboost 采用的是一种贪心算法,称为 Exact Greedy Algorithm,它会枚举每一个特征的每一个取值作为分裂点,然后计算对应的增益值,选取最大增益的分裂点作为最终的分裂点。
而 LightGBM 使用的是一种基于梯度单边采样(Gradient-based One-Side Sampling,GOSS)和直方图算法的分裂点选择方法,它会先对数据进行预排序,然后将数据划分成若干个直方图,每个直方图包含多个数据点。在寻找最优分裂点时,LightGBM 只会在直方图中选取一个代表点(即直方图中的最大梯度值)进行计算,这样大大降低了计算量。
特征并行处理
xgboost 将数据按特征进行划分,然后将每个特征分配到不同的节点上进行计算。这种方法可以有效提高训练速度,但需要额外的通信和同步开销。
LightGBM 将数据按行进行划分,然后将每个分块分配到不同的节点上进行计算。这种方法避免了通信和同步开销,但需要额外的内存空间。
处理缺失值
xgboost 会自动将缺失值分配到左右子树中概率更高的那一边。这种方法可能会引入一些偏差,但对于处理缺失值较多的数据集比较有效。
LightGBM 则采用的方法称为 Zero As Missing(ZAM),它将所有的缺失值都视为一个特殊的取值,并将其归入其中一个子节点中。这种方法可以避免偏差,但需要更多的内存空间。
训练速度
LightGBM 在训练速度方面具有显著优势,这是因为它使用了 GOSS 和直方图算法,减少了计算量和内存消耗。而 xgboost 的计算速度相对较慢,但是在处理较小的数据集时表现良好。
电力能源消耗预测
在当今世界,能源是主要的讨论点之一,能够准确预测能源消费需求是任何电力公司的关键,所以我们这里以能源预测为例,对这两个目前最好的表格类数据的模型做一个对比。
我们使用的是伦敦能源数据集,其中包含2011年11月至2014年2月期间英国伦敦市5567个随机选择的家庭的能源消耗。我们将这个集与伦敦天气数据集结合起来,作为辅助数据来提高模型的性能。
1、预处理
在每个项目中,我们要做的第一件事就是很好地理解数据,并在需要时对其进行预处理:
import pandas as pd
import matplotlib.pyplot as plt
df = pd.read_csv("london_energy.csv")
print(df.isna().sum())
df.head()
“LCLid”是标识每个家庭的唯一字符串,“Date”就是我们的时间索引,“KWH”是在该日期花费的总千瓦时数,没有任何缺失值。由于我们想要以一般方式而不是以家庭为单位来预测耗电量,所以我们需要将结果按日期分组并平均千瓦时。
df_avg_consumption = df.groupby("Date")["KWH"].mean()
df_avg_consumption = pd.DataFrame({"date": df_avg_consumption.index.tolist(), "consumption": df_avg_consumption.values.tolist()})
df_avg_consumption["date"] = pd.to_datetime(df_avg_consumption["date"])
print(f"From: {df_avg_consumption['date'].min()}")
print(f"To: {df_avg_consumption['date'].max()}")
我们来做一个折线图:
df_avg_consumption.plot(x="date", y="consumption")

季节性特征非常明显。冬季能源需求很高,而夏季的消耗是最低的。这种行为在数据集中每年都会重复,具有不同的高值和低值。可视化一年内的波动:
df_avg_consumption.query("date > '2012-01-01' & date < '2013-01-01'").plot(x="date", y="consumption")

训练像XGBoost和LightGB这样的模型,我们需要自己创建特征。因为目前我们只有一个特征:日期。所欲需要根据完整的日期提取不同的特征,例如星期几、一年中的哪一天、月份和其他日期:
df_avg_consumption["day_of_week"] = df_avg_consumption["date"].dt.dayofweek
df_avg_consumption["day_of_year"] = df_avg_consumption["date"].dt.dayofyear
df_avg_consumption["month"] = df_avg_consumption["date"].dt.month
df_avg_consumption["quarter"] = df_avg_consumption["date"].dt.quarter
df_avg_consumption["year"] = df_avg_consumption["date"].dt.year
df_avg_consumption.head()
' date '特征就变得多余了。但是在删除它之前,我们将使用它将数据集分割为训练集和测试集。与传统的训练相反,在时间序列中,我们不能只是以随机的方式分割集合,因为数据的顺序非常重要,所以对于测试集,将只使用最近6个月的数据。如果训练集更大,可以用去年全年的数据作为测试集。
training_mask = df_avg_consumption["date"] < "2013-07-28"
training_data = df_avg_consumption.loc[training_mask]
print(training_data.shape)
testing_mask = df_avg_consumption["date"] >= "2013-07-28"
testing_data = df_avg_consumption.loc[testing_mask]
print(testing_data.shape)
可视化训练集和测试集之间的分割:
figure, ax = plt.subplots(figsize=(20, 5))
training_data.plot(ax=ax, label="Training", x="date", y="consumption")
testing_data.plot(ax=ax, label="Testing", x="date", y="consumption")
plt.show()

现在我们可以删除' date '并创建训练和测试集:
# Dropping unnecessary `date` column
training_data = training_data.drop(columns=["date"])
testing_dates = testing_data["date"]
testing_data = testing_data.drop(columns=["date"])
X_train = training_data[["day_of_week", "day_of_year", "month", "quarter", "year"]]
y_train = training_data["consumption"]
X_test = testing_data[["day_of_week", "day_of_year", "month", "quarter", "year"]]
y_test = testing_data["consumption"]
2、训练模型
我们这里的超参数优化将通过网格搜索完成。因为是时间序列,所以不能只使用普通的k-fold交叉验证。Scikit learn提供了TimeSeriesSplit方法,这里可以直接使用。
from xgboost import XGBRegressor
import lightgbm as lgb
from sklearn.model_selection import TimeSeriesSplit, GridSearchCV
# XGBoost
cv_split = TimeSeriesSplit(n_splits=4, test_size=100)
model = XGBRegressor()
parameters = {
"max_depth": [3, 4, 6, 5, 10],
"learning_rate": [0.01, 0.05, 0.1, 0.2, 0.3],
"n_estimators": [100, 300, 500, 700, 900, 1000],
"colsample_bytree": [0.3, 0.5, 0.7]
}
grid_search = GridSearchCV(estimator=model, cv=cv_split, param_grid=parameters)
grid_search.fit(X_train, y_train)
对于LightGB,代码是这样的:
# LGBM
cv_split = TimeSeriesSplit(n_splits=4, test_size=100)
model = lgb.LGBMRegressor()
parameters = {
"max_depth": [3, 4, 6, 5, 10],
"num_leaves": [10, 20, 30, 40, 100, 120],
"learning_rate": [0.01, 0.05, 0.1, 0.2, 0.3],
"n_estimators": [50, 100, 300, 500, 700, 900, 1000],
"colsample_bytree": [0.3, 0.5, 0.7, 1]
}
grid_search = GridSearchCV(estimator=model, cv=cv_split, param_grid=parameters)
grid_search.fit(X_train, y_train)
3、评估
为了评估测试集上的最佳估计量,我们将计算:平均绝对误差(MAE)、均方误差(MSE)和平均绝对百分比误差(MAPE)。因为每个指标都提供了训练模型实际性能的不同视角。我们还将绘制一个折线图,以更好地可视化模型的性能。
from sklearn.metrics import mean_absolute_error, mean_absolute_percentage_error,\
mean_squared_error
def evaluate_model(y_test, prediction):
print(f"MAE: {mean_absolute_error(y_test, prediction)}")
print(f"MSE: {mean_squared_error(y_test, prediction)}")
print(f"MAPE: {mean_absolute_percentage_error(y_test, prediction)}")
def plot_predictions(testing_dates, y_test, prediction):
df_test = pd.DataFrame({"date": testing_dates, "actual": y_test, "prediction": prediction })
figure, ax = plt.subplots(figsize=(10, 5))
df_test.plot(ax=ax, label="Actual", x="date", y="actual")
df_test.plot(ax=ax, label="Prediction", x="date", y="prediction")
plt.legend(["Actual", "Prediction"])
plt.show()
然后我们运行下面代码进行验证:
# Evaluating GridSearch results
prediction = grid_search.predict(X_test)
plot_predictions(testing_dates, y_test, prediction)
evaluate_model(y_test, prediction)
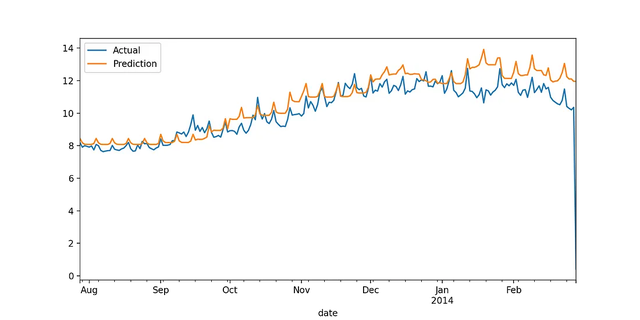
XGB:
LightGBM:
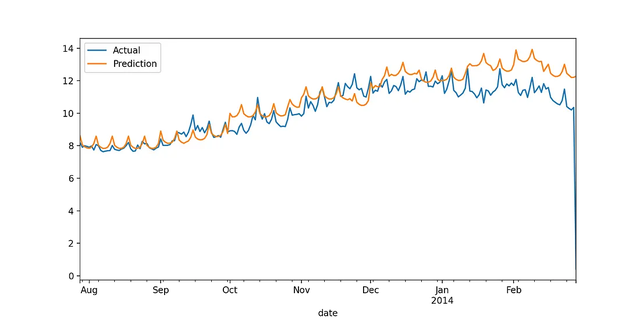
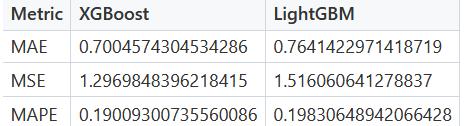
从图上可以看到,XGBoost可以更准确地预测冬季的能源消耗,但为了量化和比较性能,我们计算误差指标。通过查看下面的表,可以很明显地看出XGBoost在所有情况下都优于LightGBM。
使用外部辅助天气数据
该模型表现还不错,我们看看还能不能提高呢?为了达到更好的效果,可以采用许多不同的技巧和技巧。其中之一是使用与能源消耗直接或间接相关的辅助特征。例如,在预测能源需求时,天气数据可以发挥决定性作用。这就是为什么我们选择使用伦敦天气数据集的天气数据的原因。
首先让我们来看看数据的结构:
df_weather = pd.read_csv("london_weather.csv")
print(df_weather.isna().sum())
df_weather.head()
这个数据集中有各种缺失的数据需要填充。填充缺失的数据也不是一件简单的事情,因为每种不同的情况填充方法是不同的。我们这里的天气数据,每天都取决于前几天和下一天,所以可以通过插值来填充这些值。另外还需要将' date '列转换为' datetime ',然后合并两个DF,以获得一个增强的完整数据集。
# Parsing dates
df_weather["date"] = pd.to_datetime(df_weather["date"], format="%Y%m%d")
# Filling missing values through interpolation
df_weather = df_weather.interpolate(method="ffill")
# Enhancing consumption dataset with weather information
df_avg_consumption = df_avg_consumption.merge(df_weather, how="inner", on="date")
df_avg_consumption.head()
在生成增强集之后,必须重新运行拆分过程获得新的' training_data '和' testing_data '。
# Dropping unnecessary `date` column
training_data = training_data.drop(columns=["date"])
testing_dates = testing_data["date"]
testing_data = testing_data.drop(columns=["date"])
X_train = training_data[["day_of_week", "day_of_year", "month", "quarter", "year",\
"cloud_cover", "sunshine", "global_radiation", "max_temp",\
"mean_temp", "min_temp", "precipitation", "pressure",\
"snow_depth"]]
y_train = training_data["consumption"]
X_test = testing_data[["day_of_week", "day_of_year", "month", "quarter", "year",\
"cloud_cover", "sunshine", "global_radiation", "max_temp",\
"mean_temp", "min_temp", "precipitation", "pressure",\
"snow_depth"]]
y_test = testing_data["consumption"]
训练步骤不需要做更改。在新数据集上训练模型后,我们得到以下结果:
XGBoost
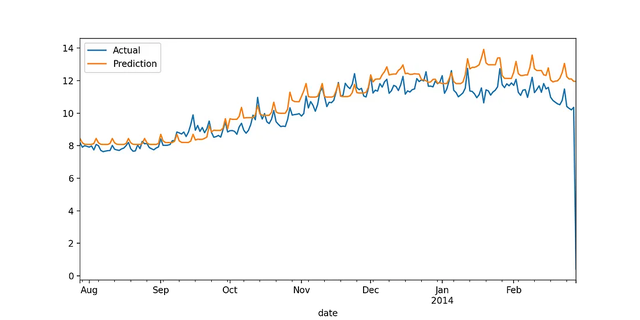
LightGBM

整合上面的表格:

我们看到:天气数据大大提高了两个模型的性能。特别是在XGBoost场景中,MAE减少了近44%,而MAPE从19%减少到16%。对于LightGBM, MAE下降了42%,MAPE从19.8%下降到16.7%。
总结
xgboost 和 LightGBM 都是优秀的梯度提升框架,它们各自具有一些独特的优点和缺点,选择哪一种算法应该根据实际应用场景和数据集的特征来决定。如果数据集中缺失值较多,可以选择 xgboost。如果需要处理大规模数据集并追求更快的训练速度,可以选择 LightGBM。如果需要解释模型的特征重要性,xgboost 提供了更好的特征重要性评估方法,并且如果需要更加鲁棒的模型,可以优先选择xgboost。
在本文中我们还介绍了一种提高模型的方法,就是使用附加数据,通过附加我们认为相关的辅助数据,也可以大大提高模型的性能。
除此以外,我们还可以结合滞后特征或尝试不同的超参数优化技术(如随机搜索或贝叶斯优化),来作为提高性能的尝试,如果你有任何新的结果,欢迎留言。
文章出处,入侵吾删