正文
这次先来看一段NCNN应用代码中,最先出现的部分,模型加载
ncnn::Net squeezenet;
squeezenet.load_param("squeezenet_v1.1.param");
squeezenet.load_model("squeezenet_v1.1.bin");
首先我们可以看到一个 ncnn的类Net,这个就是用来记录网络的,我们跳过这个,有四个东西是我们比较关心的:
方法:load_parm和load_model
文件:*.param 和 *.bin(可以用netron可视化)
一、Load_parm
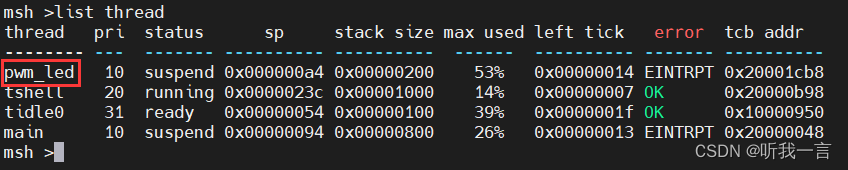
load_parm的具体代码在net.cpp的第92行处,考虑到该函数是加载param文件的,squeezenet_v1.1.param的内容,其中的各部分的含义我都按照源码的变量名指示了出来,看图:
在一个param文件里面,只有第一行与其他行的区别。
1. 第一行
- 第一个数:表示了该param所表示的模型,共有多少layer,,layer的值是从第二行开始一直数下去的,所以如果增删了某几行,这里也要对应修改。
- 第二个数:表示了该某些有多少个blob,可以理解成有多少个数据流节点。例如一个卷积就是一个输入blob一个输出blob,数据其实就是在blob之间流来流去。
2. 其他行:除了第一行,其他的都是layer行,上图用第三行举例,具体行内容依次为:
-
layer_type:该行layer对应的类型,如 Convolution、Pooling、ReLU 等。每种类型的层执行不同的操作,并具有不同的参数和配置。
-
layer_name:该行layer的名字,这是为网络中的每一层指定的唯一名称。它用于在网络的定义中引用特定的层,模型导出的时候导出工具自动生成的
-
bottom_count:这表示一个层的输入数量。在神经网络中,某些层可能从一个或多个其他层接收输入数据。bottom_count 指明了该层需要接收多少个输入。这层可以理解为我这个小弟上面有多少个大哥。
-
top_count:这表示一个层的输出数量。某些层可能向一个或多个其他层输出数据。top_count 指出该层产生多少个输出。该层参数可以理解为我这个大哥下面有多少个小弟。
-
bottom_name:这些是输入到该层的底部(或输入)blob(数据块)的名称。在 NCNN 中,blob 是指流经网络的数据。每个 blob 有一个唯一的名称,这样在定义网络时可以清楚地指出数据从哪里来,到哪里去。上面大哥叫什么名字
-
blob_name:这些是该层输出的顶部(或输出)blob的名称。这些名称用于在网络定义中将这些数据传递到其他层。我下面小弟叫什么名字。
-
特有参数:这个是该layer特有的一些参数,不是同一参数,由各具体layer实例读。例如卷积有有kernel_size、stride_size、padding_size,ReLU又是无参的,softmax则需要一个指示维度的参数,具体参具体分析。
代码详细分析如下:
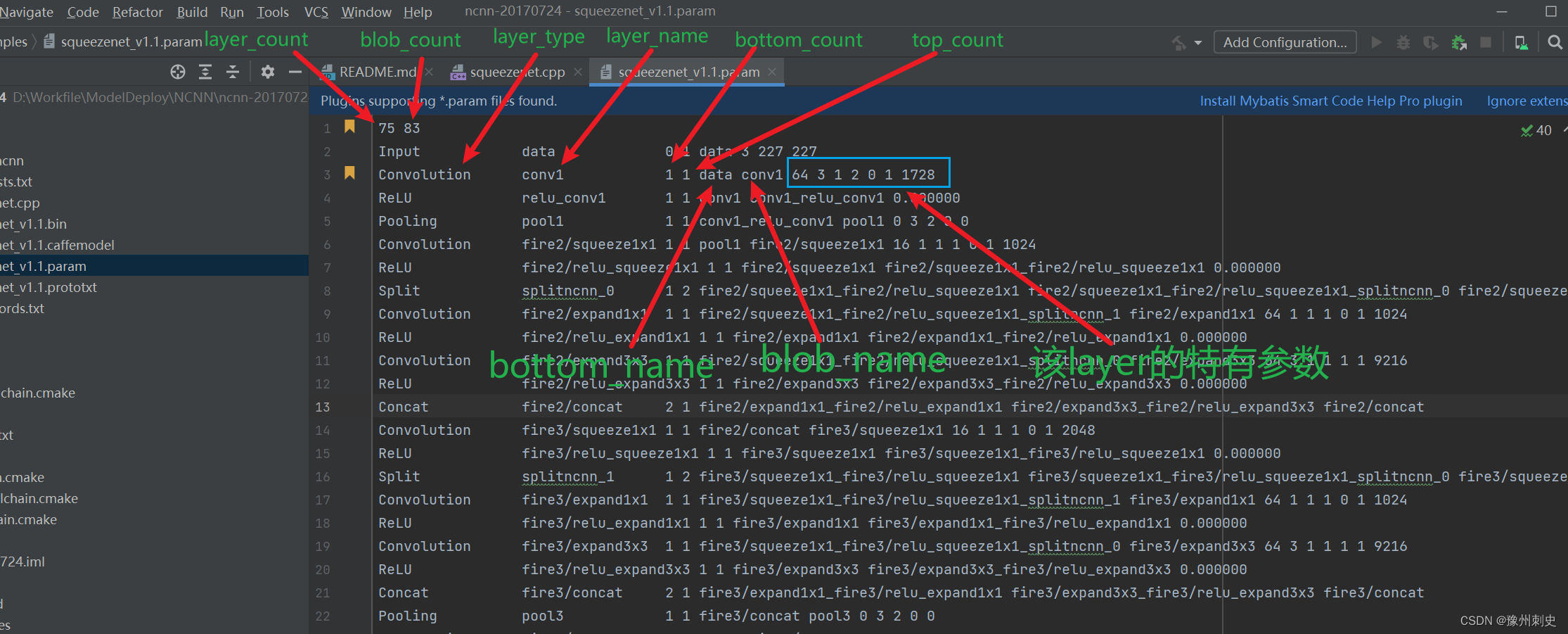
75 83
Input data 0 1 data 3 227 227
Convolution conv1 1 1 data conv1 64 3 1 2 0 1 1728
ReLU relu_conv1 1 1 conv1 conv1_relu_conv1 0.000000
Pooling pool1 1 1 conv1_relu_conv1 pool1 0 3 2 0 0
文件开头
- 78: 表示网络中层的数量。NCNN 中的每个层代表一个操作,如卷积、池化、激活等。
- 83: 表示网络中 blob 的总数。在 NCNN 中,blob 是指流经网络的数据,每个层的输入和输出都可以被视为一个或多个 blob。
各层定义
-
Input Layer:
Input: 层的类型,这里表示它是一个输入层。data: 层的名称,这里将该层命名为data。0: 输出数量,输入层不产生输出,所以是0。1: 输入数量,这是一个常规的输入层,因此只有一个输入(即图像本身)。data: 输入blob的名称。3,227,227: 输入数据的维度。这里指的是输入图像有3个通道(彩色图像),宽和高分别为227像素。
-
Convolution Layer:
Convolution: 层的类型,表示这是一个卷积层。conv1: 层的名称。1: 输出数量,这层有一个输出。1: 输入数量,这层有一个输入。data: 输入blob的名称,即接受data层的输出作为输入。conv1: 输出blob的名称。64: 卷积核的数量。3: 卷积核的尺寸(宽和高),这里是3x3。1: 步长,表示卷积操作在宽和高方向上的移动步长。2: 填充,表示在输入数据的周围添加的零的层数。0: 群组数量,用于分组卷积。1: 卷积方式,1表示使用常规卷积。1728: 权重数据的数量。
-
ReLU Layer:
ReLU: 层的类型,表示这是一个激活层,使用ReLU激活函数。relu_conv1: 层的名称。1: 输出数量。1: 输入数量。conv1: 输入blob的名称,接受conv1层的输出。conv1_relu_conv1: 输出blob的名称。0.000000: ReLU激活函数的负斜率(Leaky ReLU的参数),这里为0表示标准ReLU。
-
Pooling Layer:
Pooling: 层的类型,表示这是一个池化层。pool1: 层的名称。1: 输出数量。1: 输入数量。conv1_relu_conv1: 输入blob的名称,接受relu_conv1层的输出。pool1: 输出blob的名称。0: 池化方式,0通常表示最大池化。3: 池化核的尺寸。2: 步长,表示池化操作的移动步长。0: 填充,表示在输入数据周围添加的零的层数。0: 全局池化标志,0表示不使用全局池化。
有了param文件的分析,我们结合源码对比写出load_param的伪代码了:
# layer列表,存下所有layer
# blobs列表,背后维护,为find_blob服务
layer_count, blob_count = read(param_file
for param_file is not EOF: # 循环读取每一行的layer数据
layer_type, layername, bottom_count, top_count = read(param_file) # 读取前四个固定参数
layer = create_layer(layer_type) # 根据layer类型创建一个layer
for bottom_count:
bottom_name = read(param_file) # 读取每一个bottom_name
blob = find_blob(bottom_name) # 查找该blob,没有的话就要新建一个
blob.consumers.append(layer) # 当前层是这个blob的消费者,这里的blob是是大哥,当前层是小弟,没钱花找大哥要
layer.bootoms.append(blob) # 记住谁才是你的大哥
for top_count:
blob_name = read(param_file) # 读取每一个blob_name
blob = find_blob(bottom_name) # 查找该blob,没有的话就要新建一个
blob.producer = layer # 当前层是这个blob的生产者,这里的blob是小弟,当前层是大哥
layer.tops.append(blob) # 花名册上把小弟名字写一些
layer.param = read(param_file)
layers.append(layer)
其实整个流程是很简单,对于某一层数据来说,首先要认清自己的身份,记住谁是你的大哥(bottom_name),记住谁是你的小弟(blob_name),认清自己几斤几两(特有参数)。
后面的load_model这里暂不分析,因为这里涉及到layer的特有参数,这个我们后面拉几个layer单独分析。
这里大哥小弟思想是受到一篇帖子的启发链接,感觉挺有意思的。
- 方案一:每个人都发,大家都有钱,有些小弟还不需要钱,你也给他发了
- 优点:每个人你都发了,缺钱也别来问,都给你了(直接完整推理,要什么数据取就行了)
- 缺点:大哥都发出去了,累死累活的(全部计算量)
- 方案二:来要钱才给他,有些不要钱的不给了
- 优点:大哥省事,谁要给谁(节省计算量)
- 缺点:每个小弟要钱都要往上打报告,大哥再给他们发(取不同节点数据中间需要再推理)