1.Introduction
大多数视频生成主要关注文本到视频的生成,PixelDance在文本指令的基础上,将图像指令分别用于视频剪辑的第一帧和最后一帧,第一帧图像指令描绘了视频剪辑的主要场景,最后一帧图像是可选的,描述了剪辑的结尾,并为生成提供了额外的控制。以<文本,第一帧,最后一帧>为指令,文本指令由预训练的文本编码器编码,与unet进行cross-attention,图像由预训练的VAE编码和扰动的视频潜变量或高斯噪声串联编码,作为输入传递给扩散模型,在训练中,使用真实的第一帧来强制模型严格遵循指令,保持连续性。模型有15亿参数。在各种复杂的场景中创作了首个具有清晰故事情节的三分钟视频,角色在各个场景中保持一致。

2.Related work
2.1 Video Generation
GAN、VQVAE-transformer,将temporal convs和temporal attention添加到预训练的文本到图像的扩散模型的2D unet中。视频生成和视频编辑。
2.2 Long video Generation
需要在连续的视频片段之间实现平滑过渡,保持场景和角色的长期一致性。1.自回归,在生成新片段时以迁移片段为条件使用滑动窗口;2.分层方法,先生成稀疏帧,再插帧。PixelDance以自回归的方式生成连续视频片段。
3.method
3.1 Model architecture
3.1.1 Latent diffusion architecture
LDM是在VAE潜空间中从受扰动输入中去噪的模型。使用2d unet,通过在空间维度插入temporal layer,将2d unet扩展为3d unet,其中2d conv沿temporal维度使用1d attention,模型可以同时训练图像和视频,以保持在空间维度上的高保真度生成能力。temporal attention层中使用bi-self-attention,使用预训练的CLIP文本编辑器对文本指令进行编码,通过cross-attention将text嵌入unet,hidden states作为query,text作为key和value。
3.1.2 Image Instruction Injection
将第一帧和最后一帧的图像和文本结合,在训练中,使用真实的视频帧作为指令,指定第一帧和最后一帧,使用VAE将其编码到扩散模型的输入空间中,采用[first,PAD,last],将image条件和加噪的潜变量沿通道维度连接,作为扩散模型的输入。
3.2 Training and inference
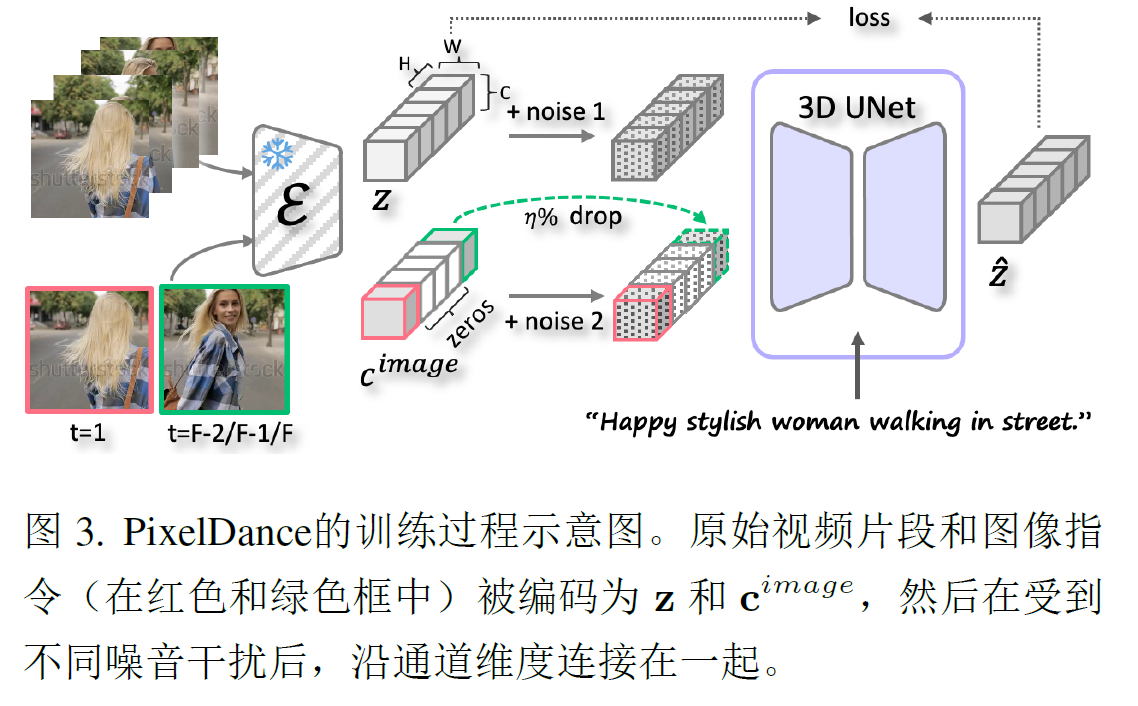
对于第一帧,使用真实第一帧来训练,使模型在推理中严格遵循第一帧的指令。相比之下,有意的避免鼓励模型完全复制最后一帧的指令,在推理时,预先无法获得真实的最后一帧,模型需要根据用户提供的粗略草图进行引导,以生成时间连贯的视频。引入了三种技术,1.从一个剪辑的最后三帧真实图像中随机选择一张图像作为最后一帧的指令进行训练;2.对图像指令的潜在code进行噪声扰动;3.在训练过程中以概率n随机丢弃最后一帧的指令,将相应的潜在code变成0。相应的,在推理时,在总共T个去噪步骤中的钱t个步骤中,使用最后一帧的指令来引导视频生成,以达到期望的技术状态后,在后续步骤中丢弃该指令。推理中使用classifer-free guidance。
4.Experiments
4.1 Implementation details
在WebVid-10M上训练了视频扩散模型,该数据集包含约1000w个短视频片段,平均持续时间为18s,分辨率主要为336x596。每个视频斗鱼一段文本相关联,该文本通常只提供与视频内容弱相关的粗略描述。此外WebVid-10M所有视频上都有水印,自采集了500k的视频剪辑,粗粒度的文本描述对。
PixelDance同时在视频-文本数据集和图像-文本数据集上进行训练,对于视频数据,每个视频随机采样16个连续帧,每秒读4帧,采用LAION-400M作为图像-文本数据集,图像-文本数据每8个训练迭代进行一次利用,这块还挺特别,是图文和视频文本同时在训练的。预训练的文本编码器和VAE模型的权重在训练时冻结,使用DDPM训练,首先在分辨率为256x256模型上训练,bs为192,在32个A100上进行200k迭代,然后在更高分辨率上微调50k。
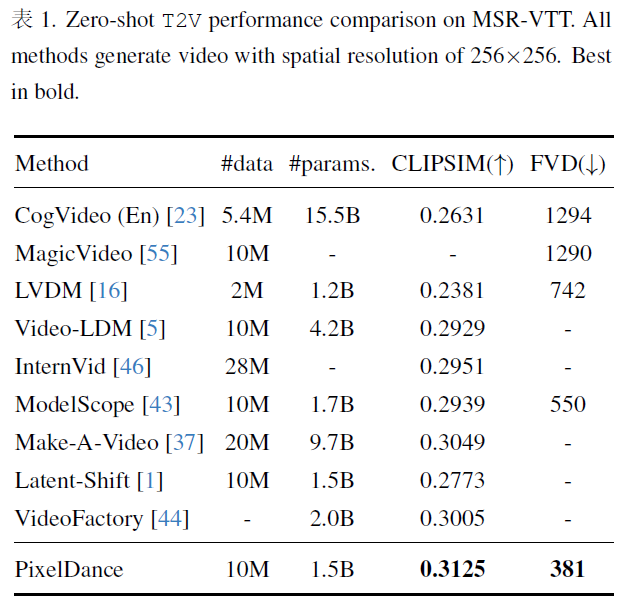
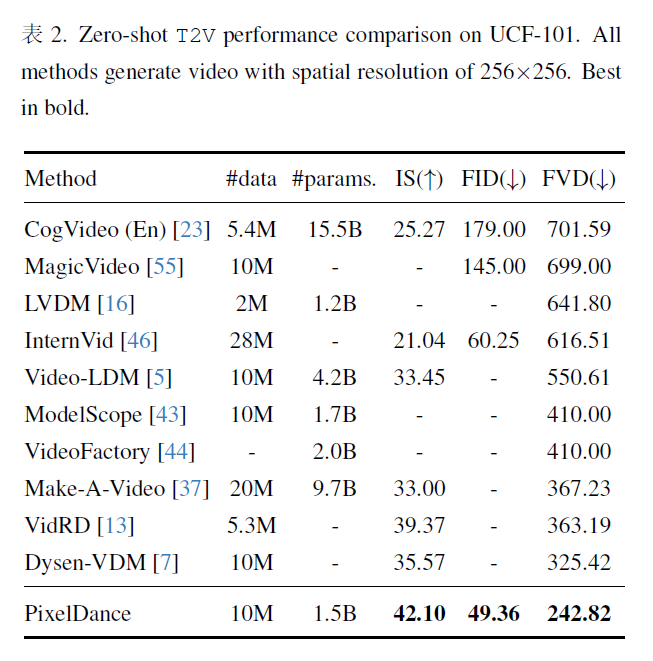
5.mode
第一种模式为base模式,只需要提供一张指导图片和相应文本描述;
第二种模式为高级模式,用户需要提交两张指导图片和相关描述文本描述;