微信公众号:愤怒的it男,超多Python技术干货文章。
一、jieba的简介
在自然语言处理任务时,中文文本需要通过分词获得单个的词语,此时一个好的分词工具是非常有必要的。jieba分词是一个开源项目,地址为:github.com/fxsjy/jieba。目前是国内最好的中文分词Python库,它在分词准确度和速度方面均表现非常不错。
二、jieba的安装
使用pip安装,由于官方源在国外,可能由于网络超时而导致安装失败,这里建议使用国内的镜像源:
阿里云镜像:https://mirrors.aliyun.com/pypi/simple/
清华大学镜像:https://pypi.tuna.tsinghua.edu.cn/simple/
豆瓣镜像:https://pypi.doubanio.com/simple/
中科大镜像:https://mirrors.tuna.tsinghua.edu.cn/pypi/web/simple/
pip的安装命令如下:
pip install jieba -i https://mirrors.aliyun.com/pypi/simple/
三、中文分词
1、默认模式分词
默认模式分词使用jieba.cut或jieba.lcut方法,都是接受四个输入参数:
(1)需要分词的字符串
(2)cut_all:True为采用全面分词,False为采用精准分词
(3)HMM:是否使用HMM模型,HMM默认为True
(4)use_paddle:是否使用PaddlePaddle深度学习框架分词
jieba.cut返回的是迭代生成器,而jieba.lcut返回的是列表
import jieba
text = '微信公众号:愤怒的it男,超多Python技术干货文章。'
seg_list = jieba.cut(text, cut_all=True)
print("/".join(seg_list))
# 微/信/公众/号/:/愤怒/的/it/男/,/超/多/Python/技术/干货/文章/。
seg_list = jieba.cut(text, cut_all=False)
print("/".join(seg_list))
# 微信/公众/号/:/愤怒/的/it/男/,/超多/Python/技术/干货/文章/。
seg_list = jieba.lcut(text, cut_all=True)
print(seg_list)
# ['微', '信', '公众', '号', ':', '愤怒', '的', 'it', '男', ',', '超', '多', 'Python', '技术', '干货', '文章', '。']
seg_list = jieba.lcut(text, cut_all=False)
print(seg_list)
# ['微信', '公众', '号', ':', '愤怒', '的', 'it', '男', ',', '超多', 'Python', '技术', '干货', '文章', '。']
2、搜索引擎模式分词
搜索引擎模式分词使用jieba.cut_for_search或jieba.lcut_for_search方法,都是接受两个输入参数:
(1)需要分词的字符串
(2)HMM:是否使用HMM模型,HMM默认为True
jieba.cut_for_search返回的是迭代生成器,而jieba.lcut_for_search返回的是列表,该分词模式适合用于搜索引擎构建排序索引的分词,粒度比较细
import jieba
text = '微信公众号:愤怒的it男,超多Python技术干货文章。'
seg_list = jieba.cut_for_search(text)
print("/".join(seg_list))
# 微信/公众/号/:/愤怒/的/it/男/,/超多/Python/技术/干货/文章/。
seg_list = jieba.lcut_for_search(text)
print(seg_list)
# ['微信', '公众', '号', ':', '愤怒', '的', 'it', '男', ',', '超多', 'Python', '技术', '干货', '文章', '。']
3、相关知识
HMM:隐马尔科夫模型,是一种用于处理生成序列数据问题的统计模型,被广泛应用于自然语言处理、语音识别等领域。
PaddlePaddle:飞桨,以百度多年的深度学习技术研究和业务应用为基础,集深度学习核心训练和推理框架、基础模型库、端到端开发套件、丰富的工具组件于一体,是中国首个自主研发、功能完备、开源开放的产业级深度学习平台。
四、自定义词典
1、载入字典
开发者可以使用自定义的字典,这样能够保证更高的分词正确率。字典为普通的txt文件,格式为一个词占一行,每一行分三部分:词语、词频(可省略)、词性(可省略),用空格隔开,顺序不可颠倒。
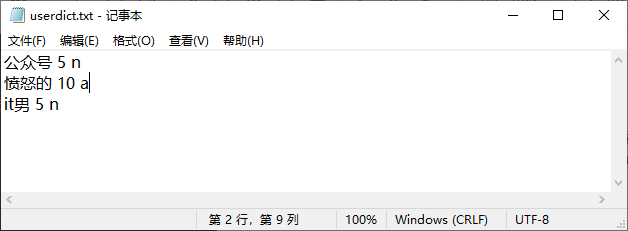
import jieba
text = '微信公众号:愤怒的it男,超多Python技术干货文章。'
jieba.load_userdict("userdict.txt")
seg_list = jieba.cut(text)
print("/".join(seg_list))
# 微信/公众号/:/愤怒/的/it男/,/超多/Python/技术/干货/文章/。
2、调整字典
(1)使用add_word(word,freq=None,tag=None)和del_word(word)可在程序中动态修改词典。
import jieba
text = '微信公众号:愤怒的it男,超多Python技术干货文章。'
jieba.add_word('公众号', freq=5, tag='n')
jieba.add_word('it男', freq=5, tag='n')
seg_list = jieba.cut(text)
print("/".join(seg_list))
# 微信/公众号/:/愤怒/的/it男/,/超多/Python/技术/干货/文章/。
jieba.del_word('公众号')
jieba.del_word('it男')
seg_list = jieba.cut(text)
print("/".join(seg_list))
# 微信/公众/号/:/愤怒/的/it/男/,/超多/Python/技术/干货/文章/。
(2)使用suggest_freq(segment,tune=True)可调节单个词语的词频,使其能(或不能)被分出来。
import jieba
text = '微信公众号:愤怒的it男,超多Python技术干货文章。'
seg_list = jieba.cut(text)
print("/".join(seg_list))
# 微信/公众/号/:/愤怒/的/it/男/,/超多/Python/技术/干货/文章/。
jieba.suggest_freq('公众号', True)
jieba.suggest_freq('it男', True)
jieba.suggest_freq(('超', '多'), True)
seg_list = jieba.cut(text)
print("/".join(seg_list))
# 微信/公众号/:/愤怒/的/it男/,/超/多/Python/技术/干货/文章/。
五、关键词提取
1、基于TF-IDF算法提取关键词
使用jieba.analyse.extract_tags基于TF-IDF算法提取关键词,其接受四个输入参数:
(1)sentence:待提取的文本
(2)topK:返回关键词的数量,默认为20
(3)withWeight:是否返回关键词权重值,默认为False
(4)allowPOS:返回指定词性的关键词,默认为空
使用jieba.analyse.set_idf_path设置逆向文件频率(IDF)语料库。逆向文件频率是文件频率的倒数,主要用于TF-IDF算法中。
使用jieba.analyse.set_stop_words设置停止词(Stop Words)语料库。停止词一般指‘的’,‘了’,‘和’等频率高但又不重要的词。
import jieba.analyse
text = '微信公众号:愤怒的it男,超多Python技术干货文章。'
seg_list = jieba.analyse.extract_tags(text, topK=2, withWeight=True, allowPOS=('n'))
print(seg_list)
# [('干货', 2.798156862725), ('公众', 1.6857355419325)]
2、基于TextRank算法提取关键词
使用jieba.analyse.textrank基于TextRank算法提取关键词,其接受四个输入参数:
(1)sentence:待提取的文本
(2)topK:返回关键词的数量,默认为20
(3)withWeight:是否返回关键词权重值,默认为False
(4)allowPOS:返回指定词性的关键词,默认为空
import jieba.analyse
text = '微信公众号:愤怒的it男,超多Python技术干货文章。'
seg_list = jieba.analyse.textrank(text, topK=2, withWeight=True, allowPOS=('n'))
print(seg_list)
# [('文章', 1.0), ('技术', 0.9966849915940917)]
六、词性标注
使用jieba.posseg.cut进行词性标注方式地分词,这对于文本挖掘的帮助很大。
import jieba.analyse
text = '微信公众号:愤怒的it男,超多Python技术干货文章。'
words = jieba.posseg.cut(text)
for word, flag in words:
print('%s %s' % (word, flag))
# 微信 vn
# 公众 n
# 号 m
# : x
# 愤怒 v
# 的 uj
# it eng
# 男 n
# , x
# 超多 v
# Python eng
# 技术 n
# 干货 n
# 文章 n
# 。 x
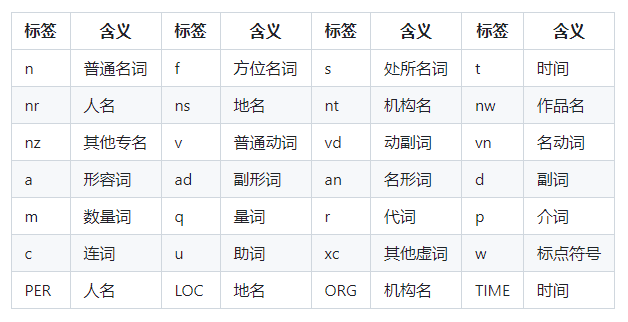
词性和专用名类别标签集合如下,其中词性标签24个(小写字母),专名类别标签4个(大写字母)。
七、分词定位
使用jieba.tokenize进行分词定位方式地分词,可以返回分词在原文的起止位置。其接受两个输入参数:
(1)待提取的文本,只接受unicode编码的文本
(2)mode:值为’search’则选择搜索引擎模式分词,值为空则选择默认模式分词
import jieba
text = u'微信公众号:愤怒的it男,超多Python技术干货文章。'
words = jieba.tokenize(text)
for word in words:
print("word %s\t\t start: %d \t\t end:%d" % (word[0],word[1],word[2]))
# word 微信 start: 0 end:2
# word 公众 start: 2 end:4
# word 号 start: 4 end:5
# word : start: 5 end:6
# word 愤怒 start: 6 end:8
# word 的 start: 8 end:9
# word it start: 9 end:11
# word 男 start: 11 end:12
# word , start: 12 end:13
# word 超多 start: 13 end:15
# word Python start: 15 end:21
# word 技术 start: 21 end:23
# word 干货 start: 23 end:25
# word 文章 start: 25 end:27
# word 。 start: 27 end:28
八、命令行分词
使用python -m jieba [options] filename使用jieba命令行界面。
固定参数:
filename 输入文件
可选参数:
-h, --help 显示此帮助信息并退出
-d [DELIM], --delimiter [DELIM]
使用 DELIM 分隔词语,而不是用默认的' / '。
若不指定 DELIM,则使用一个空格分隔。
-p [DELIM], --pos [DELIM]
启用词性标注;如果指定 DELIM,词语和词性之间
用它分隔,否则用 _ 分隔
-D DICT, --dict DICT 使用 DICT 代替默认词典
-u USER_DICT, --user-dict USER_DICT
使用 USER_DICT 作为附加词典,与默认词典或自定义词典配合使用
-a, --cut-all 全模式分词(不支持词性标注)
-n, --no-hmm 不使用隐含马尔可夫模型
-q, --quiet 不输出载入信息到 STDERR
-V, --version 显示版本信息并退出
如果没有指定文件名,则使用标准输入。
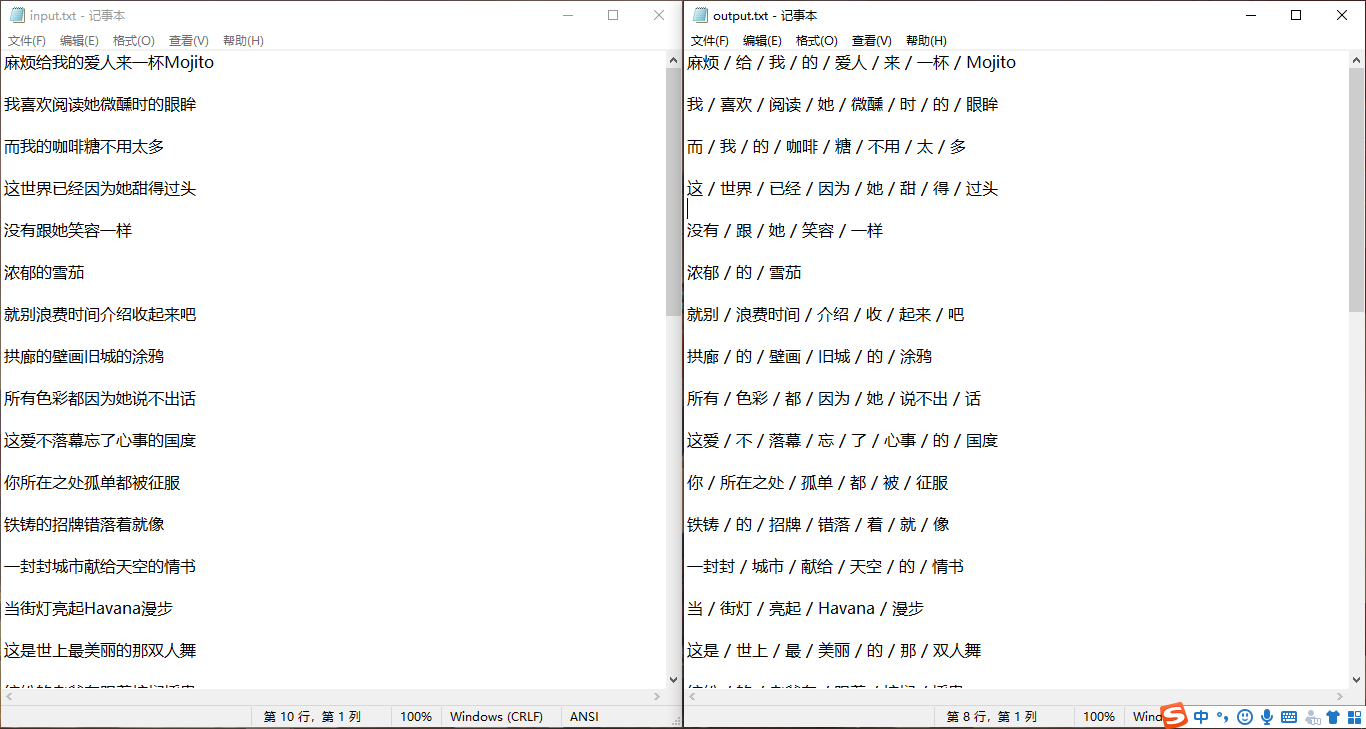
最后的最后,使用终端命令python -m jieba input.txt > output.txt将周杰伦新歌《mojito》的歌词进行分词
微信公众号:愤怒的it男,超多Python技术干货文章。