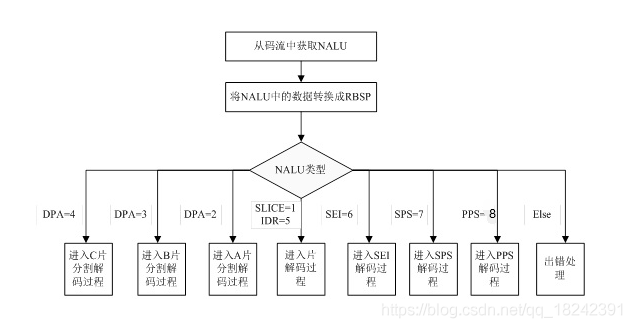
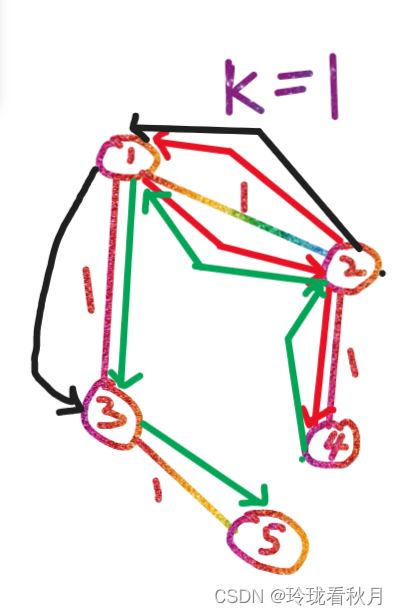
Elasticsearch处理表关联关系是比较复杂的问题,处理不好会出现性能问题、数据一致性问题等;
今天我们特意分享一下几种方式,对象类型(宽表)、嵌套类型、父子关联关系、应用端关联,每种方式都有特定的业务需求,具体可以根据业务场景选择,废话少数,现在开始。
一、对象类型
我们以博客为例,在每一博客的文档中都保留作者的信息,如果作者信息发生变化,需要修改相关的博客文档。
1、创建博客的索引
PUT /nandao_blog_index
{
"mappings": {
"properties": {
"content": {
"type": "text"
},
"time": {
"type": "date"
},
"user": {
"properties": {
"city": {
"type": "text"
},
"userid": {
"type": "long"
},
"username": {
"type": "keyword"
}
}
}
}
}
}结果:
{
"acknowledged" : true,
"shards_acknowledged" : true,
"index" : "nandao_blog_index"
}
2、修改映射,添加博客的name
POST /nandao_blog_index/_mapping
{
"properties": {
"name": {
"type": "text"
}
}
}结果:
{
"acknowledged" : true
}3、插入两条条 blog信息
PUT /nandao_blog_index/_doc/1
{
"content": "I like Elasticsearch",
"time": "2022‐01‐01T00:00:00",
"user": {
"userid": 1,
"username": "Nandao",
"city": "Changsha"
}
}
PUT /nandao_blog_index/_doc/2
{
"content": "I like Java",
"time": "2022‐01‐01T00:00:00",
"user": {
"userid": 1,
"username": "Nandao",
"city": "Changsha"
}
}4、查询 blog信息
POST /nandao_blog_index/_search
{
"query": {
"bool": {
"must": [{
"match": {
"content": "Elasticsearch"
}
},
{
"match": {
"user.username": "Nandao"
}
}
]
}
}
}结果就会查到一条信息
5、包含对象数组的文档,创建索引
PUT /nandao_movies_index
{
"mappings": {
"properties": {
"actors": {
"properties": {
"first_name": {
"type": "keyword"
},
"last_name": {
"type": "keyword"
}
}
},
"title": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
}
}
}
}
6、创建一条数据:
POST /nandao_movies_index/_doc/1
{
"title": "Speed",
"actors": [
{
"first_name": "Keanu",
"last_name": "Reeves"
},
{
"first_name": "Dennis",
"last_name": "Hopper"
}
]
}7、查询电影信息
POST /nandao_movies_index/_search
{
"query": {
"bool": {
"must": [{
"match": {
"actors.first_name": "Keanu"
}
},
{
"match": {
"actors.last_name": "Hopper"
}
}
]
}
}
}结果:
{
"took" : 2,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 0.723315,
"hits" : [
{
"_index" : "erpx_test_order_array",
"_type" : "_doc",
"_id" : "1",
"_score" : 0.723315,
"_source" : {
"title" : "Speed",
"actors" : [
{
"first_name" : "Keanu",
"last_name" : "Reeves"
},
{
"first_name" : "Dennis",
"last_name" : "Hopper"
}
]
}
}
]
}
}搜到了不需要的结果,存储时,内部对象的边界并没有考虑在内,JSON格式被处理成扁平式键值对的结构。当对多个字段进行查询时,导致了意外的搜索结果。可以用Nested Data Type解决这个问题 ,下面我们会分析。
二、嵌套类型
1、场景索引
PUT /nandao_movies_index_nested
{
"mappings": {
"properties": {
"actors": {
"type": "nested",
"properties": {
"first_name": {
"type": "keyword"
},
"last_name": {
"type": "keyword"
}
}
},
"title": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
}
}
}
}2、添加数据
POST /nandao_movies_index_nested/_doc/1
{
"title": "Speed",
"actors": [{
"first_name": "Keanu",
"last_name": "Reeves"
},
{
"first_name": "Dennis",
"last_name": "Hopper"
}
]
}3、Nested方式 查询
POST /nandao_movies_index_nested/_search
{
"query": {
"bool": {
"must": [{
"match": {
"title": "Speed"
}
},
{
"nested": {
"path": "actors",
"query": {
"bool": {
"must": [{
"match": {
"actors.first_name": "Keanu"
}
},
{
"match": {
"actors.last_name": "Hopper"
}
}
]
}
}
}
}
]
}
}
}显然结果 没有查到数据:
{
"took" : 1,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 0,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
}
}
4、Nested Aggregation 查询
POST /nandao_movies_index_nested/_search
{
"size": 0,
"aggs": {
"actors": {
"nested": {
"path": "actors"
},
"aggs": {
"actor_name": {
"terms": {
"field": "actors.first_name",
"size": 10
}
}
}
}
}
}5、普通 aggregation不工作查询
POST /erpx_test_order_nested/_search
{
"size": 0,
"aggs": {
"NAME": {
"terms": {
"field": "actors.first_name",
"size": 10
}
}
}
}三、父子关系类型:即join 联合查询
对象和Nested对象的局限性: 每次更新,可能需要重新索引整个对象(包括根对象和嵌套对象)
ES提供了类似关系型数据库中Join 的实现。
使用Join数据类型实现,可以通过维护Parent/ Child的关系,从而分离两个对象父文档和子文档是两个独立的文档更新父文档无需重新索引子文档。
子文档被添加,更新或者删除也不会影响到父文档和其他的子文档。
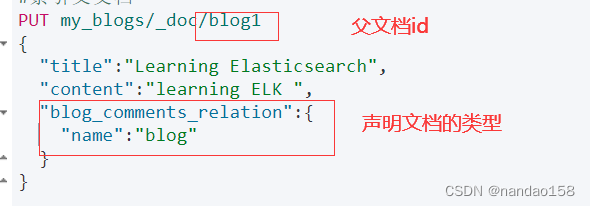
1、创建父子索引
PUT /nandao_relation_index
{
"settings": {
"number_of_shards": 2
},
"mappings": {
"properties": {
"blog_comments_relation": {
"type": "join",
"relations": {
"blog": "comment"
}
},
"content": {
"type": "text"
},
"title": {
"type": "keyword"
}
}
}
}解释:

2、创建两个父文档
PUT /nandao_relation_index/_doc/blog1
{
"title": "Learning Elasticsearch",
"content": "learning ELK ",
"blog_comments_relation": {
"name": "blog"
}
}
PUT /nandao_relation_index/_doc/blog2
{
"title": "Learning Hadoop",
"content": "learning Hadoop",
"blog_comments_relation": {
"name": "blog"
}
}解释:
3、创建三个子文档
PUT /nandao_relation_index/_doc/comment1?routing=blog1
{
"comment": "I am learning ELK",
"username": "Jack",
"blog_comments_relation": {
"name": "comment",
"parent": "blog1"
}
}
PUT /nandao_relation_index/_doc/comment2?routing=blog2
{
"comment":"I like Hadoop!!!!!",
"username":"Jack",
"blog_comments_relation":{
"name":"comment",
"parent":"blog2"
}
}
PUT /nandao_relation_index/_doc/comment3?routing=blog2
{
"comment": "Hello Hadoop",
"username": "Bob",
"blog_comments_relation": {
"name": "comment",
"parent": "blog2"
}
}
4、查询所有文档
POST /nandao_relation_index/_search显示父子五个文档:
{
"took" : 2,
"timed_out" : false,
"_shards" : {
"total" : 2,
"successful" : 2,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 5,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
{
"_index" : "erpx_test_order_test",
"_type" : "_doc",
"_id" : "blog1",
"_score" : 1.0,
"_source" : {
"title" : "Learning Elasticsearch",
"content" : "learning ELK ",
"blog_comments_relation" : {
"name" : "blog"
}
}
},
{
"_index" : "erpx_test_order_test",
"_type" : "_doc",
"_id" : "blog2",
"_score" : 1.0,
"_source" : {
"title" : "Learning Hadoop",
"content" : "learning Hadoop",
"blog_comments_relation" : {
"name" : "blog"
}
}
},
{
"_index" : "erpx_test_order_test",
"_type" : "_doc",
"_id" : "comment1",
"_score" : 1.0,
"_routing" : "blog1",
"_source" : {
"comment" : "I am learning ELK",
"username" : "Jack",
"blog_comments_relation" : {
"name" : "comment",
"parent" : "blog1"
}
}
},
{
"_index" : "erpx_test_order_test",
"_type" : "_doc",
"_id" : "comment2",
"_score" : 1.0,
"_routing" : "blog2",
"_source" : {
"comment" : "I like Hadoop!!!!!",
"username" : "Jack",
"blog_comments_relation" : {
"name" : "comment",
"parent" : "blog2"
}
}
},
{
"_index" : "erpx_test_order_test",
"_type" : "_doc",
"_id" : "comment3",
"_score" : 1.0,
"_routing" : "blog2",
"_source" : {
"comment" : "Hello Hadoop",
"username" : "Bob",
"blog_comments_relation" : {
"name" : "comment",
"parent" : "blog2"
}
}
}
]
}
}
5、根据父文档ID查看
GET /nandao_relation_index/_doc/blog2结果:
{
"_index" : "nandao_relation_index",
"_type" : "_doc",
"_id" : "blog2",
"_version" : 1,
"_seq_no" : 1,
"_primary_term" : 1,
"found" : true,
"_source" : {
"title" : "Learning Hadoop",
"content" : "learning Hadoop",
"blog_comments_relation" : {
"name" : "blog"
}
}
}6、根据Parent Id 查询
POST /nandao_relation_index/_search
{
"query": {
"parent_id": {
"type": "comment",
"id": "blog2"
}
}
}结果:
{
"took" : 6,
"timed_out" : false,
"_shards" : {
"total" : 2,
"successful" : 2,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : 0.53899646,
"hits" : [
{
"_index" : "erpx_test_order_test",
"_type" : "_doc",
"_id" : "comment2",
"_score" : 0.53899646,
"_routing" : "blog2",
"_source" : {
"comment" : "I like Hadoop!!!!!",
"username" : "Jack",
"blog_comments_relation" : {
"name" : "comment",
"parent" : "blog2"
}
}
},
{
"_index" : "erpx_test_order_test",
"_type" : "_doc",
"_id" : "comment3",
"_score" : 0.53899646,
"_routing" : "blog2",
"_source" : {
"comment" : "Hello Hadoop",
"username" : "Bob",
"blog_comments_relation" : {
"name" : "comment",
"parent" : "blog2"
}
}
}
]
}
}7、 Has Child 查询,返回父文档
POST /nandao_relation_index/_search
{
"query": {
"has_child": {
"type": "comment",
"query": {
"match": {
"username": "Jack"
}
}
}
}
}结果:
{
"took" : 14,
"timed_out" : false,
"_shards" : {
"total" : 2,
"successful" : 2,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
{
"_index" : "erpx_test_order_test",
"_type" : "_doc",
"_id" : "blog1",
"_score" : 1.0,
"_source" : {
"title" : "Learning Elasticsearch",
"content" : "learning ELK ",
"blog_comments_relation" : {
"name" : "blog"
}
}
},
{
"_index" : "erpx_test_order_test",
"_type" : "_doc",
"_id" : "blog2",
"_score" : 1.0,
"_source" : {
"title" : "Learning Hadoop",
"content" : "learning Hadoop",
"blog_comments_relation" : {
"name" : "blog"
}
}
}
]
}
} 注意:
1)父文档和子文档必须存在相同的分片上,能够确保查询join 的性能。
2)当指定子文档时候,必须指定它的父文档ld。使用routing参数来保证,分配到
相同的分片。
四、应用端关联
1、此方案比较好理解,就是多长查询,下一次查询依赖上一次查询结果。
常用的嵌套文档和父子文档对比:

到此、es相关的DSL语句分享完毕,后期我们分享一下相关的javaAPI,也是实战的必经之路,敬请期待!







![[标准库]STM32F103R8T6 点灯以及按键扫描](https://img-blog.csdnimg.cn/a5eb21d2096e42f2b6275f0022de8ace.png)