学习率角度
学习率是一个非常非常重要的超参数,这个参数呢,面对不同规模、不同batch-size、不同优化方式、不同数据集,其最合适的值都是不确定的,我们无法光凭经验来准确地确定lr的值,我们唯一可以做的,就是在训练中不断寻找最合适当前状态的学习率。
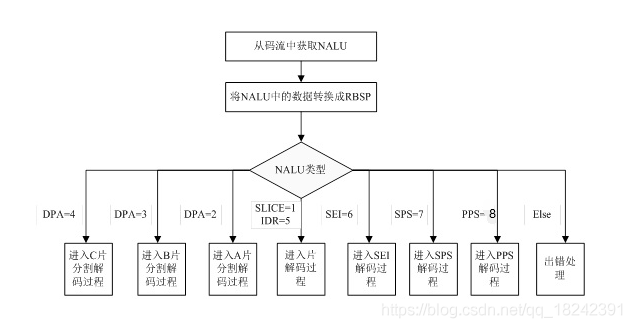
比如下图利用fastai中的lr_find()函数寻找合适的学习率,根据下方的学习率-损失曲线得到此时合适的学习率为1e-2。

推荐一篇fastai首席设计师「Sylvain Gugger」的一篇博客:How Do You Find A Good Learning Rate[1], 以及相关的论文Cyclical Learning Rates for Training Neural Networks[2]。
1、Warm up
深度学习训练策略--学习率预热Warmup_ytusdc的博客-CSDN博客_warmup_steps
训练初始阶段:由于刚开始训练时模型的权重(weights)是随机初始化的,此时选择一个较大的学习率,可能会带来模型的不稳定。学习率预热就是在刚开始训练的时候先使用一个较小的学习率,训练一些epoches或iterations,等模型稳定时再修改为预先设置的学习率进行训练。
上述的方法是constant warmup,18年Facebook又针对上面的warmup进行了改进,因为从一个很小的学习率一下变为比较大的学习率可能会导致训练误差突然增大。提出了gradual warmup来解决这个问题,即从最开始的小学习率开始,每个iteration增大一点,直到最初设置的比较大的学习率。
2、Linear scaling learning rate —— learning-rate与batch-size的关系
实验证明,大的batch size在相同的epoch下准确率会更小,使用warm up可以在一定程度上解决这个问题,而Linear scaling learning rate也是一种有效的方法。
一般来说,越大的batch-size使用越大的学习率。
在mini-batch SGD训练时,梯度下降的值是随机的,因为每一个batch的数据是随机选择的。增大batch size不会改变梯度的期望,但是会降低它的方差。也就是说,大batch size会降低梯度中的噪声,所以我们可以增大学习率来加快收敛。
具体做法很简单,比如ResNet原论文中,batch size为256时选择的学习率是0.1,当我们把batch size变为一个较大的数b时,学习率应该变为 0.1 × b/256。即线性的根据batch大小设置学习率,从而达到更好的学习效果。
简单的说,大的batch size计算得到的梯度噪声更小,所以可以使用更大的学习率来加大收敛。那么这里就有一个问题了,为什么小的batch size一般收敛的更快呢?这是因为小的batch size尽管方向不一定准确,但是更新次数多,最终收敛速度会更快。而大的batch size虽然噪声小,方向也更准确,但是由于学习率效果不会很好,这样线性的增加学习率其实也是相当于用单次更新量变大弥补更新次数小的事实。
总结,越大的batch-size意味着我们学习的时候,收敛方向的confidence越大,我们前进的方向更加坚定,而小的batch-size则显得比较杂乱,毫无规律性,因为相比批次大的时候,批次小的情况下无法照顾到更多的情况,所以需要小的学习率来保证不至于出错。
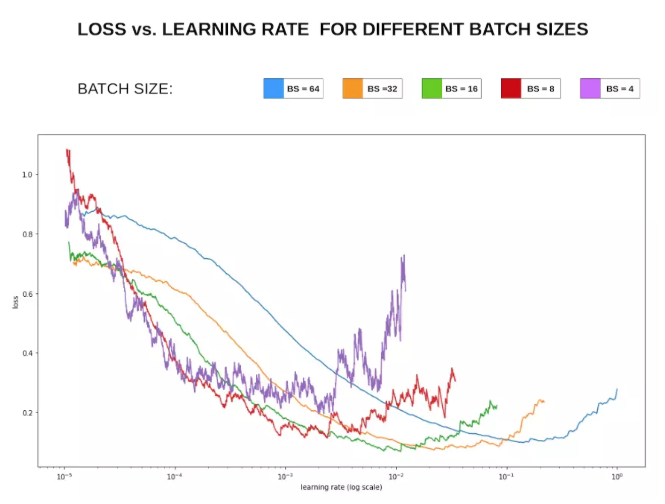
可以看下图损失Loss与学习率Lr的关系:
在显存足够的条件下,最好采用较大的batch-size进行训练,找到合适的学习率后,可以加快收敛速度。另外,较大的batch-size可以避免batch normalization出现的一些小问题,
3、学习率衰减策略
在warmup之后的训练过程中,学习率不断衰减是一个提高精度的好方法。因此可以选择合适的学习率衰减策略:
学习率衰减策略 - 知乎
还要注意一点有些参数有更快、或更慢的学习速率,因此我们可以针对模型中的不同参数组,设定不同的学习率。在上述链接中也有介绍






![[标准库]STM32F103R8T6 点灯以及按键扫描](https://img-blog.csdnimg.cn/a5eb21d2096e42f2b6275f0022de8ace.png)