前言
作为后端研发,性能分析是我们在研发过程中必然会会遇到的环节,接口耗时、堆栈溢出、内存泄露等等。所谓工欲善其事必先利其器,之前在java中我们是使用arthas这一大神器,不得不说确实好用,想了解arthas的可以看下我之前的文章:Arthas性能分析工具。本节内容我们带来Go的分析神器pprof的使用,帮助我们分析各种性能问题。
pprof介绍
pprof是GoLang程序性能分析工具,和arthas这种工具不一样,pprof是内置在Go里面的,我们只需要开启对应的功能就可以进行采集,本质上还是生成对应的性能数据文件,然后通过pprof打开。不过pprof还提供了web形式的访问,这对于server程序而言真实太方便了,通过http的交互方式,我们就可以进入性能分析的界面。
开启pprof
pprof可以支持单机程序和server项目,单机程序的话我们需要在程序里面硬编码,通过的打点的方式告诉pprof采集CPU、内存等文件,然后文件会落入指定的路径最终进行分析。但是我们实际开发场景大都是server项目,所以这里我也以server项目来举例说明。
1、Go原生的http服务框架
当采用go原生的http服务框架,使用pprof非常的简单:只需要导入net/http/pprof包即可。代码如下:
package main
import (
"fmt"
"net/http"
_ "net/http/pprof"
)
func HelloWorld(w http.ResponseWriter, r *http.Request) {
fmt.Fprintln(w, "hello world")
}
func main() {
http.HandleFunc("/", HelloWorld)
err := http.ListenAndServe(":8080", nil)
if err != nil {
fmt.Println(err)
}
}2、使用gin框架实现的服务
这个也是我们常用的一种方式,Gin框架如果要添加pprof, 可以借助github.com/gin-contrib/pprof包,并且在项目启动的入口位置注册一下pprof,代码如下:
package routers
import (
"github.com/gin-contrib/pprof"
"github.com/gin-contrib/pprof" //引入gin对应的pprof包
"github.com/gin-gonic/gin"
"go-server/app/controller"
)
func init() {
//创建一个gin示例
router := gin.Default()
pprof.Register(router) //注册pprof
//注册路径
user := router.Group("/performance")
{
user.GET("/pertest", controller.CollectPerformance)
}
//监听端口
router.Run(":8080")
}server类型的项目,启动之后出现如下日志说明注册pprof成功:
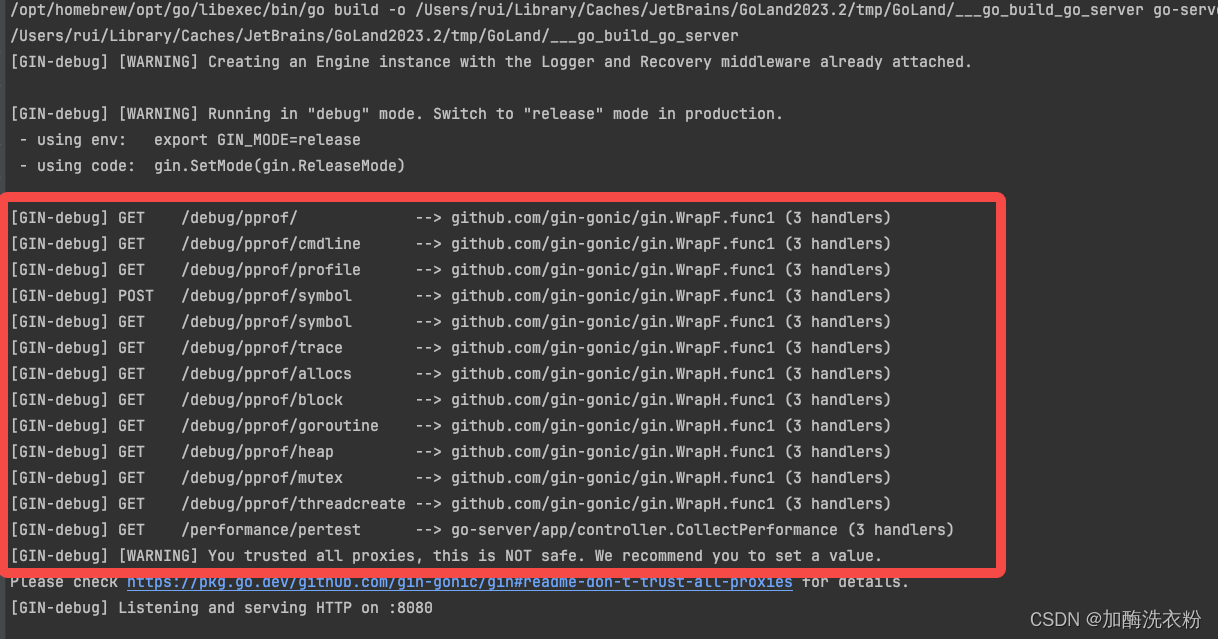
浏览器中访问:localhost:8080/debug/pprof
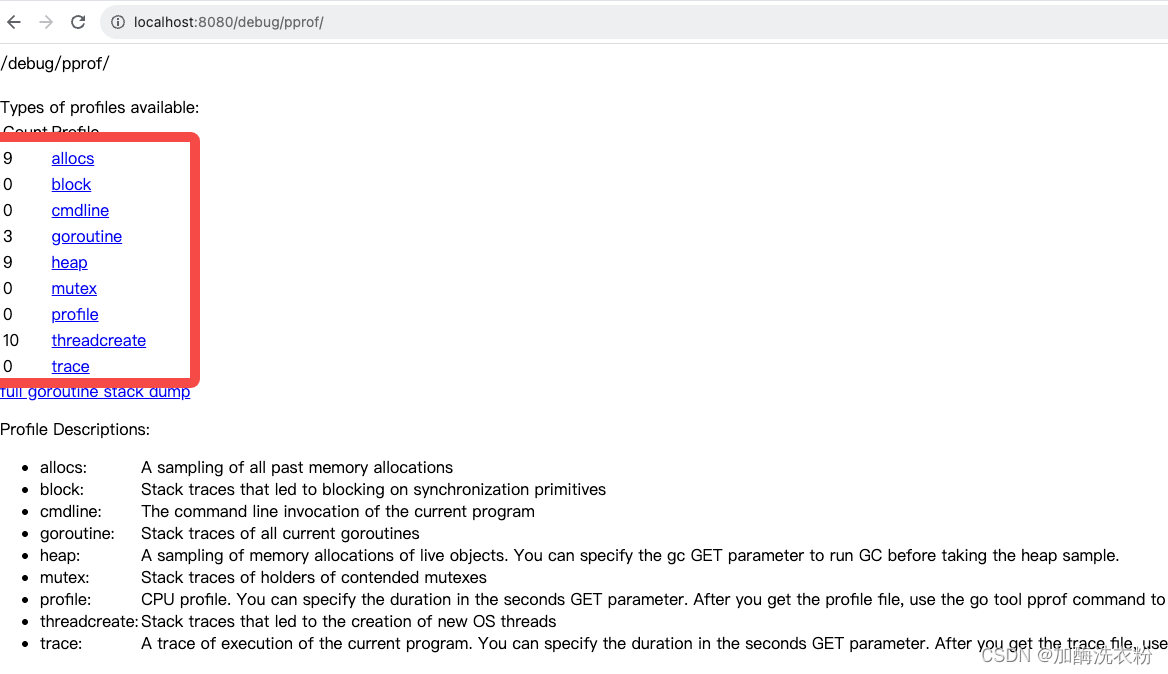
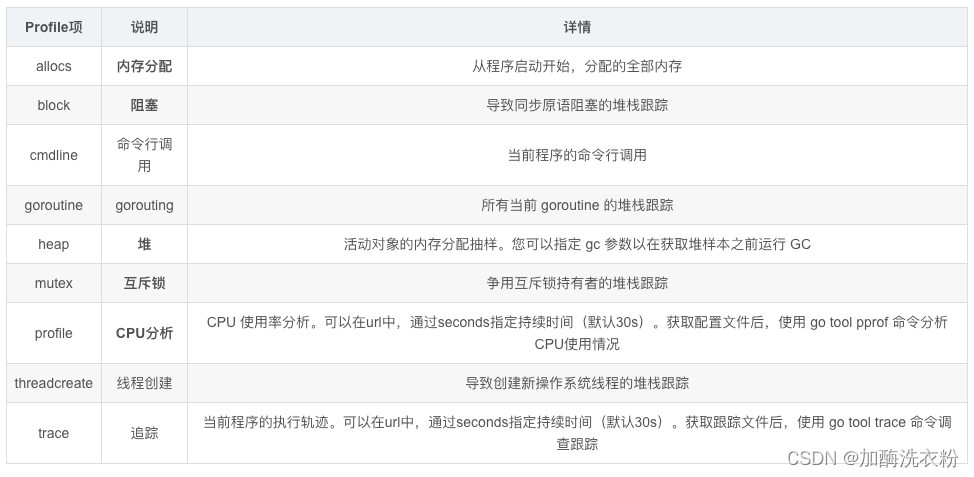
各项指标说明:
pprof分析
性能分析
性能分析主要是分析程序的耗时情况,这个在pprof是采集CPU的信息,在CPU的采集信息里会有每个函数占用CPU片段的时间,这个也间接的反应了函数的耗时时长。
通过上面这些步骤开启pprof之后,接下来我们就要进行数据的采集,pprof并不是默认采集数据的,而是需要手动去采集一段时间的性能数据(默认是30s),所以开启这个不需要担心会对系统造成负担,只要不主动采集,pprof是不会进行工作。
开启CPU采集通过访问url地址:http://<host>:<port>/debug/pprof/profile,可以带参数?seconds = 60表示采集60s,访问这个地址之后,程序会block住等待一定的时间,在这个时间内我们进行的操作就会被采集进去,一般采用交互式命令的方式开启采集:
go tool pprof http://<host>:<port>/debug/pprof/profile
开启采集之后我们就可以立即访问需要测试的程序,然后采集数据,在本示例中我通过一个接口来模拟数据:
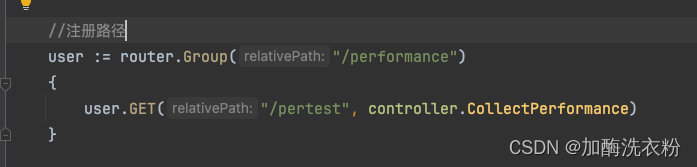
访问http://localhost:8080/performance/pertest地址会调用CollectPerformance这个函数,在这个函数中调用了另外一个耗时函数:
func CollectPerformance(ctx *gin.Context) {
performanceWait() //这是一个耗时函数
}
func performanceWait() {
for i := 2000000; i >= 0; i-- {
fmt.Println(i)
}
}访问程序之后,pprof的交互界面经过默认的采集时间之后就可以进行查看数据了,下面就是分析阶段了:
1、top n 按照函数耗时排序,展示前多少个
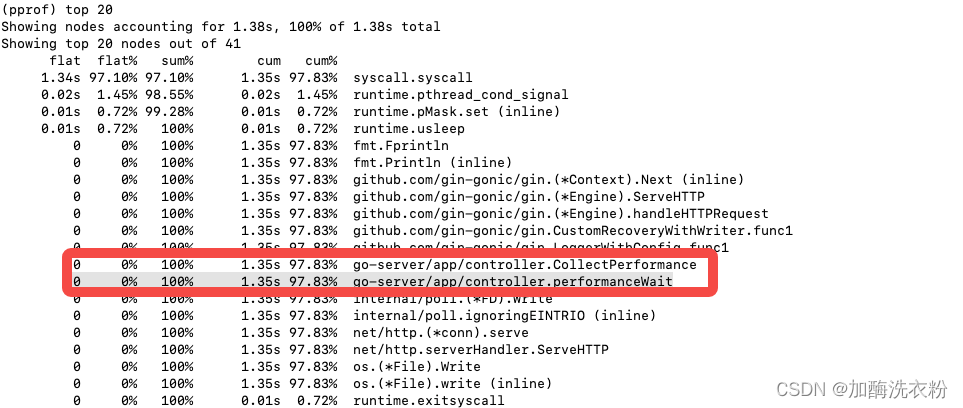
这里重点看cum这个值,这个值表示的是函数本身执行的时间和调用其他函数的时间,我们可以直接按照cum来排序,top 20 -cum
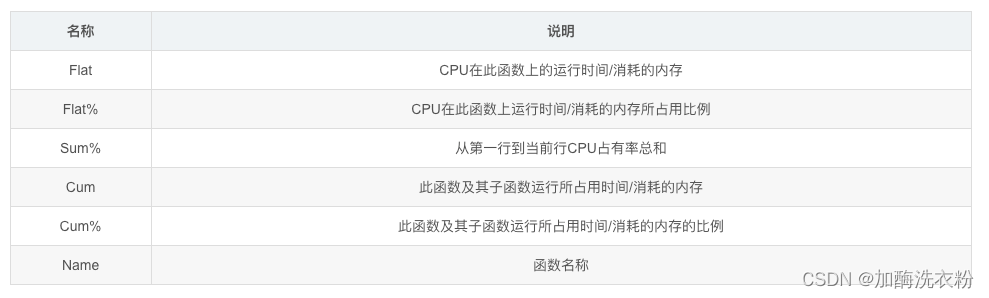
各项指标说明:
2、list
list命令有点类似于arthas中的trace,可以列出程序的具体的耗时信息,比如上面我看到performanceWait这个函数耗时较长,那么通过list去看一下:

上面看到在20行消耗的cpu时间片最长,因为这里有一个很大的循环
注意:
- pprof采集的数据是这段时间的总和,比如上面的1.35s表示这段时间程序执行时间的总和,不是平均值
- 上述时间是函数CPU的时间,不一定是函数真实的运行时间,比如在函数里有一行time.sleep(13 * time.Second),这个时间并不会计算进去

内存分析
内存分析这里我们主要是分析堆内存,也是我们平时程序作用的地方。pprof提供了堆内存的检测方式,可以通过实施快照的方式帮助我们dump内存数据并且进行分析。
dump堆内存:go tool pprof http://localhost:6060/debug/pprof/heap
访问上面的地址pprof就会dump出当时的堆内存情况,这个和cpu的prfile不一样,不是执行完就block住等待数据产生,而是直接dump出执行时间点的堆内存信息

我在接口中编写一个不断申请内存的程序,导致最终内存溢出,通过文件进行分析。
func CollectHeap(ctx *gin.Context) {
tick := time.Tick(time.Second)
var buf []byte
stime := time.Now()
for range tick {
// 1秒1M内存
buf = append(buf, make([]byte, 1024*1024)...)
fmt.Printf("%f\n", time.Now().Sub(stime).Seconds())
}
}访问接口让程序执行,然后通过heap快照内存后进行分析,分析的方式和cpu一样,也是top和list命令:
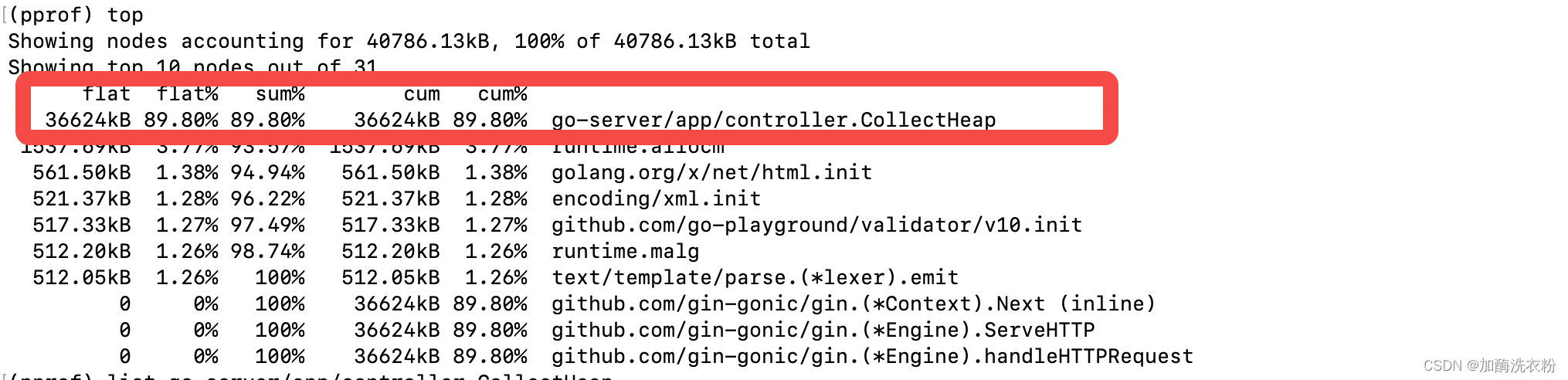
执行top可以看到CollectHeap这个函数占用内存很高,通过list可以定位到具体的哪一行
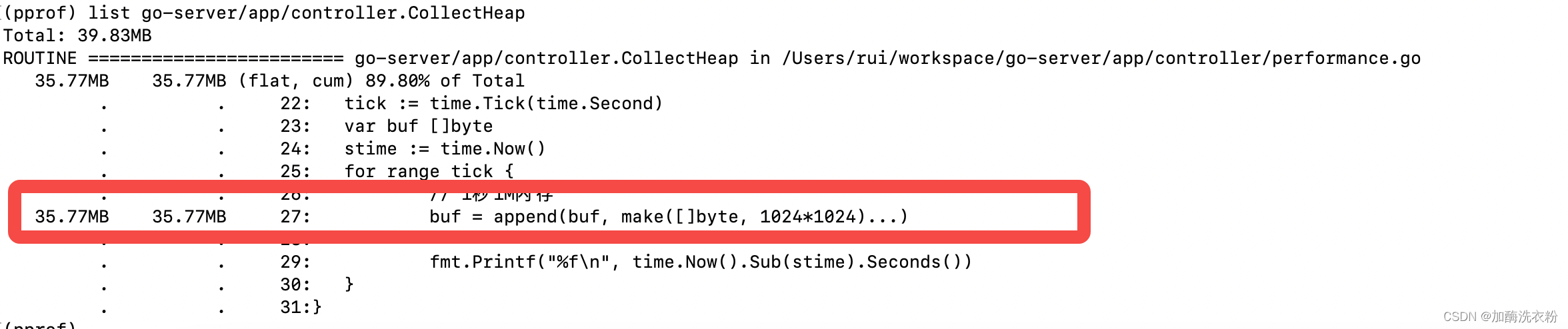
再测试一个大对象占用的场景,在函数里定义一个map,循环往里面放数据。
package controller
import (
"fmt"
"github.com/gin-gonic/gin"
"github.com/google/uuid"
"go-server/app/models"
"time"
)
var userMap = map[string]models.User{}
func CollectHeap(ctx *gin.Context) {
for i := 1000000; i >= 0; i-- {
uuid := uuid.New().String()
user := models.User{
Name: uuid,
Age: i,
}
userMap[uuid] = user
}
}
访问接口执行程序,然后看下堆内存情况
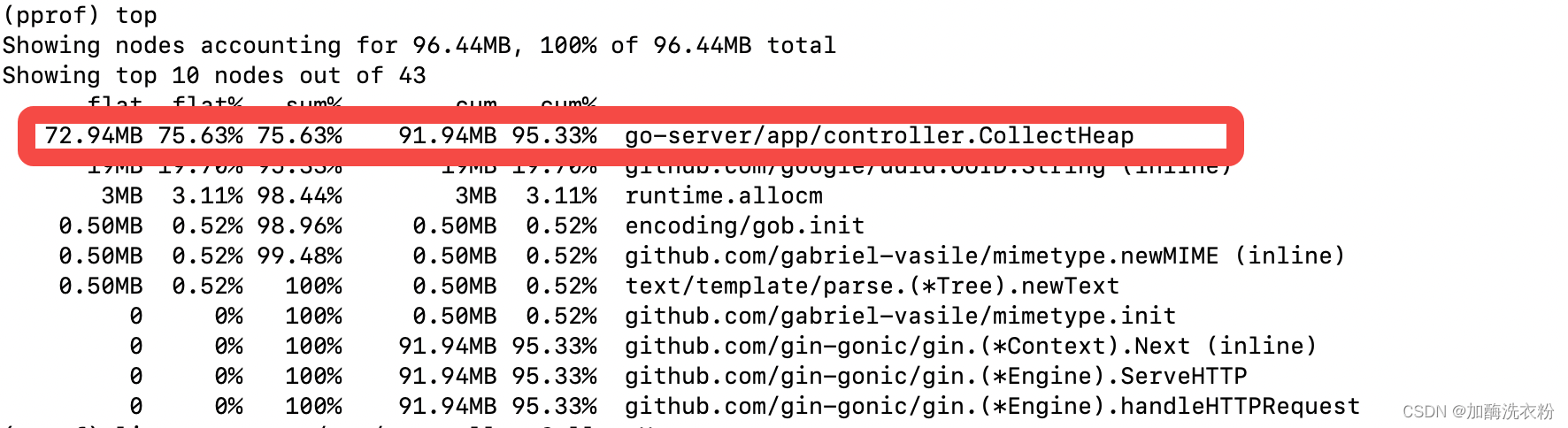
通过top可以看到在CollectHeap函数中有内存占用比较大
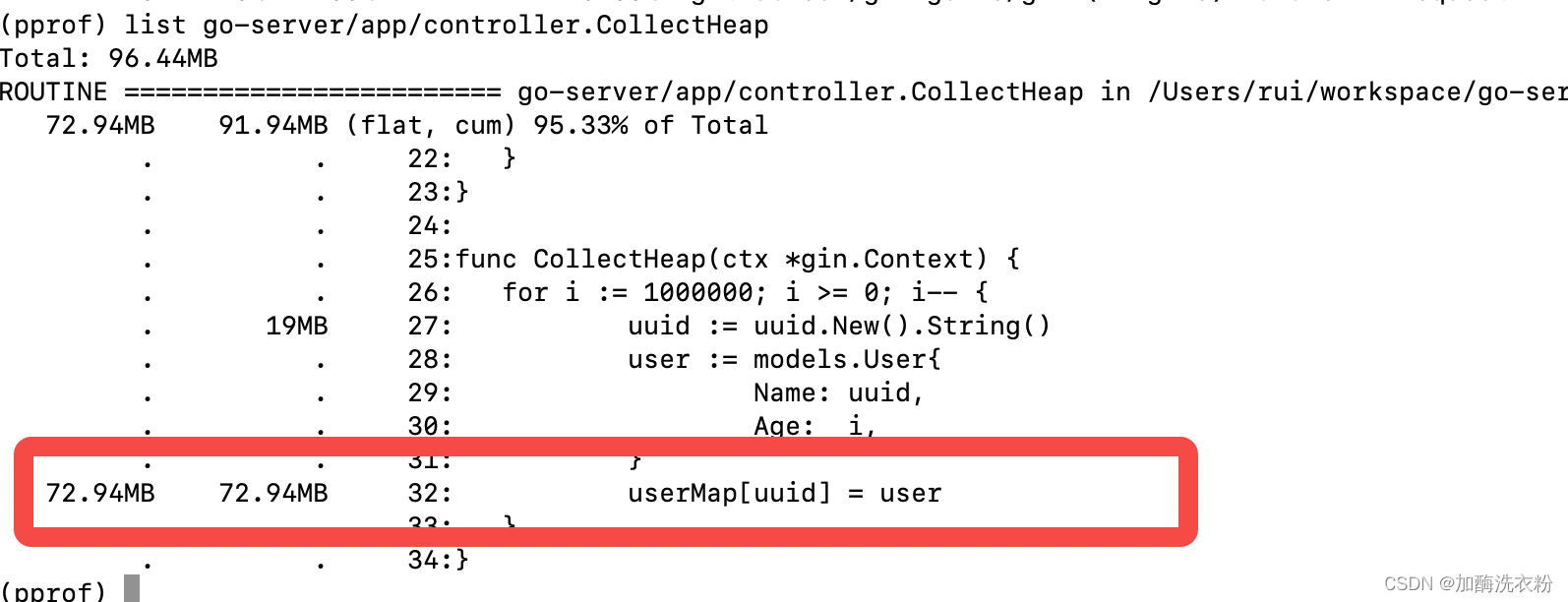
通过list可以看到在map赋值这一行占用内存最多,这里有一点和Java不太一样,就是pprof的分析都是基于函数为基础,所有所有的都显示到函数执行上,比如Java的内存分析会直接分析到对象,某个具体的map,但是Go里面还是对应函数执行,会有一点点不直观
goroutine分析
分析goroutine主要是分析阻塞这种情况,比如系统中存在大量的goroutine没有执行完,导致泄露
代码示例:
func CollectGoroutine(ctx *gin.Context) {
outCh := make(chan int) //无缓冲channel
stime := time.Now()
// 每1s个goroutine
for {
time.Sleep(1 * time.Second)
go alloc(outCh)
fmt.Printf("last: %dseconds\n", int(time.Now().Sub(stime).Seconds()))
}
}
// alloc分配1M内存,goroutine会阻塞,不释放内存,导致泄漏
func alloc(outCh chan<- int) {
buf := make([]byte, 1024*1024*1)
_ = len(buf)
fmt.Println("alloc make buffer done")
outCh <- 0
fmt.Println("alloc finished")
}访问接口会不断开启goroutine分配内存,并且系统中的goutinue数量会不断上升,具体分析如下:
pprof分析goroutine推荐使用web界面访问的方式,这种访问也是实时的,每次访问都是实时的快照系统中的gotoutine情况,有两种分析方式:
1、goroutine总览:http://localhost:8080/debug/pprof/goroutine?debug=1
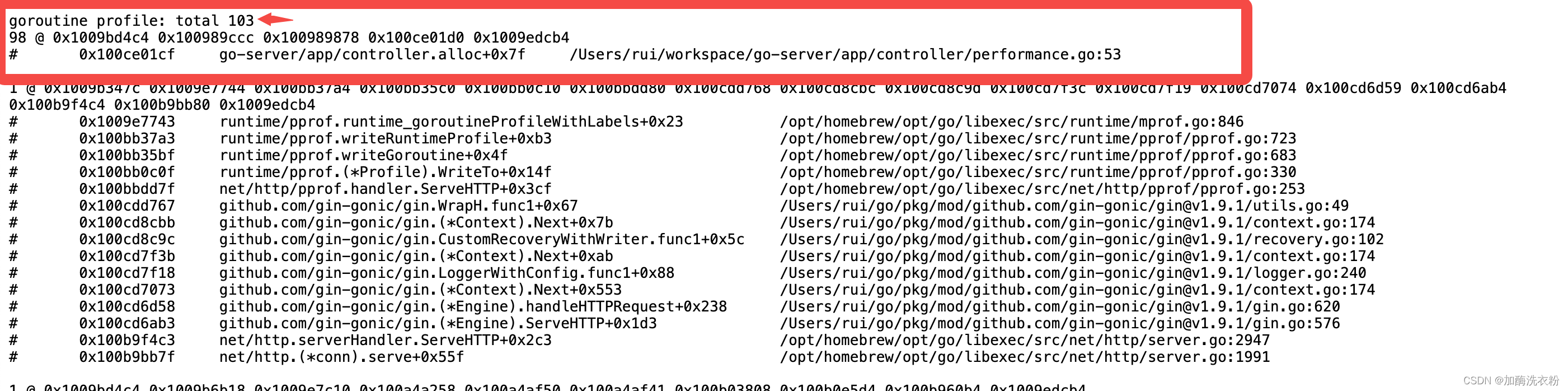
在goroutine总览里面可以看到系统中存在的goroutine数量,通过实时刷新我们可以看到这个数值在直线上升,说明肯定有阻塞的地方,导致goroutine没有释放,通过第二种方式查看明细
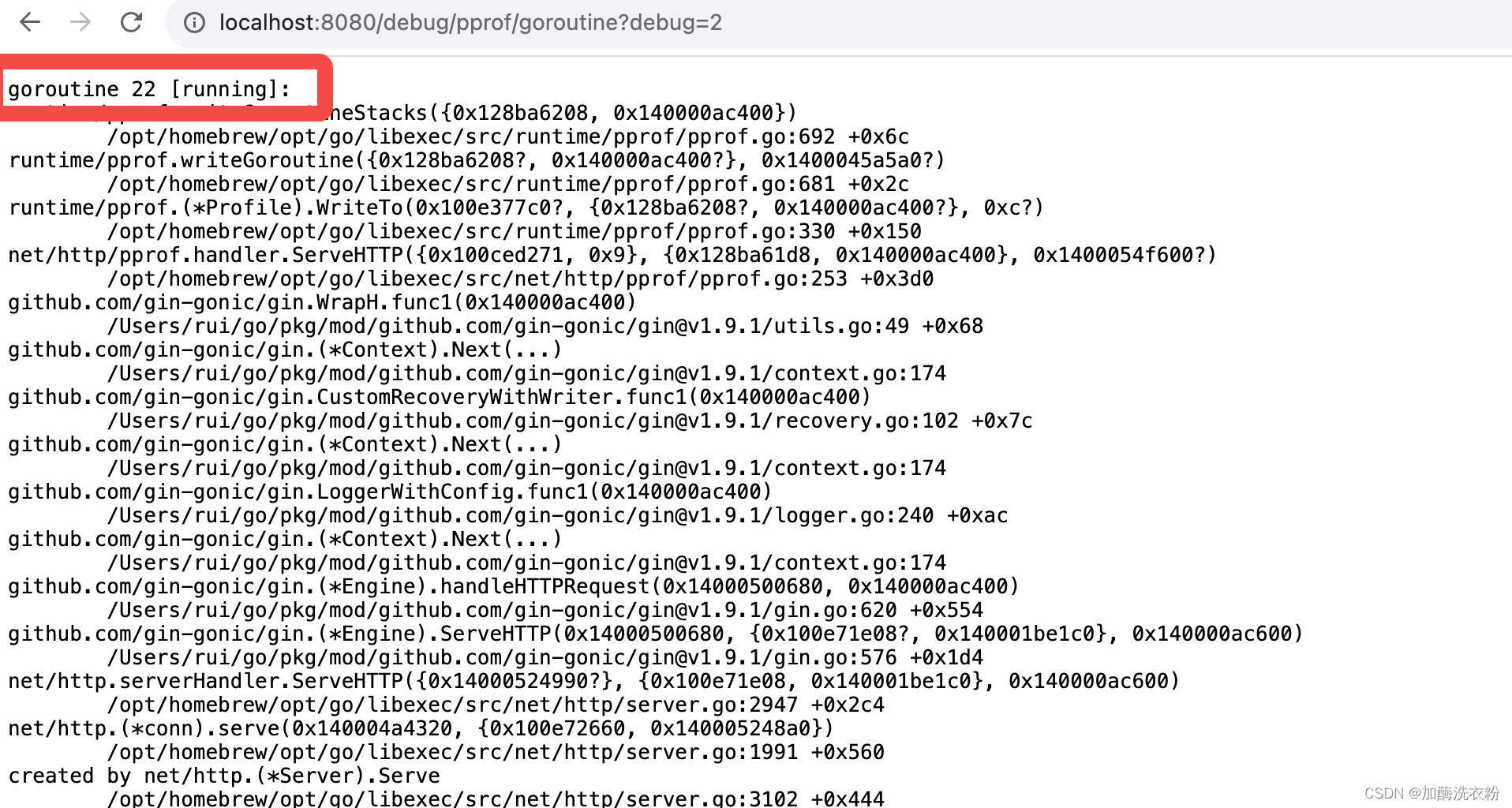
1、goroutine明细:http://localhost:8080/debug/pprof/goroutine?debug=2
明细里面会展示所有状态的goroutine情况
running状态:
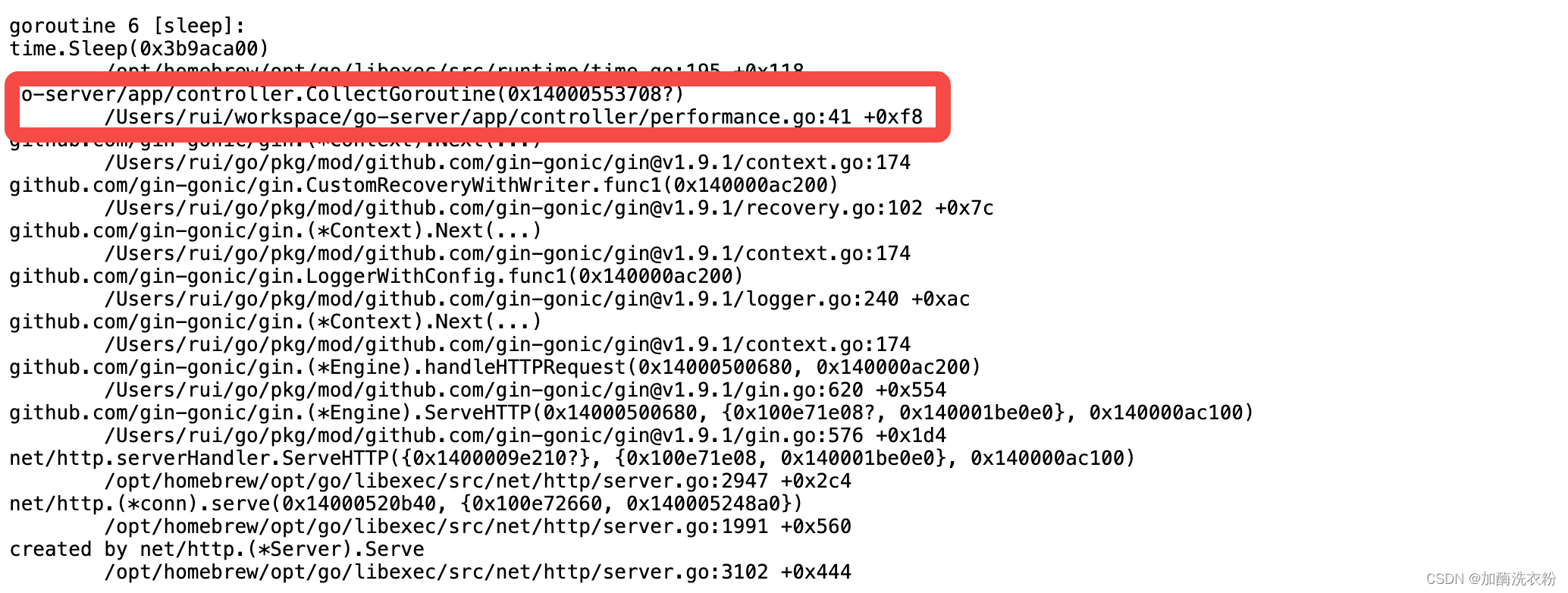
sleep状态:
我们在代码41行执行了sleep的方法
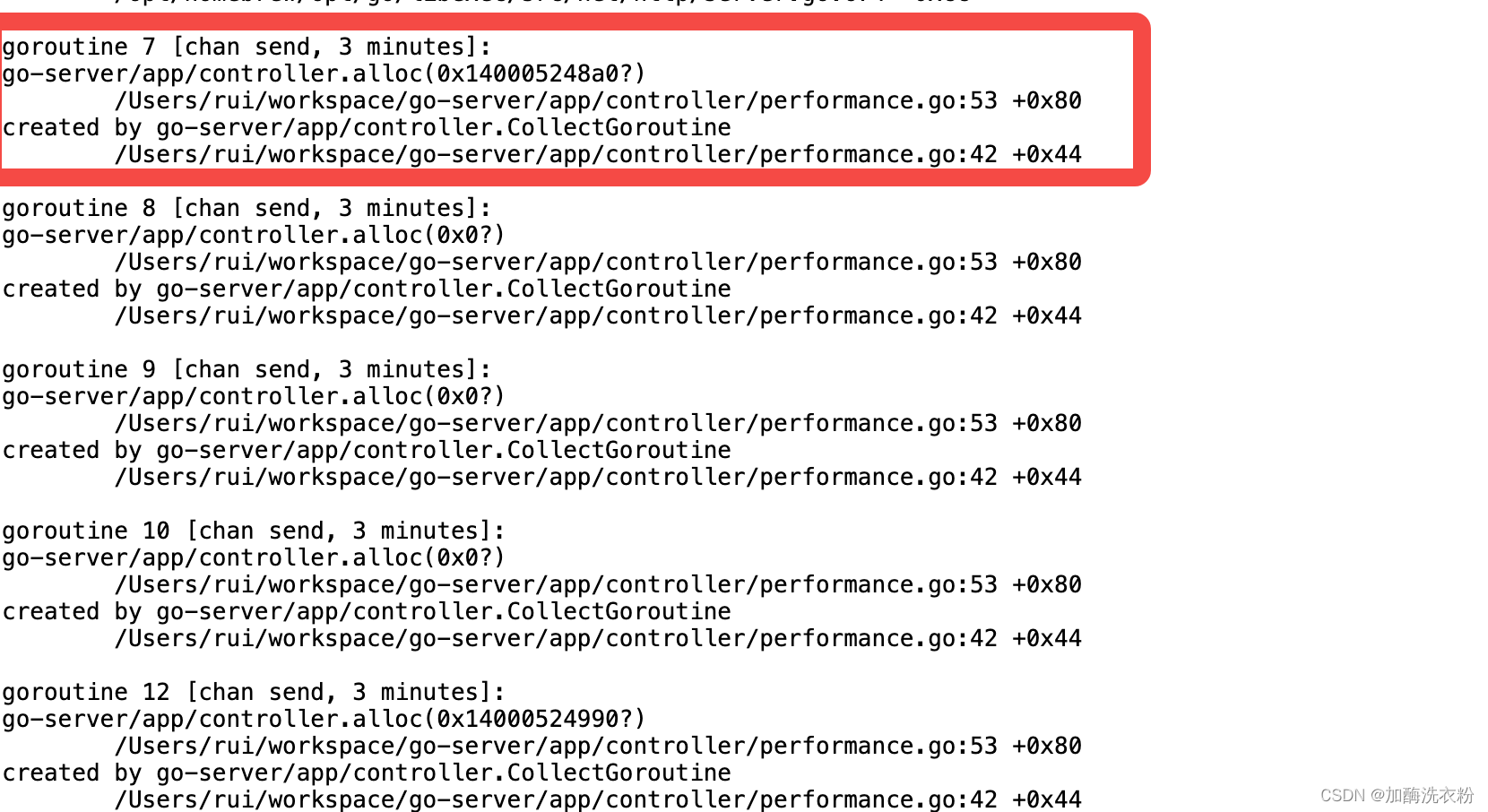
block状态:
这里可以看到有很多线程都是阻塞在chan的发送上面,耗时几分钟,这里也列了代码中阻塞在哪一行