论文地址:https://arxiv.org/pdf/1904.07850.pdf
代码地址:https://github. com/xingyizhou/CenterNet.
Abstract
基于anchor的目标检测算法通常会列举大量可能存在对象位置的列表,这是浪费的、低效的。作者采用了一种不同的方法。将一个对象建模为单个点——其边界框的中心点。检测器使用关键点估计来寻找中心点,并回归到所有其他对象属性,如大小、三维位置、方向,甚至姿态。基于中心点的方-CenterNet,是端到端的,比相应的基于边界盒的检测器更简单、更快、更准确
1. Introduction
在本文中,作者摒弃了原来基于锚框的做法。作者在对象的边界框中心用单个点来表示对象(参见图2)。其他属性,如对象大小、尺寸、三维范围、方向和姿态,然后直接从中心位置的图像特征回归。对象检测是一个标准的关键点估计问题[3,39,60]。我们只需将输入的图像提供给一个完全卷积的网络[37,40],从而生成一个热图。这个热图中的峰值对应于对象中心。每个峰值处的图像特征可以预测物体边界框的高度和权重。该模型使用标准的密集监督学习[39,60]进行训练。推理仅仅只需要进行预测,而不需要经过非极大值抑制等后处理

3. Preliminary
分类:
正负样本的分配:首先将原始图像下采样R倍(4倍),然后,基于下采样的特征图分配正负样本。为了维持正负样本均衡,采用高斯分布的方式为每个关键点分配标签。![]()
即以中心点为中心的高斯分布。![]() 表示原图像像素点对应于下采样后的特征图的关键点位置。
表示原图像像素点对应于下采样后的特征图的关键点位置。
如果出现了重叠,就取较大的值。
此时,关键点分类的损失:

位置:
为正样本预测一个偏移值![]() ,这里的偏移与YOLO的偏移差不多,损失函数:
,这里的偏移与YOLO的偏移差不多,损失函数:

长宽:
长宽也是根据关键点直接进行预测:![]() ,损失函数为:
,损失函数为:

总损失函数:
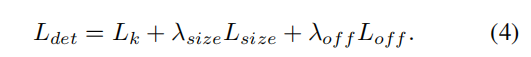
作者在所有实验中都设置了λsize = 0.1和λof f = 1。我们使用一个单个网络来预测关键点Yˆ、偏移量ˆO和大小Sˆ。该网络预测了每个位置的C+4个输出。所有的输出都共享一个共同的全卷积主干网络。对于每个模态,主干的特征然后通过一个单独的3×3卷积,ReLU和另一个1×1卷积。图4显示了网络输出的概述。

从关键点到检测框:
在推理时,首先独立地提取每个类别的热图中的峰值。检测所有值大于或等于它的8个连接邻居的位置,并保持前100个峰值。类c的n个中心点![]() 组成了集合
组成了集合![]() 。每个关键点的位置都由一个整数坐标(xi、yi)给出。使用关键点值
。每个关键点的位置都由一个整数坐标(xi、yi)给出。使用关键点值![]() 作为其检测置信度的度量,并在一个位置产生一个边界框。
作为其检测置信度的度量,并在一个位置产生一个边界框。![]() 为偏移量,
为偏移量,![]() 为宽和高。所有的输出都是直接从关键点估计中产生的,而不需要基于iou的非最大抑制(NMS)或其他后处理。峰值关键点提取是一个足够的NMS替代方案,可以使用3×3最大池化操作在设备上有效实现。
为宽和高。所有的输出都是直接从关键点估计中产生的,而不需要基于iou的非最大抑制(NMS)或其他后处理。峰值关键点提取是一个足够的NMS替代方案,可以使用3×3最大池化操作在设备上有效实现。

4.1. 3D detection
三维检测估计每个对象有一个三维边界框,并且每个中心点需要三个额外的属性:深度、三维维度和方向。我们为每个人添加一个单独的头。深度d是每个中心点的单个标量。然而,深度很难直接回归到。使用![]() 进行深度变换。并使用L1损失
进行深度变换。并使用L1损失
4.2. Human pose estimation
人体姿态估计的目的是估计图像中每个人体实例的k个2D人体关节位置(k = 17为COCO)。将姿态视为中心点的k×2二维的中心点坐标,并通过偏移点来参数化每个关键点。我们使用L1损失直接回归到联合偏移量![]() (以像素为单位)。
(以像素为单位)。
为了细化关键点,我们进一步使用标准的自下而上的多人体姿态估计[4,39,41]估计了k个人体关节热图![]() 。我们用焦点损失和局部像素偏移来训练人体关节热图
。我们用焦点损失和局部像素偏移来训练人体关节热图
然后,我们将最初的预测捕捉到这个热图上最近检测到的关键点。在这里,我们的中心偏移量作为一个分组线索,将单个的关键点检测分配给他们最近的人实例。具体来说,设(ˆx,yˆ)是一个检测到的中心点。我们首先回归到所有的联合位置![]() 。我们还从相应的热图ˆΦ··j中提取每个关节类型j的
。我们还从相应的热图ˆΦ··j中提取每个关节类型j的![]() 的置信度>0.1。然后,我们将每个回归位置lj分配到其最近的检测关键点
的置信度>0.1。然后,我们将每个回归位置lj分配到其最近的检测关键点![]() ,只考虑被检测对象的边界框内的联合检测。
,只考虑被检测对象的边界框内的联合检测。
5. Implementation details
作者实验了4种体系结构: ResNet-18、ResNet- 101 [55]、DLA-34 [58]和Hourglass-104[30]。我们使用可变形的卷积层[12]修改了ResNets和DLA-34,并按原样使用Hourglass网络。
6. Experiments
作者在MSCOCO上进行了实验
6.1. Object detection

6.1.1 Additional experiments
Center point collision 在COCO训练集中,有614对物体在步幅4时碰撞到同一中心点。总共有860001个对象,因此由于中心点的碰撞,CenterNet无法预测< 0.1%的对象。这比RCNN系列要少得多,因此一个基于中心的分配会导致更少的碰撞。
NMS NMS影响很小,不使用
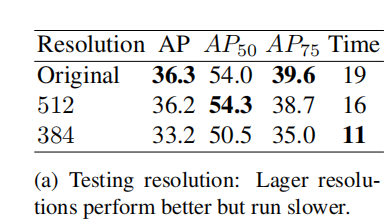
Training and Testing resolution 在测试阶段,保持原始分辨率略优于固定测试分辨率。
Regression loss L1明显优于Smooth L1。、

Bounding box size weight 对于较大的值,AP显著下降,因为损失范围从0到输出大小w/R或h/R,而不是0到1。然而,对于较低的权重,该值不会显著降低。

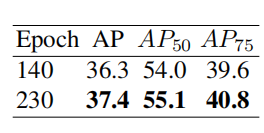
Training schedule 更长的训练计划能够带来更好的性能
6.2. 3D detection

6.3. Pose estimation