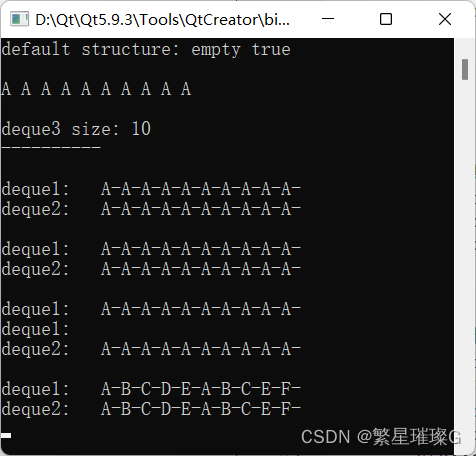
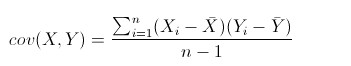文章目录
- 前言
- 服务注册
- 服务续约
- 服务剔除(服务端去剔除过期服务)被动下线
- 服务下线(主动下线)client发起的
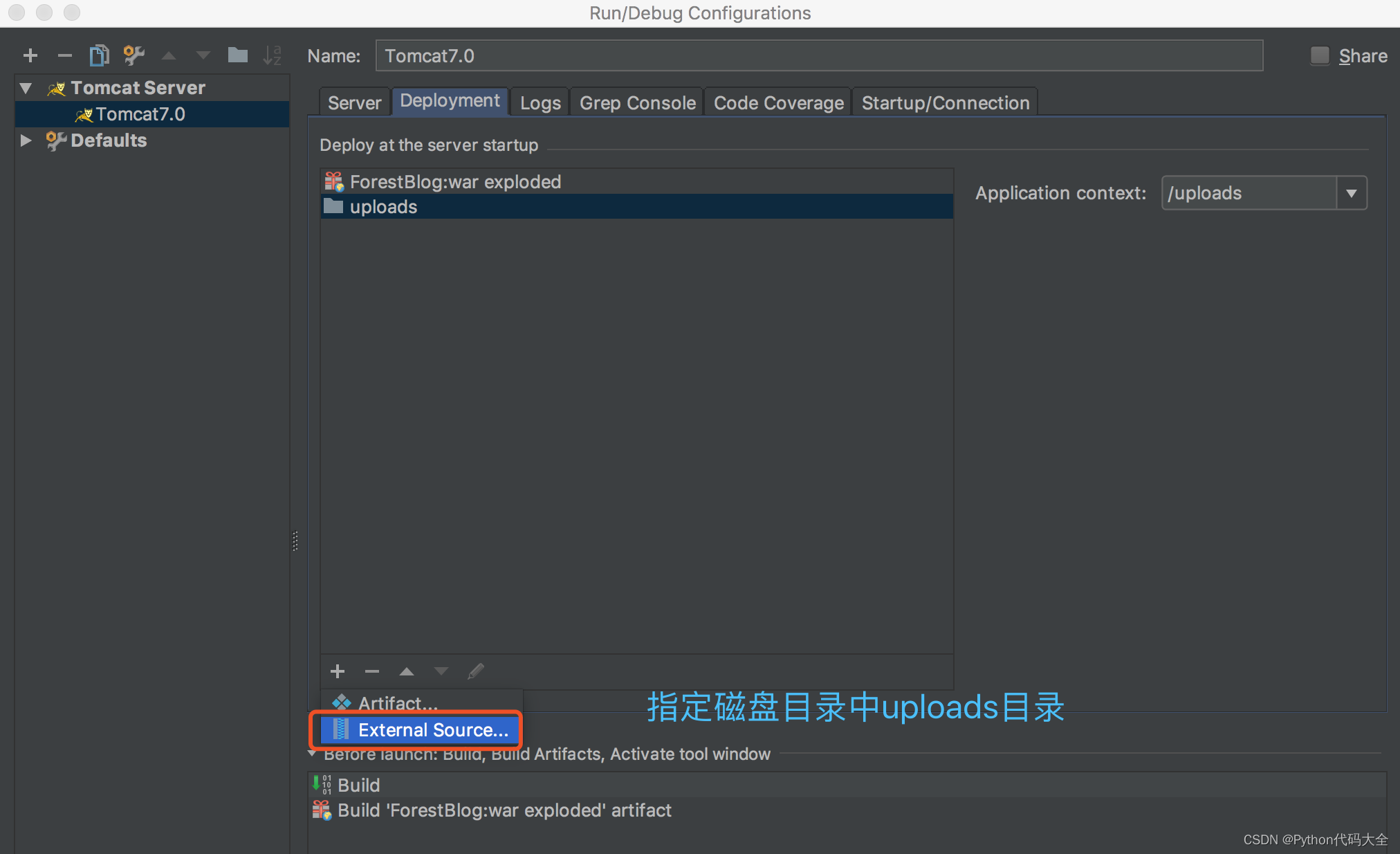
- 服务发现
- 集群同步信息
- Work下载
前言
Eureka是SpringCloud的具体实现之一,提供了服务注册,发现,续约,撤销等功能。并且我们使用Eureka的时候会将其分为客户端client和服务端server。服务端用于作为注册中心,而客户端则作为服务提供者和调用者。
我们引入了Netflix的Eureka-client这个jar包之后,其中包含了DicoveryClient这个类,其提供了与eureka-server进行交互的方法,如register(注册),renew(续约),cancel(注销)等方法。
服务注册
首先是服务注册方法。
这个类中的注册方法首先调用 AbstractJerseyEurekaHttpClient 类的register方法:Jersey是一个Restful请求服务的框架

下面是Jersey这个类中的register方法,他会从我们的配置文件中拿到我们设定的注册中心的URL地址,然后向这个地址发送一个post请求(因为post请求在Restful风格中代表的是添加),并且携带自己的info信息,这个info信息就是该client的配置文件中定义的信息。
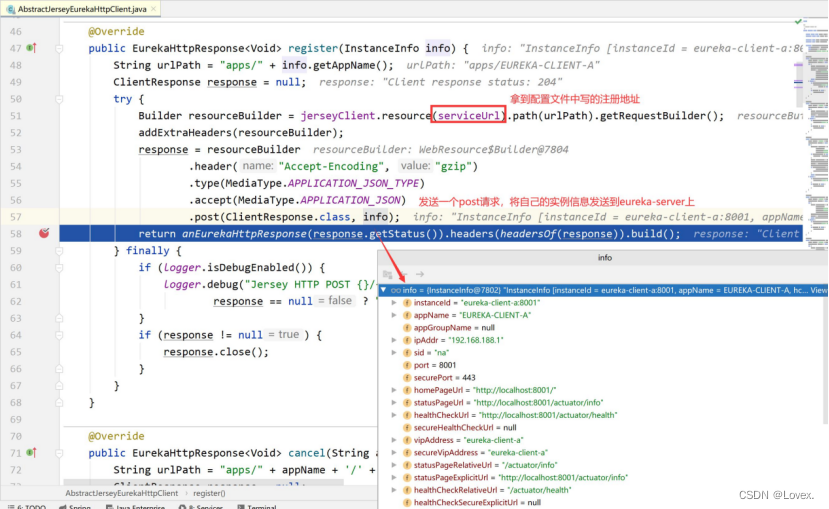
通过HTTP请求向server发送完毕一个注册消息之后,就会构建一个响应结果。
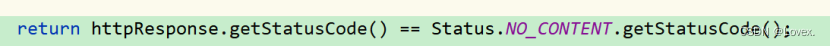
当 eureka 启动的时候,会向我们指定的 serviceUrl 发送请求,把自己节点的数据以 post
请求的方式,数据以 json 形式发送过去。
当返回的状态码为 204 的时候,表示注册成功。
上面是客户端client的注册流程,那么发送注册请求之后,就需要server服务器端去保存这个注册信息了。
在ApplicationResource这个类中,有一个addInstance方法,用于将我们的注册的实例添加到注册中心去.

这个代码的前面是一堆的if else判断,用于对注册的实例信息进行验证.

然后进入这个register方法

可以发现注册信息过来了
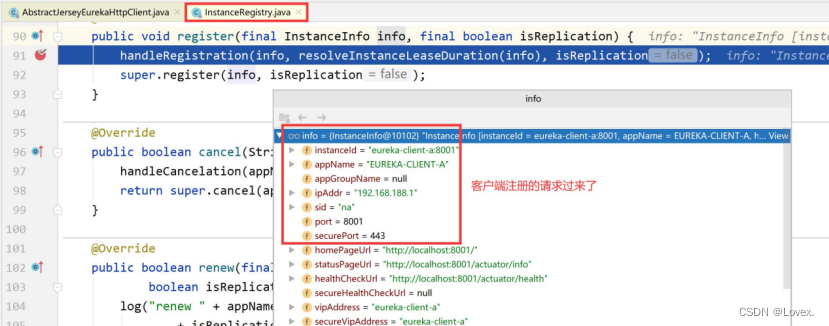
在这里做了两个功能:
1、调用handleRegistration,在方法中使用publishEvent发布了监听事件 。Spring支持事件驱动,可以监听者模式进行事件的监听,这里广播给所有监听者,收到一个服务注册的请求。
2、调用父类PeerAwareInstanceRegistryImpl的register方法:
① 拿到微服务的过期时间,并进行更新
② 将服务注册交给父类完成
③ 完成集群信息同步(这个会在后面说明)
调用父类AbstractInstanceRegistry的register方法,在这开始真正开始做服务注册:
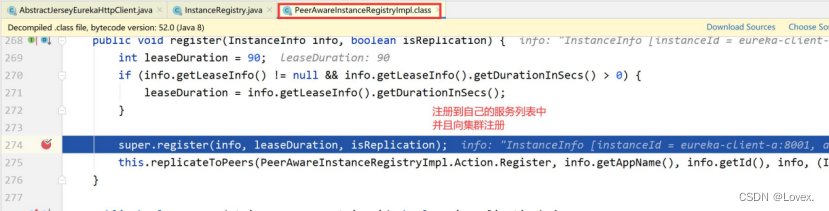
之后这里开始调用父类AbstractInstanceRegistry的register方法,在这开始真正开始做服务注册:
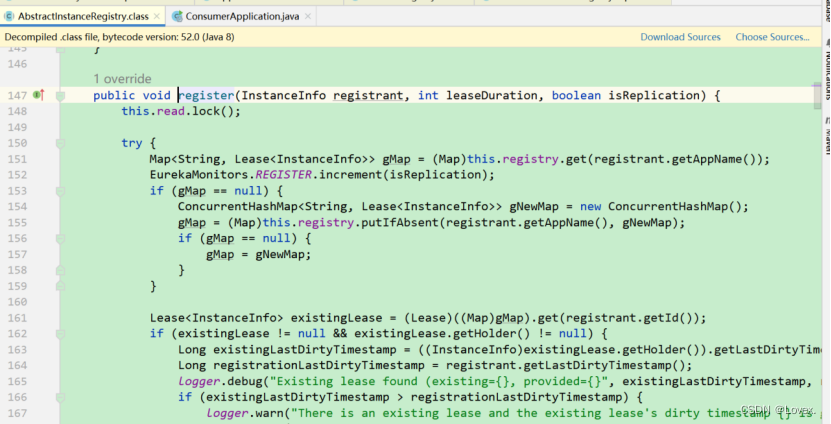
先说一下在这个类中定义的Eureka-server的服务注册列表的结构:

ConcurrentHashMap<String, Map<String, Lease>> registry;
ConcurrentHashMap中外层的String表示服务名称;spring.application.name
Map中的String表示服务节点的id (也就是实例的instanceid);
Lease是一个心跳续约的对象,InstanceInfo表示实例信息。
重要的类:
--------------------------------------client发送注册请求----------------------------
DiscoveryClient 里面的 register()方法完后注册的总体构造
AbstractJerseyEurekaHttpClient 里面的 register()方法具体发送注册请求(post)
-------------------------------------------下面是server中的处理-----------------
InstanceRegistry 里面 register()方法接受客户端的注册请求
PeerAwareInstanceRegistryImpl 里面调用父类的 register()方法实现注册
AbstractInstanceRegistry 里面的 register()方法完成具体的注册保留数据到 map 集合
保存服务实例数据的集合:
第一个 key 是应用名称(全大写) spring.application.name
Value 中的 key 是应用的实例 id
eureka.instance.instance-id

Value 中的 value 是 具体的服务节点信息 也就是Lease里面存放的是你设定的具体实例信息
首先,注册表根据微服务的名称或取Map,如果不存在就新建,使用putIfAbsent。
然后,从gMap(gMap就是该服务的实例列表)获取一次服务实例,判断这个微服务的节点是否存在,第一次注册的情况下一般是不存在的。
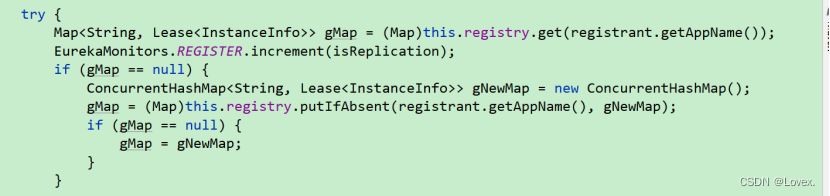
当然,也有可能会发生注册信息冲突时,这时Eureka会根据最后活跃时间来判断到底覆盖哪一个:
这段代码中,Eureka拿到存在节点的最后活跃时间,和当前注册节点的发起注册时间,进行对比。当存在的节点的最后活跃时间大于当前注册节点的时间,就说明之前存在的节点更活跃,就替换当前节点。
这里有一个思想,就是如果Eureka缓存的老节点更活跃,就说明它能够使用,而新来的服务我并不知道是否能用,那么Eureka就保守的使用了可用的老节点,从这一点也保证了可用性。
也就是已经存在的节点发送消息的时间与现在的时间更加接近,就说明已经存在的节点更加活跃.

之后在拿到服务实例后对其进行封装:

Lease是一个心跳续约的包装类,里面存放了注册信息,最后操作时间,注册时间,过期时间,剔除时间等信息。在这里把注册实例及过期时间放到这个心跳续约对象中,再把心跳续约对象放到gmap注册表中去。之后进行改变服务状态,系统数据统计,至此一个服务注册的流程就完成了。
注册完成后,查看一下registry中的服务实例,发现我们启动的Eureka-client都已经放在里面了:
在我们的eureka-server中,只要我们写完配置文件之后,就可以使用@EnableEurekaServer注解来开启注册中心服务。
查看该注解的实现方法,发现为空白注解,使用@Import:
@Import(EurekaServerMarkerConfiguration.class)
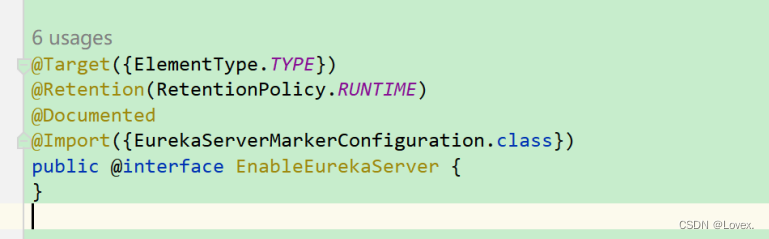
而这个类的作用就是向spring容器中注入Marker对象
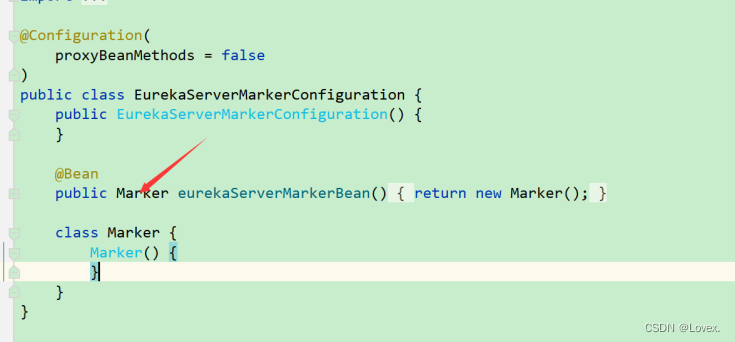
此时继续查看Eureka-server的自动配置类,发现其要求必须先注入Marker这个类
所以@EnableEurekaServer就相当于一个开关,起到标识的作用。

服务续约
服务续约由Eureka-client端主动发起,由之前介绍过的DiscoveryClient类中的renew方法完成,主要内容仍然是发送http请求:

每隔30秒进行一次续约,调用AbstractJerseyEurekaHttpClient的sendHeartBeat方法:
发送心跳其实就是进行服务的续约了
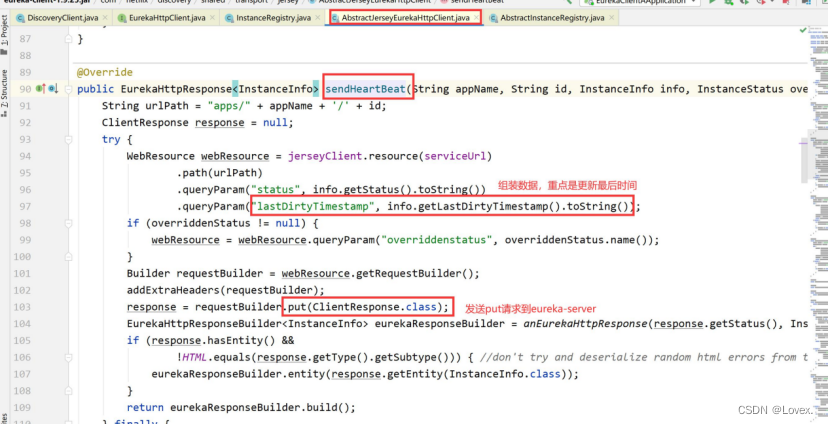
在eureka-server端
在Eureka-server端,服务续约的调用链与服务注册基本相同:
InstanceRegistry # renew() ->PeerAwareInstanceRegistry # renew()->AbstractInstanceRegistry # renew()
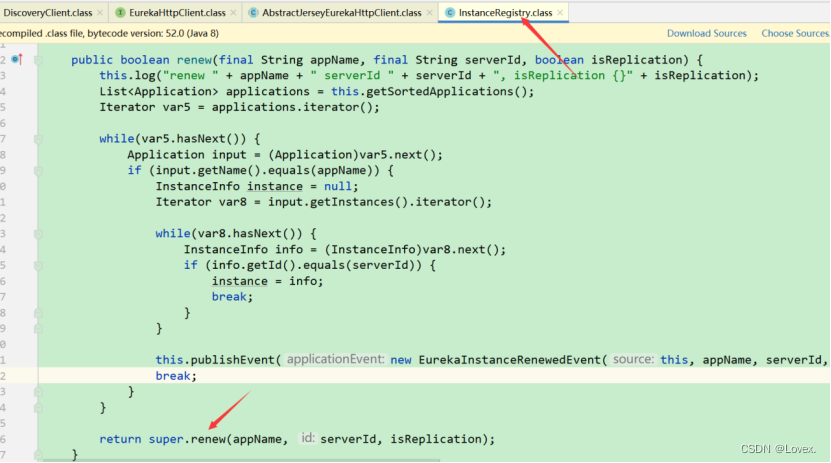
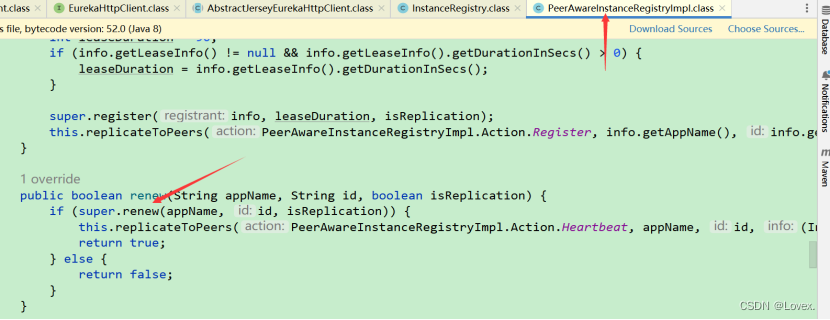
主要看一下AbstractInstanceRegistry 的renew方法:
先从注册表获取该服务的实例列表(gMap),再从gMap中通过实例的id 获取具体的 要续约的实例。之后根据服务实例的InstanceStatus判断是否处于宕机状态,以及是否和之前状态相同。如果一切状态正常,最终调用Lease中的renew方法:
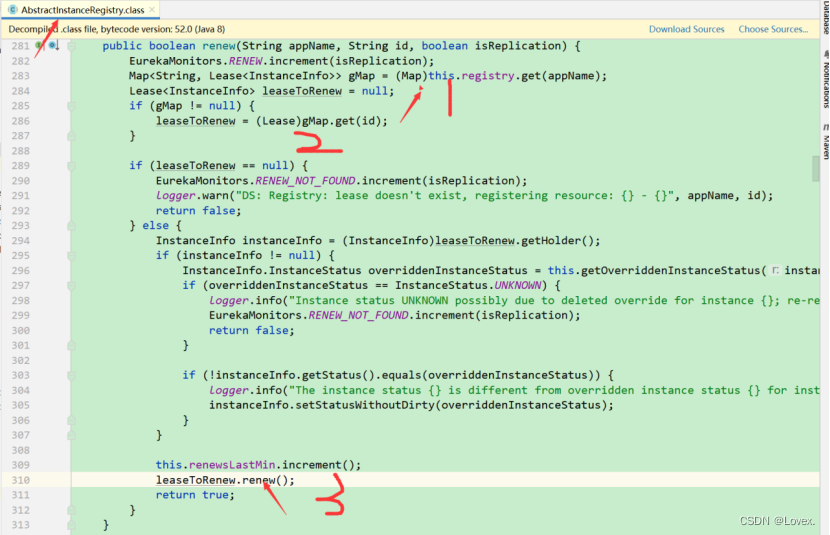
可以看出,其实服务续约的操作非常简单,它的本质就是修改服务的最后的更新时间。将最后更新时间改为系统当前时间加上服务的过期时间。续约的本质就是修改了服务节点的最后更新时间
值得提一下的是,lastUpdateTimestamp这个变量是被volatile关键字修饰的。
volitaile是用来保证可见性的。那么要被谁可见呢,提前说一下,这里要被服务剔除中执行的定时任务可见
因为剔除某个服务的话就是根据时间来判定的,因此要求这个时间是实时可见的,要求是最新的.所以这里用volatile
duration:代表注册中心最长的忍耐时间:
并不是 30s 没有续约就里面剔除,而是 30 +duration(默认是 90s) 期间内没有续约,才剔 除服务
Volatile 标识的变量是具有可见性的,当一条线程修改了我的剔除时间,其他线程就可以立 马看到(应用场景:一写多读),后面在剔除里面有一个定时任务,去检查超时从而判断某一 个服务是否应该被剔除

服务剔除(服务端去剔除过期服务)被动下线
当Eureka-server发现有的实例没有续约超过一定时间,则将该服务从注册列表剔除,该项工作由一个定时任务完成的。
在AbstractInstanceRegistry 中有一个 postInit()方法。这个方法设定了一个EvictionTask任务,这个任务用于定时执行剔除操作
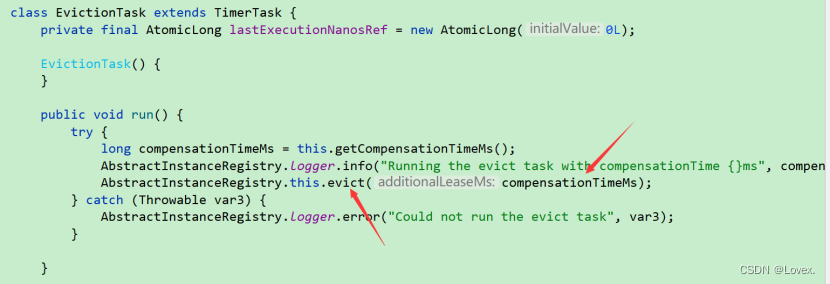
之后来看evict方法的实现
这个方法首先创建了一个用于存放已经过期的实例的List集合,之后开始吧每一个spring。application。name下面的每一个注册中心的拥有的服务进行遍历,并且把所有已经过期的服务放入到这个List集合,知道遍历完毕所有的服务之后开始进行处理。
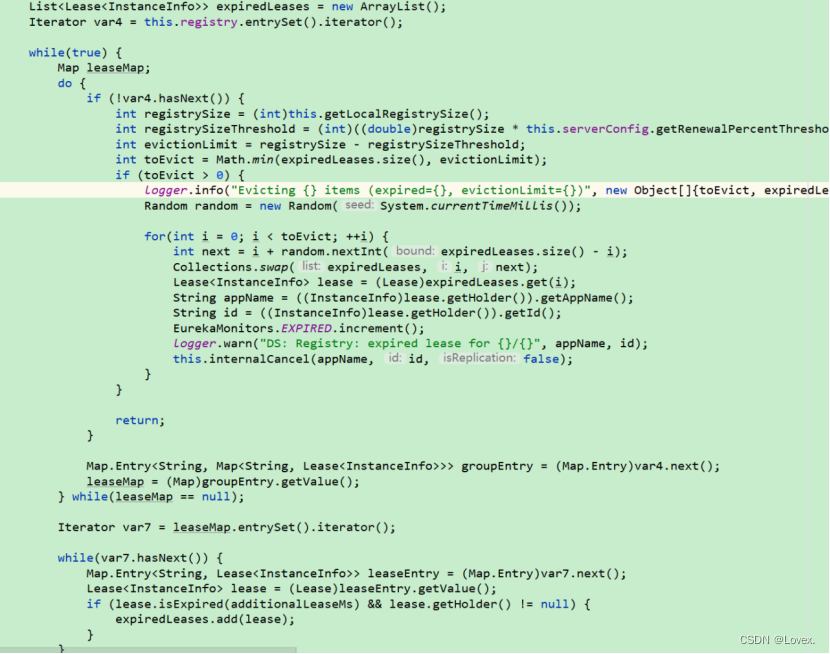
其中这个方法
evictionTimestamp:剔除时间,当剔除节点的时候,将系统当前时间赋值给这个
evictionTimestampadditionalLeaseMs:集群同步产生的预留时间,这个时间是程序中传过来的

系统当前时间 >最后更新时间 + 过期时间 + 预留时间
当该条件成立时,认为服务过期。在Eureka中过期时间默认定义为3个心跳的时间,一个心跳是30秒,因此过期时间是90秒。
当以上两个条件之一成立时,判断该实例过期,将该过期实例放入上面创建的列表中。注意这里仅仅是将实例放入List中,并没有实际剔除。
在实际剔除任务前,需要提一下eureka的自我保护机制:
当15分钟内,心跳失败的服务大于一定比例时,会触发自我保护机制。

这个值在Eureka中被定义为85%,一旦触发自我保护机制,Eureka会尝试保护其服务注册表中的信息,不再删除服务注册表中的数据。
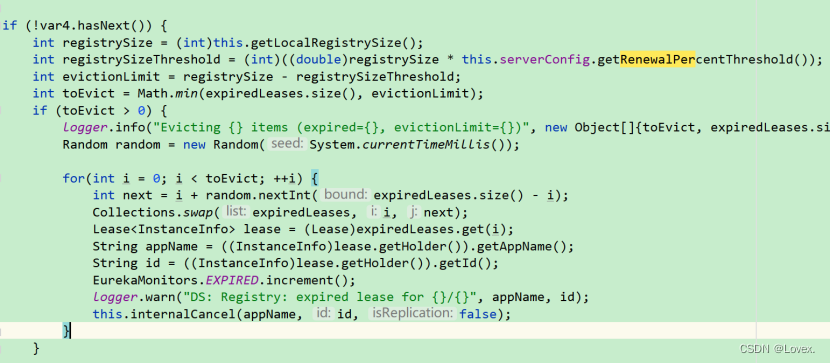
参数意义:
registrySizeThreshold:根据阈值计算可以被剔除的服务数量最大值evictionLimit:剔除后剩余最小数量
expiredLeases.size():剔除列表的数量
上面的代码中根据自我保护机制进行了判断,使用Min函数计算两者的最小值,剔除较小数量的服务实例。
举个例子,假如当前共有100个服务,那么剔除阈值为85,如果list中有60个服务,那么就会剔除该60个服务。但是如果list中有95个服务,那么只会剔除其中的85个服务,在这种情况下,又会产生一个问题,eureka-server该如何判断去剔除哪些服务,保留哪些服务呢?
其实是根据随机算法来进行删除的,首先得到一个随机数,然后交换一下剔除集合中的数据,然后得到要删除的数据的编号,然后根据这个编号得到这个服务对应的应用名称appname和服务id。
然后调用intervalCancel进行定时的服务删除。
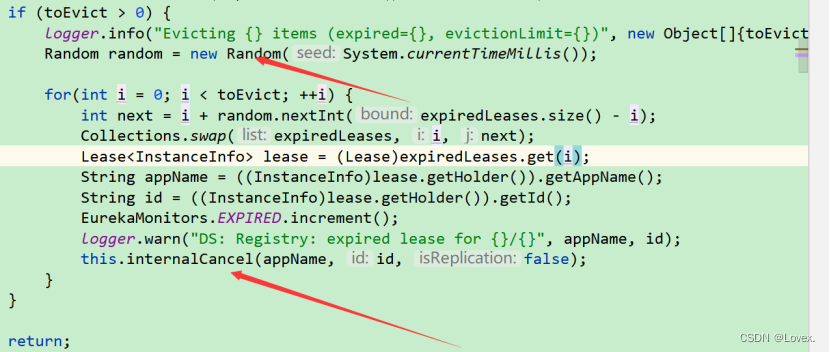
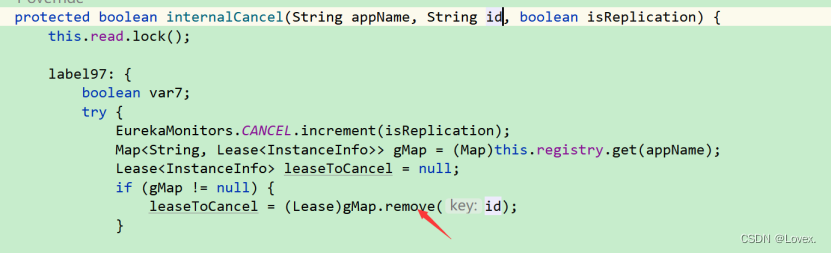
然后删除任务的方法就是从gmap中删除这个id对应的服务
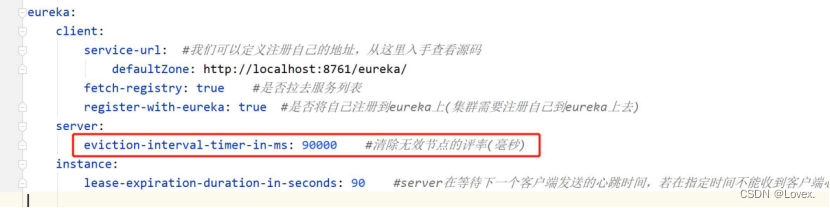
服务剔除方法每隔60s执行一次,当然我们也可以在配置文件中自定义时间
服务下线(主动下线)client发起的
要下线的时候会调用shutdown方法,然后shutdown方法调用了unregister方法
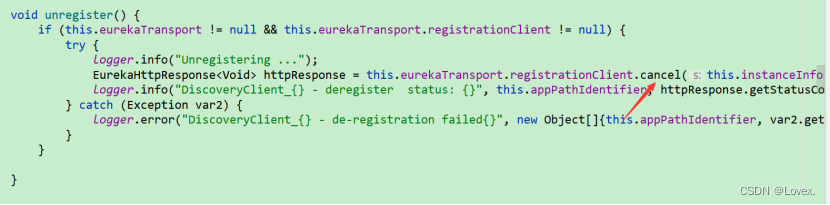
调用AbstractJerseyEurekaHttpClient 的cancel方法:
发送http请求告诉eureka-server自己下线。
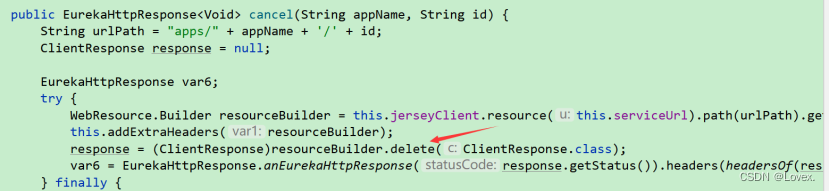
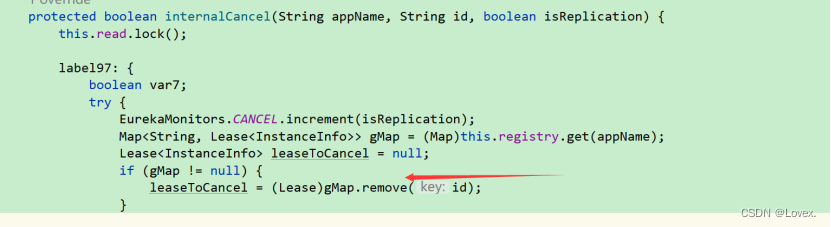
之后这个请求就会被server服务端收到,然后服务端调用cancel方法进行服务取消注册

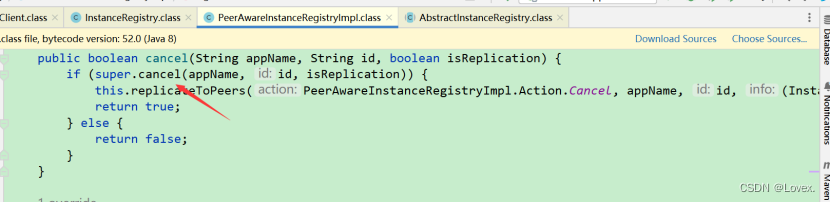
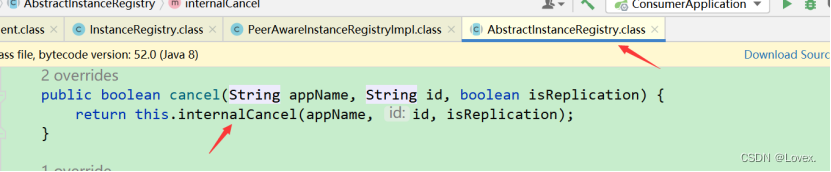
这里最后又调用了internalCancel这个方法后根据id去gmap中删除对应的实例
服务发现
服务发现也就是一个服务去发现另一个服务,或者客户端去发现另一个服务的过程
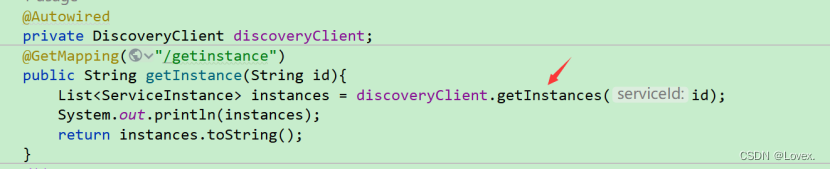
可以通过DicoveryClient的getInstances方法去得到当前serviceId对应的服务的信息。
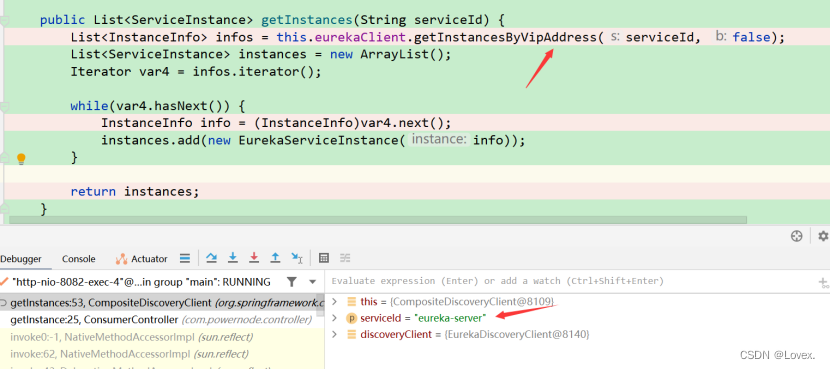
getInstancesByVipAddress这个方法用于进行服务发现。
首先判断本地是否有这个服务,如果本地有,那么就从本地直接拿。
如果没有,那么就从远程拿。
最后applications.getInstancesByVirtualHostName才是真正的获取服务列表
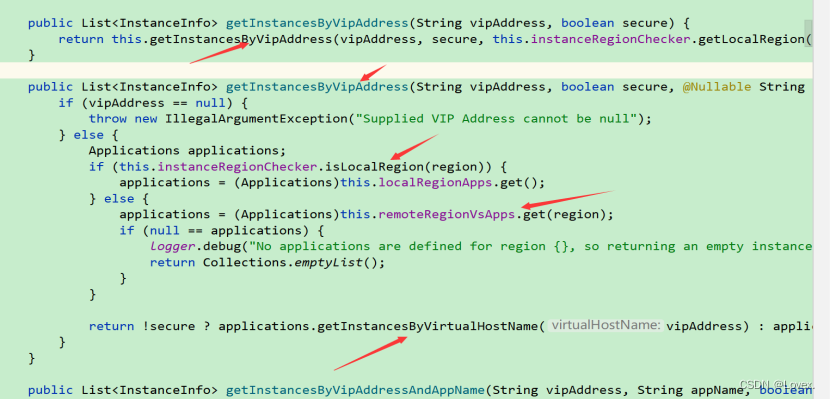
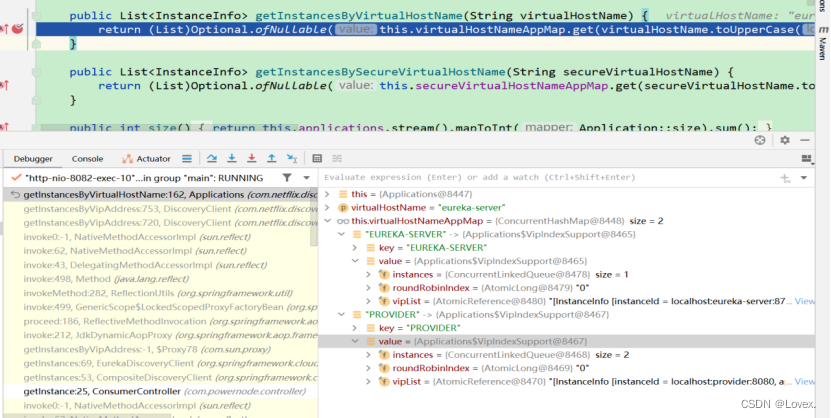
这里通过get方法真正的拿到了服务实例的集合
夸张的地方就在这里,因为明明我们还没有调用完毕getInstances获取实例的方法,但是这个map集合中就已经有了所有实例的数据了,这说明一定是在我们还没有调用getInstances试图去获取注册的实例之前,eureka就已经获取到了所有的实例了,并且把他们缓存在自己的信息中了。
也就是在我们还没有做服务发现之前,集合里面已经有值了,说明项目启动的时候就已经去server端里面拉取了所有服务并且进行了缓存。(这里的eureka是我是用客户端发送的,为下图comsumer,eureka-server表示的是注册中心,也就是说consumer这个客户端在我还没有进行服务发现的时候他就已经把server中的所有的服务都已经拉取到本地进行缓存了)
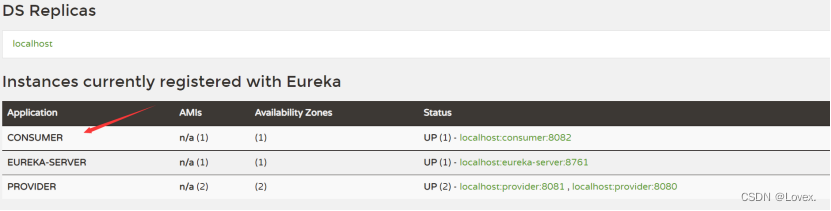
这个构造函数中有一个任务调度线程池
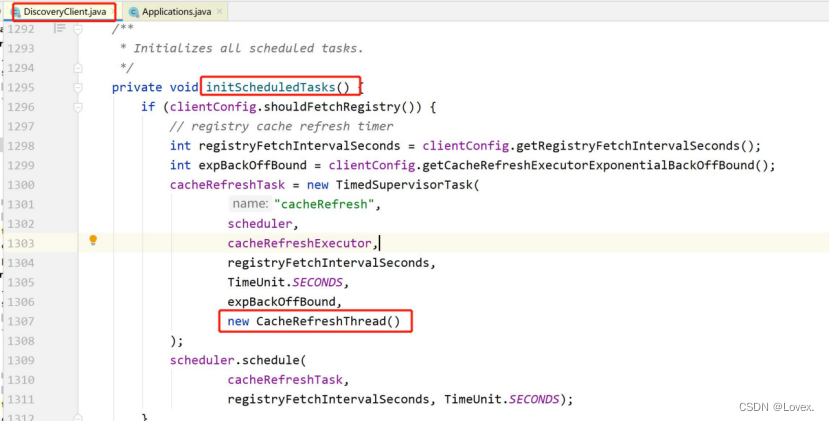
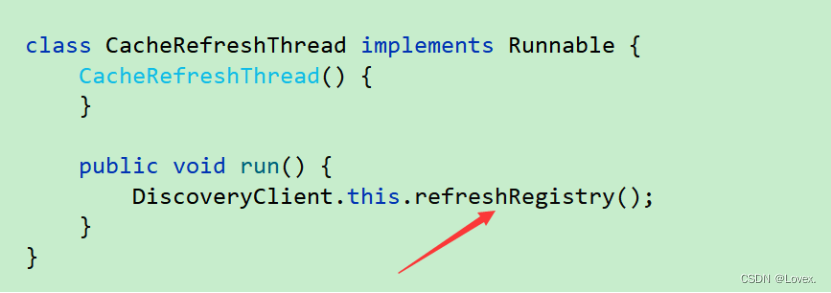
在 CacheRefreshThread()中
fetchRegistry()方法中判断决定是全量拉取还是增量拉取
这个方法就是用来拉取服务的
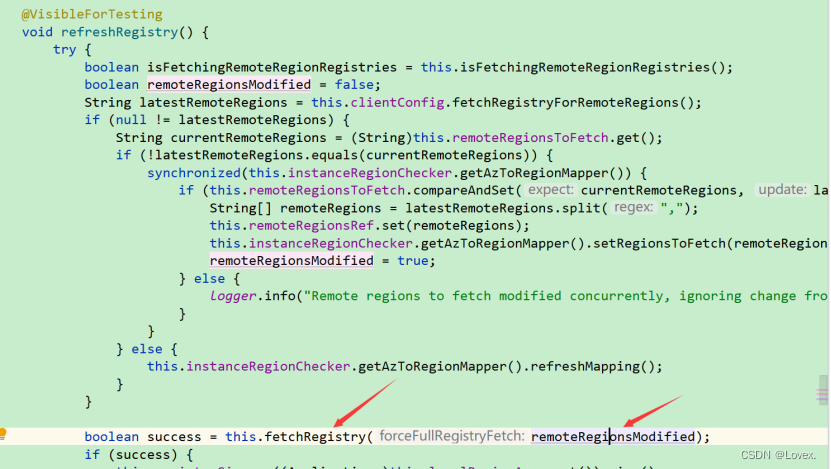
如果有新增服务,那么就进行增量拉取
如果服务列表为null,那么就直接进行全量拉取
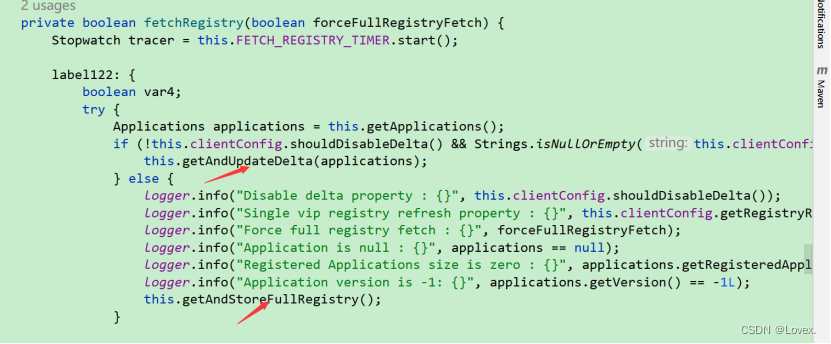
第一个箭头指向的是向eureka-server拉取服务
第二个箭头是指把服务放入到本地服务列表中
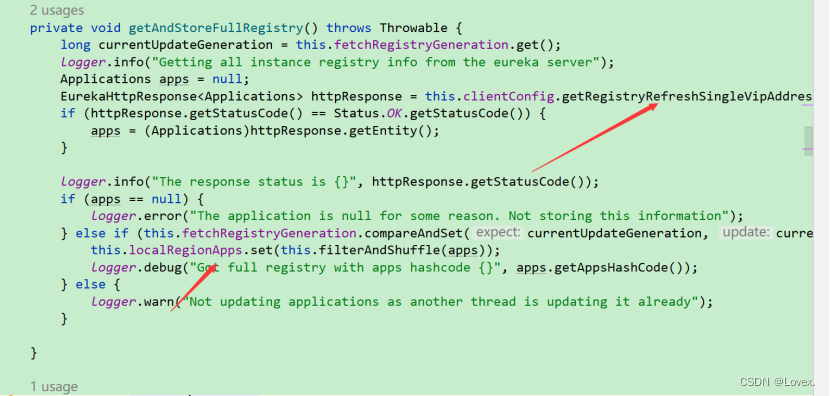
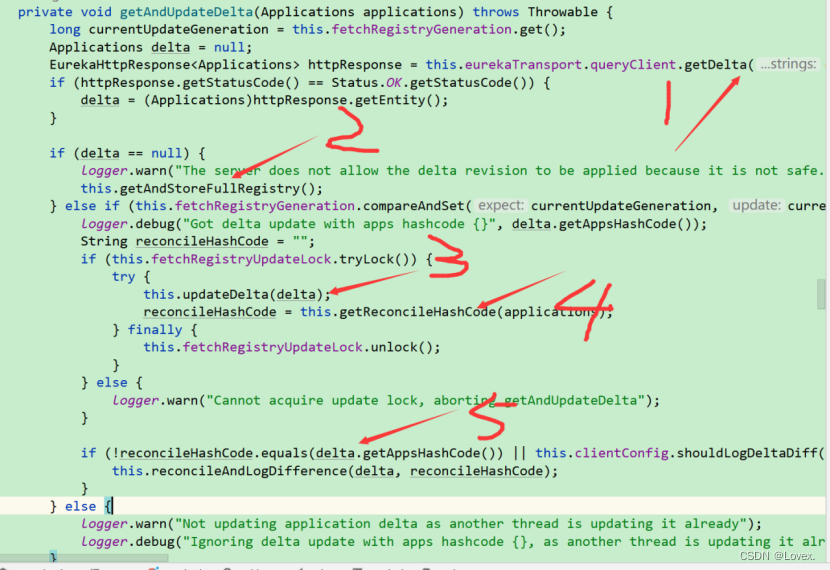
下面是增量拉取
12表示先拉取服务列表,如果服务列表为null,那么直接进行一次全量拉取
不为空则进行增量拉取,然后进行一次一致性hash算法,判断此时的服务列表是否与eureka-server中的服务是一样的,如果一样,那么成功,否则在进行一次拉取。
DiscoveryClient 类里面的构造方法执行线程初始化调用
CacheRefreshThread 类里面的 run 方法执行服务列表的拉取(方便后期做服务发现)
fetchRegistry()方法去判断全量拉取还是增量拉取
全量拉取发生在:当服务列表为 null 的情况 当项目刚启动就全量拉取
增量拉取发生:当列表不为 null ,只拉取 eureka-server 的修改的数据(注册新的服务, 上线服务)
eureka 客户端会把服务列表缓存到本地 为了提高性能
但是有脏读问题,当你启动一个新的应用的时候 不会被老的应用快速发现,毕竟eureka相比于zookeeper,放弃的就是一致性,选择的是高可用,也就是AP组合。
集群同步信息
集群的信息同步发生在eureka-server服务端之间。
在执行register方法注册微服务实例完成后,执行了集群信息同步方法replicateToPeers
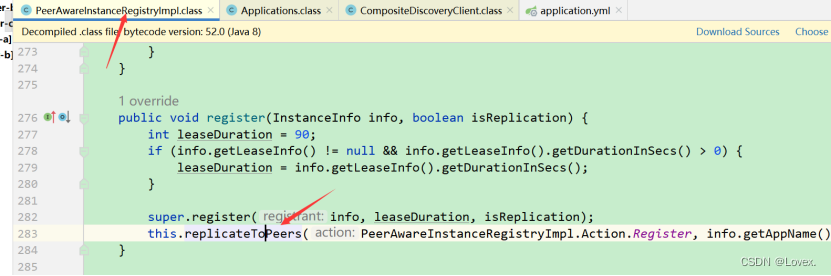
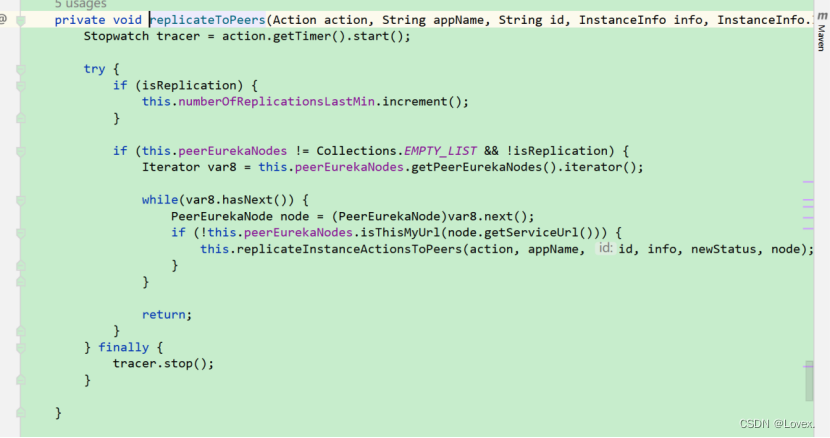
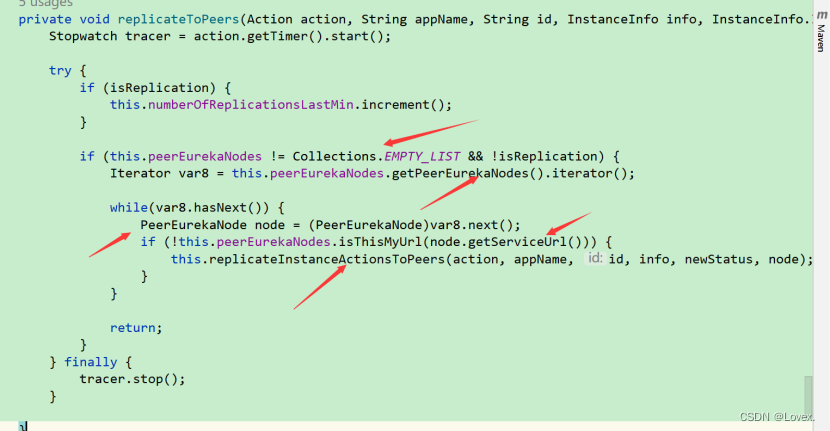
首先,判断是否有节点,然后遍历集群节点,用以给各个集群信息节点进行信息同步。
然后,调用replicateInstanceActionsToPeers方法,在该方法中根据具体的操作类型Action,选择分支,最终调用PeerEurekaNode的register方法:
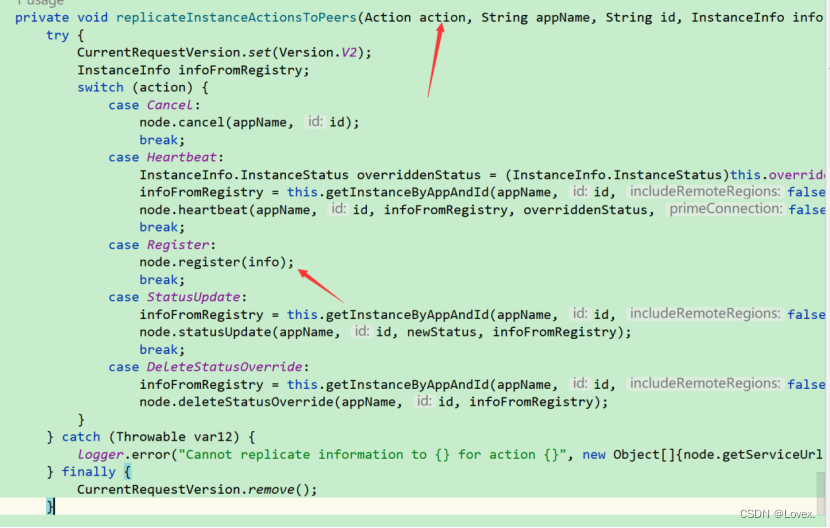
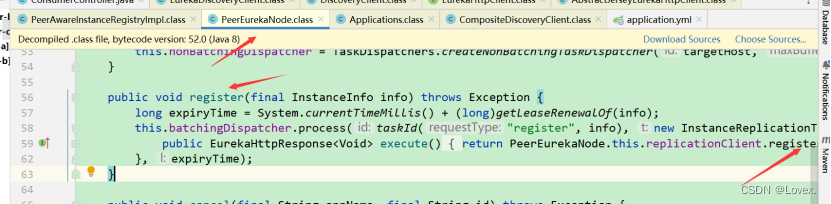
这个后面调用了一个post请求
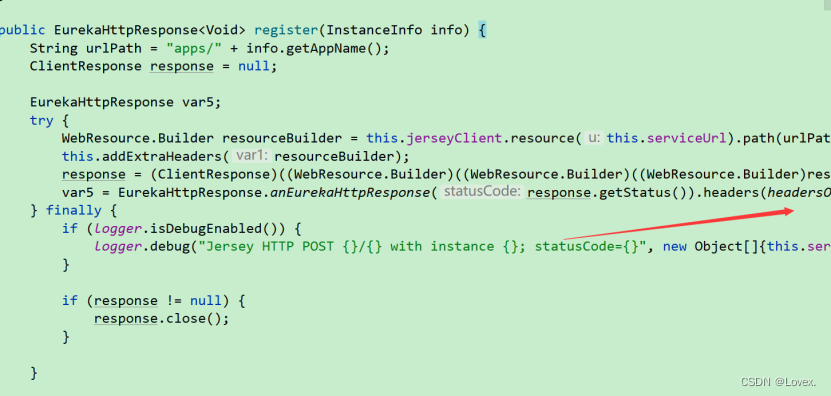
之后post请求发送完毕之后,进行判断
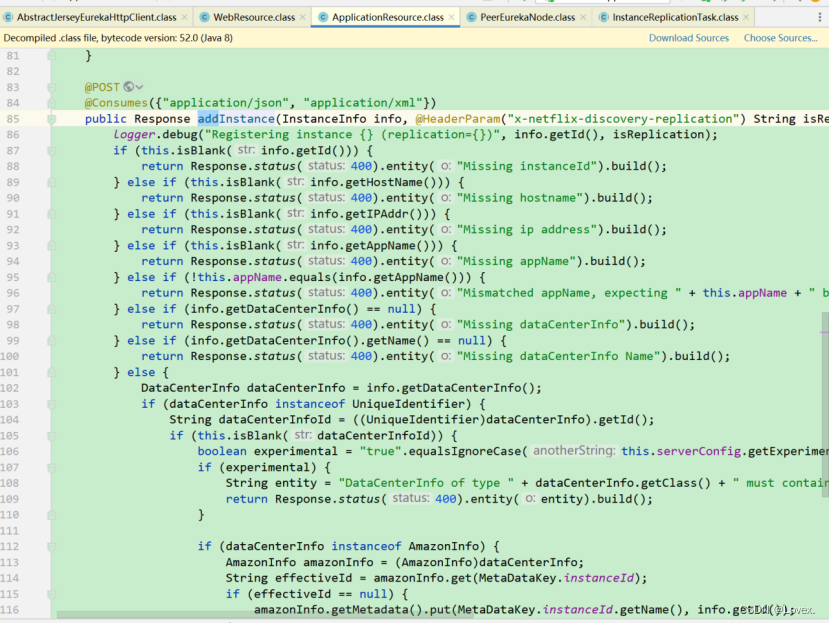

最后如果是集群模式,那么就会把集群同步的表示isReplication设定为true,说明注册的信息是来自于集群同步。
在注册过程中运行到addInstance方法时,单独注册时isReplication的值为false,集群同步时为true。通过该值,能够避免集群间出现死循环,进行循环同步的问题。
![[ Linux Audio 篇 ] Type-C 转 3.5mm音频接口介绍](https://img-blog.csdnimg.cn/480365a2c1cc47639ea99fe178bb83f4.jpeg#pic_center)