一、乐观锁和悲观锁
二、轻量级锁和重量级锁
三、自旋锁和挂起等待锁
四、普通互斥锁和读写锁
五、公平锁和非公平锁
六、可重入锁和不可重入锁
七、synchronized和Linux的mutex锁的简单比较
八、synchronized的自适应
一、乐观锁和悲观锁
乐观锁:在加锁之前,预估锁冲突的概率比较小,因此加锁的时候就不会为此做太多的准备,加锁做的事情比较少,因此加锁的速度也就可能更快。
悲观锁:在加锁之前,预估锁冲突的概率比较大,因此加锁的时候就会做大量的准备,加锁做的事情比较多,因此加锁的速度也就可能更慢。
二、轻量级锁和重量级锁
轻量级锁:运行代码之后,锁冲突的概率比较小,因此加锁的开销比较小,速度也比较快。
重量级锁:运行代码之后,锁冲突的概率比较大,因此加锁的开销比较大,速度也比较慢。
注意:这里和乐观、悲观锁不同的是,乐观、悲观锁是加锁之前进行的预估,而这里指的是加锁之后对结果的评价。
三、自旋锁和挂起等待锁
自旋锁:是轻量级锁的一种典型实现,加锁的时候,如果加锁失败,不会就此退出锁竞争,而是会循环不停的进行锁竞争,这次锁竞争失败了就再次进入循环竞争锁,直到加锁成功,才退出循环。
这种反复快速的执行,就称为 “自旋”,同时,自旋锁也是乐观锁,只要其他线程释放了锁,它就能第一时间加锁成功,这样它的加锁速度也很快,但如果有很多线程要加锁,也没必要使用自旋锁了,会白白浪费cpu资源。
等待挂起锁:是重量级锁的一种典型体现,也是悲观锁,加锁的时候,如果加锁失败,就会等待一段时间,这段时间它不会去进行加锁,和别的线程锁竞争,这时候就能把一些cpu资源让出来了,用这些cpu资源可以干一些其他事情,等一段时间过后,会再次尝试加锁,如果失败还是重复以上工作,成功就拿到锁了,没啥好说的。
当等待挂起的时候,会有内核调度器介入,这一块要完成的操作就多了,从而要获取锁的时间花费也更多一些。
四、普通互斥锁和读写锁
普通互斥锁:类似synchronized这种,操作涉及到加锁、解锁
读写锁:这里加锁的情况分为两种:加读锁,加写锁
读锁和读锁之间,不会涉及到锁冲突(不会阻塞)
写锁和写锁之间,会涉及到锁冲突(会阻塞)
读锁和写锁之间,会涉及到锁冲突(会阻塞)
当一个线程加读锁时,另一个线程只能读,不能写
当一个线程加写锁时,另一个线程不能写,也不能读
为啥要引入读写锁?
如果两个线程只读,这个操作本身就是安全的,不需要进行加锁。但是如果使用synchronized来加锁,读和读之间会涉及到锁竞争(阻塞),但我们也不能完全不给读操作加锁,就怕一个线程读,一个线程写,这时候肯定就有线程安全问题。
读写锁,就能很好的解决上述问题。
如果只有读的操作,读操作中不会有修改操作,这时候每个线程读的数据都是同一个不变的数据,如果加锁了,就会耗费一些没必要消耗的资源空间,不如加个读锁,读的时候不会锁竞争,写的时候才会,这样就能省去很多不必要的资源开销了(锁冲突的开销)
五、公平锁和非公平锁
公平锁:如果线程和线程之间,锁竞争的时间大小不一样,按照锁竞争时间久的线程先拿到锁,有先后顺序(先来后到的意思)
非公平锁:线程和线程之间没有拿锁顺序,随机调度,各凭各的本事拿锁。
这里使用公平锁,就能很好的解决线程饿死的这一问题。而要想实现公平锁,就需要引入额外的数据结构(引入队列,记录每个线程的先后顺序),才能实现公平锁。
六、可重入锁和不可重入锁
可重入锁:如synchronized,加锁一段代码,锁里面可以再进行一次加锁,锁里面可以嵌套多个锁,里面是用计数器这种方式对加锁技术,并判断是否解锁,是可重入锁。
不可重入锁:系统自带的锁,不能连续加锁两次。
七、synchronized和Linux的mutex锁的简单比较
synchronized:乐观锁 / 悲观锁自适应
轻量级锁 / 重量级锁自适应
自旋锁 / 挂起等待所自适应
不是读写锁
非公平锁
可重入锁
mutex: 悲观锁
重量级锁
挂起等待所
不是读写锁
非公平锁
不可重入锁
八、synchronized的自适应
synchronized内部优化的很好,有自适应性,通常都可以无脑用,而且效率也不会低。
1、锁升级
(1)偏向锁阶段
核心思想:“懒汉模式”,就是能不加锁,就不加锁,能晚加锁就晚加锁;所谓的偏向锁,并不是真的加锁了,只是做了个非常轻量的标记。
一旦有线程来竞争这个锁,持有偏向锁的线程能第一时间拿到这个锁,如果没有其他线程竞争锁,下次还是拿到锁的线程大概率还是持有偏向锁的线程。总的来说,当有锁竞争的情况下,偏向锁没有提高效率,在没有锁竞争的情况下,偏向锁就能大幅度的提高效率了。
这个标记是锁里面的一个属性,每个锁都有自己的标记,当锁对象首次加锁是,没有涉及到锁竞争,这个阶段就是偏向锁阶段,一旦涉及到锁竞争,就会升级成轻量级锁阶段。
(2)轻量级锁阶段
此处的轻量级锁就是通过自旋的方式实现的,假设有锁竞争,但不多,就会处于轻量级锁阶段,它的优势:当其他线程释放锁了,处于轻量级锁阶段的线程能第一时间拿到锁;劣势:比较消耗cpu资源,因为是自旋的方式实现的,会有个循环一直尝试拿锁。
当线程多了,轻量级锁就不合适了,每个线程都循环尝试拿锁,但如果已经有线程拿到锁了,其他线程要阻塞等待,但等待的这过程是会有循环不断的尝试拿锁,这里消耗的cpu资源就很多了。这时,就会从轻量级锁阶段升级成重量级锁阶段。
(3)重量级锁阶段
此处的轻量级锁是用挂起等待的方式实现的,当有很多线程同时去竞争这个锁时,有个线程拿到锁了,其他线程没拿到,就不会再不断的重复尝试去拿锁,而是阻塞等待,等待一段时间再去尝试拿锁,不成功再阻塞等待一段时间,循环以上步骤,这题就会让出cpu的资源,可以利用这些cpu资源干一些其他的事。
注意:此处只能升级,不能降级,但是只是当前版本是这样的,以后的版本也说不好会添加降级的功能。
2、锁消除
也是synchronized的内部优化;有时候,有些代码可以一眼看上去就不用加锁,但是代码加锁了,这时候,编译器就会把这个锁给干掉,毕竟加锁操作也是要消耗一些硬件资源的。
注意:锁消除和偏向锁的区别
锁消除:针对能够一眼就看出不涉及到线程安全问题的代码,编译器能够把锁给消除掉。
偏向锁:是已经运行代码了,才知道没有锁竞争。
3、锁粗化
通常情况下,我们更偏好于让锁更细一些,这样更有利于并发编程的时候解决线程安全问题,但有时候,让锁更粗写能提高效率,会希望锁粗点。
锁粗化:把多个细粒度的锁合并成一个粗粒度的锁。
如图:
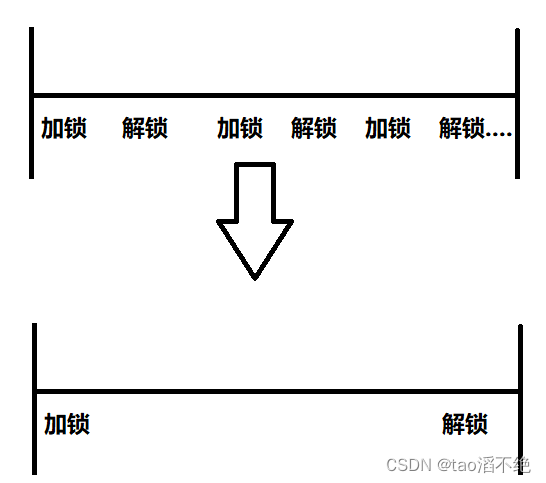
一段代码中,频繁的加锁解锁,肯定会消耗更多的硬件资源,但是如果能把一段代码这些加锁解锁操作,优化成只有一次加锁、解锁,这样也能提高效率。而锁粗化目的也是提高效率。