概念 :中央任务调度中枢
- ✅ 优点:全局资源协调,确保任务执行顺序
- ❌ 缺点:单点故障风险,可能成为性能瓶颈
import operator
import os
from langchain.schema import SystemMessage, HumanMessage
from langchain_openai import ChatOpenAI
from langgraph.graph import StateGraph, START, END
from langgraph.constants import Send
from pydantic import BaseModel, Field
from typing_extensions import Annotated, TypedDict, List
# 将一个论证标题拆分为多个子标题,大模型并行执行这些子标题,最终汇总所有的结果。
# 初始化模型
llm = ChatOpenAI(
model="gpt-3.5-turbo",
openai_api_key=os.environ["GPT_API_KEY"],
openai_api_base="https://api.chatanywhere.tech/v1",
streaming=False # 禁用流式传输
)
# 大模型拆分的某一个维度的结构
class Section(BaseModel):
name: str = Field(description="章节标题")
description: str = Field(description="章节概述")
# 结构化输出信息的实体类,输出一个列表
class Sections(BaseModel):
sections: List[Section] = Field(description="章节列表")
# 大模型用到的一些参数
class State(TypedDict):
topic: str
sections: list[Section]
completed_sections: Annotated[list, operator.add]
final_report: str
# 大模型并行执行的任务参数
class WorkerState(TypedDict):
section: Section
completed_sections: Annotated[list, operator.add]
# 大模型的调度器,将任务拆分
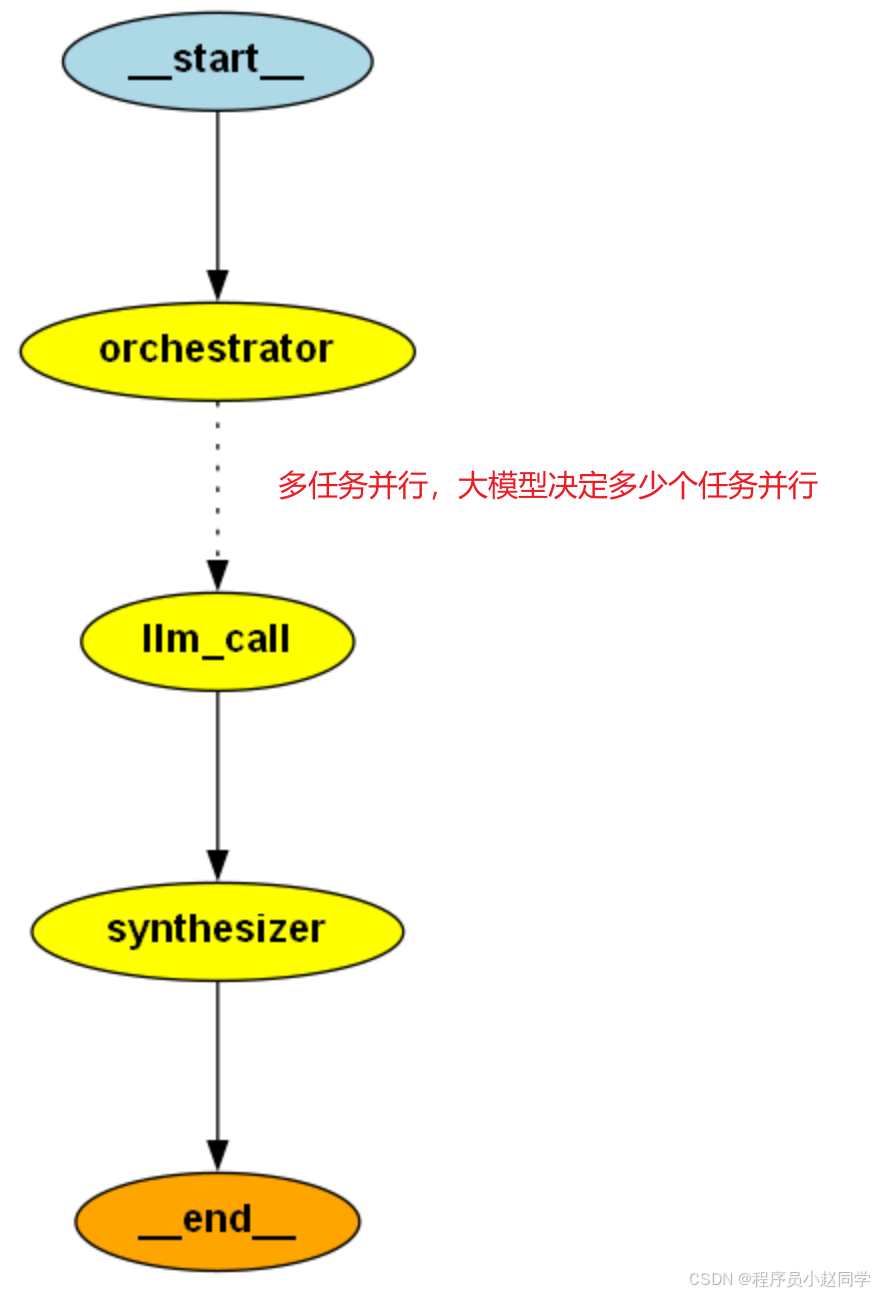
def orchestrator(state: State):
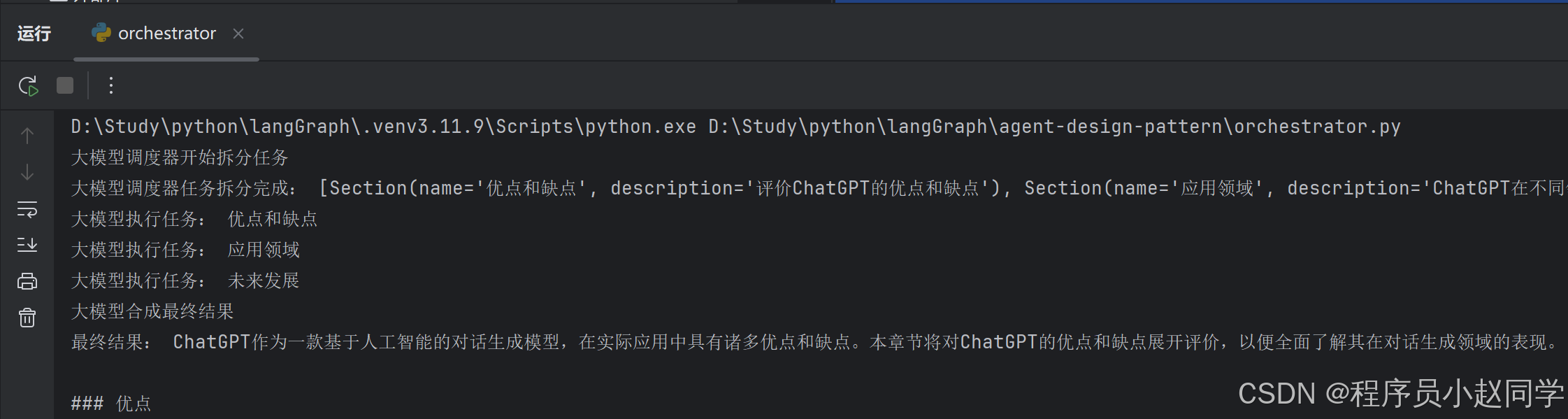
print("大模型调度器开始拆分任务")
new_llm = llm.with_structured_output(Sections, method="function_calling")
output = new_llm.invoke(
[
SystemMessage(content="你需要分析论证某个主题,并将其拆分成几个不同的立场进行多视角分析。"),
HumanMessage(content=f"论证主题:{state['topic']}")
]
)
print(f"大模型调度器任务拆分完成: {output.sections}")
return {"sections": output.sections}
# 大模型执行的具体任务
def llm_call(state: WorkerState):
print(f"大模型执行任务: {state['section'].name}")
output = llm.invoke(
[
SystemMessage(content="根据提供的章节标题和概述,完成论证文章中的其中一个章节。"),
HumanMessage(content=f"章节标题为:{state['section'].name} 章节概述为:{state['section'].description}")
]
)
return {"completed_sections": [output.content]}
# 大模型合成最终结果
def synthesizer(state: WorkerState):
print(f"大模型合成最终结果")
completed_sections = state["completed_sections"]
completed_report_sections = "\n\n---\n\n".join(completed_sections)
return {"final_report": completed_report_sections}
# 分配到多个任务上
def assign_worker(state: State):
# 需要多个任务并发,但是并不清楚有多少个任务时,使用Send
return [Send("llm_call", {"section": s}) for s in state["sections"]]
# 创建工作流
work_flow = StateGraph(State)
work_flow.add_node("orchestrator", orchestrator)
work_flow.add_node("llm_call", llm_call)
work_flow.add_node("synthesizer", synthesizer)
work_flow.add_edge(START, "orchestrator")
work_flow.add_conditional_edges(
"orchestrator",
assign_worker,
["llm_call"]
)
work_flow.add_edge("llm_call", "synthesizer")
work_flow.add_edge("synthesizer", END)
graph = work_flow.compile()
result = graph.invoke({"topic": "如何评价ChatGPT"})
print(f"最终结果: {result['final_report']}")
执行结果
![MySQL基础 [三] - 数据类型](https://i-blog.csdnimg.cn/direct/286af1eb96cd41e6bd8d4458c4fc5eeb.png)