🚩write in front🚩
🔎大家好,我是謓泽,希望你看完之后,能对你有所帮助,不足请指正!共同学习交流🔎
🏅2021年度博客之星物联网与嵌入式开发TOP5~2021博客之星Top100~阿里云专家博主 & 星级博主~掘金⇿InfoQ~51CTO[创作者]~周榜373﹣总榜1055⇿全网访问量40w+🏅
🆔本文由 謓泽 原创 CSDN首发🙉如需转载还请通知⚠
📝个人主页-謓泽的博客_CSDN博客 📃
🎁欢迎各位→点赞👍 + 收藏⭐️ + 留言📝
📣系列专栏-【C】系列_謓泽的博客-CSDN博客🎓
✉️我们并非登上我们所选择的舞台,演出并非我们所选的剧本📩
🌸程序的翻译环境和执行环境
在ANSIC的任何一种实现上都存在这两种不同的环境。
张三:ANSIC是什么东东,謓泽能不能说下ヾ(^▽^*)))。
什么张三同学学了这么久竟然连ANSIC是什么都忘记了,怎么回事(doge)
ANSIC实际上就是 美国国家标准协会(American National Standards Institute)协会制定的一个C语言的标准。任何C语言的编译器都在ANSIC的基础上扩充的。张三同学这个我们还是必须要了解的。
那么在上面说ANSIC的任何一种实现上都存在这两种不同的环境有⇣
- 🔥翻译环境🔥→在这个环境源代码被转换为可执行的机器指令。
在我们所使用的编译器像Vs所扮演的就是这个翻译环境。
- 🔥执行环境🔥→用于实际的执行代码当中。
这里的运行环境实际上就是执行环境。
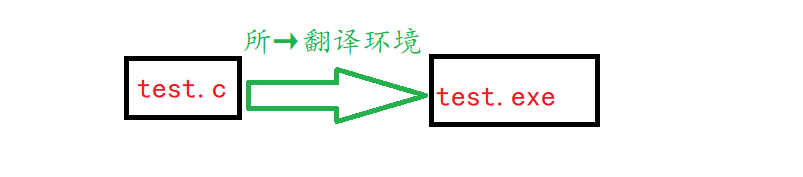
🍀翻译环境
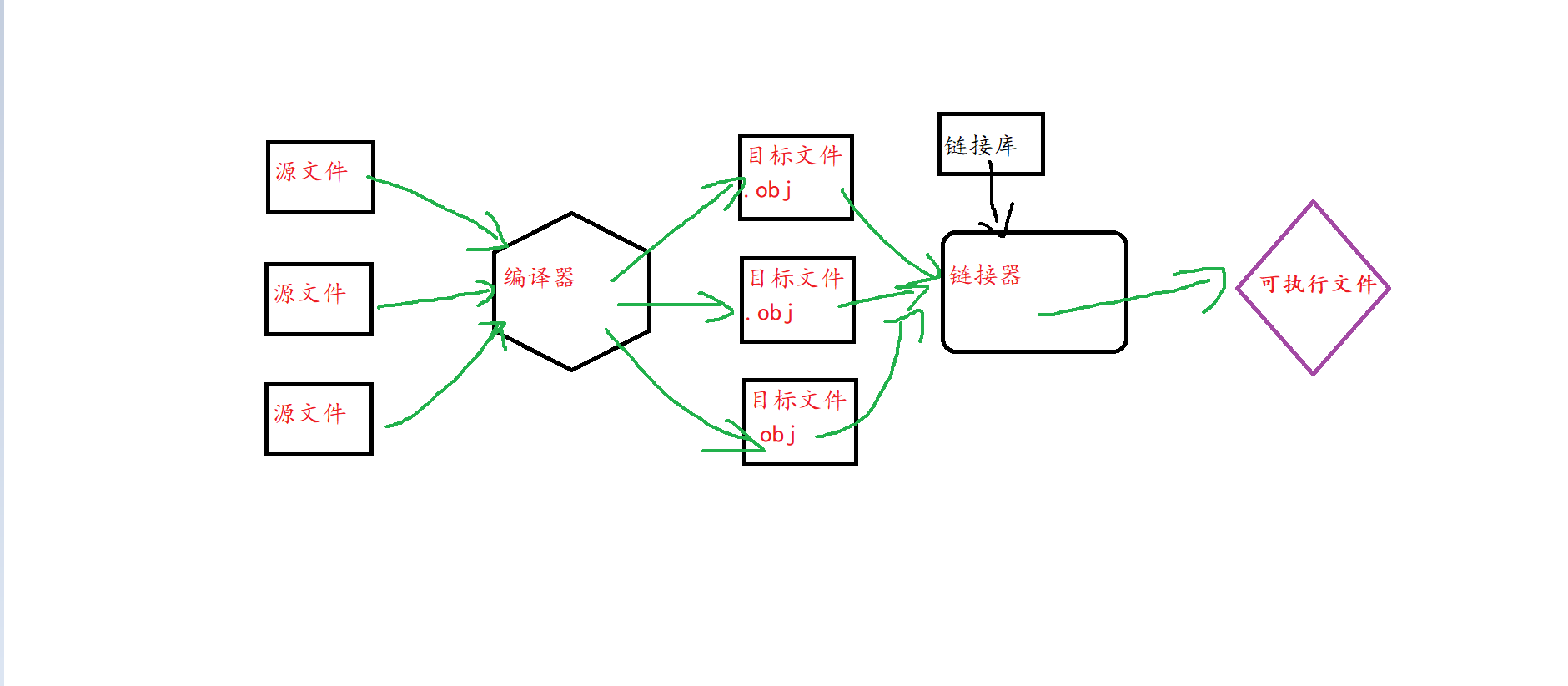
这幅图来表示下面所讲述的过程ヽ(✿゚▽゚)ノ 每个源程序也就是.c(可以是多个源程序)文件实际上都会经过编译器的处理,最后在各自生成一个目标文件.obj。
然后,这些目标文件一起就会生成一个叫做链接器的东西。在链接器进行链接的时候还会生成一个名为链接库的东西,把链接库连接到连接器当中去。最后在生成一个名为可执行文件(.exe)。
那么在这里介绍下什么是链接器和链接库如下↓
- 🎄链接器🎄→链接器(Linker)是一个程序,将一个或多个由编译器或汇编器生成的目标文件外加库链接为一个可执行文件。目标文件是包括机器码和链接器可用信息的程序模块。简单的讲,链接器的工作就是解析未定义的符号引用,将目标文件中的占位符替换为符号的地址。链接器还要完成程序中各目标文件的地址空间的组织,这可能涉及重定位工作。
- 🎄链接库🎄→一个函数当中有可能存在这链接库(library),然后这个链接库的信息就会一起存放在链接器当中去。这里的链接库就可能包含了这个函数的相关信息。
🌹翻译环境分支部分
在翻译环境中还存在几个步骤,先用一副图来表示如下↓
Ⅰ→预编译预处理:完成了对头文件(#include)的包含,#define定义的符号和宏的替换,也就是说会把宏定义数据赋值给对应变量的值,注释删除,因为注释是给我们打代码的人看的。它的指令是:gcc test.c - E (预处理后就停止)
Ⅱ→编译:把C语言的代码转换成汇编代码,那么肯定要做什么事情也就是我们所说的一个过程实际上有:语法分析、词法分析、语义分析、符号汇总(汇总全局变量的符号)。它的指令是:gcc test.i - S,生成 test.s
Ⅲ→汇编:对.s的文件进行汇编,把汇编代码转换成机器代码指令(二进制代码),还有进行了生成符号表(生成全局变量的符号)。它的指令是:gcc test.s -c,生成 test.o(test.obj)
- gcc 是编译器。
🌹链接器Linker
链接器工作的 ③ 个部分如下↓
- 将代码和数据模块象征性地放入内存。
- 决定数据和指令标签的地址。
- 修补内部和外部引用。
把多个目标文件和链接库来进行连接。
链接器使用每个目标模块中的重定位信息和符号表,来解析所有未定义标签。这种引用发生在分支指令、跳转指令和数据寻址处,所以这个程序的工作非常像一个编辑器:它寻找所有旧地址并用新地址取代它们:编辑是"链接编辑器"或链接器名字的简称。采用链接器的原因是修补代码比重新编译和汇编要快得多。可以说,通过这个地址就可以找到它所在的函数。
如果所有外部引用都解析完,链接器接着决定每个模块将要占用的内存位置。MlIPS在内存中为程序和数据分配空间的方式。因为文件是单独汇编的,所以汇编器不可能知道该模块的指令和数据相对于其他模块而言将会被放到哪里。当链接器将一个模块放到内存中的时候,所有绝对引用(absolute reference),即与寄存器无关的内存地址必须重定位以反映它的真实地址。
链接器产生一个可执行文件(executable file),它可以在一台计算机上运行。通常,这个文件与目标文件具有相同的格式,但是它不包含未解决的引用。具有部分链接的文件是可能的,如库程序,在目标文件中仍含有未解决的地址。
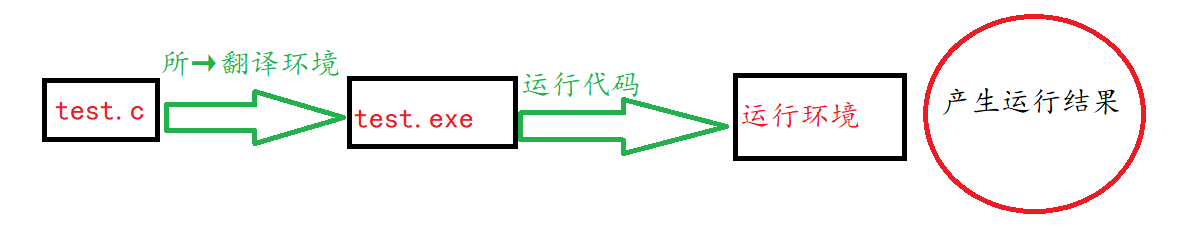
🍀运行环境
程序执行的过程如下⇣
①程序是必须载入的内存当中,在操作系统的环境中的环境中:一般都是由这个操作系统完成的。在独立的环境中,程序的载入都必须是手工进行安排,也可以是通过可执行代码置入只读的内存当中完成。
- 计算机当中所有的数据都是必须要放在内存当中的,不同类型的数据占用的字节数不一样。
- 常见的操作系统有很多种例如:Linux、Windows、macos 等
②程序的执行都是从 main() 函数当中开始的。
③开始执行程序代码,这个时候程序将会使用一个运行时候的堆栈(stack),存储函数的局部变量和返回的地址。当然程序也可以同时使用静态(stack)内存,存储于静态内存中的变量程序的整个执行过程一直会保存它们的值得。
栈
- 在执行函数的时候,函数内部局部变量的存储单元都是可以在栈上进行创建的,函数执行结束的时候这些存储单元会被自动的进行释放。栈区主要存放运行函数所分配的局部变量,函数的参数,返回数据,返回地址等。
堆
通常定义变量(或对象),编译器在编译时都可以根据该变量(或对象)的类型知道所需内存空间的大小,从而系统在适当的时候为他们分配确定的存储空间。这种内存分配称为静态存储分配;有些操作对象只在程序运行时才能确定,这样编译时就无法为他们预定存储空间,只能在程序运行时,系统根据运行时的要求进行内存分配,这种方法称为动态存储分配。所有动态存储分配都在堆区中进行。
堆当程序运行到需要一个动态分配的变量或对象时,必须向系统申请取得堆中的一块所需大小的存贮空间,用于存贮该变量或对象。当不再使用该变量或对象时,也就是它的生命结束时,要显式释放它所占用的存贮空间,这样系统就能对该堆空间进行再次分配,做到重复使用有限的资源。
④终止程序,正常终止main()函数,当然也可能是意外得终止。
👌总结-以上内容你学费了没~
★最后★ ⇢ 点赞👍 + 关注👋 + 收藏📑 == 学会✔
【C语言】程序的翻译环境和执行环境
news2026/2/16 8:45:55




本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.coloradmin.cn/o/12961.html
如若内容造成侵权/违法违规/事实不符,请联系多彩编程网进行投诉反馈,一经查实,立即删除!相关文章
智慧博物馆解决方案-最新全套文件
智慧博物馆解决方案-最新全套文件一、建设背景二、思路架构三、解决方案建成5个方面1、集约化2、物联网接入3、大数据可视化分析4、室内室外地图集成5、可视化信息多元交互四、获取 - 智慧博物馆全套最新解决方案合集一、建设背景
博物馆是征集、典藏、陈列和研究代表自然和人…

【FME实战教程】002:FME完美实现CAD数据转shp案例教程(以三调土地利用现状数据为例)
FME完美实现CAD数据转shp案例教程(以三调土地利用数据为例) 文章目录1. cad数据预览2. 转换过程3. shp数据预览1. cad数据预览 2. 转换过程
(1)打开FME Desktop2020中文软件,点击【新建】。 (2)…
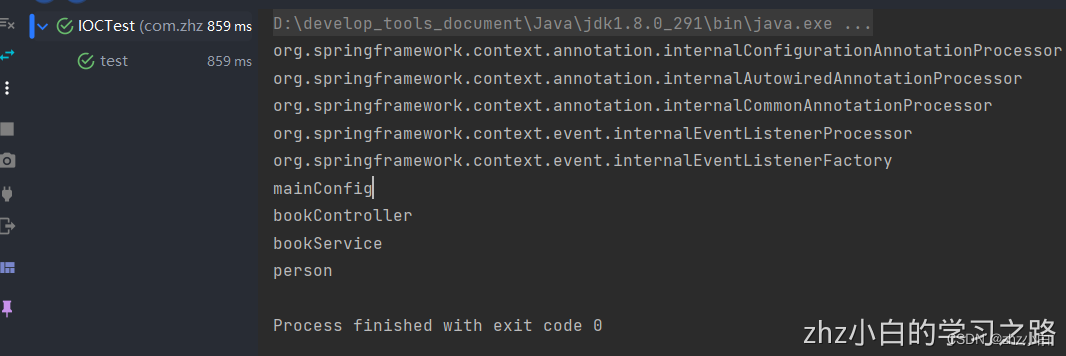
【Spring】——2、使用@ComponentScan自动扫描组件并指定扫描规则
📫作者简介:zhz小白 公众号:小白的Java进阶之路 专业技能: 1、Java基础,并精通多线程的开发,熟悉JVM原理 2、熟悉Java基础,并精通多线程的开发,熟悉JVM原理,具备⼀定的线…
微信小程序开发(九):使用扩展组件库
前端开发中离不开各种组件库,我最先接触的组件库还是Bootstrap,后来工作中又陆续使用了inoic、ng-zorro等各种不同的库。
在微信小程序开发中也有多种组件库,这里记录其中几种不同组件库的使用方法。
WeUI
这是微信官方推出的一款和微信原…
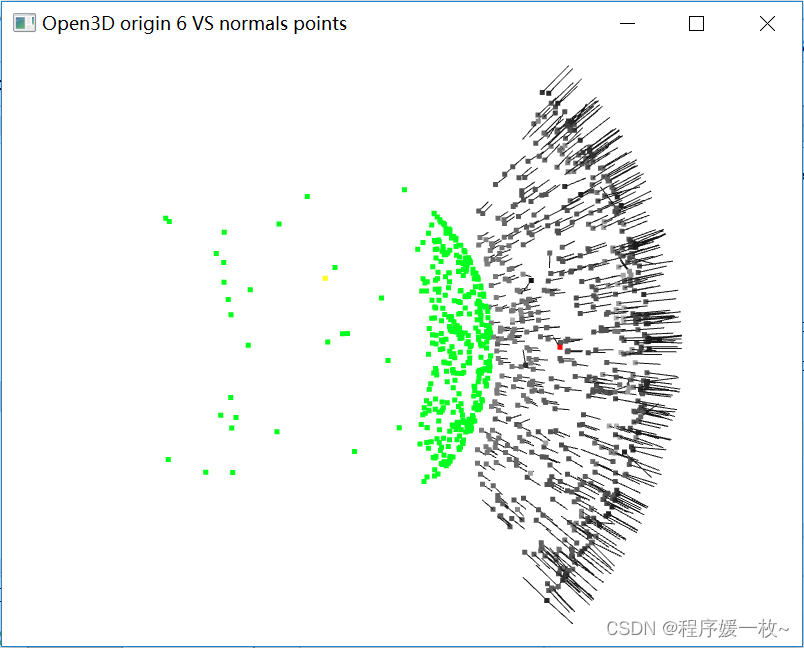
使用Python,Open3D对点云散点投影到面上并可视化,使用3种方法计算面的法向量及与平均法向量的夹角
使用Python,Open3D对点云散点投影到面上并可视化,使用3种方法计算面的法向量及与平均法向量的夹角
写这篇博客源于博友的提问,他坚定了我继续坚持学习的心,带给了我充实与快乐。 将介绍以下5部分:
随机生成点云点投影…

MySQL数据库索引和事务详解
目录
前言:
索引
查看索引
创建索引
删除索引
索引使用
底层数据结构分析
事务
事务引出
MySQL设计事务
事务四大特性
小结: 前言: 数据库索引和事务的存在,对于数据库的一些性能有了显著提升。我们需掌握其底层的实现…

Elasticsearch与Kibana安装
现有环境
windows
docker ubuntu
Elasticsearch安装
安装包下载
ES不同平台、版本下载路径:Download Elasticsearch | Elastic
本文演示用linux
# 启动ubuntu环境,开放端口9200、9300、5601
docker run -name es -p 9200:9200 -p 9300:9300 -p 5…

指夹式血氧饱和检测仪方案分析
指夹式心率血氧饱和度方案的测量原理是根据血红蛋白(Hb)和氧合血红蛋白 (HbO2)在红光和近红光区域的吸收光谱特性为依据,运用Lambert Beer定律建立数据处理经验公式,采用光电血氧检测技术结合光电容积脉搏波描记(PPG)技术…

化工制造行业数字化升级案例—基于HK-Domo商业智能分析工具
案例背景导读 世伟洛克(Swagelok)是全球领先的流体系统解决方案的开发商和制造商,为包括科研、仪表、制药、油气、电力、石化、代用燃料和半导体等在内的各个行业提供产品、组装和服务。世伟洛克通过独立的销售和服务中心网站进行运营&#x…

使用 Typescript 封装 Axios
对 axios 二次封装,更加的可配置化、扩展性更加强大灵活 通过 class 类实现,class 具备更强封装性(封装、继承、多态),通过实例化类传入自定义的配置 创建 class
严格要求实例化时传入的配置,拥有更好的代码提示
/*** param {AxiosInstance…

C语言习题练习8--二进制操作符
IO型--从main函数开始写,要写输入、计算、输出
接口型--不需要写主函数,默认主函数是存在的,你只需要完成函数就行
一、二进制中1的个数
(12条消息) C语言丨关键字signed和unsigned 的使用与区别详解_Emily-C的博客-CSDN博客_signed unsi…

【笔记】samba shell 脚本 离线安装 - Ubuntu 20.04
前言
按照官网调试代码、网上各种步骤来走(还收费)都不行 结果发现是防火墙问题 公司服务器安装的ufw使用失效,导致端口号放行添加失败 换用firewall-cmd成功 现在免费放下代码,气死他们收费的
目录
├── home│ ├── k…

linux备份mysql8.0数据库脚本
文章目录环境要求步骤1、创建一个.sh文件编写shell脚本2、添加定时任务环境要求
linux系统,安装了mysql8.0
步骤
1、创建一个.sh文件编写shell脚本
创建文件的命令:
vim ***.shshell文件文件参考自文章 链接
export LANGen_US.UTF-8
#注意…

测试开发技术:Python测试框架Pytest的基础入门
Pytest简介
Pytest is a mature full-featured Python testing tool that helps you write better programs.The pytest framework makes it easy to write small tests, yet scales to support complex functional testing for applications and libraries.
通过官方网站介绍…

十五、Lua 协同程序(coroutine)的学习
Lua 协同程序(coroutine) 什么是协同(coroutine)?
Lua 协同程序(coroutine)与线程比较类似:拥有独立的堆栈,独立的局部变量,独立的指令指针,同时又与其它协同程序共享全局变量和其它大部分东西。
协同是非常强大的功…
2646-61-9, 脯氨酰内肽酶(PEP)底物: Z-GPLGP-OH
编号: 160473中文名称: 脯氨酰内肽酶(PEP)底物:Z-Gly-Pro-Leu-Gly-ProCAS号: 2646-61-9单字母: Z-GPLGP-OH三字母: Cbz-Gly-Pro-Leu-Gly-Pro-COOH氨基酸个数: 5分子式: C28H39O8N5平均分子量: 573.64精确分子量: 573.28等电点(PI): -pH7.0时的…
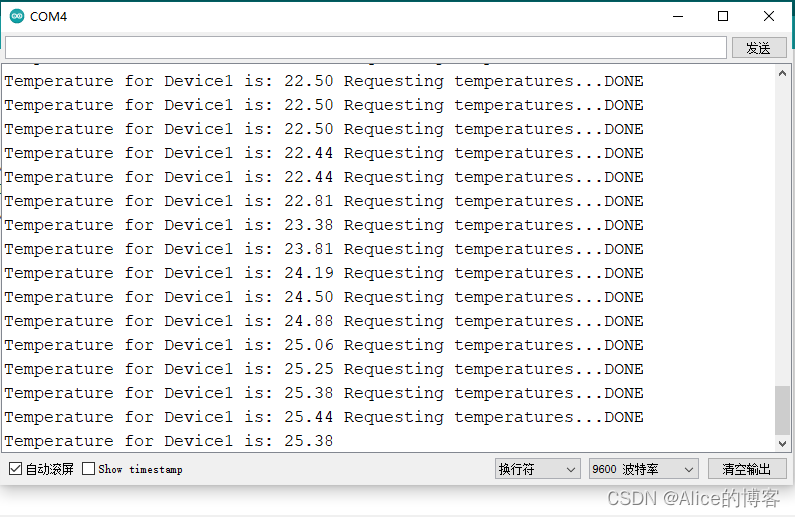
Arduino程序设计(三) 光照采集 + 温度采集
光照采集 温度采集前言一、光敏电阻检测环境光二、DS18B20检测环境温度总结参考文献前言
本文主要介绍两种常见的传感器采集环境参数,即光照传感器和温度传感器。光照传感器采用光敏电阻GL3516(5-10K)检测环境光。温度传感器采用DS18B20检测…
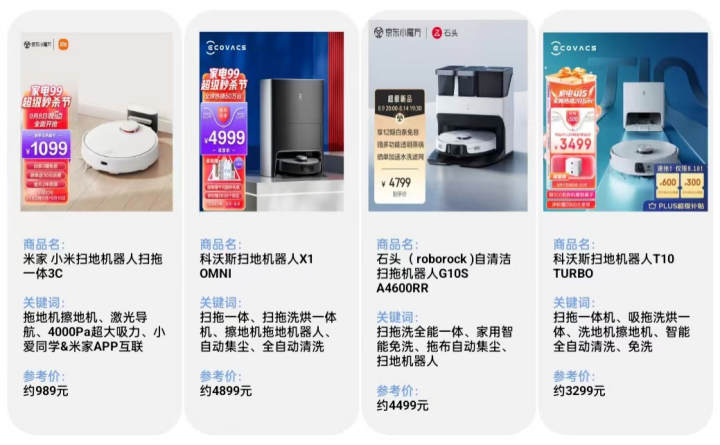
2022Q3家电行业高增长细分市场分析(含热门品类数据)
2022年,在大环境的影响下,大众消费偏好更趋于理性化、追求高性价比,不少行业增速有所放缓,在此背景下,2022年Q3季度中,消费市场中仍有一些高增长概念涌现。 在家电行业中,我们发现了3个高增长品…