目录
前言:
索引
查看索引
创建索引
删除索引
索引使用
底层数据结构分析
事务
事务引出
MySQL设计事务
事务四大特性
小结:
前言:
数据库索引和事务的存在,对于数据库的一些性能有了显著提升。我们需掌握其底层的实现原理。
索引
查看索引
语法:show index from 表名;
show index from student;
注意:可以清楚看见id这一列是由primary key约束的,具有索引。
创建索引
语法:create index 索引名称 on 表名(列名);
create index idx_student_name on student(name);
注意:
索引已经创建成功,name这列已经具有索引。一个表只能有一个主键,但是可以有多个索引。
创建索引最好在创建表最初时就创建成功。如果一张表有大量数据,创建索引是极其危险的行为。需要读取服务器硬盘数据,会消耗大量的磁盘IO。这段时间里数据库可能无法正常使用。
删除索引
语法:drop index 索引名称 on 表名;
drop index idx_student_name on student;
注意:name这列索引已经删除成功。同样的删除索引也需要读取硬盘数据,也是危险行为。
索引使用
索引创建成功后,不需要手动使用,在执行查询语句时会分析具体使用还是不使用索引。SQL是通过数据库执行引擎来执行的,它会自动评估这次查询使用还是不使用索引,并且会对SQL进行一些优化操作。选择成本低,速度快的方案。那么一次查询是否在走索引,以及怎么走,我们是不好分析的。可以通过explain关键字,具体查询索引的使用情况。
底层数据结构分析
如果使用哈希表作为底层数据结构。由于数据库中经常进行范围查询,而哈希表只能进行是否相等的查询,那么哈希表显然就不适合。如果使用二叉搜索树来作为底层数据结构,由于数据量特别大时,树的高度就会比较高,而树的高度决定了查找的次数。服务器中的查询需要读取硬盘数据,这样会增加IO的压力,也是不合适的。
如果使用N叉搜索树(B树)作为底层数据结构。它每个节点上有多个值,同时有多个分叉。这样树的高度就会降低,但随之带来的是不稳定的查询。

这样的结构可以降低树的高度。一个节点上有多个数据,可以减少读取硬盘的次数(一次可读多个数据)。由于数据的实体都是在节点上存储,即可能一次就查找到目标数据,也可能多次查找到目标数据,带来的是不稳定的查询。在B树的基础上提出了B+树。
B+树作为MySQL的InnoDB数据库引擎里典型的数据结构。不同的数据库,不同的引擎,底层的数据结构可能会不一致。
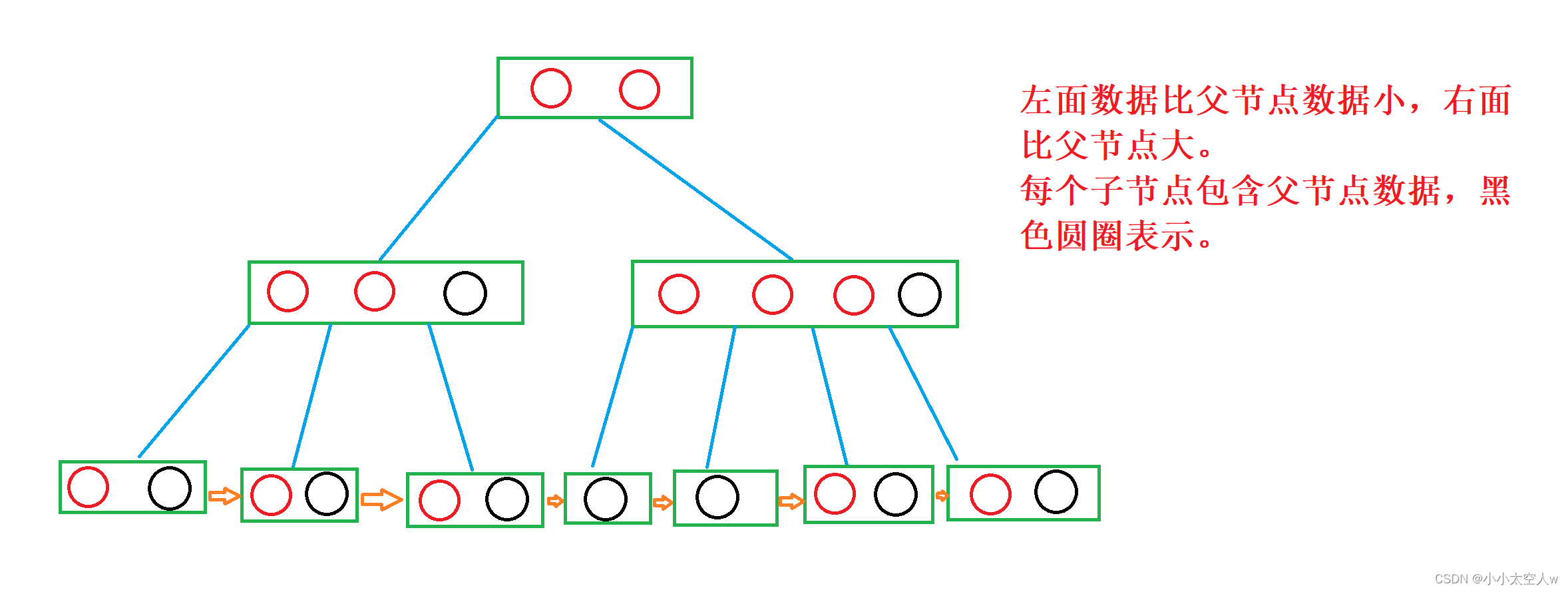
B+树的叶子节点是用链表连接起来的。由于子节点包含父节点的数据,并且是以最大值出现的。即在叶子节点就会包含所有数据的全集合。
结构特点:
1)可以使树的高度降低下来。
2)一次可对读多条数据,减少对硬盘的读取次数,降低硬盘IO压力。
3)数据的全集和是用链表连接起来,更加适合范围查询。
4)由于叶子节点包含数据的全集和,可将实体数据存入叶子节点,非叶子节点存储索引即可。
5)所有查询都是落入叶子节点,无论查询那个数据,中间比较次数都差不多,查询比较稳定。
注意:
一个表可能有多个索引。非主键有索引,也会构造一个B+树。非叶子节点存储索引,叶子节点存储主键id。
如果使用主键查询,只需要查一次B+树即可。如果使用非主键的索引查询,需要遍历一次非主键的B+树,找到对应的主键id,再去查主键的B+树。这样的操作称为回表。
事务
事务引出
由于一些操作是一个整体。例如转账操作,需要从一个户主账户里扣钱,另一个户主账户里要增加钱。两步操作要么都进行,要么都不进行。
MySQL中为了保证这样的想法,就将这两个操作称为一个事务。事务是不可以分割的,体现出事务的原子性。如果事务执行一半出错了,MySQL中会记录目前正在进行事务的操作,一旦发生错误就会进行恢复操作。保证和之前执行的样子一致。称为回滚操作(rollback),也是事务一致性的体现。
MySQL设计事务
start transaction;//开启事务
中间写多个SQL
commit;//提交事务
注意:中间的SQL不会立即执行,等到commit统一执行(保证原子性)。可以使用rollback主动进行回滚,恢复之前的状态。
事务四大特性
1)原子性
一个事务是一个整体,不可以分割。
2)一致性
事务执行的前后,数据都是合法状态。
3)持久性
数据库操作都是针对于硬盘,产生的效果就具有持久性。
4)隔离性
首先介绍一个例子。我在写数据的时候,如果旁边有人看,他可能读一个错误的数据,因为我可能会改,称为脏读问题。如果我写完他在看,会解决脏读问题,但我可能会更新我写的东西,造成他前后读的数据不一样,称为不可重复读问题。如果我写完他再看,并且他在看的时候我不能更新,可以解决脏读和不可重复读问题,但我可以写其他的数据,造成他读数据的集合不一样,称为幻读问题。
其实这个过程我在逐渐减小读和写的并发程度。并发越低,隔离性就越高,执行效率越低,数据准确度越高。并发越高,隔离性就越低,执行效率就越高,数据准确度越低。
MySQL提供了四个隔离级别
1)read uncommitted
不做任何限制,并发程度最高,隔离性最低,执行效率最高,数据最没有准确度。会造成脏读,不可重复的,幻读问题。
2)read committed
对写操作加锁,降低并发程度,隔离性增加,执行效率降低,数据准确度增加。解决脏读问题。
3)repeatable read
对读和写都加锁,又进一步降低并发程度,隔离性又进一步增加,执行效率又降低,数据准确度又进一步增加。解决脏读,不可重复读问题。
4)serializable
严格串行化,并发程度最低,隔离性最高,执行效率最低,数据准确度最高。解决脏读,不可重复读,幻读问题。
小结:
在学习过程中,要多思考底层的原理,对于我们理解会有很大帮助,也会加深印象。坚持就会有不一样的收获。