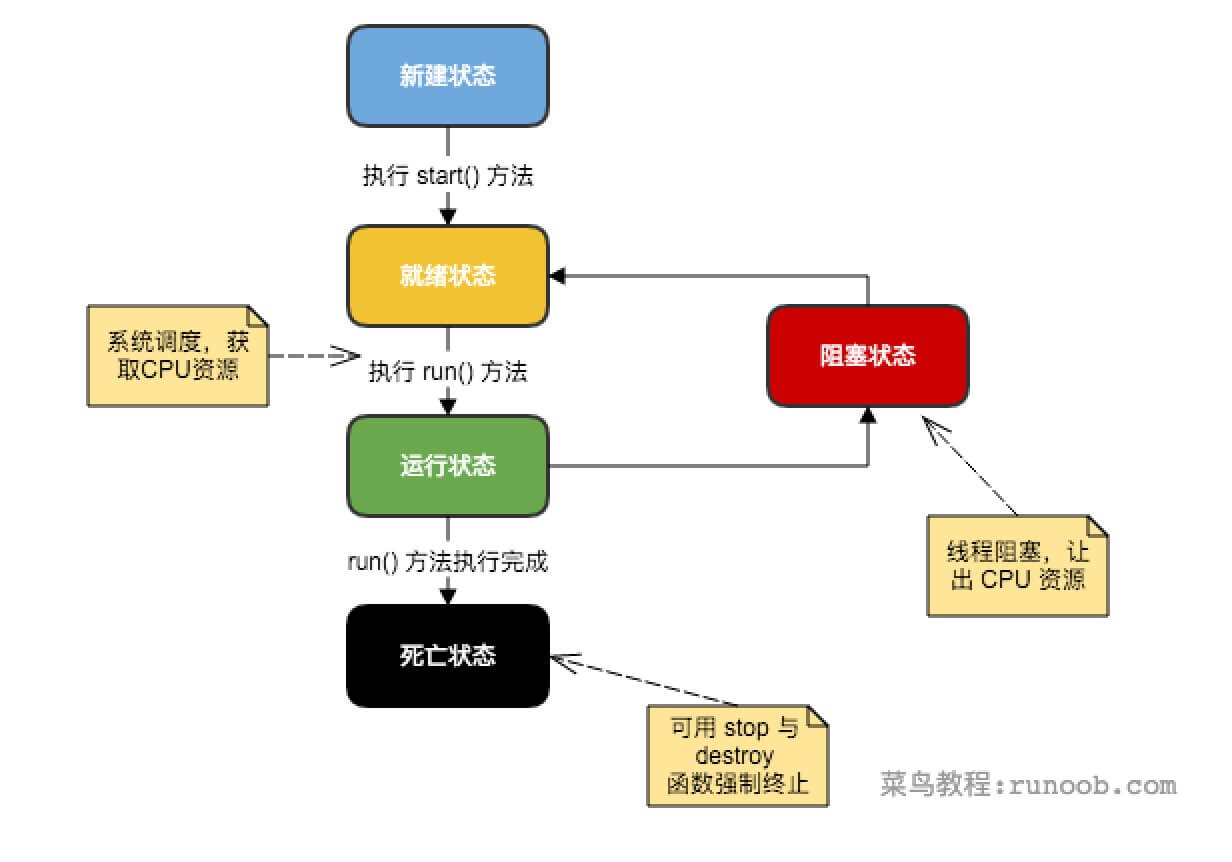
Mysql 小Tips
目录
- Mysql 小Tips
- 1.group_concat
- 2.char_length
- 3.locate
- 4.replace
- 5.now
- 6.insert into ... select
- 7.insert into ... ignore
- 8.select ... for update
- 9.on duplicate key update
- 10.show create table
- 11.create table ... select
- 12.explain
- 13.show processlist
- 14.mysqldump
- 总结
| 函数名 | 说明 |
|---|---|
| group_concat | group by 字段拼接 |
| char_length | 字符长度 |
| locate | 关键字位置 |
| replace | 字符替换 |
| now | 当前时间 |
| insert into … select | 类似于拷贝其它表然后插入 |
| insert into … ignore | 插入时忽略重复插入的引起的错误 |
| select … for update | 低并发下,更新表时使用悲观锁 |
| on duplicate key update | 无数据时插入,有数据时则更新 |
| show create table | 查看创表信息 |
| create table … select | 快速备份表 |
| explain | 查看mysql执行计划 |
| show processlist | 查看当前线程执行情况 |
| mysqldump | 导出表中的数据 |
1.group_concat
group_concat跟group by一般一起使用。
在平时的工作中,使用group by进行分组的场景,非常多。
比如,我想统计出注册的用户中用户名称具体有哪些?
可以用以下sql进行查询:
SELECT name from test
GROUP BY name;
这里我们对 name 列进行了group by, 要是想把相同姓名的用户id拼接在一起,放在另外一列中该怎么办呢?
这个时候可以使用group_concat函数。
SELECT name, GROUP_CONCAT(id) as all_id from test
GROUP BY name;
执行结果:

说明:
使用
group_caoncat函数,可以轻松的把分组后,name相同的数据拼接到一起,组成一个字符串,用逗号分隔。
2.char_length
有时候我们需要获取字符的长度,然后按照字符的长度进行排序,这个时候就可以使用char_length函数。
根据字符长度对查询到的结果进行排序:
SELECT name from test where name LIKE "%Abc%"
ORDER BY CHAR_LENGTH(name);
执行结果:

说明:
这里name 字段使用关键字 模糊查询 之后,再使用
char_length函数获取name字段的字符长度,然后按长度进行升序。
3.locate
有时候我们在查找某个关键字,比如:abc, 需要明确知道它在某个字符串中的位置时,该怎么办呢?
这个时候我们就可以使用locate函数。
例如我们使用locate函数进行查询:
SELECT * from test ORDER BY LOCATE("y",name);
执行结果:

说明:
按照name中“y”所在的位置进行排序,"y"越靠左的越排在前面。
这个类似的还有instrh和position函数,它们的功能跟locate类似,下面举例instr的用法:
SELECT * from test where INSTR(name,'A');
执行结果:

说明:
instr应该见到名字可以大致猜出作用,就是判断某个关键字是否在某个字符串中。上述查询语句的意思就是查找出所有
name中包含"A"的数据。
locate函数其实跟locate差不多,有用法上的区别:
SELECT * from test ORDER BY POSITION("1" IN name);

4.replace
我们经常会有替换字符串中部分内容的需求,比如:将字符串A替换成B。
这种情况就能够使用replace函数。例如:
UPDATE test set name=REPLACE(name, "A", "F");
执行结果:

也可以使用该函数去掉字符的前后空格:
UPDATE test set name=REPLACE(name, " ", "") WHERE name LIKE " %";
UPDATE test set name=REPLACE(name, " ", "") WHERE name LIKE "% ";
5.now
在MYSQL中获取当前时间,可以使用now()函数,例如:
SELECT NOW() from test LIMIT 10;
执行结果:

通过now()函数会包含年月日时分秒
若还想返回毫秒,可以使用now(3),例如:
SELECT NOW(3) from test LIMIT 10;
执行结果:

6.insert into … select
因为id字段是自增的,所以插入null的时候自动填充
在工作中我们常常遇到要插入数据的场景
通常我们的插入语句是这样的:
insert into test(id, name, time)
VALUES(7, "zxc", NOW(3));
这种插入操作只适用于插入少量并且已经确定的数据。但是如果有大批量的数据需要插入,特别是需要插入的数据来自另外一张表或者多张表的结果集中。
这个时候就能使用MYSQL提供的:insert into ... select语法。
例如:
insert into test(id, name, time)
SELECT NULL, user, now(3) from User;
这样就很方便将 User 表中的部分数据,插入到test表中。
7.insert into … ignore
比如我们遇到这样的场景:在插入1000条数据之前,需要先根据name,判断一下是否存在,如果存在,则不插入数据。如果不存在,才需插入数据。
我们可以在sql语句后面拼接not exists语句,也可能达到防止出现重复数据的目的,比如:
insert into test(id, name, time)
SELECT null, "ywh", now(3)
FROM `User` WHERE NOT EXISTS (SELECT * from test WHERE `name`="ywh");
不过使用复合sql语句的方法比较麻烦。
我们可以直接使用insert into ... ignore语法
insert IGNORE into test(id, name, time)
VALUES(2, "ywh", now(3));
执行结果:

使用ignore之后,就会自动忽略重复插入的异常。若返回的结果影响行数为0,则表明不会重复插入数据。
8.select … for update
MYSQL数据库自带了悲观锁, 它是一种排它锁,根据锁的粒度从大到小分为:表锁、间隙锁和行锁。
在我们的实际业务场景中,有些情况并发量不太高,为了保证数据的正确性,使用悲观锁也可以。
比如:用户扣减积分,用户的操作并不几种。但是也要考虑到自动赠送积分的并发情况,所以有必要加悲观锁限制,防止出现积分加错的情况发生。
这时候就可以使用MYSQL中的select ... from update语法了。
例如:
begin;
select * from `user` where id=1
for update;
//业务逻辑处理
update `user` set score=score-1 where id=1;
commit;
这样子在一个事务中使用for update锁住一行记录,其他事务就不能在该事务提交之前,去更新那一行的数据。
需要注意的是for update前的id条件,必须是表的主键或者唯一索引, 不然行锁可能会失效,有可能变成表锁。
9.on duplicate key update
通常情况下,我们在插入数据之前,一般会先查询一下,该数据是否存在。如果不存在,则插入数据。如果已存在,则不插入数据,而直接返回结果。
在并发量小的场景中,这种做法一般没什么问题。但是如果插入数据的请求,有一定的并发量,这种做法就可能会产生重复的数据。
当然我们可以用加唯一索引、加分布式锁等方法防止重复数据。但是这些方案都不能做到让第二次请求也更新数据,它们一般会判断已经存在就直接返回了。
这种情况可以直接使用on duplicate key update语法。
该语法会在插入数据之前判断,如果主键或唯一索引存在,则执行更新操作。
具体需要更新的字段可以指定,例如:
INSERT INTO `brand`(`id`, `code`, `name`, `edit_date`)
VALUES (123, '108', '苏三', now(3))
on duplicate key update name='苏三',edit_date=now(3);
10.show create table
有时候,我们想给快速查看某张表的字段情况,通常会使用desc命令,比如:
desc test;
执行结果:

这却是能够看到 test表中的字段名、字段类型、字段长度、是否允许为空,是否主键、默认值等信息。
但看不到该表的索引信息,如果想看创建了哪些索引,该怎么办?
可以使用show index命令。
比如:
show index from test;
也能够查出该表的所有索引:

但查看字段和索引数据呈现方式,总觉得不是很好,有没有更加直观的方式?
这时候可以使用show create table命令了。
例如:
show create table test;
执行结果:

表名,Create Table就是我们需要看的建表信息。我们可以看到非常完整的建表语句,表名、字段名、字段类型、字段长度、字符集、主键、索引、执行引擎等都能看到。
11.create table … select
有时候,我们需要快速备份表。
通常情况下,可以分为两步走:
- 创建一张临时表
- 将数据插入临时表
创建时可以使用命令:
create table new_test like test;
创建成功后,就会出现叫做new_test的新表,表的结构和test表一样,但是其中的数据是空的。
接下来使用命令:
INSERT into new_test SELECT * from test;
执行之后就会将test表中的数据插入到new_test表中。
我们也可以直接使用create table ... select 命令,一步实现上面的功能。
create TABLE new_test2
SELECT * from test;
执行完毕后会自动创建new_test2表,并且将test表中的数据自动插入到new_test2表中去。
12.explain
有时候,我们优化一条sql语句,需要查看索引执行情况。
可以使用explain命令,查看mysql执行计划,它会显示索引的使用情况。
例如:
EXPLAIN SELECT * from test where NAME="ywh";
执行结果:

通过这几列可以判断索引使用情况,执行计划包含列的含义如下图所示:

常见的索引失效的原因:

13.show processlist
有时候我们线上的sql或者是数据库出现了问题。比如连接过多,或者发现有一条sql语句的执行时间特别长。
这时候我们可以使用show processlist命令查看当前线程执行情况。
例如,执行结果:

从执行结果中,我们呢可以查看当前的连接状态,帮助识别出有问题的 查询语句。
| 字段名 | 说明 |
|---|---|
| id | 线程id |
| User | 执行sql的账号 |
| Host | 执行sql的数据库的ip和端号 |
| db | 数据库名称 |
| Command | 执行命令,包括:Daemon、Query、Sleep等 |
| Time | 执行sql所消耗的时间 |
| State | 执行状态 |
| info | 执行信息,里面可能包含sql信息 |
如果发现了异常的sql语句,可以直接kill掉,确保数据库不会出现严重的问题。
14.mysqldump
有时候我们需要导出MYSQL表中的数据。
这种情况我们可以使用mysqldump工具,该工具会将数据查出来,转换成insert语句,写入到某个文件中,相当于数据备份。
我们呢获取到该文件,然后执行相应的insert语句,就能创建相关的表,并且写入数据了,这就相当于数据还原。
mysqldump的命令语法为:mysqldump -h主机名 -P端口 -u用户名 -p密码 参数1,参数2.... > 文件名称.sql
备份远程数据库中的数据库:
mysqldump -h 127.0.0.1 -u root -ywh dbname > backup.sql
总结
转自: https://juejin.cn/post/7179239346967412773










![Java高效率复习-SpringMVC[SpringMVC]](https://img-blog.csdnimg.cn/eefd6995fed541f0830eb0e2f48cdbe1.png)