数理逻辑部分
- 数理逻辑
- 命题逻辑
- 逻辑连接词
- 命题符号化
- 命题公式
- 命题公式的等价
- 矛盾式与重言式
- ※重言关系蕴含式的证明
- ※重言关系等价式的证明
- 析取范式与合取范式
- 主析取范式
- 主合取范式
- 对于两种范式,我的一些看法
- 命题逻辑推理
- 直接推理
- 间接推理
- 谓词逻辑
- 谓词演算的等价式和蕴含式
- 谓词演算推理理论
数理逻辑
- 什么是数理逻辑?
用数学方法研究形式逻辑。 - 什么是数学方法
我们从小就学习的数学就是数学方法,即用某些符号来研究解决形式逻辑。那么也称作**“符号逻辑”**
即:数理逻辑也可以称为符号逻辑。 - 数理逻辑的划分
分为两部分:
一、命题逻辑
二、谓词逻辑
命题逻辑
- 什么是命题
能够表达判断的陈述句。 - 命题的真值
只有两个真值
为真:T(True)
为假:F(False) - 如何判断是否为命题
综上所述:
一、陈述句
二、该命题不是真就是假。(即不能又真又假) - 命题的种类
(一):原子命题
不能分解成更加简单的陈述句命题
(二):复合命题
由多个原子命题通过连接词或者标点符号连接起来,构成复合的命题。
逻辑连接词
归纳自然语言中的联结词,定义了六个逻辑联结词。

下面解释仅仅是我认为需要注意的点
- 否定
对命题P的否定,一般读作:非P - 合取
(顾名思义合在一起取)
两个命题进行合取的时候需要二者都为真才为真,其他均为假 - 析取
(顾名思义将二者析开来取)
两个命题进行析取的时候需要二者都为假才为假,其他均为真 - 异或
(也称排斥或)
我的理解就是:二者必须有一个出现而且不能同时出现。即不能同时进行
举个栗子:
P:列车在8:00开
Q:列车在12:00开
P和Q显然是不能同时进行的,也不能两个都不进行。
总结:因为二者不能同时进行,那么其中一个发生了,该命题就表示为真,否则为假。
需要注意的是:二者为真的时候也为假!
谈一谈为什么叫异或:
我认为因为两个命题不能同时发生或者同时不发生所以就叫做异或。 - 蕴含
现有两个命题:P 、Q
P->Q 可以说成:P是Q的充分条件,Q是P的必要条件。
即:如果。。。就。。。
特别注意:当前件为假的时候,后件无论是真是假都无所谓,整个命题便为真。这个叫做善意的谎言,可以说成是,前件命题只要是假的,整个命题我们都认为你说的是对的。
例子:P为真,Q不管真假
命题1:非P->Q
命题1中因为非P为假,我们善意的推断命题1是真的。
特别注意:当两边都为真的时候,整个命题肯定为真 - 等价
(也称双条件)
首先解释为什么称为双条件:
因为需要边都为真或者两边都为假的时候,整个命题才为真。
P<—>Q
表示的是P是Q的充分必要条件。 - 异或与等价的区别
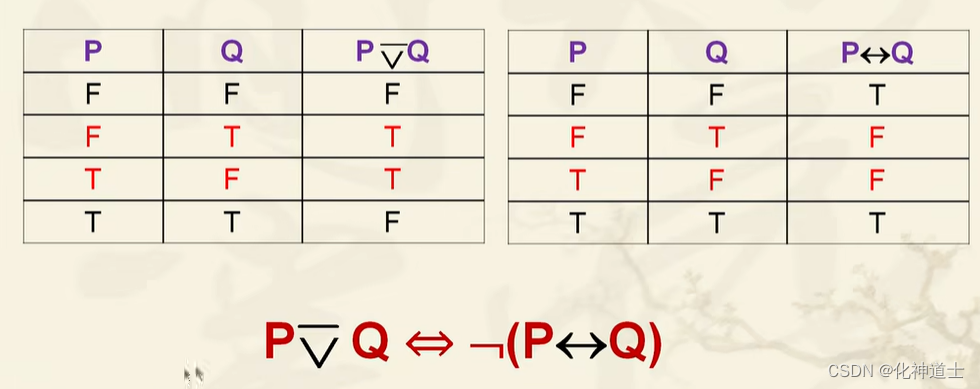
很明显,在解释异或的时候就提到,两件事情不能够同时发生,只要同时发生便为假,否则为真。而等价的解释便是充分必要条件,需要二者都为真或者都为假的时候才为真,否则为假。
二者是刚好相反的。 - 真值表
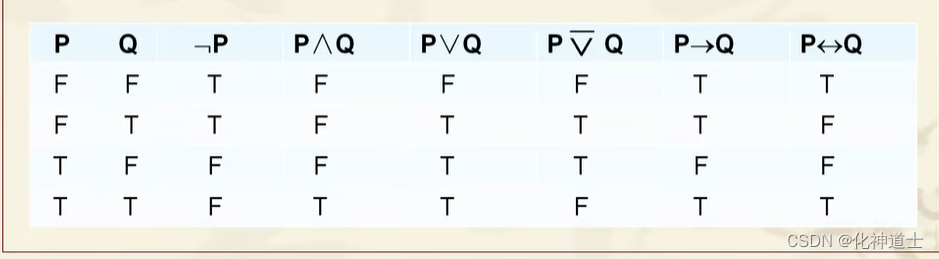
每个原子命题遍历真值且对应在每个用不同的联结词把原子命题联结成一个复合命题,通过原子命题的真值写出每个复合命题的真值即为真值表。
简单来说就是:将六种联结词遍历两个原子命题,两个原子命题遍历真值,然后得出不同的复合命题的真值。
如下图:
命题符号化
解释:就是将自然中的语言即陈述句,拆分成多个原子命题,然后将这些原子命题组合,最终将该陈述句用符号化的形式表达出来。
不多说,一张图来说明一切。

命题公式
构成命题公式的有以下三种数据类型:
-
命题常项:
即命题真值,T or F。 -
(常值)命题:
即具体的命题,他有真值。 -
命题变元:
即一个字母符号代表一个命题,但是该命题还未确定他的真值,没有固定真值。待确定真值后就变成了常值命题。 -
合式公式
就是用六种符号对命题进行一系列的组合
我们平时看到的用六种联结词联结起来的都是合式公式。
这个不作解释,因为说多了都是废话。 -
真值表
在这里重新详细的谈谈真值表。因为真值表蕴含的东西远远不止比表面的真值。

-
有多少行真值
有三个命题变元,所以有23行
那么可推出:有n个命题变元的话就有2n行 -
0 代表 F ;1 代表 T
-
还有一个隐含的意思
就是该真值表可以看做一个矩阵,然后每个真值具有脚标,脚标就是隐含的意思,在写主合取范式和主析取范式的时候十分有用,利用下标能够直接写出一个蕴含式所表达的主范式。下标是用0和1来表示。
埋一个彩蛋,到了主范式的时候会详细解释。
命题公式的等价
-
什么是命题公式的等价?
两个命题的原子命题通过取一样的真值,最后发现构成两个命题的真值也是一样的,就是命题的等价。
通过真值表表示更直观,如图:
每一列真值都一样。
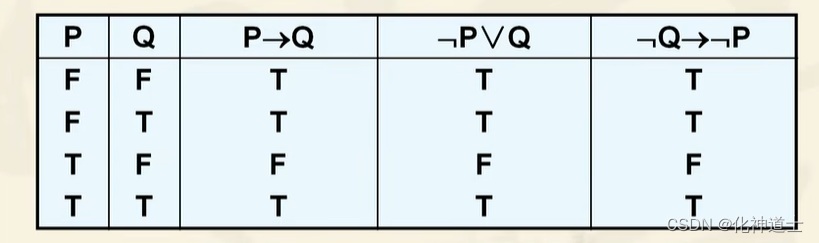
可以直观看出三个命题表示的真值无论P、Q取什么,都是一样的,就可以说着三个合式公式等价,在做运算的时候可以直接进行转换,这是基本的转换公式。 -
注意点
— 最后一个命题公式是P->Q的逆否命题,所以是非Q->非P。
— 第一二个命题是最常用的转换公式。

-
基础等价公式:


-
吸收律
如何记忆:
内外符号不一样,只有两个命题变元。
吸收律为什么叫吸收律,顾名思义就是把内部吸收掉, 只留括号外面的变元。(前提是括号内外的符号不相同) -
德摩根律
很重要的一个规律,在信息安全与数学基础,概率论中都有用到。
记忆:(使用概率论的口诀)
长杠变短杠,符号要变向。
解释:就是说括号内是一个命题,括号外有一个否定联结,把括号拆开,否定联结词放进去需要把每个变元都加一个否定,然后联结两个变元的合取变析取,析取变合取。
简而言之就是:将概率论中的杠号变成否定联结词,操作还是和概率论是一样的。
如图所示:

-
对偶式
这对于简化我们计算步骤十分重要。
对偶式的定义如下:

对偶式的使用如下:
解释:好比你现在要把非符号放进一个很复杂的括号内的命题里面,我们先学的知识只允许我们使用德摩根律,但如果真的反复使用德摩根律就会变得十分繁杂,做到猴年马月才行,总之就是十分的满。
这时候我们如果使用对偶式就会变得十分简单:
步骤1:首先写出括号内的对偶式
步骤2:直接把非放进每一个原子命题的前面即可。
得到的合式公式就是与原命题等价,就不用反复使用德摩根律就能得出最终化简的结果,省去了十分多的步骤。
如下图:
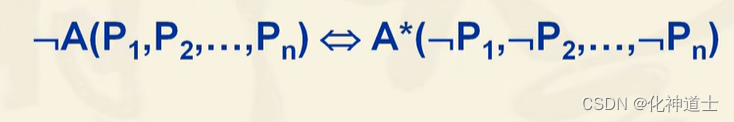
例子:
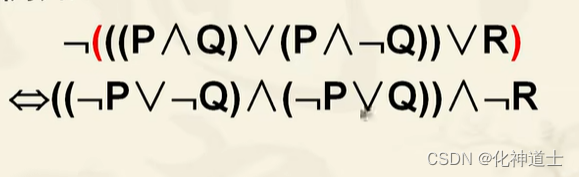
-
对于等价的说明
等价符号不是运算符号而是一个关系符号,表示两边的命题之间的关系是等价的,就是他们原子命题取的值无论是什么,两边的命题最后的真值都是等价,可能化简后式子不一样了。

矛盾式与重言式
- 矛盾式
命题永远为假,即为矛盾式。
即无论命题变元的真值如何取,最后整个复合命题还是为假。 - 重言式
命题永远为真,即为重言式,也称永真式。
即无论命题变元的真值如何取,最后整个复合命题还是为真。
※重言关系蕴含式的证明
- 细说关系符号
(一)引出关系等价<=>符号:该符号是关系符号,表示两边命题的一个等价关系
比如:P<=>Q,表示的是P整个命题等价Q这个命题,就是说无论P与Q里面的原子命题如何取真值,PQ真值都相等,即等价。
即:P与Q的真值都一样,那么就有P < - > Q = T。
再次重申:等价关系符号不是运算符,只有<->才是运算符。
(二)再引出关系蕴含=>符号:该符号是关系符号,表示两边的一个蕴含关系
比如:P=>Q,表示当且仅当P->Q为重言式的时候,才能记作成P=>Q。 - 按照上面的等价符号说法,得出结论:
(一)假如P<=>Q,那么就当且仅当P < - > Q为重言式
通过等价推出重言式,因为等价就相当于PQ两个最终的真值都是相等的,不用考虑原子命题的真值,直接等价就说明了P与Q是相同真值。
(二)假如P->Q=T 时,推出P=>Q。
通过重言式,推出关系蕴含。 - 重言蕴含式的两种证明方式:
解释:因为在蕴含符号中,只要前件为假,则就变成了善意的谎言,整个命题都是真的。所以我们就是利用这个特点进行证明,只要证明出不会出现这种情况即可。
第一种:假设前件为真,若能推出后件也为真的话就是重言蕴含式。
第二种:假设后件为假,若能推出前件也为假的话就是重言蕴含式。 - 基本的重言蕴含式子
不用刻意去记忆,只是说这些公式都能用刚刚说的两种方法进行验证。


※重言关系等价式的证明
- P<=>Q等价关系证明
我们知道等价关系能引出一个运算
即:P<->Q = T
又因为:P->Q合取Q->P = T
即:P->Q = T ; Q -> P = T
那么两边的重言式又可以推出:
P=>Q ;Q => P
所以在证明等价的时候就利用反推法:
只要证明出了:P=>Q ;Q => P
那么就证明出了P<=>Q等价关系
也就是说↓ :
P<=>Q等价关系的充要条件是P=>Q ;Q => P
析取范式与合取范式
这里我不采用官方的定义去解释这两种范式
析取范式
- 什么是析取范式?
析取符号两边的命题不能有析取符号,两边的命题可以是单个原子命题变元,也可以是由 合取符号组成的复合命题变元。复合命题必须使用合取符号。
(其实还有一个前提就是:析取符号两边的命题分别用括号括起来后,两边的括号内不能再添加括号,而且否定联结词也不能加在括号外边,只能放在每一个原子命题的前面)
析取范式没有这么严格,只要析取符号两边满足上面的需求即可,可以一个合取符号命题析取一个原子命题。
虽然不喜欢官方的定义,还是放一下原图:

合取范式
- 什么是合取范式
合取符号两边的命题不能有合取符号,而且命题可以是单个原子命题变元、可以是由 析取符号组成的复合命题变元。复合命题必须使用析取符号。
(其实还有一个前提就是:合取符号两边的命题分别用括号括起来后,两边的括号内不能再添加括号,而且否定联结词也不能加在括号外边,只能放在每一个原子命题的前面)
合取范式没有这么严格,只要合取符号两边满足上面的需求即可,可以一个析取符号命题析取一个原子命题。
官方定义:

- 小结
(一):合取与析取范式都是只含有三种运算符。
即:否定联结词、合取符号、析取符号。
(二):否定联结词必须放在命题变元前面,不可加在括号前面。
(三):一个合取式:既可以是合取范式,也可以是析取范式。
解释一下为什么也能是析取范式:

首先我们需要一个套娃的思维:毋庸置疑这一看就是合取范式,但就是当我们把他看成一个命题元来说的话,再将该命题与命题T(T就是真值为1,永远为真)进行析取,那么就是成为了一个析取范式。
同样的我们也可以将一个析取式看做合取范式。
最后就是说一下为何析取范式与合取范式只有三种运算符号:
很现实的来说就是,我们需要将<=>、=>这两个符号转化为析取、合取、否定联结词这三个符号来表示,所以就没有这两个符号的出现。
主析取范式
- 计划任务
- 1:什么是小项?
- 2:小项的编码是什么意思?
- 3:引出主析取范式。
- 4:主析取范式与析取范式有什么区别?
- ☆什么是小项?
主析取范式两边的合取式就是小项。
小项的特点:每个命题变元在小项中必须出现一次且仅当只出现一次。
为什么叫小项:我自己的理解是因为合取在集合中的表示是交集,两个集合的交集可能会比原来的集合小,所以就是小的项。
假如有n个变元,那么就有2n个变元。
(所以一般来说至少有四个小项)
注意:小项是属于主析取范式的,所以小项是合取式。

-
☆小项的编码
编码即脚标。
(注意的是我们这脚标也是真值表中的脚标,只是我们这些小项蕴含在小项的真值表中。特别注意,说的是小项的真值表,因为现在这些小项都是变元。)
编码使用二进制的编码,有n个变元就最后一个小项采用n的二进制编码进行脚标的编码。
现假设只有两个变元,用来表示小项(合取)。
1表示变元本身,0表示变元的否定。
例如:当P合取Q的时候脚标为00。
以此类推,01表示P合取非Q,直到最后一个11
(提一嘴:一般是按照字母进行排列,P合取Q而很少时候是Q合取P)

-
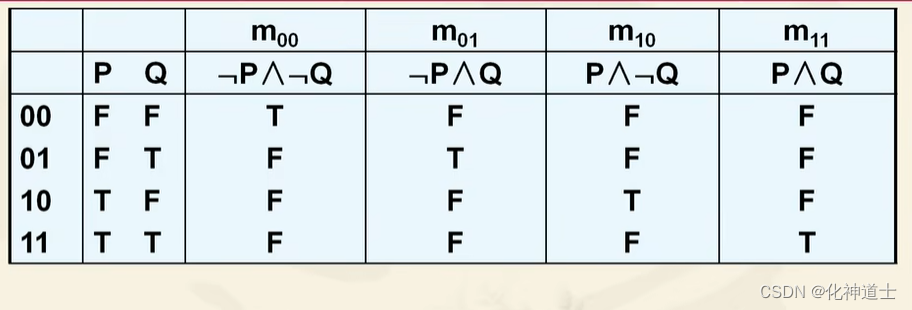
划分了脚标编码后有什么用?
我们把这些小项的脚标进行排序,排成一个矩阵,就可以得到一个真值表,我们再通过真值表进行研究,可以得出某些规律。
-
小项真值表的规律
规律1:可以看出在真值表中,PQ取的真值用01表示的时候,对应着真值表中的脚标就是全为真T。
比如第一行中的PQ真值为00,那么与对应真值表中m00的那一列的第一行真值为T
第二行中的PQ真值为01,那么与对应真值表中m01的那一列的第二行真值为T。
以此类推…
规律2:全体小项的析取式为永真式 = T。 -
小项小结
小项是变元公式,没有赋真值
小项的编码是按照变元本身1与变元的否定0进二进制编码。
小项的编码与小项真值表之间的联系:小项用01进行行排序,真值表用01进行列的排序,组成一个矩阵。那么小项的脚标与真值表中的真值相同,所对应的小项的位置作为列坐标与用该小项编码作为真值赋值的位置作为行坐标,然后该行列坐标对应的位置就是真值为真的位置。(很废话难懂)
简而言之:一、编码都是排序的,赋值也是按照二进制排序的
二、找到小项所在的列,再找到与该列小项编码相同的真值所在的行,然后行列相交的位置就是真值为T的地方。
可以结合图片再看我这句话就可能印象深刻。 -
总结
我感觉就是十二分的绕,我们既要明白小项是什么,小项的编码是按照小项的变元进行编码,小项的编码又与小项的真值表有联系,编码对应着真值后,该位置的真值为T。
其实还有些小细节就是:小项编码后只有2n个,因为是按照小项的种类作为个数,编码又是按照小项中的变元的本身或者变元的否定进行1与0的二进制编码,所以不是真值表中的个数。
所以最后得出就是:全体小项进行析取的话就是永真式。(因为无论怎么取真值,真值表中一定有为T的真值。)
- 引出主析取范式
定义:主析取范式就是小项之间进行析取。
很概括了其实,说细一点就是,每一个变元都要出现在析取的两边的合取式的里面。(你晕了吗?)
再说白点:析取小项,小项里面都要出现一次命题变元,且只能出现一次,该析取式就叫做主析取范式。
惯例,附上官方定义:

- 如何求主析取范式?
- 第一种方法
第一步:将不齐全的命题变元补齐,即在析取的两边补上没有出现的命题变元。(如何补齐:假如Q这变元中没有出现P这个变元,那就补一个:P析取非P,因为该真值为1,将该补上的式子要与Q作合取,因为合取一个真值为1的还是本身)
第二步:运用之前学过的分配律或者其他规则

- 第二种方法
使用真值表方法:
在求主析取范式的时候给出的都是蕴含式和等价式。
所以我们使用他们的真值表来求,然后因为我们上面的小项真值表中发现编码对应的都是真值问T的,所以我们这里蕴含式也找到他对应的真值为T的编码,然后将这些对应为T的真值赋给对应编码的小项然后分别析取就为主析取范式。

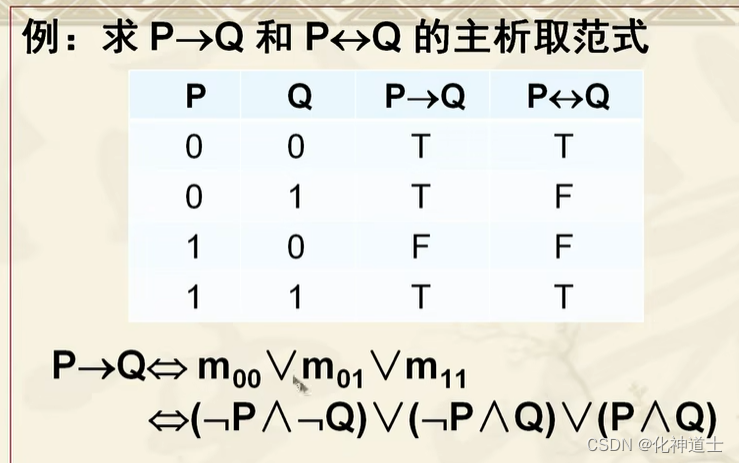
同理:等价式求主析取范式的时候也是一样的,即00和11这两个小项进行析取的时候是主析取范式, 找到对应真值为T的编码然后将这些对应为T的真值赋给对应编码的小项然后小项进行析取即可。 - 为什么要求一个关系符号的主析取范式的时候可以直接使用真值表?
我的解释:因为在小项的真值表中,当给每一个小项赋值之后,最多的就是真值为F,所以我们就不用真值为F的赋值,而是用T的赋值方式,比如我们在一个蕴含式中要写出他的主析取范式的时候,我们只要找出使该蕴含式为T的真值赋值情况,然后把该真值赋值情况放进小项的脚标,找到该小项,然后又因为小项真值表中脚标对应真值的情况为T,所以正好我们找到这些所有的小香蕉进行析取便找到了主析取范式。
- 主析取范式与析取范式有什么区别?
首先最主要的区别就是主析取范式要求做到的是平衡,而析取范式更加的随意一点,并且否定符号不能放在括号里面。。
解释什么是平衡:就是在主析取范式中,一个析取符号两边的命题变元数量是一样的,这个就称作小项,并且一边的小项中的命题变元必须只出现一次,还要有且仅能出现一次。这里要注意不是整个析取式,而是针对于该小项来说,每一个小项里面必须要每一个变元都要出现并且只能出现一次,所以两边的小项的变元数量是一样的,只是说否定连接词导致了小项之间的不同。
说回析取范式,那它只要求两边是合取式的命题。
主合取范式
-
计划任务
-
1:什么是大项?
-
2:大项的编码是什么意思?
-
3:引出主合取范式。
-
4:主合取范式与合取范式有什么区别?
-
什么是大项
每个变元必出现一次,且只能出现一次,该析取式就为大项。 -
在主合取范式中为什么说析取式为大项。
因为析取的定义就像在集合中的并集,将两个集合进行合并,那么合起来之后肯定会变大,所以叫做大项。 -
同理与小项一样,有n个变元就有2n个大项。
- 大项的编码
大项的编码形式也是采用变元本身与变元的否定进行编码,采用的也是01二进制方式进行编码。
但是:大项的编码赋值方式与小项的相反。大项的变元本身是0,变元的否定是1。 - 我对于为什么大小项编码相反的理解
因为在大项中我们在真值表中找的是真值为F的,原因也很简单,最主要的原因就是因为大项中真值为F的项比较少,然后又因为大项中我们取得编码是相反的,所以在蕴含式真值表中也要找到真值为F的保证FF为T,也就是我们所说的负负得正。
- 引出主合取范式
主合取范式要的是将两个大项进行合取。 - 如何求主合取范式
第一种:补齐的方式,因为大项是需要析取,所以在补齐的时候也要用析取符号来补齐,也就是析取上一个缺少的命题变元即(变元的本身合取变元的否定)。为什么是析取一个变元的合取呢,因为变元的本身合取变元的否定是F,所以你析取一个F就等同于只取决于你本身是T还是F。
第二种:使用真真值表。比如要求一个蕴含式的,当你写出该蕴含式的真值表,就可以找到对应的F的真值的赋值情况,作为该赋值情况作为大项的编码,将所有的这些符合的大项进行合取就变成了主合取范式。

- 主合取范式与合取范式有什么区别?
主合取范式需要更加严谨,合取符号两边必须都是大项。
合取范式比较随意,合取符号两边无所谓,只要不是合取式就行,并且否定符号不能放在括号里面。
对于两种范式,我的一些看法
- 析取,我理解成集合中的并集。合取,我理解成集合中的交集。
析取范式,首先肯定必须是一个析取的式子,合取范式,同样肯定必须是一个合取的式子。 - 一个析取范式中,在析取符号两边不能又含有析取符号,将两边的东西看成一个个体,无论该个体是什么,只要不含有析取符号就可以了。那么通过把两边看成一个个体的这种思维,引出了小项的定义,而且小项就是一个合取式,又通过了解了小项的定义,继续引出了主析取范式,因为主析取范式两边就是小项。在把一个关系式子化成主析取范式的时候,有一个比较巧妙地方法,就是写出该关系式的真值表,并且把命题变元的小项真值表写出来,然后将能使关系式真值为T的命题变元的赋值作为小项的编码,然后将这些小项进行析取就变成了该关系式的主析取范式。
- 一个合取范式中,在合取符号两边不能又含有合取符号,将两边的东西看成一个个体,无论个体是什么,只要不含有合取符号就可以了。那么通过把两边看成一个个个体的这种思维,引出了大项的定义,而且大项就是一个析取式,又通过了解了大项的定义,继续引出了主合取范式,因为主合取范式两边就是小项。在把一个关系式子化成主合取范式的时候,也是与析取范式方法一样,写出该关系式的真值表,并且把命题变元的大项真值表写出来,然后将能使关系式真值为F的命题变元的赋值作为大项的编码,然后将这些大项进行合取就变成了该关系式的主合取范式。
命题逻辑推理
- 两个推理规则
P规则:(引入前提规则)
在推理过程中可随时引入前提,我们认为前提都是正确的,所以能够随时引入,不会影响结论。
T规则:(引入结论规则)
如果在前面推理过程中使用的公式能够重言蕴含着公式S就可以把S结论引进来,也就是通过推理过程得到的结论引进来,再继续推理我们想要的结论。 - 常见的重言蕴含公式

直接推理
- 什么是直接推理:直接推理是由一组前提,利用P规则和T规则最终得到我们需要的结论。
- 推理过程举例
P->Q , Q->R , P => R
(题目分析:左边是前提,利用前提,需要推出结论R)
答案:
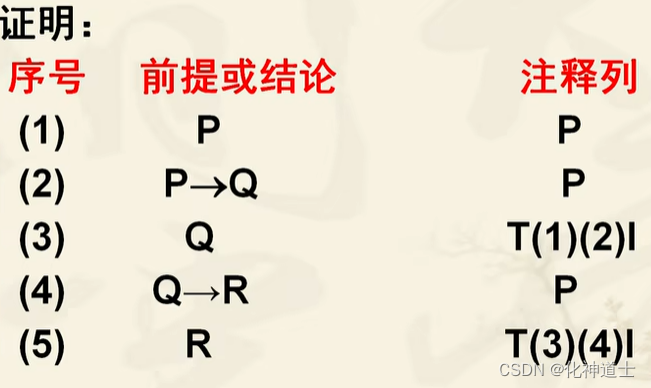
答案解析:
首先我们推理的时候要从最简单的前提开始引入,所以首先引入P前提,然后再找与P前提有关的前提进行前提引入,然后可以观察有没有一些前提能够的得出一些有效的结论,就可以使用T规则将前提进行归纳得出结论,最后得到的结论就是我们所要推理出来的结论。
Tips:
1:写T规则的时候后需要注明用到的前提是哪一个步骤的
2:前提的逗号都表示合取符号,也就是说需要把所有前提合取起来能够推出结论的。
3:直接推理的结论都是一个命题,而不是有蕴含式符号的,一般都是用原子命题作为结论,需要你去证明一个原子命题。
间接推理
-
条件论证
如果我们要证明的结论是一个蕴含式,那么我们就可以用条件论证,比如我们要证明的结论是:R->S
我们需要做的就是把R这个前件放入到前提中,然后与前面给出的前提进行合取,合取出来永真蕴含S后,就表示R->S是推理出来了,最后那一步叫做CP规则。
所以最后一步的注释列一般都是写由CP规则得出R->S -
推理过程举例:
P->(Q->S), 非R析取P, Q => R -> S
答案:

答案解析:
首先我们需要把R->S 结论中的前提取出来放进前提中,明显前件是R,所以把R提取出来放进前提中,和前提一并推理出结论S即可,最后需要标注用CP规则得到的结论即可。
Tips:
1:引入前件
2:先用简单的前提进行前提引入
3:然后再找与引入的前提有关的其他前提进行推理,看能否得出一些结论
4:通过观察能有一些前提得出结论之后,就把这些非前提进行合取得到一些结论,就是使用T规则
5:最后就是使用CP规则得出证明
- 反证法
我们将结论进行取非的形式与前面的所有前提进行合取,如果最终得到的结论是一个矛盾式,就表证明成功了。 - 推理过程举例:
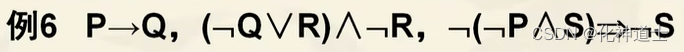
答案:

答案解析:
我们知道R与非R做合取肯定是一个永假式。所以即证明了我们推理出了结论。
Tips:首先我们需要将结论进行取非,然后与前提进行合取,接下来的步骤与前面的都差不多,先简单后顺着这条线索找下去,然后进行最后证明得到一个永假式即可推理成功。
谓词逻辑
预备知识:
1:个体
能够独立存在的具体的或者抽象的事物,称为个体,一般来说也就是我们能够表达出来的不能够变化的东西。
- 个体常项:指具体的特定的个体,类似于编程中的
通常用小写字母a,b,c…来表示。 - 个体变元:指不确定表示哪一个具体的事物,但是这个事物是一类的,类似于编程中的变量
通常用x,y,z…来表示。
2:谓词
刻画个体属性的词,叫做谓词,有点类似于编程中的函数。
比如:谓词S,表示是一个大学生,
个体常项:a为小李,b为小明
S(a)表示小李是一个大学生,S(b)表示小明是一个大学生。
- n元谓词:
如果在一个谓词里面的参数个数为几元谓词。
比如:一个个体变元的时候,S(x1)称1元谓词,如果有n个就叫n元谓词。 - 0元谓词:
就是当一个谓词里面的个体为常量,就叫做0元谓词。0元谓词也就是命题。 - 谓词变项:
谓词变项就是反应一个抽象性质或者相互之间的一个关系,通常用大写字母:F,H,G,P等作为谓词变项,其实谓词常项就是我们做题中经常用到的,相当于一个函数,能够表示一中关系而已。 - 谓词常项:
谓词常项,一般都是文字表述,“是…”,比如:“是男生”, “是女生”… - 谓词常项与谓词变项的区别
我们谓词常项一般都是我们口头上使用文字表述出来的叫做谓词常项,而谓词变项就是我们约定用某一个字母来表示个体之间的关系或者某种性质,让你看到该字母就知道表达的是哪一个谓词常项的性质。
比如我们用P表示某一个数字是整数,那么P(4)就是一个真值为T的命题,因为4就是一个整数没毛病,所以我们知道括号里面的是4,也指定了P是一个谓词,表示的是“是整数”,所以其本质就是将谓词变项转化为谓词常项的过程,因为我们人就是需要谓词常项才能知道表示的是什么意思,这也体现了离散数学中数理逻辑还是有点意思的。
命题函数
函数:必须有定义域和值域
那么一个命题函数中,他的定义域是谓词中的参数所能取的范围就是定义域,而值域就是{F,T},也就是真值0和1两个真值表作为值域。
- 命题函数
命题函数是一个函数,并没有指定一个个体常量,也就是说,该命题函数是:谓词加n个体变元即命题函数。(当然不可以没有定义域) - 命题
命题函数里面需要将个体变元指定一个确定的值才能成为命题,也就是说谓词中的参数要是个体常量。 - 命题函数与命题的区别
命题函数相当于一个公式一样,命题就是相当于一个值,你给了命题函数一个具体的常量之后,该函数就变成了一个有真值的命题。 - 个体域
一个函数中有一个叫定义域的概念,那么在命题函数中的定义域就是叫做个体域。个体域也就是个体变元的取值范围。 - 个体域的分类:
1:全域,指的就是所有东西,啥都有可能,即一切皆有可能。称为“全总个体域”
2:指定的范围。不用多解释,就是指定一个定义域。
3:约定:命题函数定义域中有一个约定,就是当没有指定的范围的时候就是属于全域范围的。
量词
个体有时候需要量化,也就是全部,一些,几个类似这样的表达就是量词。

- 量词的指导变元:
量词后面需要一个个体变元,表示该个体变元的量词符号

量词就是一个将个体变元量化的过程,用来特地限制的一个个体变元的量词。
所有就表示在定义域范围内的所有
存在就表示在定义域范围内的存在 - 特性谓词
按照我们程序员的逻辑来理解就是:将一个不不可以直接解决的问题通过一些手段或者桥梁进行搭建,然后完美的解决该问题。

我们首先设置一个前提条件,也就是设置一个if语句将其限制住范围,如果满足该条件就可以进入下一步。
谓词演算的等价式和蕴含式
- 命题变元:只有两种形式,真和假(T ,F)
- 谓词公式:
在谓词公式演算过程中,谓词变元中可能含有命题变元和个体变元,所以谓词公式中赋值的时候:
1:有命题变元就给命题赋值确定的真值
2:个体变元按照个体域范围进行赋值
3:注意的是个体域一般都是非空的,即使没有指定也默认全域作为个体域
4:谓词变项用谓词常项替代(这里看不懂回忆上面我解释谓词常项与谓词变项的时候) - 谓词公式的永真式:
也就是假设一个谓词公式A,无论我们对命题变元或者个体变元如何进行赋值,其公式真值都为T,那么就是永真式 - 谓词公式的等价式:
假设两个谓词公式AB满足:A<->B = T (即是永真式)
那么就表示两个谓词公式是等价的。 - 谓词公式的永真蕴含式
该意思其实就相当于是命题中的永真蕴含式,没啥区别,区别就是命题符号变成了谓词变项符号,也能进行之前学过的永真蕴含式公式之间的运算。 - 总结上述
命题演算中的公式也可以直接运用的谓词公式演算中去。
注意事项:如果有量词的时候需要注意,因为量词管辖的区域不能够因为公式运算导致量词管辖的区域改变了,所以需要注意不能让量词进入到公式演算中
黄色这句话需要理解一下:意思是一个量词管辖的区域与另一个量词管辖的区域之间的命题变元或者个体变元不能够相互牵扯,在自己管辖的区域内进行公式演算是可以的。
举例说明:
比如下图中的最后一个谓词演算公式,利用了德摩根律进行置换,首先这里的量词并没有进入到演算过程中,因为两个存在量词都是分别对各自的x进行管辖的区域,所以我们运算过程中并没有破坏管辖区域内个体变元的位置和关系,所以是可以直接套用公式演算的。

- 有限个体域消去量词
1:全称量词
全称量词的谓词公式,将个体变元在个体域范围内代入具体的个体常项进去之后,将谓词公式变成命题,然后将这些命题进行合取。

2:存在量词
存在量词的谓词公式,将个体变元在个体域范围内代入具体的个体常项进去之后,将谓词公式变成命题,然后将这些命题进行析取。

- 注意只有在有限个体域才能将量词消去
- 量词否定等价公式

- 注意
量词是有管辖范围的,不在范围内不归他管。
-
量词的扩充与收缩
当一个量词只对一个谓词变项生效的时候,命题符号后面不管接的是什么命题都不受该量词影响,因为量词是有自己管辖的区域的,管x就管x,并且只管指定范围内的x。如果单个谓词没含有命题变元x或者个体变元x的话就不受量词的影响,可以直接用括号与量词范围内的谓词公式括起来,这叫收缩,扩张就是收缩反过去叫做收缩。
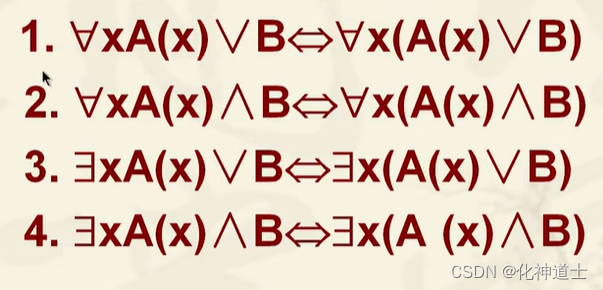
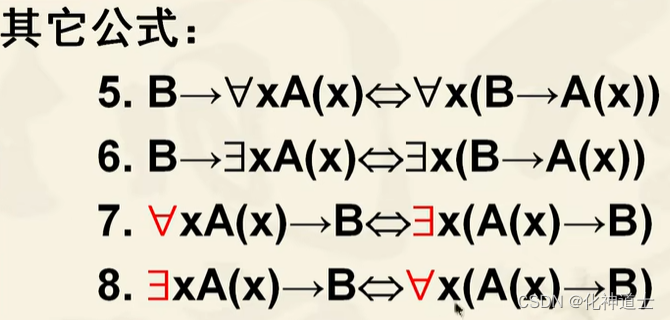
-
量词的分配公式
与分配律一样的,其实质也是收缩与扩张那个差不多,只是收缩与扩张那个是因为另一个没有与量词相关的个体变元,而这里的分配律就是两个谓词变项都有与量词管辖的变元,所以两个谓词都可以直接分配一个量词。
以下是等价式的分配律
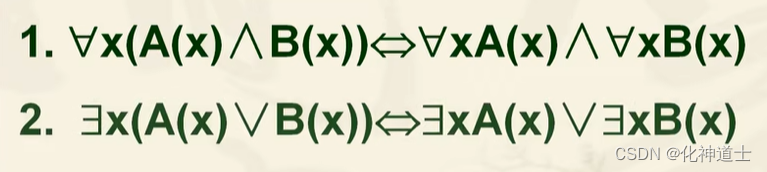
以下是蕴含式的分配律
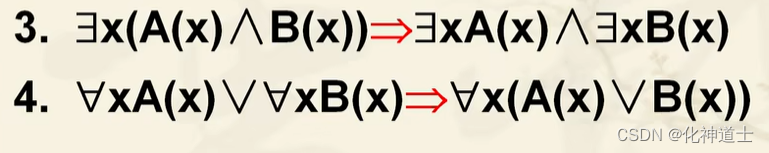
-
前束范式
定义:
1:量词前面没有联结词
2:量词在公式的左边
3:量词管辖范围延伸到公式末尾 -
我的理解
前束范式顾名思义是在公式前面进行约束,也就是说量词约束了公式里面的个体变元,并且范围是整个式子都起作用。 -
如何求前束范式
1:将联结词消去,用命题符号便于量词管辖的区域进行扩充或者缩小
2:如果有否定符号就用量词转化律将否定符号进行后移
3:用约束变元进行改名,或者对自由变元进行改名。
什么是改名规则?
就是假如谓词变项中的量词管辖的变元与另一个量词管辖的变元重名了,这时候我们知道他们时不相干的,为了运算过程中避免混乱,所以我们就需要将二者进行区分,就要把其中一个进行改名,但是还是之前那个,也就是我们平常说的换名不换人。
说白了,在编程思想中就是将变量换名而已,实质不影响整个程序运行。
4:可以运用量词分配律来进行辖域的扩充缩小公式提取量词,然后就能进行上述其中一个步骤,也就是能够最终将成为前束范式。 -
我的思考:前束范式有啥用?
1:在编程思维中思考前束范式:拿到一个乱糟糟的谓词公式的时候,我们一般是不清楚表达的什么意思的,,这时候就需要将量词提出来,然后分析里面的谓词公式,对应着量词与个体域就能知道是什么意思了。
:2:那么对应在计算机编程思想中有什么联系:我在学习C语言中,一个稍微大一点的项目,有时候迫不得已会使用到全局变量,全局变量是在你程序运行开始的时候就一直存在,直至你的程序退出,那么这与我们的量词也就能扯上一点关系了,我们在给谓词公式提取出量词的时候,其实就是在做一个观察全局变量的一个过程,进行一些列操作之后提取量词出来,然后谓词公式里面的谓词变元就是一个受外部量词约束的个体变元,就是相当于一个全局变量,如果量词改变,里面对应的个体变元也会随之改变。
谓词演算推理理论
- 推理方法:
就是我们前面学过的几种,直接推理、条件论证、反证法 - 用到的公式:
基础等价公式,基础重言蕴含公式 - 推理规则:
P , T , US , ES , EG , UG , CP , 反证法以及其他一些规则 - 下面补充US , ES , EG , UG规则:
①全称特指规则US:作用:去掉全称量词
解释:就是我们知道了个体域内任意一个x都是能够满足该谓词公式,那么我们就可以直接选定一个个体域范围内的一个个体放进去,就可以将全称量词去掉了。

②存在特指规则ES:作用:去掉存在量词
解释:我们知道在个体域中肯定有一个符合x的个体常项,然后我们就直接挑选出符合的c填进去,就能够把存在量词消去。
注意事项:想要消去存在量词,指定一个个体c的时候应该是完全贴合该管辖内的x范围,而应该是前面用US或者已经用过ES指定过的个体,这样就会导致作用域的不一样整个命题表达意思错误。其实说白了就是作用域的问题,就是前面指定过的变量不许再次用在另一个作用域内,思考一下如果用全局变量就不会有这样的情况发生,所以回到谓词公式中,我们将前面不仅符合存在量词的范围,也符合其他量词的范围的个体进行选取,那么后面运算的时候都能用,也不用换来换去了。

③存在推广规则EG:作用:添加存在量词
解释:在一个命题中我们已知是有一个个体符合谓词公式了,我们把他抽象出来成为一个参数,然后使用存在量词,这步骤就是添加存在量词。
思考:在编程思想中就想当于一种优化思想,当我们写出一个程序或者一个函数功能的时候,不能然一个函数功能过于死板,我们就会想要提取出一个参数出来,让使用函数的人在使用函数的时候能够对应输入不同的参数得出不一样的结果。在谓词公式推理中有时候会使用到分配律,有些谓词公式没有量词,这时候就需要进行一些添加,然后就能够进行分配公式中的提取量词步骤。

④全称推广规则UG:作用:添加全称量词
说明:该规则说实话我很少用到,因为能找到一个c个体,并且他还要满足个体域内任意一个个体,其实一般很难想到。


- 总结图:

- 谓词推理说明总结:
首先在推理过程中,我们遇到否定符号与量词在一块的时候首先就是要把否定符号往后移。
去掉量词的时候,我们要注意他的辖域范围,必须在量词是作用在公式最末端的时候才能够使用去掉量词规则
添加量词的时候也是一样的,与去掉量词是一样的要求。
说白了就是一个作用域的问题,学过编程的小伙伴应该一下子就能体会得到。
结语:
数理逻辑这一章十分重要,就是为后面学习理论做铺垫的,写此篇巩固基础。
(除了我个人认为的代数系统和图论之外不需要很多数理逻辑之外)






![[综][PDPTW]A survey on pickup and delivery problems](https://img-blog.csdnimg.cn/1e736345a94a4beb9a6e12e20483629d.png)